人工神經網絡可以從動物大腦中學到什麼?
最新一期Nature子刊上,就刊登了這樣一篇文章。美國冷泉港實驗室的神經科學家Anthony M. Zador,對當下人工神經網絡的研究思路進行了深刻反思與批判:
大多數動物行爲不是通過監督或者無監督算法就能模擬的。
具體來說,動物天生具備高度結構化的大腦連接,使它們能夠快速學習。從出生下時的神經結構就決定了動物具有哪些技能,再通過後天學習變得更加強大。
由於連接過於複雜無法在基因組中明確指定,因此必須通過「基因瓶頸」進行壓縮。但人工神經網絡還不具備這種能力。
但這也表明,AI有潛力通過類似的方式快速學習。
也就是說,通過反思當前的研究方式能夠發現,我們現在關於深度學習的研究從出發點的側重似乎就搞錯了,先天架構比後天訓練重要得多。
這個結論一出現,就在推特上引發了巨大的反響,不到一天,點贊數超過了1.8K,各大論壇上也少不了各種討論。不少網友表示,文章讓人有一種醍醐灌頂的感覺。
一研究者表示,很喜歡這篇文章,尤其是其中具體說明了進化與學習之間的生物學差異,以及在深度學習中能借鑑的思路見解。
機器學習研究者、http://fixr.com網站的CEO Andres Torrubia表示,這個研究不禁讓人想到權重無關的人工神經網絡,接下來的重點是如何在「遺傳瓶頸」中進行編碼了。
還有研究人員提出了新思路,猜測基因瓶頸與今年ICLR 2019的最佳論文「彩票假設」理論中得到的簡化表示之間有相似之處。
是項怎樣的研究,讓AIer的思路一下子如此開闊?

先天的重要性
機器能在多長時間內取代人類的工作?1956年,AI先驅Herbert Simon曾預言,機器能夠在二十年內完成人類可以做的任何工作。
雖然這個預測離AI的發展軌道偏離了太遠,但那時已經有了類似通用人工智能(AGI)的概念。
今天的科技界這種樂觀情緒再次高漲,主要源於人工神經網絡和機器學習的進展,但離設想的達到人類智慧的水平還很遠。
人工神經網絡可以在國際象棋和圍棋等遊戲中擊敗人類對手,但在大多數方面,比如語言、推理、常識等,還無法接近四歲兒童的認知能力。
也許更引人注目的是人工神經網絡更接近於接近簡單動物的能力。用人工智能的先驅之一Hans Moravec的話說:
人腦中高度發達的感知與運動部分的編碼,是從生物界十億年的進化經驗中學到的。我們稱之爲「推理」的深思熟慮的過程,是人類思維能力中最薄弱的一個,因爲依靠無意識的感知運動的支持才能生效。
與人工智能網絡相比,動物嚴重依賴於後天學習與先天機制的融合。這些先天機制通過進化產生,在基因組中完成了編碼,並採取一定規則連接大腦。
所以,基因瓶頸(genomic bottleneck)瞭解一下?
在這篇文章中,研究人員引入了這個概念,具體來說,是指壓縮到基因組中的任何先天行爲都是進化過程帶來的,這是連接到大腦規則的一種約束。
而下一代機器學習的算法的突破點,很有可能就在基因瓶頸上。
而這,也是當前機器學習算法與人類思維方式最大差別。
算力促進神經網絡發展
在AI的早期階段,有符號主義和連接主義兩種主義之爭。
Marvin Minsky等人支持的符號主義認爲,應該由程序員來編寫AI系統運行的算法。而連接主義認爲,在人工神經網絡方法中,系統可以從數據中學習。
符號主義可以視爲心理學家的方法,它從人類認知處理中獲取靈感,而不是像連接主義那樣試圖打開黑匣子,使用神經元組成的人工神經網絡,從神經科學中獲取靈感。
符號主義是是20世紀60~80年代人工智能的主導方法,但從之後被連接主義的的人工神經網絡方法所取代。
但是現代人工神經網絡與三十年前的仍然十分相似。神經網絡大部分進步可以歸因於計算機算力的增加。
