 是否曾經幻想過能和自己的私人助理對話或是漫無邊際地探討任何問題?多虧
機器學習和
深度神經網絡,你曾經的幻想很快會變成現實。讓我們來看一下Apple的Siri或
亞馬遜的Alexa所展示的這一神奇功能吧。
不要太激動,我們在下面一系列帖子中,創建的不是一個無所不能的
人工智能,而是
創建一個簡單的聊天機器人,預先些輸入一些信息,它能夠對此類信息相關的問題做出是或否的回答。
它遠不及Siri或Alexa,但它卻能很好地說明:即使使用非常簡單的
深度神經網絡架構,也可以獲得不錯的結果。在這篇文章中,我們將學習
人工神經網絡,深度學習,遞歸神經網絡和長短期記憶網絡。在下一篇文章中,我們將在真實項目中利用它來回答問題
在開始討論
神經網絡之前,先仔細看看下面的圖像。其中有兩張圖片:其中一張圖片是一輛校車行駛通過馬路,另一張圖片是是普通的起居室,這兩張圖片都有
人工註釋人員對其進行了描述。
是否曾經幻想過能和自己的私人助理對話或是漫無邊際地探討任何問題?多虧
機器學習和
深度神經網絡,你曾經的幻想很快會變成現實。讓我們來看一下Apple的Siri或
亞馬遜的Alexa所展示的這一神奇功能吧。
不要太激動,我們在下面一系列帖子中,創建的不是一個無所不能的
人工智能,而是
創建一個簡單的聊天機器人,預先些輸入一些信息,它能夠對此類信息相關的問題做出是或否的回答。
它遠不及Siri或Alexa,但它卻能很好地說明:即使使用非常簡單的
深度神經網絡架構,也可以獲得不錯的結果。在這篇文章中,我們將學習
人工神經網絡,深度學習,遞歸神經網絡和長短期記憶網絡。在下一篇文章中,我們將在真實項目中利用它來回答問題
在開始討論
神經網絡之前,先仔細看看下面的圖像。其中有兩張圖片:其中一張圖片是一輛校車行駛通過馬路,另一張圖片是是普通的起居室,這兩張圖片都有
人工註釋人員對其進行了描述。

圖中爲兩個不同的圖像,附有人工註釋人員對其進行的描述
好了,讓我們繼續吧!
開始 - 人工神經網絡
爲了構建一個用於創建
聊天機器人的
神經網絡模型,會用到一個非常流行的
神經網絡Python庫:Keras。然而,在進一步研究之前,首先應瞭解人工
神經網絡(ANN)是什麼。
人工
神經網絡是一種
機器學習模型,它試圖模仿人類大腦的功能,它由連接在一起的大量
神經元構建而成- 因此命名爲「人工
神經網絡」。
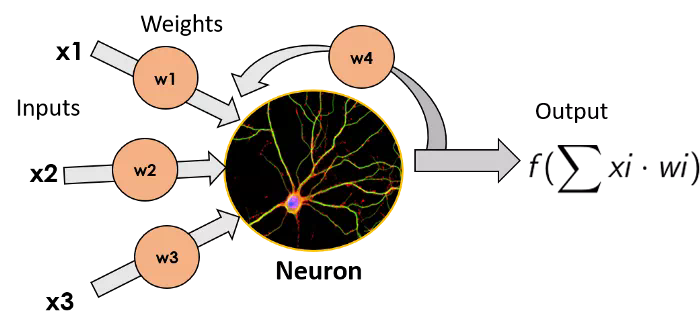
感知器
最簡單的ANN模型由單個神經元組成, Star-Trek將之命名爲感知器(Perceptron)。它由弗朗克·羅森布拉特(Frank Rossenblatt)於1957年發明,它包括一個簡單的神經元,對輸入的加權和進行函數變換(在生物神經元中是枝狀突起),並輸出其結果(輸出將等同於生物神經元的軸突)。我們不在這裏深入研究用到的函數變換的細節,因爲這篇文章的目的不是成爲專家,而只是需要了解神經網絡的工作原理。
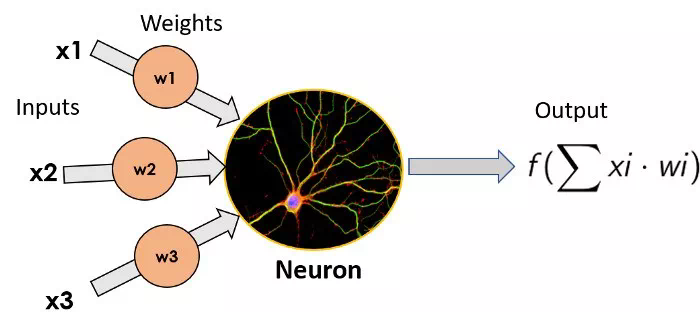 單個神經元的圖像,左邊爲輸入,乘以每個輸入的權重,神經元將函數變換應用於輸入的加權和並輸出結果這些單獨的神經元可以堆疊起來,形成包含不同個數神經元的層,這些層可以順序地相鄰放置,從而使得網絡更深。
單個神經元的圖像,左邊爲輸入,乘以每個輸入的權重,神經元將函數變換應用於輸入的加權和並輸出結果這些單獨的神經元可以堆疊起來,形成包含不同個數神經元的層,這些層可以順序地相鄰放置,從而使得網絡更深。
當以這種方式構建網絡時,不屬於輸入層或輸出層的
神經元叫做隱藏層,正如它們的名稱所描述:隱藏層是一個黑盒模型,這也正是ANN的主要特徵之一。通常我們對其中的數學原理以及黑盒中發生的事情有一些認知,但是如果僅通過隱藏層的輸出試圖理解它,我們大腦可能不夠用。
儘管如此,ANN卻能輸出很好的結果,因此不會有人抱怨這些結果缺乏可解釋性。
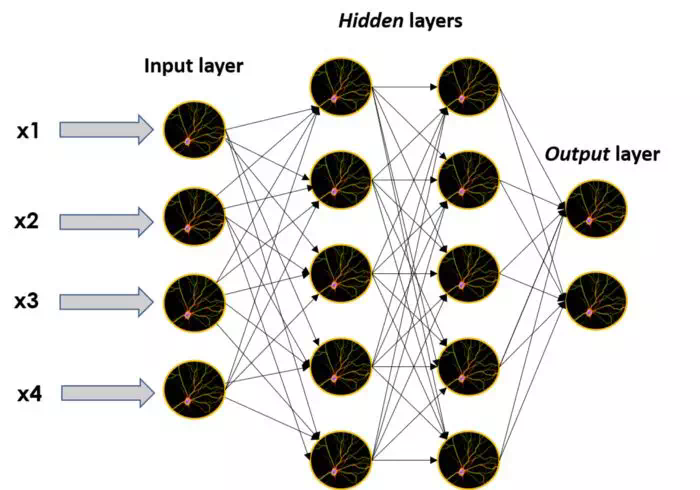
大的
神經網絡的圖像,由許多單獨的
神經元和層組成:一個輸入層,兩個隱藏層和一個輸出層
神經網絡結構以及如何訓練一個神經網絡,已爲人所知有二十多年了。那麼,又是什麼原因導致了當今對人工神經網絡和深度學習的火爆和炒作?下面我們會給出問題的答案,但在此之前,我們先了解一下深度學習的真正含義。
什麼是深度學習?
從它的名稱可以猜測到,深度學習使用多個層逐步從提供給神經網絡的數據中提取出更高級別的特徵。這個道理很簡單:使用多個隱藏層來增強神經模型的性能。
明白了這一點之後,上面問題的答案便簡單了:
規模。在過去的二十年中,各種類型的可用數據量以及我們的數據存儲和處理機器(即,計算機)的功能都呈指數級增長。
計算力的增加,以及用於訓練模型的可用數據量的大量增加,使我們能夠創建更大、更深的
神經網絡,這些
深度神經網絡的性能優於較小的
神經網絡。
Andrew Ng是世界領先的
深度學習專家之一,他在本視頻中明確了這一點。在這個視頻(https://www.youtube.com/watch?v=O0VN0pGgBZM&t=576s)中,他展示了與下面圖像類似的一副圖像,並用它解釋了利用更多數據來訓練模型的優勢,以及大型
神經網絡與其他
機器學習模型相比較的優勢。
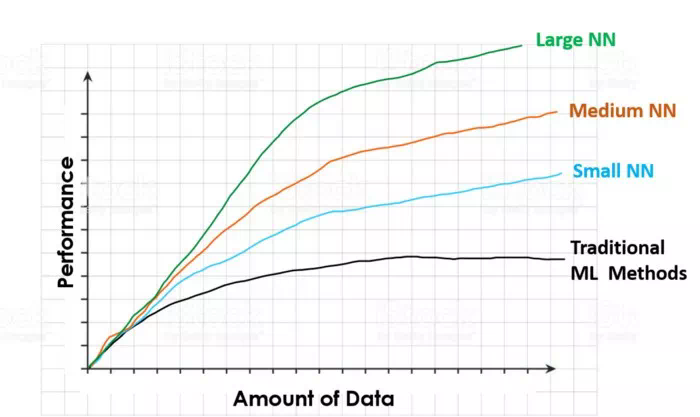 圖像顯示了當訓練數據集增大時,不同算法的性能演變傳統的機器學習算法(線性或邏輯迴歸,SMV,隨機森林等)的性能會隨着訓練數據集的增大而增加,但是當數據集增大到某一點之後,算法的性能會停止上升。數據集大小超過這一值之後,即便爲模型提供了更多的數據,傳統模型卻不知道如何去處理這些附加的數據,從而性能得不到進一步的提高。
圖像顯示了當訓練數據集增大時,不同算法的性能演變傳統的機器學習算法(線性或邏輯迴歸,SMV,隨機森林等)的性能會隨着訓練數據集的增大而增加,但是當數據集增大到某一點之後,算法的性能會停止上升。數據集大小超過這一值之後,即便爲模型提供了更多的數據,傳統模型卻不知道如何去處理這些附加的數據,從而性能得不到進一步的提高。
神經網絡則不然,這種情況永遠不會發生。
