Learning Feature Pyramids for Human Pose Estimation 是發表在 ICCV 2017 的一篇有關人體姿態估計的論文,提出利用特徵金字塔來進行人體姿勢預測。作者是 Wei Yang,香港中文大學博士生。
 論文復現代碼: http://aistudio.baidu.com/aistudio/#/projectdetail/24019
論文復現代碼: http://aistudio.baidu.com/aistudio/#/projectdetail/24019
人體姿態估計介紹
人體姿態估計是計算機視覺領域一個較有挑戰性的任務,問題的輸入是一張圖片,輸出是圖片中的人體各個關節點的位置,如下圖所示。人體姿態任務可以是單人姿態估計,或者是多人姿態估計,而本文給出的方法是單姿態估計,即一張圖片只預測一個人的姿態。

在本文之前,在人體姿態估計效果較好的工作是 2016 年 Alejandro Newell 等人的 Stacked Hourglass Networks for Human Pose Estimation [1],而本文的網絡結構是在此之上的改進, 因此 Hourglass Network 的相關設計對理解本文網絡非常重要。
重要工作介紹
Stacked Hourglass Network
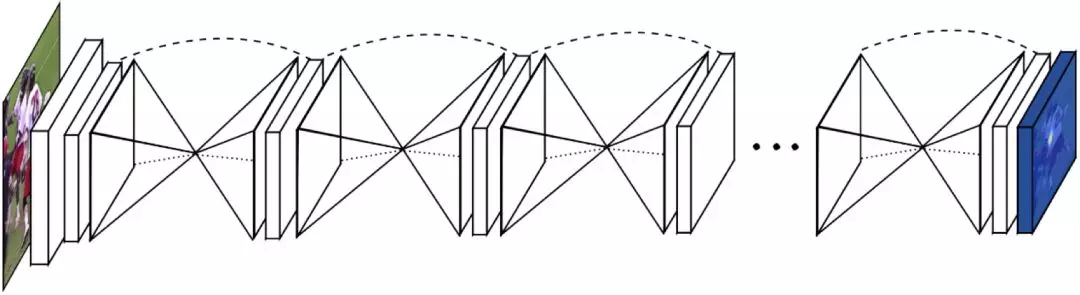
Stacked Hourglass Network 是一種堆疊沙漏型的全卷積網絡,能夠很好地捕捉圖片的多尺度特徵,並由粗到細地預測關節點位置的熱力圖 Heatmap,即關節點出現在各個位置的概率。最終的關節點的位置預測結果取 Heatmap 中概率最大的索引。

網絡的基本結構如下圖所示,可以看到網絡後面都是由一個個沙漏型的結構堆疊而成的。
Hourglass Module
沙漏模塊則是一種編碼器-解碼器加短接層的設計,其動機是捕獲多尺度信息。因爲對於人體的各個不同部位的大小尺度是不一樣的,通過短接層將不同尺度下的特徵圖加入到解碼階段可以獲得更尺度的信息,從而得到更精準的預測。
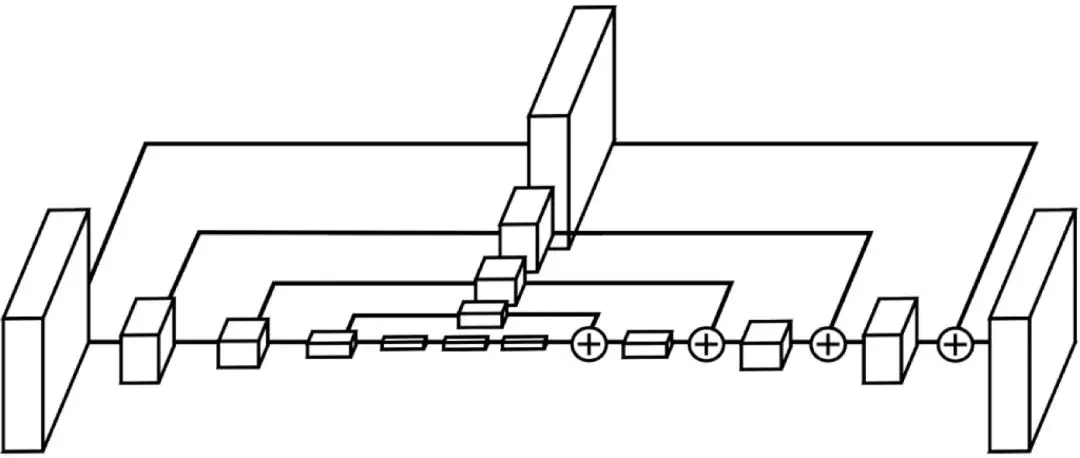
Hourglass 模塊和 Networks 中的白色方塊表示的都是類似於 ResNet 中的殘差模塊 [2],其作用是在保留原特徵信息的同時進一步提取更深層次的特徵,同時也能使得網絡變得更深又不至於梯度消失。
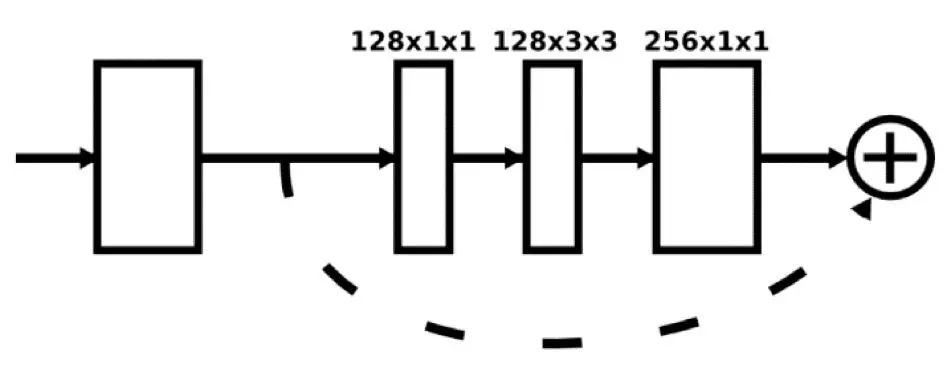
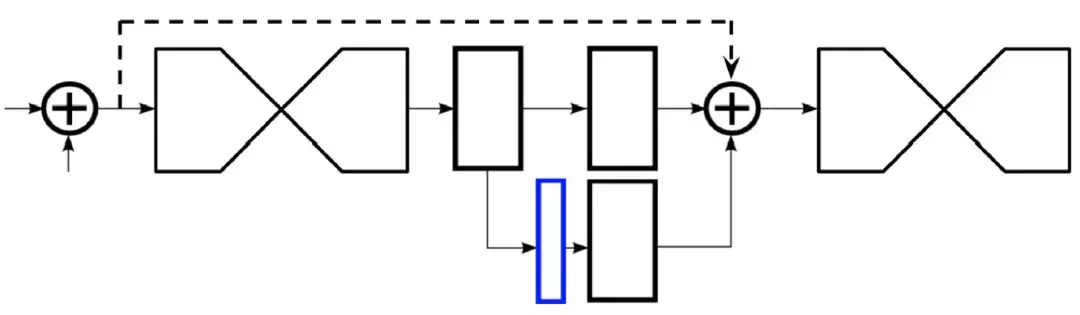
像堆疊殘差模塊一樣堆疊沙漏模塊就得到了堆疊沙漏網絡。值得注意的是,沙漏模塊的輸入和輸出大小可以是一樣的,也就是說在每個沙漏模塊之後都可以進行最終結果的預測並計算損失,起到中間監督作用。
另外,上層模塊的預測結果也可以作爲下層模塊的輸入,從而更好的幫助下層模塊進行預測,因此預測結果也可以通過 1*1 的卷積重新加入到原來的特徵中,進行由粗糙到細緻的估計。
 改進方向
改進方向
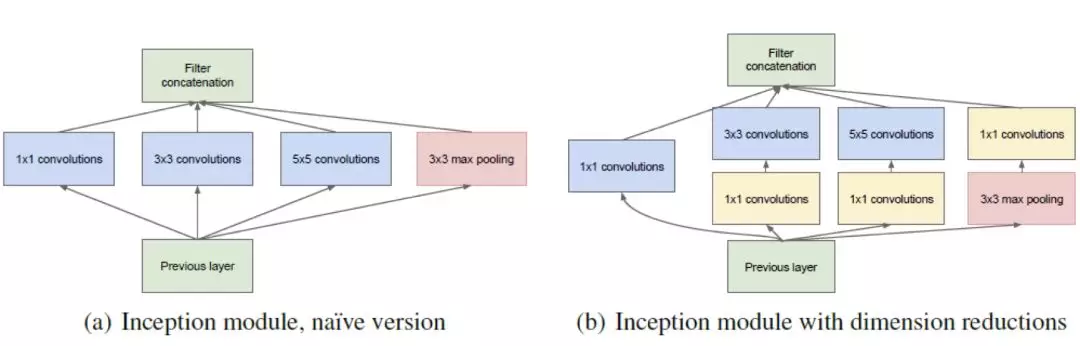
爲了捕捉不同尺度的,除了使用短接層,還可以使用不同的卷積核同時進行卷積,再將得到的特徵進行疊加,比如 Inception 模塊 [3]。Inception 模塊通過使用不同大小的卷積核以及 1*1 的卷積使得網絡能夠捕捉不同分辨率的特徵,並減少參數數量。
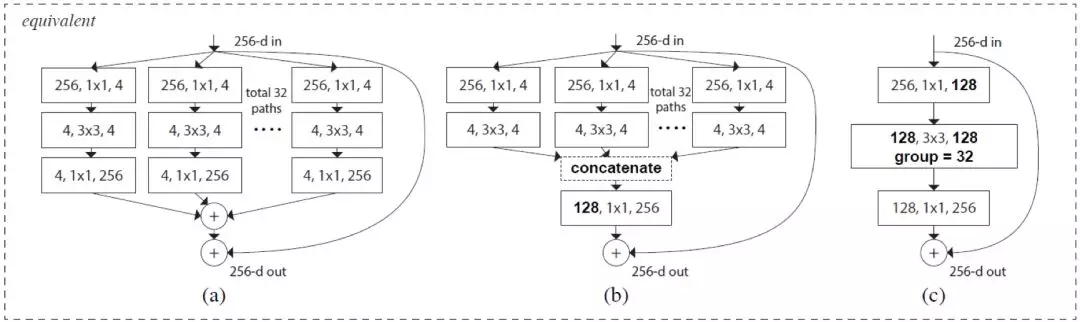
而在減少參數數量方面,ResNeXt 又在 ResNet 更進一步 [4],將初始的輸入分裂成多條分支進行卷積,其中每條分支的卷積核大小都是一樣的。
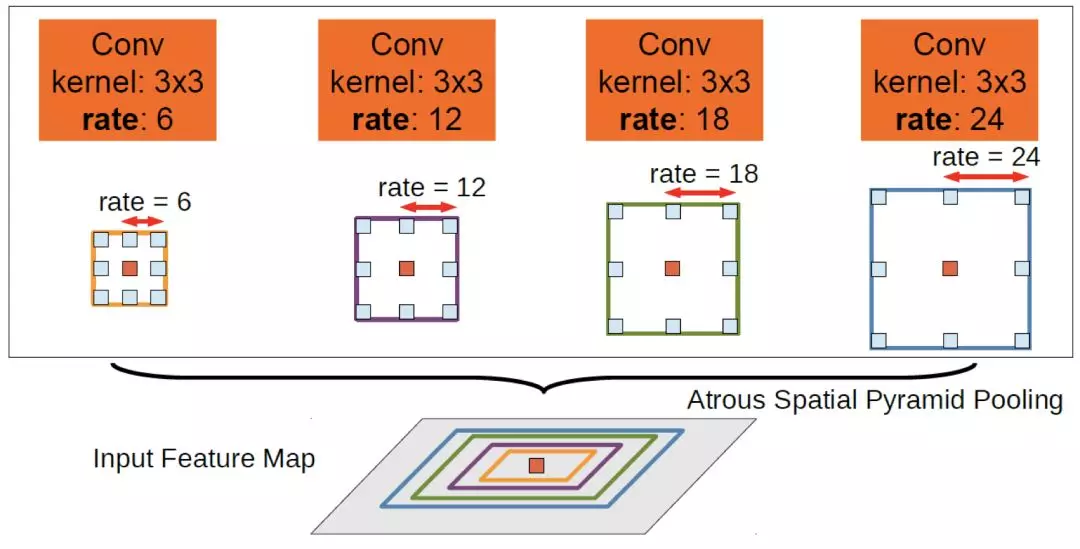
另外,使用空洞卷積也可以獲得多尺度的特徵 [5],空洞卷積是通過使用具有間隔的卷積核在特徵圖上進行卷積從而避免對原特徵圖進行下采樣的步驟。
本文方法
Pyramid Residual Modules (PRMs)
可能是受到上述三種模塊的啓示,本文作者設計出了四種特徵金字塔模塊如下圖所示。
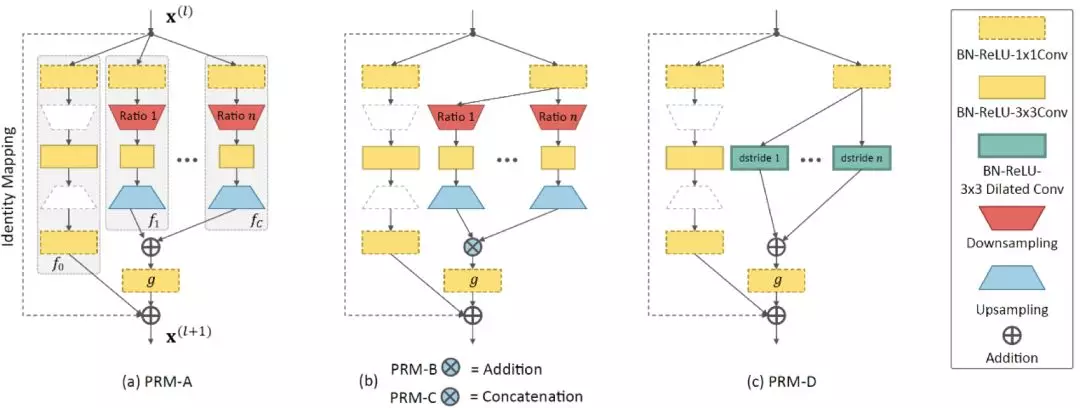
PRM-A 是在原先的殘差模塊的分支基礎上,直接增加多個分辨率的分支,其分辨率的不同主要是通過下采樣實現的,而由於殘差模塊的結果需要將不同分支的結果相加,因此下采樣後的特徵要通過上採樣恢復原來分辨率。
PRM-B 則是將 PRM-A 中不同分辨率的分支開始的 1*1 卷積進行參數共享,從而減少參數數量。
PRM-C 則是將 PRM-B 中多分辨率特徵的相加改爲了串聯,由於串聯後的特徵通道數與原來不同,因此可能需要再進行一個 1*1 的卷積對齊特徵通道後再與原特徵相加。
PRM-D 則是使用空洞卷積代,替下采樣和上採樣得到多尺度的特徵。
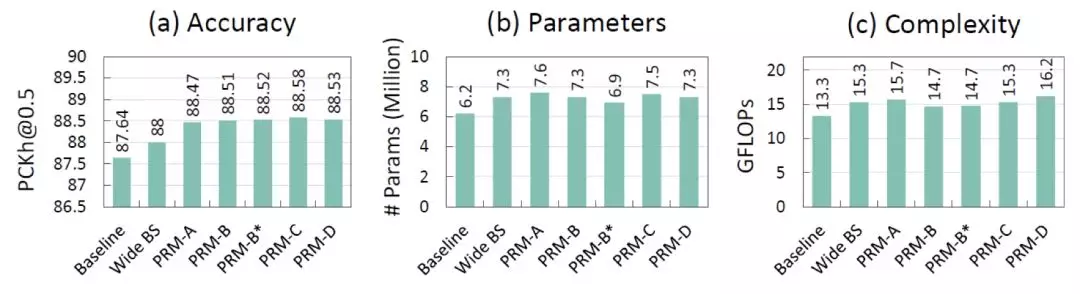
根據後面的實驗結果可以看到在準確率、參數數量和複雜度的權衡之下,PRM-B 模塊是較好的選擇。
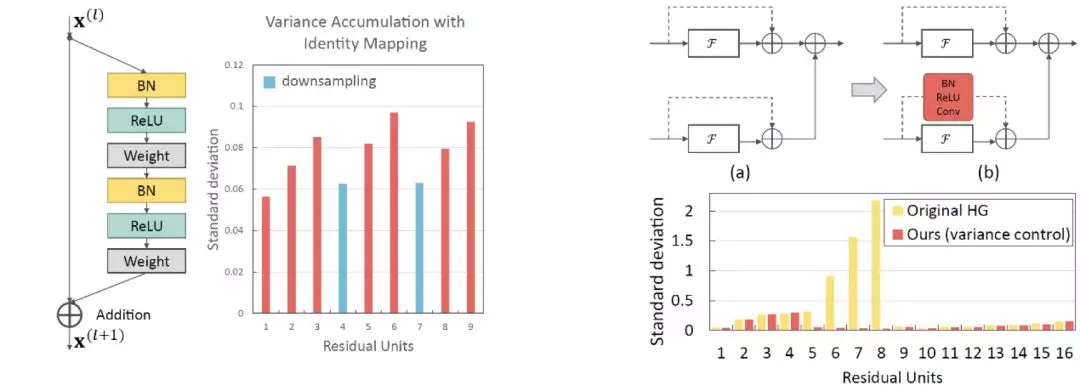
Output Variance Accumulation
除了上述的改進,本文作者還提到原始的殘差模塊有輸出方差積累的問題,當堆疊多個殘差塊時,將原始特徵直接與卷積後的特徵相加時會有較大的方差,通過對原始特徵添加一個 Bn-ReLu-Conv 操作可以較好的控制這個問題。
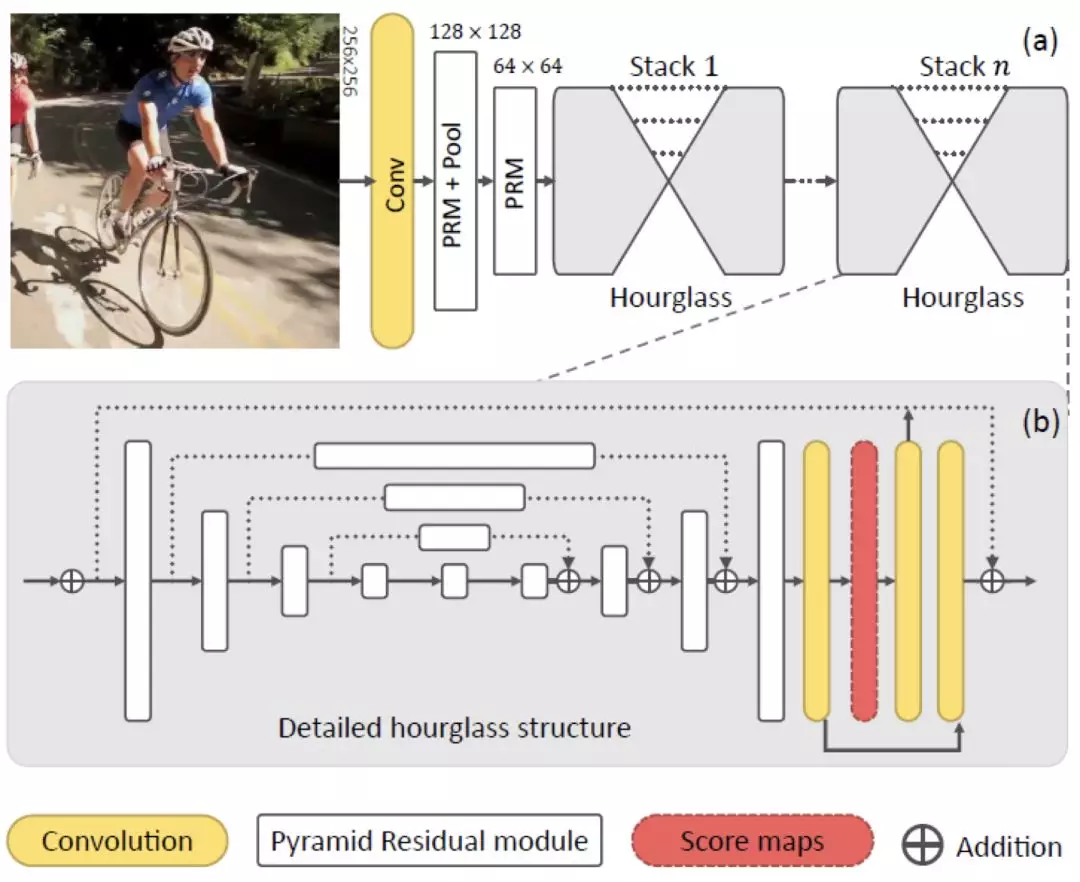
PyraNet
本文網絡框架使用 Stacked Hourglass Network 的基本框架,但將其中的殘差模塊都替換成了上述特徵金字塔模塊 PRMs,網絡結構圖如下。
再談初始化
網絡參數的初始化對網絡的訓練以及結果會有一定影響,爲了使得網絡更順利的開始訓練,有許多不同的初始化方案,其中較常見的即是 Xavier [6]。
Xavier
Xavier 的提出者指出,第 i 層的參數方差從正向和反向傳播的角度考慮,應分別滿足如下式子。其中的 n_i 和 n_(i+1) 分別是該層輸入的元素個數以及輸出的元素個數。
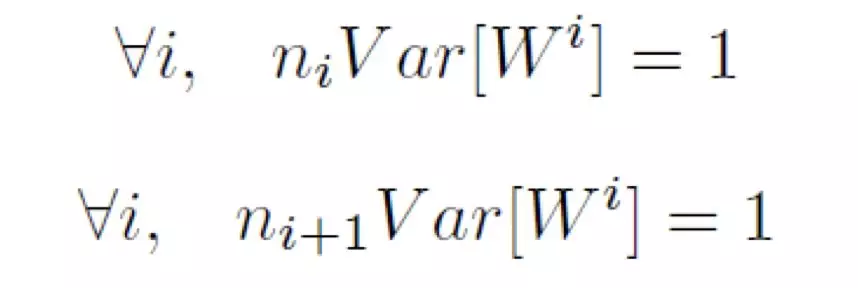