僅僅因爲摩爾定律,今天的計算機速度比當年快了幾個數量級,並且GPU加快了人工神經網絡的速度。
大數據集的可用性是神經網絡快速發展的第二個原因:收集用於訓練的大量標記圖像數據集,在谷歌出現之前是非常困難的。
最後,第三個原因是現代人工神經網絡比之前只需要更少的人爲干預。現代人工神經網絡,特別是「深度網絡」 可以從數據中學習適當的低級表示(例如視覺特徵),而不是依靠手工編程。

在神經網絡的研究中,術語「學習」的意義與神經科學和心理學不同。在人工神經網絡中,學習是指從輸入數據中提取結構統計規律的過程,並將該結構編碼爲網絡參數。這些網絡參數包含指定網絡所需的所有信息。
例如,一個完全連接的由N個神經元組成的網絡,每個神經元都有一個相關聯的參數,以及另外N2個參數來指定神經元突觸的連接強度,總共有N+N2個自由參數。當神經元的數量N很大時,完全連接的神經網絡參數爲O(N+N2)。
從數據中提取結構,並將該結構編碼爲網絡參數(即權重和閾值),有三種經典範例。
在監督學習中,數據由輸入項(例如,圖像)和標籤(例如,單詞「長頸鹿」)成對組成,目標是找到爲新的一對數據生成正確標籤的網絡參數。
在無監督學習中,數據沒有標籤,目標是發現數據中的統計規律,而沒有明確指導查找的規則。例如,如果有足夠的長頸鹿和大象的圖片,最終神經網絡可能會推斷出兩類動物的存在,而不需要明確標記它們。
最後,在強化學習中,數據用於驅動動作,並且這些動作的成功與否是基於「獎勵」信號來評估的。
人工神經網絡的許多進步都是爲監督學習開發更好的工具。監督學習的一個主要考慮因素是「泛化」。隨着參數數量的增加,網絡的「表現力」 ,即網絡可以處理的輸入輸出映射的複雜性也隨之增加。
有足夠的自由參數的網絡可以擬合任何函數。但是,在沒有過擬合的情況下,訓練網絡所需的數據量通常也會隨着參數的數量而變化。如果網絡具有太多的自由參數,則網絡存在過擬合的風險。
在人工神經網絡研究中,網絡的靈活性與訓練網絡所需的數據量之間的這種差異稱爲「偏差 - 方差權衡」。
具有更大靈活性的網絡更強,但如果沒有足夠的訓練數據,網絡對測試數據的預測可能會非常不正確,甚至遠比簡單且功能較弱的網絡的預測結果差。
用「蜘蛛俠」 的話來說就是:能力越大責任越大。偏差-方差權衡解釋了爲什麼大型網絡需要大量標記的訓練數據。
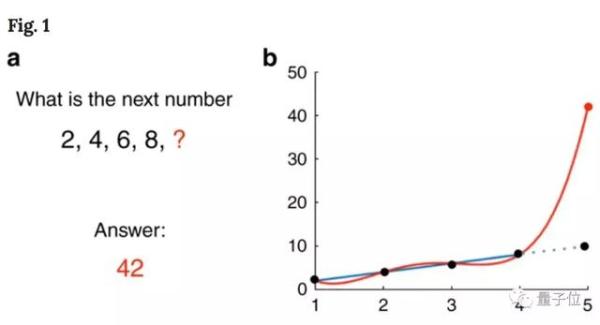
比如一組數2、4、6、8,下一個數字什麼,人會很自然的想到10,但是如果我們使用有4個參數的多項式來擬合,神經網絡會告訴我們結果是42。
三巨頭如何看待監督學習
神經科學和心理學中的「學習」一詞指的是經驗導致的長期行爲改變。在這種情況下,學習包括動物的行爲,例如經典的自發行爲以及通過觀察或指導學習獲得的知識。
儘管神經科學和人工神經網絡術語的「學習」存在一些重疊,但在某些情況下,這些術語的差異足以導致混淆。
也許它們之間最大的差異是術語「監督學習」的應用。
監督學習是允許神經網絡準確地對圖像進行分類的範例。但是,爲了確保泛化性能,訓練此類網絡需要大量數據集。一個視覺查詢系統的訓練需要107個標註樣本。這種訓練的最終結果是人工神經網絡至少表面上具有模仿人類分類圖像的能力,但人工系統學習的過程與新生兒學習的過程幾乎沒有相似之處。
一年的時間大約107秒,所以要按照這種方法訓練孩子,需要不吃不喝不睡覺每一秒都問一個問題,以獲得相同數量的標記數據。然而,孩子遇到的大多數圖像都沒有標註。
因此,可用的標記數據集與兒童學習的速度之間存在着不匹配。顯然,兒童並不是主要依靠監督算法來學習對象進行分類。
