
由於其對於原始數據潛在概率分佈的強大感知能力,GAN 成爲了當下最熱門的生成模型之一。然而,訓練不穩定、調參難度大一直是困擾着 GAN 愛好者的老問題。本文是一份乾貨滿滿的 GAN 訓練心得,希望對有志從事該領域研究和工作的讀者有所幫助!
在當下的深度學習研究領域中,對抗生成網絡(GAN)是最熱門的話題之一。在過去的幾個月裏,關於 GAN 的論文數量呈井噴式增長。GAN 已經被應廣泛應用到了各種各樣的問題上,如果你之前對此並不太瞭解,可以通過下面的 Github 鏈接看到一些酷炫的 GAN 應用:
時至今日,我已經閱讀了大量有關 GAN 的文獻,但我還從來沒有自己動手實踐過。因此,在瀏覽了一些對人有所啓發的論文和 Github 代碼倉庫後,我決定親自嘗試訓練一個簡單的 GAN。不出所料,我立刻就遇到了一些問題。
本文的目標讀者是從 GAN 入門的熱愛深度學習的朋友。除非你走了大運,否則你自己第一次訓練一個 GAN 的過程可能是非常令人沮喪的,而且需要花費好幾個小時才能做好。當然,隨着時間的推移和經驗的增長,你可能會漸漸善於訓練 GAN。但是對於初學者來說,可能會犯一些錯,而且不知道該從哪裏開始調試。在本文中,我想向大家分享我第一次從頭開始訓練 GAN 時的觀察和經驗教訓,希望本文可以幫助大家節省幾個小時的調試時間。
GAN 簡介
在過去的一年左右的時間裏,深度學習圈子裏的每個人(甚至一些沒有參與過深度學習相關工作的人),都應該對 GAN 有所耳聞(除非你住在深山老林裏、與世隔絕)。生成對抗網絡(GAN)是一種數據的生成式模型,主要以深度神經網絡的形式存在。也就是說,給定一組訓練數據,GAN 可以學會估計數據的底層概率分佈。這一點非常有用,因爲我們現在可以根據學到的概率分佈生成原始訓練數據集中沒有出現過的樣本。如上面的鏈接所示,這催生了一些非常實用的應用程序。
該領域的專家已經提供了一些很棒的資源來解釋 GAN 以及它們的工作遠離,所以本文在這裏不會重複他們的工作。但是爲了保持文章的完整性,在這裏對相關概念進行簡要的回顧。
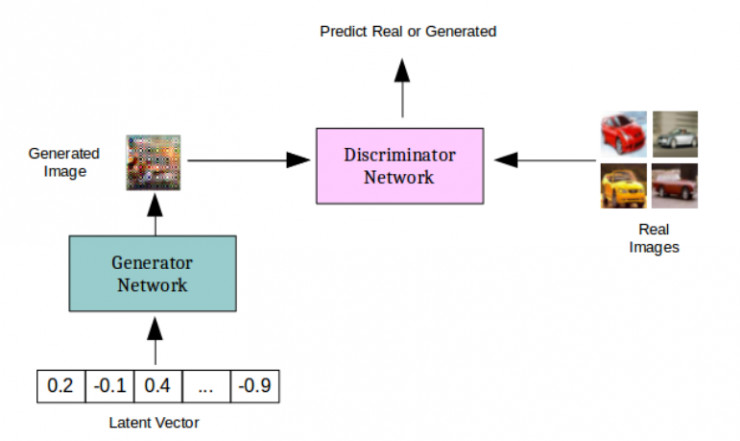
GAN 模型概覽
生成對抗網絡實際上是兩個相互競爭的深度網絡。給定一個訓練集 X(比如說幾千張貓的圖像),生成網絡 G(x) 會將隨機向量作爲輸入,並試圖生成與訓練集中的圖像相類似的新圖像樣本。判別器網絡 D(x) 則是一種二分類器,試圖將訓練集 X 中「真實的」貓的圖像和由生成器生成的「假的」貓圖像區分開來。如此一來,生成網絡的職責就是學習 X 中的數據的分佈,這樣它就可以生成看起來真實的貓圖像,並確保判別器無法區分來自訓練集的貓圖像和來自生成器的貓圖像。判別器則需要通過學習跟上生成器不斷進化、嘗試通過新的方式生成可以「騙過」判別器的「假的」貓圖像的步伐。
最終,如果一切順利,生成器(或多或少)會學到訓練數據的真實分佈,並變得非常善於生成看起來真實的貓圖像。而判別器則不能再將訓練集中的貓圖像和生成的貓圖像區分開來。
從這個意義上說,這兩個網絡一直在努力確保對方不能很好地完成自己的任務。那麼,這究竟是如何起作用的呢?
另一種看待 GAN 的方式是:判別器試圖通過高速生成器真實的貓圖像看起來是怎樣的,從而引導生成器。最終,生成器研究清楚了問題,開始生成看起來真實的貓圖像。訓練 GAN 的方法類似於博弈論中的極大極小算法,兩個網絡試圖達到同時考慮二者的納什均衡。更多細節,請參閱本文底部給出的參考資料。
GAN 訓練面臨的挑戰
下面,我們將繼續分析 GAN 的訓練過程。爲了簡單起見,我使用了「Keras+Tensorflow 後端」的組合,在 MNIST 數據集上訓練了一個 GAN(確切地說是 DC-GAN)。這並不太困難,在對生成器和判別器網絡進行了一些小的調整之後,GAN 就可以生成清晰的 MNIST 圖像了。

生成的 MNIST 數字
如果你覺得 MNIST 中黑白數字沒那麼有趣,那麼生成各種物體和人的彩色圖片還很酷炫的。而這樣一來,問題就變得棘手了。在攻克了 MNIST 數據集之後,顯然下一步就是生成 CIFAR-10 圖像。經過日復一日的超參數調參、改變網絡架構、增添或刪除網絡層,我終於能夠生成出高質量的和 CIFAR-10 類似的圖像。

使用 DC-GAN 生成的青蛙

使用 DC-GAN 生成的汽車
我最初使用了一個非常深的網絡(但是大多數情況下性能並不佳),最後使用的真正有效的網絡卻十分簡單。在我開始調整網絡和訓練過程時,經過 15 個 epoch 的訓練後生成的圖像從這樣:

變成了這樣:

最終的結果是:

下面,我基於自己犯過的錯誤以及一直以來學到的東西,總結出了 7 大規避 GAN 訓練陷阱的法則。所以,如果你是一個 GAN 新兵,在訓練中沒有很多成功的經驗,也許看看下面的幾個方面可能會有所幫助:
鄭重聲明:下面我只是列舉出了我嘗試過的事情以及得到的結果。並且,我並不是說已經解決了所有訓練 GAN 的問題。
1. 更大更多的卷積核
更大的卷積和可以覆蓋前一層特徵圖中的更多像素,因此可以關注到更多的信息。在 CIFAR-10 數據集上,5*5 的卷積核可以取得很好的效果,而在判別器中使用 3*3 的卷積核會使判別器損失迅速趨近於 0。對於生成器來說,我們希望在頂層的卷積層中使用較大的卷積核來保持某種平滑性。而在較底層,我並沒有發現改變卷積核的大小會帶來任何關鍵的影響。
卷積核的數量的提升會大幅增加參數的數量,但通常我們確實需要更多的卷積核。我幾乎在所有的卷積層中都使用了 128 個卷積核。特別是在生成器中,使用較少的卷積核會使得最終生成的圖像太模糊。因此,似乎使用更多的卷積核有助於捕獲額外的信息,最終會提升生成圖像的清晰度。
2. 反轉標籤(Generated=True, Real=False)
儘管這一開始似乎有些奇怪,但是對我來說,改變標籤的分配是一個重要的技巧。
如果你正在使用「真實圖像=1」、「生成圖像=0」的標籤分配方法,將標籤反轉過來會對訓練有所幫助。正如我們會在後文中看到的,這有助於在迭代早期梯度流的傳播,也有助於訓練的順利進行。
3. 軟標籤和帶噪聲標籤
這一點在訓練判別器時極爲重要。使用硬標籤(非 1 即 0)幾乎會在早期就摧毀所有的學習進程,導致判別器的損失迅速趨近於 0。我最終用一個 0-0.1 之間的隨機數來代表「標籤 0」(真實圖像),並使用一個 0.9-1 之間的隨機數來代表 「標籤 1」(生成圖像)。在訓練生成器時則不用這樣做。
此外,添加一些帶噪聲的標籤是有所幫助的。在我的實驗過程中,我將輸入給判別器的圖像中的 5% 的標籤隨機進行了反轉,即真實圖像被標記爲生成圖像、生成圖像被標記爲真實圖像。
4. 批量歸一化有所助益,但還有其它先決條件
批量歸一化當然對提升最終的結果有所幫助。加入批量歸一化可以最終生成明顯更清晰的圖像。但是,如果你錯誤地設置了卷積核的大小和數量,或者判別器損失迅速趨近於 0,那加入批量歸一化可能也無濟於事。

在網絡中加入批量歸一化(BN)層後生成的汽車
5. 一次訓練一類
爲了便於訓練 GAN,確保輸入數據有類似的特性是很有用的。例如,與其在 CIFAR-10 數據集中所有 10 個類別上訓練 GAN,不如選出一個類別(比如汽車或青蛙),訓練 GAN 根據此類數據生成圖像。DCGAN 的另外一些變體可以很好地學會根據若干個類生成圖像。例如,條件 GAN(CGAN)將類別標籤一同作爲輸入,以類別標籤爲先驗條件生成圖像。但是,如果你從一個基礎的 DCGAN 開始學習訓練 GAN,最好保持模型簡單。
6. 觀察梯度的變化
如果可能的話,請監控網絡中的梯度和損失變化。這可以幫助我們瞭解訓練的進展情況。如果訓練進展不是很順利的話,這甚至可以幫助我們進行調試。
理想情況下,生成器應該在訓練的早期接受大梯度,因爲它需要學會如何生成看起來真實的數據。另一方面,判別器則在訓練早期則不應該總是接受大梯度,因爲它可以很容易地區分真實圖像和生成圖像。當生成器訓練地足夠好時,判別器就沒有那麼容易區分真實圖像和生成圖像了。它會不斷髮生錯誤,並得到較大的梯度。
我在 CIFAR-10 中的汽車上訓練的幾個早期版本的 GAN 有許多卷積層和批量歸一化層,並且沒有進行標籤反轉。除了監控梯度的變化趨勢,監控梯度的大小也很重要。如果生成器中網絡層的梯度太小,學習可能會很慢或者根本不會進行學習。
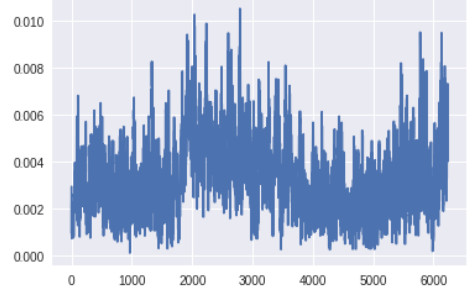
生成器頂層的梯度(x 軸:minibatch 迭代次數)
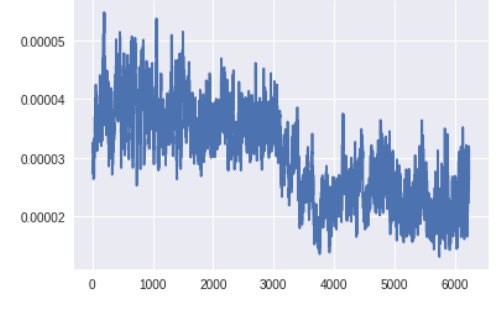
生成器底層的梯度(x 軸:minibatch 迭代次數)
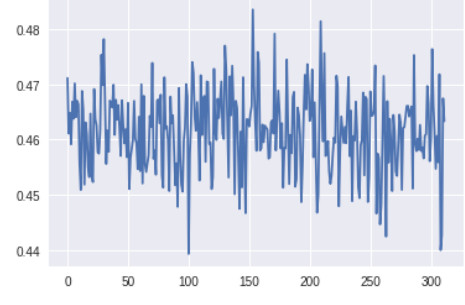
判別器頂層的梯度(x 軸:minibatch 迭代次數)
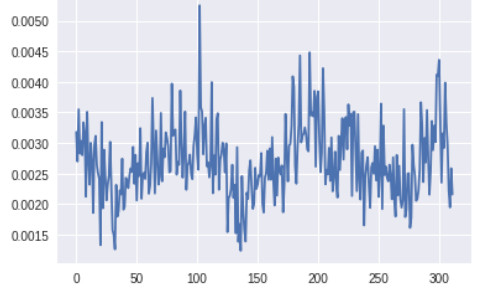
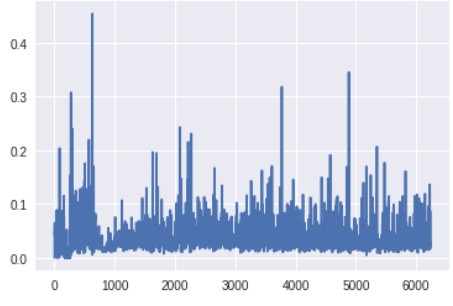
判別器底層的梯度(x 軸:minibatch 迭代次數)
生成器最底層的梯度太小,無法進行任何的學習。判別器的梯度自始至終都沒有變化,說明判別器並沒有真正學到任何東西。現在,讓我們將其與帶有上述所有改進方案的 GAN 的梯度進行對比,改進後的 GAN 得到了很好的、與真實圖像看起來類似的圖像:
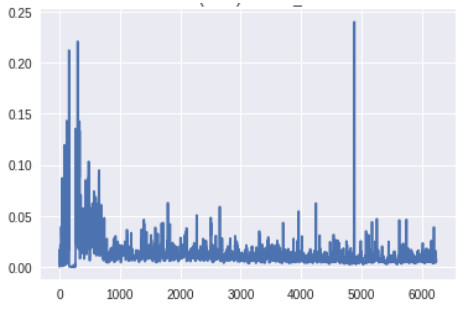