折衷考慮,Xavier 初始化的參數方差同時考慮輸入和輸出元素個數,即將上述兩式相加後得到的結果。
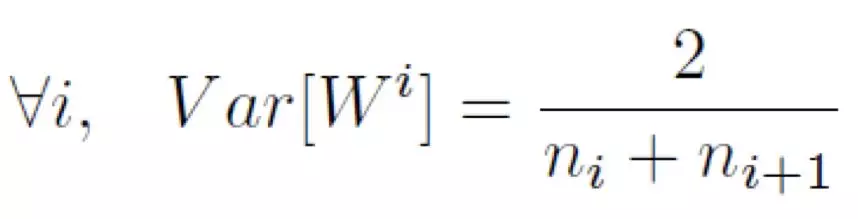
Initialization Multi-Branch Networks
本文作者考慮到提出 Xavier 時的大部分網絡並沒有多條分支,因此對多分支網絡的初始化方案重新考量,得出瞭如下的更泛化的結果。其中 l 表示網絡層數,C_i 和 C_o 分別表示輸入和輸出分支數,n_i 和 n_o 分別表示各輸入和輸出分支的元素個數,α 根據激活函數有不同取值,ReLu 取 0.5。即從前向和反向傳播的角度考慮,各層參數初始化時的方差應與各輸入分支合併前的總元素個數、各輸出分支分離後的總元素個數有關。
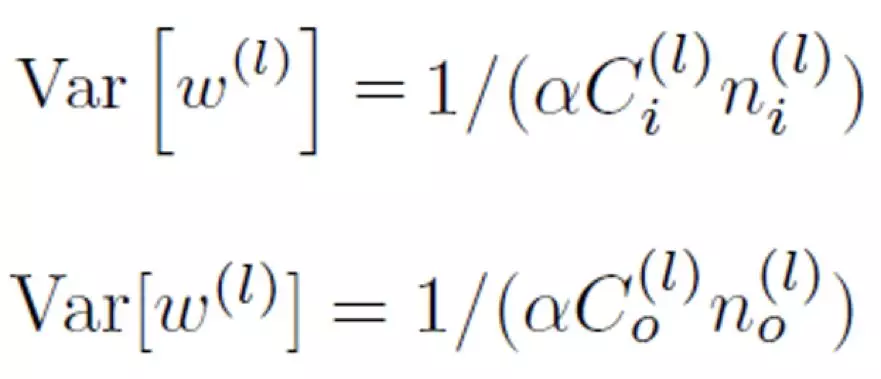
折衷考慮,多分支參數初始化的方差在文中應爲滿足如下式子。注意到 α 帶有平方,特殊情況下,若 α 取 0.5,輸入輸出均只有 1 條分支,結果與 Xavier 不一致,因此筆者認爲 α 不應取平方,這樣在上述情況下仍能 Xavier 保持一致,作爲 Xavier 的泛化。
