YOLO 是一種非常流行的目標檢測算法,速度快且結構簡單。日前,YOLO 作者推出 YOLOv3 版,在 Titan X 上訓練時,在 mAP 相當的情況下,v3 的速度比 RetinaNet 快 3.8 倍。在 YOLOv3 官網上,作者展示了一些對比和案例。在論文中,他們對 v3 的技術細節進行了詳細說明。我們將內容編譯整理如下。
我們針對 YOLO 做了一些更新,在設計上進行了一些小改動,讓它變得更好。當然,我們也訓練了這個新網絡,它的性能非常優秀。它比前一版本要大一點,但更準確。當然了,不必擔心會犧牲速度,它仍然很快。YOLOv3 可以在 22ms 之內執行完一張 320 × 320 的圖片,mAP 得分是 28.2,和 SSD 的準確率相當,但是比它快三倍。
此外,它在 Titan X 上經過 51 ms 訓練,mAP50 爲 57.9,相比之下,RetinaNet 經過 198ms 的訓練之後 mAP50 爲 57.5。對比起來,兩者的性能差異不大,但是 YOLOv3 比 RetinaNet 快 3.8 倍。
所有的代碼都在 https://pjreddie.com/yolo/上。
與其他檢測器相對比
YOLOv3 非常快速和準確,在 IoU=0.5 的情況下,與 Focal Loss 的 mAP 值相當,但快了 4 倍。此外,大家可以輕鬆在速度和準確度之間進行權衡,只需改變模型的大小,而不需要重新訓練。
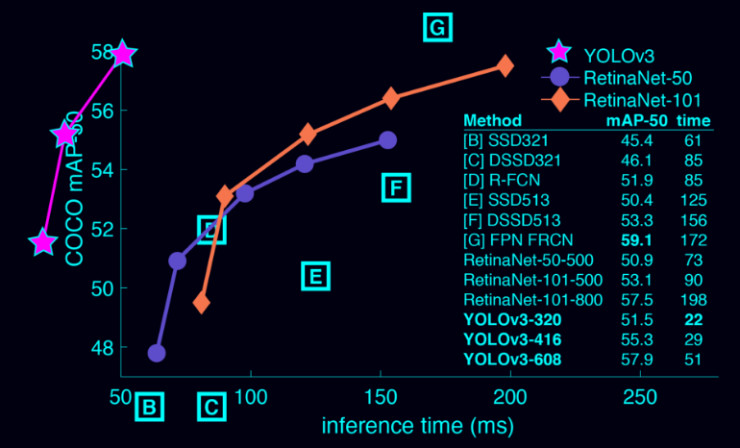
在 COCO 數據集上的表現
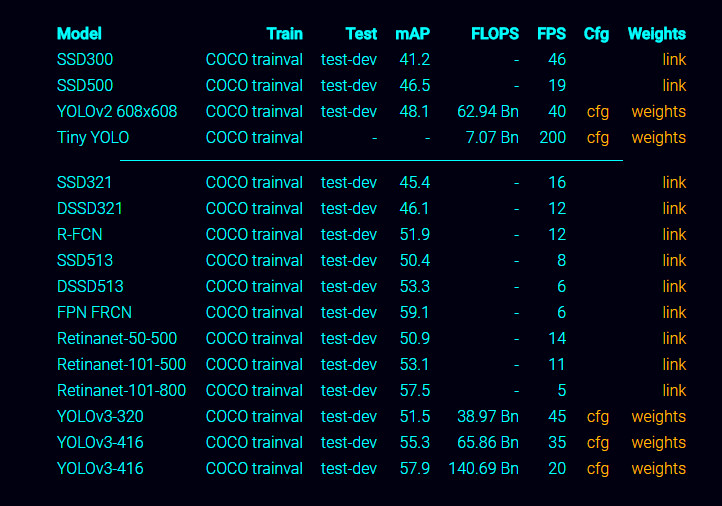
工作原理
先前的檢測系統是讓分類器或定位器來執行檢測任務。他們將模型應用於圖片中,圖片裏物體的位置和尺寸各異,圖像的高得分區域被認爲是檢測區域。
我們採用了完全不同的方法——將一個簡單的神經網絡應用於整張圖像。該網絡將圖像分割成一塊塊區域,並預測每個區域的 bounding box 和概率,此外,預測概率還對這些 bounding box 進行加權。

我們的模型相較基於分類的檢測系統有如下優勢:它在測試時觀察整張圖像,預測會由圖像中的全局上下文(global context)引導。它還通過單一網絡評估做出預測,而不像 R-CNN 這種系統,一張圖就需要成千上萬次預測。對比起來,YOLO 的速度非常快,比 R-CNN 快 1000 倍,比 Fast R-CNN 快 100 倍。
可以參閱我們的論文,瞭解關於完整系統的更多細節。
在 v3 中,有哪些全新的方法呢?
YOLOv3 用了一些小技巧來改進訓練、提高性能,包括多尺度預測,更好的主幹分類器等等。
同樣,詳細信息我們也全寫在論文上了。
用預訓練模型進行檢測
接下來是利用 YOLO 使用預訓練模型來檢測物體。請先確認已經安裝 Darknet。接下來運行如下語句:
git clone https://github.com/pjreddie/darknet
cd darknet
make
這樣一來 cfg/子目錄中就有了 YOLO 配置文件,接下來下載預訓練的 weight 文件(237 MB)(https://pjreddie.com/media/files/yolov3.weights),或者運行如下語句:
wget https://pjreddie.com/media/files/yolov3.weights
然後執行檢測器:
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
輸出如下:
layer filters size input output
0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BFLOPs
1 conv 64 3 x 3 / 2 416 x 416 x 32 -> 208 x 208 x 64 1.595 BFLOPs
.......
105 conv 255 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 255 0.353 BFLOPs
106 detection
truth_thresh: Using default '1.000000'
Loading weights from yolov3.weights...Done!
data/dog.jpg: Predicted in 0.029329 seconds.
dog: 99%
truck: 93%
bicycle: 99%
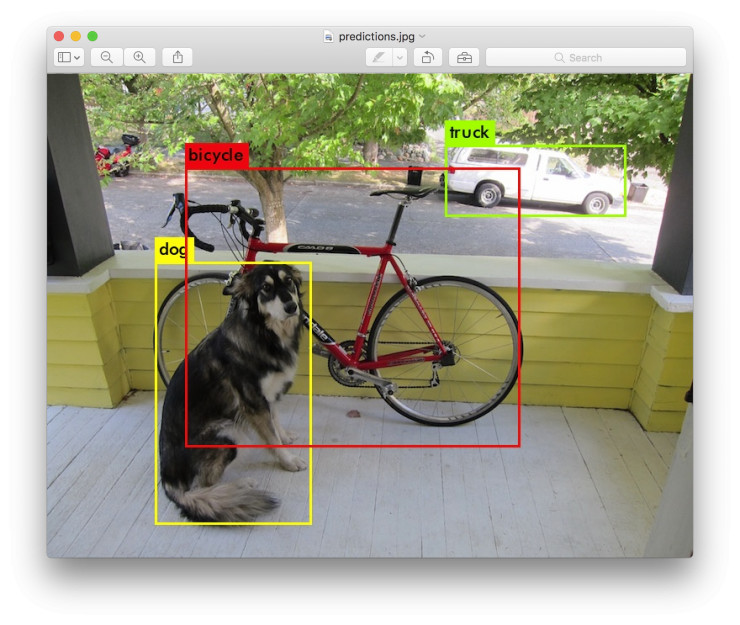
Darknet 會輸出檢測到的物體、confidence 以及檢測時間。我們沒有用 OpenCV 編譯 Darknet,所以它不能直接顯示檢測情況。檢測情況保存在 predictions.png 中。大家可以打開這個圖片來查看檢測到的對象。我們是在 CPU 上使用 Darknet,檢測每張圖片大約需要 6-12 秒,如果使用 GPU 將快得多。
我還附上了一些例子給大家提供靈感,你們可以試試 data/eagle.jpg,data/dog.jpg,data/person.jpg 或 data/horses.jpg。
detect 指令是對 command 的常規版本的簡寫:
./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/dog.jpg
如果你只是想檢測圖像,並不需要了解這個,但如果你想做其他的事情,比如在網絡攝像頭上運行 YOLO,這將非常有用(稍後詳細描述)。
多個圖像
在 command 行不寫圖像信息的話就可以連續運行多個圖片。當加載完配置和權重,你將看到如下提示:
./darknet detect cfg/yolov3.cfg yolov3.weights
layer filters size input output
0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BFLOPs
1 conv 64 3 x 3 / 2 416 x 416 x 32 -> 208 x 208 x 64 1.595 BFLOPs
.......
104 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
105 conv 255 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 255 0.353 BFLOPs
106 detection
Loading weights from yolov3.weights...Done!
Enter Image Path:
輸入類似 data/horses.jpg 的圖像路徑來進行邊框預測。
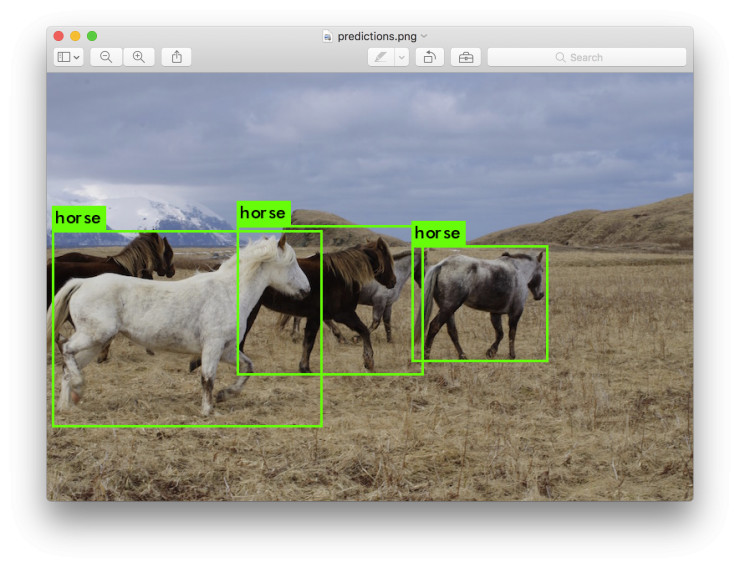
一旦完成,它將提示你輸入更多路徑來檢測不同的圖像。使用 Ctrl-C 退出程序。
改變檢測門限
默認情況下,YOLO 只顯示檢測到的 confidence 不小於 0.25 的物體。可以在 YOLO 命令中加入-thresh
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg -thresh 0
網絡攝像頭實時檢測
如果在測試數據上運行 YOLO 卻看不到結果,那將很無聊。與其在一堆圖片上運行 YOLO,不如選擇攝像頭輸入。
要運行如下 demo,需要用 CUDA 和 OpenCV 來編譯 Darknet。接下來運行如下指令:
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights
YOLO 將會顯示當前的 FPS 和預測的分類,以及伴有邊框的圖像。
你需要一個連接到電腦的攝像頭並可以讓 OpenCV 連接,否則就無法工作。如果有連接多個攝像頭並想選擇其中某一個,可以使用 -c
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights
在 VOC 數據集上訓練 YOLO
首先需要 2007-2012 年的所有 VOC 數據,這是下載地址:https://pjreddie.com/projects/pascal-voc-dataset-mirror/,爲了存儲數據,執行如下語句:
wget https://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar
wget https://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar
wget https://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar
tar xf VOCtrainval_11-May-2012.tar
tar xf VOCtrainval_06-Nov-2007.tar
tar xf VOCtest_06-Nov-2007.tar
接下來所有 VOC 訓練數據都在 VOCdevkit/ 子目錄下。
生成標籤
接下來需要生成 Darknet 使用的標籤文件。Darknet 需要的.txt 文件格式如下:
x, y, width 和 height 對應圖像的寬和高。需要在 Darknet scripts/子目錄下運行 voc_label.py 腳本來生成這些文件。
wget https://pjreddie.com/media/files/voc_label.py
python voc_label.py
幾分鐘後,這個腳本將生成所有必需文件。大部分標籤文件是在 VOCdevkit/VOC2007/labels/ 和 VOCdevkit/VOC2012/labels/ 下,大家可以在目錄下看到如下信息:
ls
2007_test.txt VOCdevkit
2007_train.txt voc_label.py
2007_val.txt VOCtest_06-Nov-2007.tar
2012_train.txt VOCtrainval_06-Nov-2007.tar
2012_val.txt VOCtrainval_11-May-2012.tar
類似 2007_train.txt 的語句列出了圖像文件的年份和圖像集。Darknet 需要一個包含所有你想要訓練的圖片的文本文件。在這個例子中,我們訓練除了 2007 測試集的所有數據。運行如下語句:
cat 2007_train.txt 2007_val.txt 2012_*.txt > train.txt
修正
現在去 Darknet 目錄,需要改變 cfg/voc.data 配置文件以指向數據:
1 classes= 20
2 train =/train.txt
3 valid =2007_test.txt
4 names = data/voc.names
5 backup = backup
將
下載預訓練卷積權重
在訓練中使用在 Imagenet 上預訓練的卷積權重。我們這裏使用 darknet53 模型的權重,可以點擊這裏https://pjreddie.com/media/files/darknet53.conv.74下載卷積層權重:
wget https://pjreddie.com/media/files/darknet53.conv.74
訓練模型
接下來執行如下語句進行訓練:
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
在 COCO 上的訓練與 VOC 上類似,大家可以在這裏查看詳情。
YOLOv3 論文地址如下:
https://pjreddie.com/media/files/papers/YOLOv3.pdf