選自Google Research
作者:Tara N. Sainath、Yonghui Wu
近日,谷歌發表博客介紹了他們對端到端語音識別模型的最新研究成果,新模型結合了多種優化算法提升 LAS 模型的性能。相較於分離訓練的傳統系統,新方法充分地發揮了聯合訓練的優勢,在語音搜索任務中取得了當前業內最低的詞錯率結果。
當前最佳語音搜索模型
傳統自動語音識別系統(ASR)一直被谷歌的多種語音搜索應用所使用,它由聲學模型(AM)、發音模型(PM)和語言模型(LM)組成,所有這些都會經過獨立訓練,同時通常是由手動設計的,各個組件會在不同的數據集上進行訓練。AM 提取聲學特徵並預測一系列子字單元(subword unit),通常是語境依賴或語境獨立的音素。然後,手動設計的詞典(PM)將聲學模型生成的音素序列映射到單詞上。最後,LM 爲單詞序列分配概率。獨立地訓練各個組件會產生額外的複雜性,最終得到的性能低於聯合訓練所有的組件。過去幾年來出現了越來越多開發中的端到端系統嘗試以單個系統的方式聯合學習這些分離的組件。雖然相關文獻表明這些端到端模型具有潛在價值 [2,3],但對於這樣的方法是否能提升當前最佳的傳統系統的性能目前尚無定論。
最近,谷歌發佈了其最新研究,「使用序列到序列模型的當前最佳語音識別系統」(State-of-the-art Speech Recognition With Sequence-to-Sequence Models[4])。這篇論文描述了一種新型的端到端模型,它的性能優於目前已商用的傳統方法 [1]。在谷歌的研究中,新的端到端系統的詞錯率(WER)可以降低到 5.6%,相對於強大的傳統系統有 16% 的性能提升(6.7%WER)。此外,該端到端模型可以在任何的假設再評分(hypothesis rescoring)之前輸出初始詞假設。該模型的大小隻有傳統模型的 1/18,因爲它不包含分離的 LM 和 PM。
谷歌的新系統建立在 Listen-Attend-Spell(LAS,在文獻 [2] 中首次提出)端到端架構之上。LAS 架構由三個組件組成。listener 編碼器組件,和標準的 AM 相似,取輸入語音信號 x 的時間-頻率表徵,然後使用一系列的神經網絡層將輸入映射到一個高級特徵表示,henc。編碼器的輸出被傳遞到 attender,其使用 henc 學習輸入特徵 x 和預測子字單元的 {y_n,...y_0} 之間的對齊方式,其中每個子字通常是一個字素或字片。最後,attention 模塊的輸出被傳遞給 speller(即解碼器),speller 和 LM 相似,可以生成一系列假設詞的概率分佈。
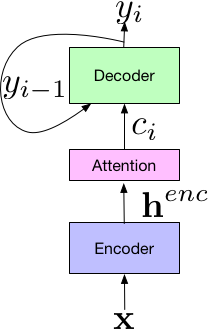
LAS 端到端模型的組件
LAS 模型的所有組件通過單個端到端神經網絡聯合地訓練,相較於傳統系統的分離模塊更加簡單。
此外,因爲 LAS 模型都是神經網絡類型,因此並不需要添加外部的手動設計組件,例如有限狀態轉換器、詞典或文本歸一化模塊。最後,和傳統模型不同,訓練端到端模型不需要決策樹的引導或一個分離系統生成的時間序列,給定了文本副本和相關的聲學特徵之後,就可以進行訓練。
在文獻 [4] 中,谷歌引入了一種新型的結構化提升,包括優化傳遞給解碼器的注意力向量,以及優化更長的子字單元(即字片,wordpieces)的訓練過程。此外,谷歌在新模型中還引入了大量的優化訓練過程的方法,包括最小詞錯率訓練法(minimum word error rate training[5])。正是這些結構化和優化提升使新模型取得了相對於傳統模型 16% 的性能提升。
這項研究的另一個潛在應用是多方言和多語言系統,僅需優化單個神經網絡所帶來的簡單性是很有吸引力的。所有的方言/語言可以被組合以訓練一個網絡,而不需要爲每個方言/語言分配分離的 AM、PM 和 LM。谷歌生成這些模型在 7 種英語方言 [6] 和 9 種印度方言 [7] 上都工作得很好,優於分離地訓練模型的性能。
雖然結果很吸引人,但是研究人員認爲目前的探索還尚未完成。第一,這些模型還不能實時地處理語音 [8,9,10],而實時處理對於延遲敏感的應用如語音搜索而言是必要的。第二,這些模型在實際生產數據上進行評估的時候表現仍然不佳。第三,谷歌目前的端到端模型是在 22,000 個錄音-文本對上學習的,而傳統系統通常可以在顯著大得多的語料庫上進行訓練。最後,新模型還不能爲生僻詞學習合適的拼寫,例如專有名詞(一般還需要使用手動設計的 PM)。谷歌接下來的目標將是解決這些問題。
論文:State-of-the-art Speech Recognition With Sequence-to-Sequence Models

論文鏈接:https://arxiv.org/abs/1712.01769
摘要:基於注意力機制的編碼器-解碼器架構,如 Listen、Attend 和 Spell(LAS)可以將傳統自動語音識別(ASR)系統上的聲學、發音和語言模型組件集成到單個神經網絡中。在我們以前的工作中,我們已經證明了這樣的架構在聽寫任務中與業內頂尖水平的 ASR 系統具有相當水平,但此前還不清楚這樣的架構是否可以勝任語音搜索等更具挑戰性的任務。
在本研究中,我們探索了多種優化和提升 LAS 模型的方法,其中的一些顯著提升了系統表現。在結構上,我們證明了詞塊模型可以用來代替字素。我們引入了新型的多頭注意力架構,它比常用的單頭注意力架構有所提升。在優化方面,我們探索了同步訓練、定期採樣、平滑標籤(label smoothing),也應用了最小誤碼率優化,這些方法都提升了準確度。我們使用一個單向 LSTM 編碼器進行串流識別並展示了結果。在 12,500 小時的語音搜索任務中,我們發現新模型將 LAS 系統的詞錯率(WER)從 9.2% 降低到了 5.6%,相對於目前業內最佳系統的 6.7% 提高了 16% 的水平。
參考文獻
[1] G. Pundak and T. N. Sainath,「Lower Frame Rate Neural Network Acoustic Models," in Proc. Interspeech, 2016.
[2] W. Chan, N. Jaitly, Q. V. Le, and O. Vinyals,「Listen, attend and spell,」CoRR, vol. abs/1508.01211, 2015
[3] R. Prabhavalkar, K. Rao, T. N. Sainath, B. Li, L. Johnson, and N. Jaitly,「A Comparison of Sequence-to-sequence Models for Speech Recognition,」in Proc. Interspeech, 2017.
[4] C.C. Chiu, T.N. Sainath, Y. Wu, R. Prabhavalkar, P. Nguyen, Z. Chen, A. Kannan, R.J. Weiss, K. Rao, K. Gonina, N. Jaitly, B. Li, J. Chorowski and M. Bacchiani,「State-of-the-art Speech Recognition With Sequence-to-Sequence Models,」submitted to ICASSP 2018.
[5] R. Prabhavalkar, T.N. Sainath, Y. Wu, P. Nguyen, Z. Chen, C.C. Chiu and A. Kannan,「Minimum Word Error Rate Training for Attention-based Sequence-to-Sequence Models,」submitted to ICASSP 2018.
[6] B. Li, T.N. Sainath, K. Sim, M. Bacchiani, E. Weinstein, P. Nguyen, Z. Chen, Y. Wu and K. Rao,「Multi-Dialect Speech Recognition With a Single Sequence-to-Sequence Model」submitted to ICASSP 2018.
[7] S. Toshniwal, T.N. Sainath, R.J. Weiss, B. Li, P. Moreno, E. Weinstein and K. Rao,「End-to-End Multilingual Speech Recognition using Encoder-Decoder Models」, submitted to ICASSP 2018.
[8] T.N. Sainath, C.C. Chiu, R. Prabhavalkar, A. Kannan, Y. Wu, P. Nguyen and Z. Chen,「Improving the Performance of Online Neural Transducer Models」, submitted to ICASSP 2018.
[9] C.C. Chiu and C. Raffel,「Monotonic Chunkwise Attention,」submitted to ICLR 2018.
[10] D. Lawson, C.C. Chiu, G. Tucker, C. Raffel, K. Swersky, N. Jaitly.「Learning Hard Alignments with Variational Inference」, submitted to ICASSP 2018.
[11] T.N. Sainath, R. Prabhavalkar, S. Kumar, S. Lee, A. Kannan, D. Rybach, V. Schogol, P. Nguyen, B. Li, Y. Wu, Z. Chen and C.C. Chiu,「No Need for a Lexicon? Evaluating the Value of the Pronunciation Lexica in End-to-End Models,」submitted to ICASSP 2018.
[12] A. Kannan, Y. Wu, P. Nguyen, T.N. Sainath, Z. Chen and R. Prabhavalkar.「An Analysis of Incorporating an External Language Model into a Sequence-to-Sequence Model,」submitted to ICASSP 2018.
原文鏈接:https://research.googleblog.com/2017/12/improving-end-to-end-models-for-speech.html