隨着NLP的不斷發展,對BERT/Transformer相關知識的研(mian)究(shi)應(ti)用(wen),也越來越細節,下面嘗試用QA的形式深入不淺出BERT/Transformer的細節知識點。
1、不考慮多頭的原因,self-attention中詞向量不乘QKV參數矩陣,會有什麼問題?
2、爲什麼BERT選擇mask掉15%這個比例的詞,可以是其他的比例嗎?
3、使用BERT預訓練模型爲什麼最多隻能輸入512個詞,最多隻能兩個句子合成?
4、爲什麼BERT在第一句前會加一個[CLS]標誌?
5、Self-Attention 的時間複雜度是怎麼計算的?
6、Transformer在哪裏做了權重共享,爲什麼可以做權重共享?
7、BERT非線性的來源在哪裏?
8、BERT的三個Embedding直接相加會對語義有影響嗎?
9、Transformer的點積模型做縮放的原因是什麼?
10、在BERT應用中,如何解決長文本問題?
1、不考慮多頭的原因,self-attention中詞向量不乘QKV參數矩陣,會有什麼問題?
Self-Attention的核心是用文本中的其它詞來增強目標詞的語義表示,從而更好的利用上下文的信息。
self-attention中,sequence中的每個詞都會和sequence中的每個詞做點積去計算相似度,也包括這個詞本身。
如果不乘QKV參數矩陣,那這個詞對應的q,k,v就是完全一樣的。
在相同量級的情況下,qi與ki點積的值會是最大的(可以從「兩數和相同的情況下,兩數相等對應的積最大」類比過來)。
那在softmax後的加權平均中,該詞本身所佔的比重將會是最大的,使得其他詞的比重很少,無法有效利用上下文信息來增強當前詞的語義表示。
而乘以QKV參數矩陣,會使得每個詞的q,k,v都不一樣,能很大程度上減輕上述的影響。
當然,QKV參數矩陣也使得多頭,類似於CNN中的多核,使捕捉更豐富的特徵/信息成爲可能。
2、爲什麼BERT選擇mask掉15%這個比例的詞,可以是其他的比例嗎?
BERT採用的Masked LM,會選取語料中所有詞的15%進行隨機mask,論文中表示是受到完形填空任務的啓發,但其實與CBOW也有異曲同工之妙。
從CBOW的角度,這裏 有一個比較好的解釋是:在一個大小爲
的窗口中隨機選一個詞,類似CBOW中滑動窗口的中心詞,區別是這裏的滑動窗口是非重疊的。
上述非官方解釋,是來自我的一位朋友。那從CBOW的滑動窗口角度,10%~20%都是還ok的比例。
3、使用BERT預訓練模型爲什麼最多隻能輸入512個詞,最多隻能兩個句子合成一句?
這是Google BERT預訓練模型初始設置的原因,前者對應Position Embeddings,後者對應Segment Embeddings
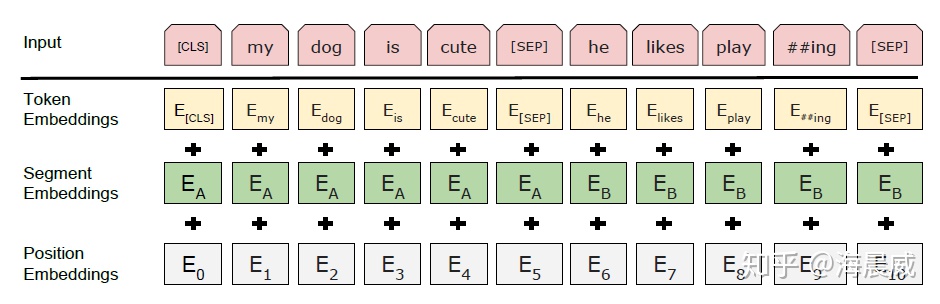
在BERT中,Token,Position,Segment Embeddings 都是通過學習來得到的,pytorch代碼中它們是這樣的
self.word_embeddings = Embedding(config.vocab_size, config.hidden_size)self.position_embeddings = Embedding(config.max_position_embeddings, config.hidden_size)self.token_type_embeddings = Embedding(config.type_vocab_size, config.hidden_size)而在BERT config中
"max_position_embeddings": 512"type_vocab_size": 2因此,在直接使用Google 的BERT預訓練模型時,輸入最多512個詞(還要除掉[CLS]和[SEP]),最多隻能兩個句子合成一句。
當然,如果有足夠的硬件資源自己重新訓練BERT,可以更改 BERT config,設置更大max_position_embeddings 和 type_vocab_size值去滿足自己的需求。
4、爲什麼BERT在第一句前會加一個[CLS]標誌?
BERT在第一句前會加一個[CLS]標誌,最後一層該位對應向量可以作爲整句話的語義表示,從而用於下游的分類任務等。
爲什麼選它呢,因爲與文本中已有的其它詞相比,這個無明顯語義信息的符號會更「公平」地融合文本中各個詞的語義信息,從而更好的表示整句話的語義。
這裏補充一下bert的輸出,有兩種:
一種是get_pooled_out(),就是上述[CLS]的表示,輸出shape是[batch size,hidden size]。
一種是get_sequence_out(),獲取的是整個句子每一個token的向量表示,輸出shape是[batch_size, seq_length, hidden_size],這裏也包括[CLS],因此在做token級別的任務時要注意它。
5、Self-Attention 的時間複雜度是怎麼計算的?
Self-Attention時間複雜度: ,這裏,n是序列的長度,d是embedding的維度。
Self-Attention包括三個步驟:相似度計算,softmax和加權平均,它們分別的時間複雜度是:
相似度計算可以看作大小爲(n,d)和(d,n)的兩個矩陣相乘: ,得到一個(n,n)的矩陣
softmax就是直接計算了,時間複雜度爲
加權平均可以看作大小爲(n,n)和(n,d)的兩個矩陣相乘: ,得到一個(n,d)的矩陣
因此,Self-Attention的時間複雜度是 。
6、Transformer在哪裏做了權重共享,爲什麼可以做權重共享?
Transformer在兩個地方進行了權重共享:
(1)Encoder和Decoder間的Embedding層權重共享;
(2)Decoder中Embedding層和FC層權重共享。
對於(1),《Attention is all you need》中Transformer被應用在機器翻譯任務中,源語言和目標語言是不一樣的,但它們可以共用一張大詞表,對於兩種語言中共同出現的詞(比如:數字,標點等等)可以得到更好的表示,而且對於Encoder和Decoder,嵌入時都只有對應語言的embedding會被激活,因此是可以共用一張詞表做權重共享的。
論文中,Transformer詞表用了bpe來處理,所以最小的單元是subword。英語和德語同屬日耳曼語族,有很多相同的subword,可以共享類似的語義。而像中英這樣相差較大的語系,語義共享作用可能不會很大。
但是,共用詞表會使得詞表數量增大,增加softmax的計算時間,因此實際使用中是否共享可能要根據情況權衡。
該點參考:https://www.zhihu.com/question/333419099/answer/743341017
對於(2),Embedding層可以說是通過onehot去取到對應的embedding向量,FC層可以說是相反的,通過向量(定義爲 x)去得到它可能是某個詞的softmax概率,取概率最大(貪婪情況下)的作爲預測值。
那哪一個會是概率最大的呢?在FC層的每一行量級相同的前提下,理論上和 x 相同的那一行對應的點積和softmax概率會是最大的(可類比本文問題1)。
因此,Embedding層和FC層權重共享,Embedding層中和向量 x 最接近的那一行對應的詞,會獲得更大的預測概率。實際上,Decoder中的Embedding層和FC層有點像互爲逆過程。
通過這樣的權重共享可以減少參數的數量,加快收斂。
但開始我有一個困惑是:Embedding層參數維度是:(v,d),FC層參數維度是:(d,v),可以直接共享嘛,還是要轉置?其中v是詞表大小,d是embedding維度。
查看 pytorch 源碼發現真的可以直接共享:
fc = nn.Linear(d, v, bias=False) # Decoder FC層定義weight = Parameter(torch.Tensor(out_features, in_features)) # Linear層權重定義Linear 層的權重定義中,是按照 (out_features, in_features) 順序來的,實際計算會先將 weight 轉置在乘以輸入矩陣。所以 FC層 對應的 Linear 權重維度也是 (v,d),可以直接共享。
7、BERT非線性的來源在哪裏?
前饋層的gelu激活函數和self-attention,self-attention是非線性的,感謝評論區指出。
還有幾個問題也非常好,值得重點關注,但網上已經有很好的解答了,如下:
8、BERT的三個Embedding直接相加會對語義有影響嗎?
參考:https://www.zhihu.com/question/374835153
9、Transformer的點積模型做縮放的原因是什麼?
參考:https://www.zhihu.com/question/339723385
10、在BERT應用中,如何解決長文本問題?
參考:https://www.zhihu.com/question/327450789