生成器頂層的梯度(x 軸:minibatch 迭代次數)
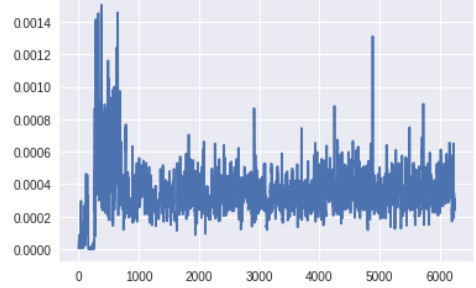
生成器底層的梯度(x 軸:minibatch 迭代次數)
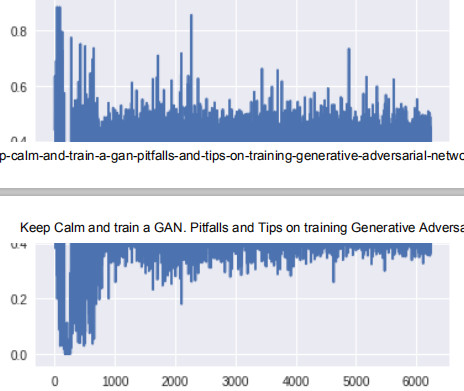
判別器頂層的梯度(x 軸:minibatch 迭代次數)
判別器底層的梯度(x 軸:minibatch 迭代次數)
此時生成器底層的梯度明顯要高於之前版本的 GAN。此外,隨着訓練的進展,梯度流的變化趨勢與預期一樣:生成器在訓練早期梯度較大,而一旦生成器被訓練得足夠好,判別器的頂層就會維持高的梯度。
7.不要採用早停法(early stopping)
可能是由於我缺乏耐心,我犯了一個愚蠢的錯誤——在進行了幾百個 minibatch 的訓練後,當我看到損失函數仍然沒有任何明顯的下降,生成的樣本仍然充滿噪聲時,我終止了訓練。比起等到訓練結束才意識到網絡什麼都沒有學到,重新開始工作、節省時間確實讓人心動。GAN 的訓練時間很長,初始的少量的損失值和生成的樣本幾乎不能顯示出任何趨勢和進展。在結束訓練過程並調整設置之前,還是很有必要等待一段時間的。
這條規則的一個例外情況是:如果你看到判別器損失迅速趨近於 0。如果發生了這種情況,幾乎就沒有任何機會補救了。最好在對網絡或訓練過程進行調整後重新開始訓練。
最終的 GAN 的架構如下所示:
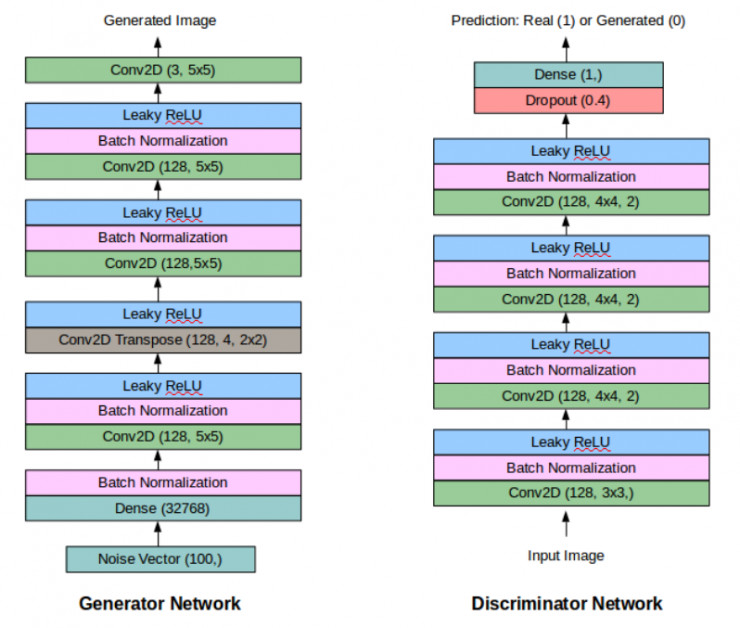
希望本文中的這些建議可以幫助所有人從頭開始訓練他們的第一個 DC-GAN。下面,本文將給出一些包含大量關於 GAN 的信息的學習資源:
GAN 論文參考:
「Generative Adversarial Networks」
「Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks」
「Improved Techniques for Training GANs」
其他參考鏈接:
「Training GANs: Better understanding and other improved techniques」
「NIPS 2016 GAN 教程」
「Conditional GAN」
本文最終版 GAN 的 Keras 代碼鏈接如下:
https://github.com/utkd/gans/blob/master/cifar10dcgan.ipynb?source=post_page