神經網絡的性能總是隨着數據量的增加而增加(當然,前提是這些數據質量良好),隨着網絡大小的增加,訓練的速度也會加快。因此,如果想要獲得最佳性能,則需要在X軸右側(高數據量)的綠線(大
神經網絡)的某個位置。
此外,雖然還需要有一些算法上的改進,但是
深度學習和人工
神經網絡興起的主要因素便是規模:
計算規模和數據規模。
傑夫·迪恩(Jeff Dean)(谷歌
深度學習的煽動者之一)是該領域的另一個重要人物,關於
深度學習,傑夫如是說:
當聽到
深度學習這個詞時,便會想到一個大的
深度神經網絡。深度通常指的是層數比較多,這是出版物中的一個流行術語,此刻,我便視它爲
深度神經網絡。
在談論
深度學習時,傑夫強調了
神經網絡的可擴展性,即隨着數據量的增大,模型規模的增大,模型輸出的結果會越來越好,同時,訓練的計算量也隨之增大,這和先前看到的結果一致。
好了,理解了原理之後,那麼神經網絡如何進行深度學習的呢?
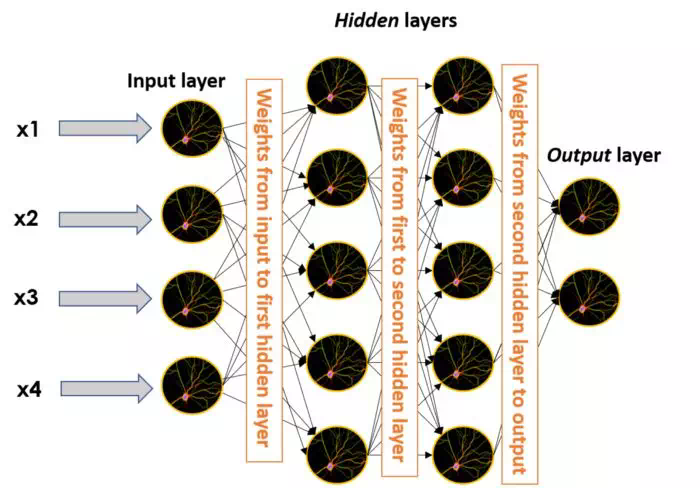
還記得將多個輸入乘以
權重之後輸入到
感知器中嗎?連接兩個不同
神經元的「邊」(連接)也需要賦
權重。這意味着在較大的
神經網絡中,
權重也存在於每個黑箱邊之中,取一個
神經元的輸出,與其相乘,然後將其作爲輸入提供給這個邊緣所連接的另一個
神經元。
當訓練神經網絡(通過ML表達式來訓練神經網絡使其進行學習)時,首先爲它提供一組已知數據(在ML中稱爲標記數據),讓它預測這些數據的特徵(比如圖像標記「狗」或「貓」)然後將預測結果與實際結果進行比對。
當這個過程在進行中出現錯誤時,它會調整
神經元之間連接的
權重,以減少所犯錯誤的數量。正因如此,如前所示,在大多數情況下,如果我們爲網絡提供更多的數據,將會提高它的性能。
從序列數據中學習 –遞歸神經網絡
瞭解了人工
神經網絡和
深度學習之後,我們懂得了
神經網絡是如何進行學習的,現在可以開始研究用於構建
聊天機器人的
神經網絡:遞歸
神經網絡或RNN 。
遞歸
神經網絡是一種特殊的
神經網絡,旨在有效地處理序列數據,序列數據包括時間序列(在一定時間段內的
參數值列表)、文本文檔(可以視爲單詞序列)或音頻(可視爲聲音頻率序列)。
RNN獲取每個
神經元的輸出,並將其作爲輸入反饋給它,它不僅在每個時間步長中接收新的信息,並且還向這些新信息中添加先前輸出的加權值,從而,這些
神經元具備了先前輸入的一種「記憶」,並以某種方式將量化輸出反饋給
神經元。
遞歸
神經元,輸出數據乘以一個
權重並反饋到輸入中
RNN存在的問題是:隨着時間的流逝,RNN獲得越來越多的新數據,他們開始「遺忘」有關數據,通過
激活函數的轉化及與
權重相乘,稀釋新的數據。這意味着RNN有一個很好的短期記憶,但在嘗試記住前一段時間發生過的事情時,仍然會存在一些小問題(過去若干時間步長內的數據)。
爲此,需要某種長期記憶,LSTM正是提供了長期記憶的能力。
增強記憶力 - 長期短期記憶網絡
長短期記憶網絡LSTM是RNN的一種變體,可解決前者的長期記憶問題。作爲本文的結尾,簡要解釋它是如何工作的。
與普通的遞歸
神經網絡相比,它們具有更爲複雜的記憶單元結構,從而使得它們能夠更好地調節如何從不同的輸入源學習或遺忘。
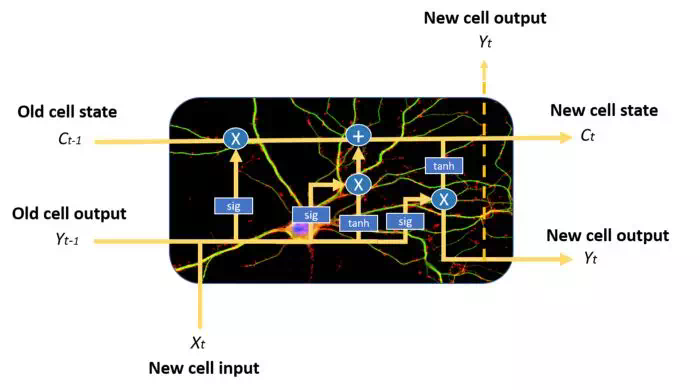
LSTM記憶單元示例。注意藍色圓圈和方框,可以看出它的結構比普通的RNN單元更復雜,我們將不在本文中介紹它
LSTM神經元通過三個不同的門的狀態組合來實現這一點:輸入門,遺忘門和輸出門。在每個時間步長中,記憶單元可以決定如何處理狀態向量:從中讀取,寫入或刪除它,這要歸功於明確的選通機制。利用輸入門,記憶單元可以決定是否更新單元狀態;利用遺忘門,記憶單元可以刪除其記憶;通過輸出門,單元細胞可以決定輸出信息是否可用。
LSTM還可以減輕梯度消失的問題,但這不在此做詳細介紹。
就是這樣!現在我們對這些不同種類的
神經網絡已經有了一個初淺的認識,下面可以開始用它來構建第一個
深度學習項目!
結論
神經網絡會非常神奇。在下一篇文章中,我們將看到,即便是一個非常簡單的結構,只有幾個層便可以創建一個非常強大的聊天機器人。哦,順便問一下,記得這張照片嗎?
 由神經網絡創建的帶有簡短文本描述的兩幅不同圖像爲了證明深度神經網絡是多麼酷,不得不承認,我對如何產生這些圖像的描述撒了謊。
由神經網絡創建的帶有簡短文本描述的兩幅不同圖像爲了證明深度神經網絡是多麼酷,不得不承認,我對如何產生這些圖像的描述撒了謊。
記得在本文的開頭,曾說明這些描述是人工註釋的,然而實際上,
每幅圖像上所的簡短文本實際上都是人工神經網絡生成的。
如果想要學習如何使用
深度學習來創建一個神奇的
聊天機器人,請在媒體上追隨我,並繼續關注我的下一篇文章!然後,盡情享受
人工智能!
其它資源
本帖中描述的概念解釋非常初淺,如果想深入學習,請參考以下附加的資源。
神經網絡如何端到端地工作
https://end-to-end-machine-learning.teachable.com/courses/how-deep-neural-networks-work/lectures/9533963
YouTube視頻系列,講解如何訓練神經網絡的主要概念
https://www.youtube.com/watch?v=sZAlS3_dnk0
深度學習和人工神經網絡
https://machinelearningmastery.com/what-is-deep-learning/
好啦,希望你喜歡這個帖子。可以在LinkedIn上與我聯繫,或在@jaimezorno的Twitter上跟我聯繫。此外,還可以在此處查看我的關於
數據科學和
機器學習的其它帖子。學習快樂!
Jaime Zornoza是一名工業工程師,擁有電子專業的學士學位和計算機科學的碩士學位。原創。經許可轉載。
原文標題:
Deep Learning for NLP: ANNs, RNNs and LSTMs explained!
原文鏈接:
https://www.kdnuggets.com/2019/08/deep-learning-nlp-explained.html