諸如此類的因素促使人們在機器學習中尋找更強大的學習算法,讓AI像孩子一樣在幾年內掌握駕馭世界的能力。
機器學習領域的許多人,包括三巨頭中的Yann Lecun和Geoff Hinton等先驅都認爲,我們主要依靠無監督算法而不是監督算法,來學習構建世界表徵的範例。
用Yann Lecun的話說:
「如果智能是一塊蛋糕,那麼大部分蛋糕都是無監督學習,蛋糕上的花就是監督學習,蛋糕上的櫻桃就是強化學習。」
由於無監督算法不需要標記數據,因此它們可能會利用我們收到的大量原始未標記的感知數據。實際上,有幾種無監督算法產生的表示讓人聯想到那些在視覺系統中發現的表示。
雖然目前這些無監督算法不能像監督算法那樣有效地生成視覺表示,但是沒有已知的理論原則或界限排除這種算法的存在。
儘管學習算法的無自由午餐定理指出不存在完全通用的學習算法,在某種意義上說,對於每個學習模型,都存在一個數據分佈很差的情況。
每個學習模型必須包含對其可以學習的函數類的隱式或顯式限制。因此,雖然孩子在他剛生下來一年內遇到帶標註的圖像數據很少,但他在那段時間內收到的總感官輸入量非常大。
也許大自然已經發展出一種強大的無監督算法來利用這一龐大的數據庫。發現這種無監督算法,如果它存在的話,那將爲下一代人工神經網絡奠定基礎。
從動物的學習方式中學習
學習行爲和天生行爲的區別在哪?
核心需要解決的問題是,動物如何在出生後迅速學習,也不需要大量訓練數據加持。
和動物相比,人類是一個例外:成熟的時間比其他動物都要長。松鼠可以在出生後的幾個月內從一棵樹跳到另一棵樹,小馬可以在幾小時內學會走路,小蜘蛛一出生就可以爬行。
這樣的例子表明,即使是最厲害的無監督算法,也會面臨實際案例上的挑戰。
因此,如果無監督機制無法解釋動物如何在出生時和不久之後就具有如此的領悟能力,那麼對於機器來說,是否有替代方案?但事實是,許多人類感官表達和行爲基本上是天生的。
從進化角度來看,天生的行爲對生存和學習是有利的,而先天與學習策略之間的進化權衡也很有意思。
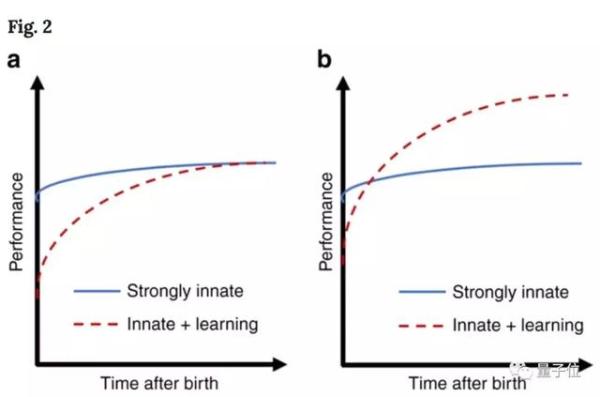
可以看出,通過純先天學習機制而成熟,與通過額外學習的表現有很大不同。
如果環境迅速變化,從時間角度來看,在其他條件相同的情況下,強烈依賴先天機制的物種將勝過採用混合策略的物種。
基因制定人腦神經網絡的佈線規則
我們認爲動物在出生後如此快速運作的主要原因是,它們嚴重依賴於先天機制。這些先天機制已經寫在了在基因編碼裏。基因編碼蘊含了神經系統的佈線規則,這些規則已經被數億年的進化所選擇,也爲動物一生中的學習提供了框架。
那麼基因是如何說明佈線規則的呢?在一些簡單的生物體中,基因組具有指定每個神經元連接的能力。以簡單的線蟲爲例,它有302個神經元和大約7000個突觸。因此在極端情況下,基因可以編碼方式精確地指定神經迴路的連接。
但是在較大型動物的大腦中,例如哺乳動物的大腦,突觸連接不能如此精確地被基因指定,因爲基因根本沒有足夠的能力明確指定每個連接。
人類基因組大約有3×109個核苷酸,因此它可以編碼不超過1GB的信息但是人類大腦每個神經元的神經元數量大約爲1011神經元,需要3.7×1015bits來制定所有連接。
即使人類基因組的每個核苷酸都用於制定大腦連接,信息容量比神經元連接少6個數量級。
因此在大型和稀疏連接的大腦中,大多數信息可能需要指定連接矩陣的非零元素的位置而不是它們的精確值。基因組無法指定顯式制定神經的接線,而必須指定一組規則,用於在孕育過程中連接大腦。
兩點啓發
將上述思考放到當前深度學習的研究當中,已經有了很多新發現:
動物出生後具備快速學習的能力,主要因爲它們天生就有一個高度結構化的大腦連接。後續學習過程中,這種連接就像提供了一個腳手架,在此基礎上快速學習,這種類似的學習理念可能會激發新的方法加速AI研究。
先說第一個。
動物行爲爲天生的而非學習中產生,動物大腦不是白板,相反配備了一個通用的算法,就像當下很多研究人員設想AGI那樣。
動物強選擇性學習,將學習範圍限制在生存必須能力中。
有些觀點認爲動物傾向快速學習具體事情是依賴於AI研究和認知科學中的元學習和歸納偏差。按照這種說法,神經網絡中有一個外循環優化學習機制,產生歸納偏差,讓我們快速學習具體任務。
先天機制的重要性也表明,神經網絡解決新問題會盡可能嘗試那裏以前所有相關問題的解決方案,就像遷移學習那樣。
但遷移學習與大腦中的先天機制有本質區別,前者的連接矩陣很大程度上屬於起點,而在動物體內需要遷移的信息量很小,經過了「瓶頸基因組」,信息的通用性和可塑性更強。
從神經科學的角度來看,應該存在一種更強大的機制,也就是一種轉移學習的泛化,不僅能夠在視覺模式中運作,還能跨模態進行遷移。
第二個結論是,基因組不直接編碼表示或者行爲,也不直接編碼優化原則。
基因組只能編碼佈線規則和模式,然後實例化這些規則和表示。進化的目標,就是不斷優化這些佈線規則,這表明佈線拓撲和網絡架構是人工系統中的優化目標。而傳統的人工神經網絡很大程度上忽略了網絡架構的細節。
目前,人工神經網絡僅利用了其中一小部分可能的網絡架構,還有待發現更強大的、受大腦皮層啓發的架構。
其實現在來看,神經處理過程可以通過神經實驗顯示出來,通過記錄神經活動,間接推斷出神經表徵和佈線。
目前,已經有方法可以直接確定佈線和腦回路,也就是說,大腦皮層連接的細節有可能不久後就會獲取到,併爲神經網絡的研究提供實驗依據。
這些啓發不難讓人聯想起谷歌大腦團隊發佈的新研究。只靠神經網絡架構搜索出的網絡WANN,即權重不可知神經網絡。不訓練,不調參,就能直接執行任務。
它在MNIST數字分類任務上,未經訓練和權重調整,就達到了92%的準確率,和訓練後的線性分類器表現相當,前景無限。
結論
大腦能爲AI研究提供幫助是人工神經網絡研究的基礎。
人工神經網絡試圖捕捉神經系統的關鍵點:許多簡單的神經單元,通過突觸連接並行運行。
人工神經網絡的一些最近的進展也來自神經科學的啓發。比如DeepMind鍾愛的強化學習算法,也誕生過AlphaGo Zero這樣的新研究,這就是從動物學習的研究中汲取靈感的範例。同樣,卷積神經網絡的靈感來自視覺皮層的結構。
但反過來說,AI的進一步發展是否會方便動物大腦的研究,仍然存在爭議。
我們認爲這不太可能,因爲我們對機器的要求,有時被誤導爲通用人工智能,根本不是通用的。
這樣與人類技能類似的能力,只有與大腦類似的機器才能實現它。但機器與人腦的構造完全不同。
飛機的設計起源於鳥,但最後遠優於鳥:飛得更快、適應更高的海拔、更長的距離、具有更大的貨容量。但飛機不能潛入水中捕魚,或者從樹上猛撲去捕鼠。
同樣,現代計算機已經通過一些措施大大超過人類的計算能力,但是無法在定義爲通用AI的明確的任務上與人類能力對應。
如果我們想要設計一個能夠完成人類所有工作的系統,就需要根據相同的設計原則構建它。
傳送門
Nature報道地址:
A critique of pure learning and what artificial neural networks can learn from animal brains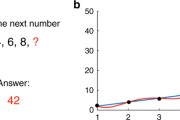
Reddit討論區: