一隻萌新,想把自己修煉成一個成熟的NLP研究人員,要經過一條怎樣的路?
有個名叫Tae-Hwan Jung的韓國小夥伴,做了一份完整的思維導圖,從基礎概念開始,到NLP的常用方法和著名算法,知識點全面覆蓋。
可以說,從0到1,你需要的都在這裏了:

這份精緻的資源剛剛上線,不到一天Reddit熱度就超過400,獲得了連篇的讚美和謝意:
「肥腸感謝。」「我需要的就是這個!」「哇,真好啊!」

所以,這套豐盛的思維導圖,都包含了哪些內容?
四大版塊
就算你從前什麼都不知道,也可以從第一個版塊開始入門:
1 概率&統計
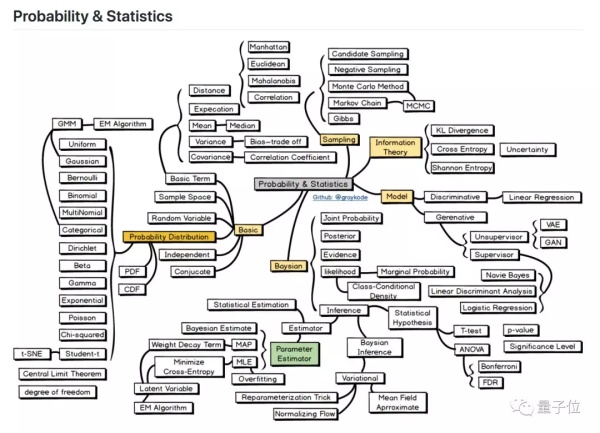
從中間的灰色方塊,發散出5個方面:
基礎 (Basic) ,採樣 (Sampling) 、信息理論 (Information Theory) 、模型 (Model) ,以及貝葉斯 (Bayesian) 。
每個方面,都有許多知識點和方法,需要你去掌握。
畢竟,有了概率統計的基礎,才能昂首挺胸進入第二個板塊。
2 機器學習
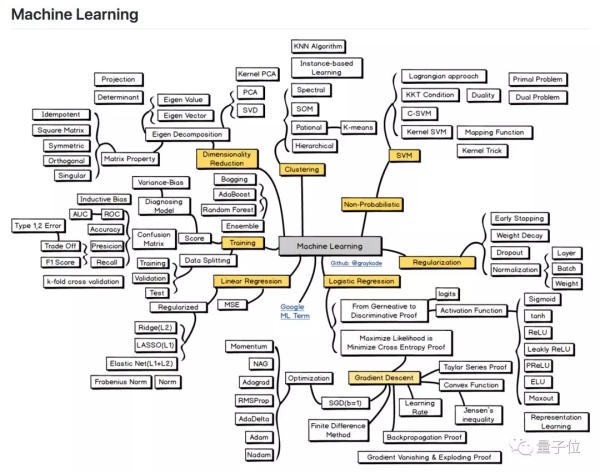
這個版塊,一共有7個分支:
線性迴歸 (Linear Regression) 、邏輯迴歸 (Logistic Regression) 、正則化 (Regularization) 、非概率 (Non-Probabilistic) 、聚類 (Clustering) 、降維 (Dimensionality Reduction) ,以及訓練 (Training) 。
掌握了機器學習的基礎知識和常用方法,再正式向NLP進發。
3 文本挖掘
文本挖掘,是用來從文本里獲得高質量信息的方法。
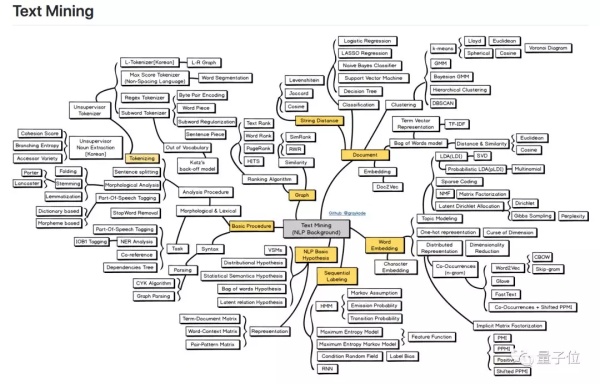
圖上有6個分支:
基本流程 (Basic Procedure) 、圖 (Graph) 、文檔 (Document) 、詞嵌入 (Word Embedding)、序列標註 (Sequential Labeling) ,以及NLP基本假設 (NLP Basic Hypothesis)。
彙集了NLP路上的各種必備工具。
4 自然語言處理
裝備齊了,就該實踐了。這也是最後一張圖的中心思想:
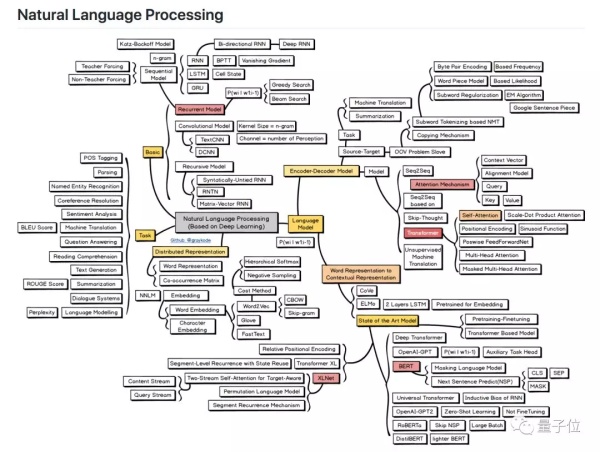
雖然只有4個分支,但內容豐盛。
一是基礎 (Basic) ,詳細梳理了NLP常用的幾類網絡:循環模型、卷積模型和遞歸模型。
二是語言模型 (Language Model) ,包含了編碼器-解碼器模型,以及詞表徵到上下文表徵 (Word Representation to Contextual Representation) 這兩部分。許多著名模型,比如BERT和XLNet,都是在這裏得到了充分拆解,也是你需要努力學習的內容。
三是分佈式表徵 (Distributed Representation) ,許多常用的詞嵌入方法都在這裏,包括GloVe和Word2Vec,它們會一個個變成你的好朋友。
四是任務 (Task) ,機器翻譯、問答、閱讀理解、情緒分析……你已經是合格的NLP研究人員了,有什麼需求,就調教AI做些什麼吧。
看完腦圖,有人問了:是不是要把各種技術都實現一下?
韓國少年說:
不不,你不用把這些全實現一遍。找一些感覺有趣的,實現一波就好了。

One More Thing
Reddit樓下,許多小夥伴對這套腦圖表示膜拜,並且想知道是用什麼做的。
韓國少年說,Balsamiq Mockups。
GitHub傳送門:

Reddit傳送門: