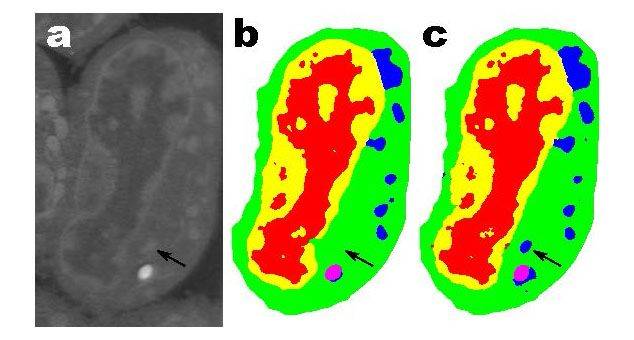
小鼠淋巴母細胞的切片。(a)原始圖像;(b)人工切割得到的切片;(c)100 層的 MS-D 網絡的輸出(數據來自 A.Ekman, C. Larabell, National Center for X-ray Tomography)
能源部勞倫斯伯克利國家實驗室(Berkeley Lab)的數學家們開發了一種針對實驗性成像數據的新的機器學習方法。這種新方法不像典型的機器學習方法一樣需要數萬或數十萬張圖像用於訓練——它可以在使用更少的圖像的同時,更快地進行學習。
伯克利實驗室的 CAMERA(能源高級數學研究與應用中心,Center for Advanced Mathematics for Energy Research Applications)的 Daniël Pelt 和 James Sethian 開發了一種新算法,他們將這種算法稱爲「多尺度密集卷積神經網絡」(MS-D,Mixed-Scale Dense Convolution Neural Network)。這種新方法與傳統方法相比,需要的參數更少,收斂得也更快,而且可以基於相當小的訓練集進行「學習」。這種方法已用於從細胞圖像中提取生物結構,還打算爲多個研究領域提供新的數據分析的計算工具。
隨着實驗設備可以更快地產生更高分辨率的圖像,科學家們可能難以通過人工方式對產生數據進行管理和分析。2014 年,Sethian 在伯克利實驗室成立了 CAMERA。CAMERA 是一個集成了許多交叉學科的中心,成立目的在於開發美國能源部科學用戶設備辦公室的實驗探索所需的基礎數學方法。CAMERA 是該實驗室計算研究部門的一部分。
Sethian 同時也是 UC Berkeley 的數學教授,他認爲:「在科學應用中,需要大量人力對實驗圖像進行註釋和標記——可能需要幾周才能得到一些批註過的圖像。我們的目標是開發一項可以通過很小的數據集進行學習的新技術。」
該算法的相關論文發表於 2017 年 12 月 26 日的美國國家科學院院刊上(見文末)。
Pelt 是荷蘭數學與計算科學研究所下屬的計算成像小組的成員,他介紹說:「這項突破源於我們意識到,不同圖像尺度的特徵提取的縮放運算,可以用能處理多個尺度的數學卷積的一層所代替。」
爲了得到更廣泛的應用,Olivia Jain 和 Simon Mo 領導的伯克利團隊建立了門戶網站「圖像數據標記引擎(SlideCAM,Segmenting Labeled Image Data Engine)」
該算法還可用於理解生物細胞內部結構,這一應用也非常有前景。使用 Pelt 和 Sethian 的 MS-D 方法,僅需要七個細胞的數據,就可確定該細胞的內部結構。
國家 X 射線斷層成像中心主任、加利福尼亞大學舊金山醫學院的教授 Carolyn Larabell 說:「我們實驗室中的主要工作是瞭解細胞的形態結構是如何影響和控制細胞行爲的。我們花費無數小時手動分割細胞,以提取細胞結構並識別細胞間的差異,如識別健康細胞和病變細胞間的差異。新算法可能徹底改變我們對疾病的認知能力,而這種算法也是繪製人類細胞圖譜的主要工具,繪製人類細胞圖譜是扎克伯格和他的夫人贊助的一項全球合作項目,旨在繪製出健康人體中所有的細胞。」
國家 X 射線斷層成像中心位於 ALS(Advanced Light Source,先進光源實驗室),伯克利實驗室的美國能源部科學用戶設備辦公室。
從更少數據中獲得更多科學
圖像無處不在。智能手機和傳感器已經產生了大量的圖片,這些圖片中已經有很多標明瞭圖片內容的相關信息。通過龐大的交叉參考圖像的數據庫,卷積神經網絡和其他機器學習算法已經徹底改變了我們快速識別自然圖像的能力(類似於曾經見過和分類過的圖像)。
這些方法需要數以百萬標記過的圖像數據,需要使用超級計算機花費大量的時間進行訓練,還需要調整一系列隱藏的內部參數進行「學習」。但是如果沒有那麼多標記過的圖像呢?在許多領域,想要這樣的數據集都是一個奢侈的願望。生物學家記錄下細胞圖像,手動標記出細胞的邊界和結構:對他們而言,爲得到一個完整獨立的細胞的三維結構而花費好幾周是一件稀鬆平常的事情。材料學家利用斷層重建技術對岩石和材料進行對比,手動對不同區域進行標記,辨認出裂縫、斷口和空隙。不同但重要的結構間的差異往往都會非常小,而數據中的噪聲會將特徵掩飾起來,並會使最好的算法以及人類產生混淆。
對於傳統的機器學習方法而言,這些珍貴的手工標記的圖像遠遠不夠。爲了迎接這一挑戰,CAMERA 的數學家們用非常有限的數據解決了這一問題。爲了用更低的成本獲得更高的收益,他們的目標是建立一組高效的數學「算符」,可以大規模減少參數數量。這些數學算符可能會與關鍵的約束條件結合,以幫助計算機對圖像進行識別,例如要求形狀和模式在科學上合理。
多尺度密集卷積神經網絡
機器學習在圖像問題上的應用大多使用的是深層卷積神經網絡(DCNNs,deep convolutional neural networks)。在 DCNN 中,輸入圖和中間圖在許多連續的層中進行卷積,使得網絡可以學到高度非線性特徵。爲了在困難的圖像處理問題中得到精確的結果,DCNN 通常會依賴一些其他操作,這些操作包括但不限於對圖像進行縮放以在不同尺度上提取特徵。爲了訓練更深層更強大的網絡,通常會需要添加更多的層類型和連接。最終,DCNN 會使用大量的中間圖和可訓練的參數(一般會超過一億)來解決複雜的問題。
相反,新的「MS-D」網絡架構避免了這些複雜的問題。它用擴張卷積替代縮放操作以捕捉不同空間範圍的特徵,在單個層中執行多個尺度的特徵提取運算,並將所有的中間圖密集地連接起來。新算法只需要很少的中間圖和參數就能得到精準的結果,既不需要調整超參數也無需額外的層和連接進行訓練。
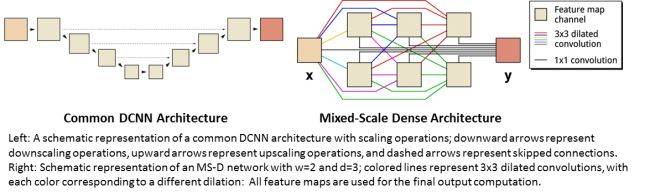
左圖:一般的 DCNN 架構。具有縮放操作的普通 DCNN 架構的簡圖;向下的箭頭代表縮小操作,向上的箭頭代表放大操作,短箭頭代表跳過連接。右圖:MS-D 架構。W = 2、d = 3 的 MS-D 網絡的草圖。帶顏色的線表示 3*3 的擴張卷積,每一個顏色都代表不同的擴張操作;所有的特徵映射都用於最終的計算輸出。
從低分辨率數據中獲得高精確度的結果
另一項挑戰在於如何從低分辨率的輸入產生高分辨率的輸出。任何一個試圖將一張小照片放大的人都會發現,隨着照片越來越大,圖片會變的越來越模糊,因此要完成這一挑戰聽起來幾乎是不可能的。但是用 MS-D 網絡處理少量的訓練圖像確實可以取得一些實際的進展。例如,對纖維增強的微型複合材料的層析重建過程進行降噪。在文獻中提到的實驗,使用 1024 個 x 射線投影重建的圖像得到的圖像噪聲相對較低。再使用 128 個投影重建,來獲得同一個對象的噪聲圖像。訓練的輸入是有噪聲的圖像,在訓練中將無噪聲的圖像作爲目標輸出。經過訓練的網絡可以高效地使用有噪聲的輸入重建高分辨率的輸出圖。

纖維增強的微星複合材料的斷層圖,使用 1024 個投影重建得到(a), 使用 128 個投影重建得到(b)。用(b)作爲 MS-D 網絡的輸入得到的輸出是(c)。每張圖紅色方框標出的小區域放大後呈現在每幅圖的右下角。
新的應用
Pelt 和 Sethian 正在將他們的方法應用於許多新的領域,例如對來自同步加速器光源的圖像進行快速實時的分析,以及生物領域的重建問題,例如細胞和大腦的映射。
Pelt 認爲:「這些新方法都很令人振奮,因爲它們讓機器學習解決更廣泛的成像問題成爲可能。通過減少需要的訓練圖的數量以及增加可處理圖像的尺寸,這個新的網絡架構可在許多研究領域解決更重要的問題。」
勞倫斯伯克利國家實驗室致力於通過推進可持續能源、保護人類健康、創造新材料以及揭示宇宙起源與命運,解決世界面臨最緊迫的問題。成立於 1931 年的伯克利實驗室已獲得 13 項諾貝爾獎。實驗室由加利福尼亞大學管理,由美國能源部科學辦公室負責。
論文:A mixed-scale dense convolutional neural network for image analysis(多尺度密集卷積神經網絡用於圖像分析)

論文鏈接:http://docs.wixstatic.com/ugd/cc66e4_bb1cd44c5f354517bb3f7b8c1db45cc4.pdf
摘要:在最近的工作中,深度卷積神經網絡已成功解決了許多圖像處理問題。當下使用的網絡架構通常會在標準架構中添加額外的操作和連接,以訓練更深層的網絡。爲了在實際應用中得到更高的準確率,就需要更多的可訓練參數。在此,我們介紹的網絡架構,是在不同的圖像尺度中通過擴張卷積以捕捉特徵,並將所有特徵圖密集連接。新架構可以在使用少量參數和使用一組操作的前提下,提高結果的準確率,使得網絡更易在實際中實施、訓練和應用,且可適用於不同的問題。我們在幾個分割問題中對現有架構和新架構進行了比較,結果表明本文提出的架構可以在使用更少參數、更大程度地避免與訓練數據過擬合的情況下,獲得準確率更高的結果。
原文鏈接:http://newscenter.lbl.gov/2018/02/21/new-berkeley-lab-algorithms-create-minimalist-machine-learning-that-analyzes-images-from-very-little-information/