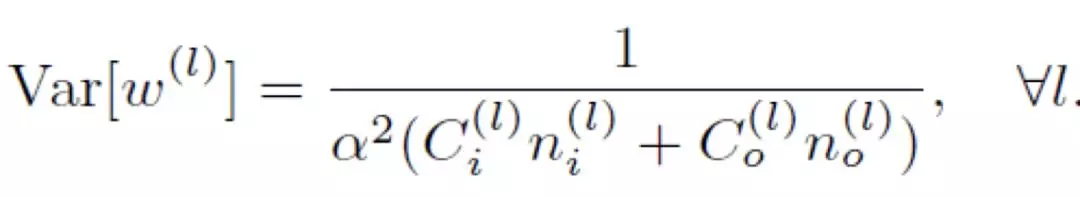 實驗結果與分析
實驗結果與分析
人體姿態估計準確性
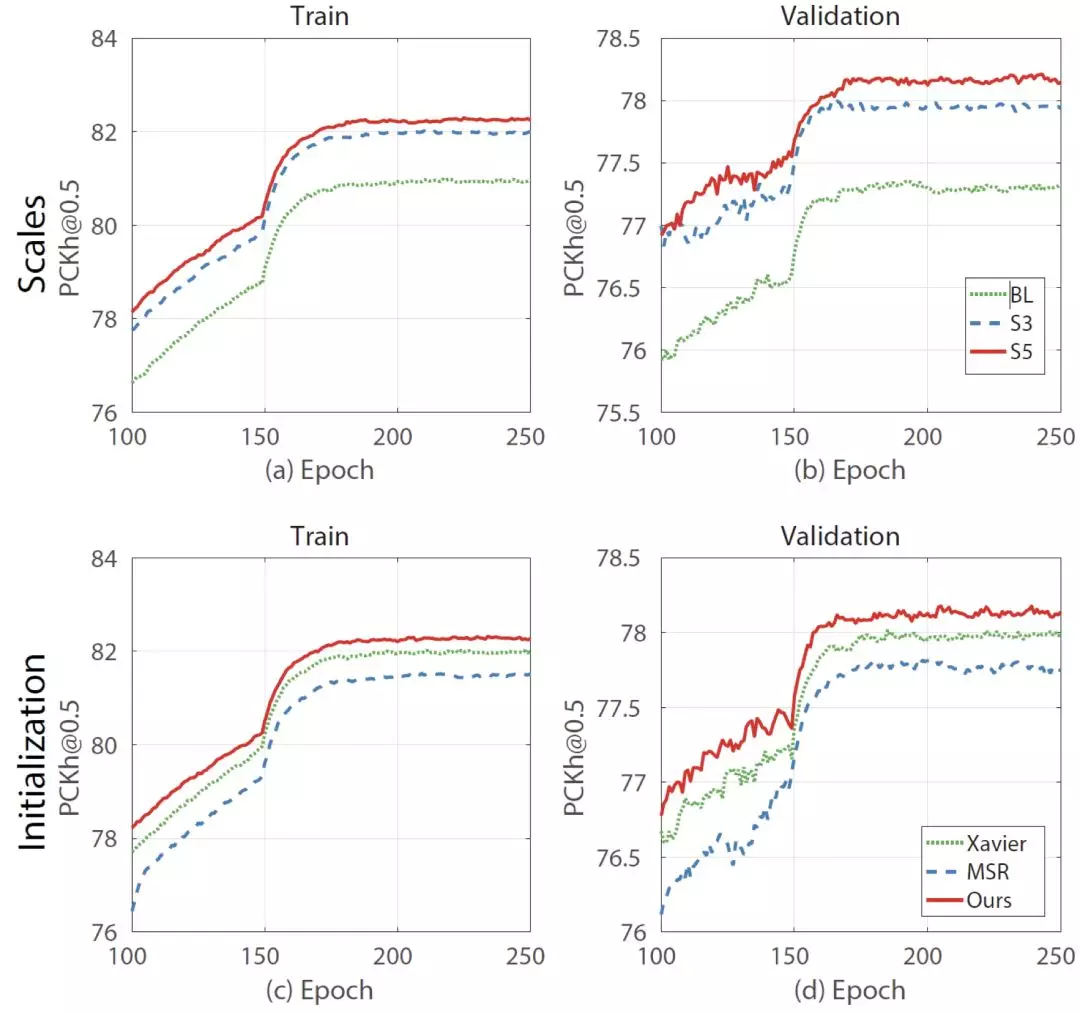
本文在 MPII 和 LSP、LSPEt 數據集上進行訓練,使用 PCK (Percentage of Correct Keypoints) 和 PCKh 進行評估,PCK 計算估計的關鍵點與真實值間的歸一化距離小於設定閾值的比例,PCKh 則以頭部長度爲參考的歸一化。實驗結果如下,可以看到使用 PRM-B 的 PyraNet 在所有對比的方法中都取得了最好的準確率。

控制變量比較
在網絡結構的對比實驗中可以看到,相比於 Baseline 即普通的 Stacked Hourglass Network,PyraNet 使用的特徵金字塔和多分支參數初始化方案都有提高結果的準確性。
 其他實驗
其他實驗
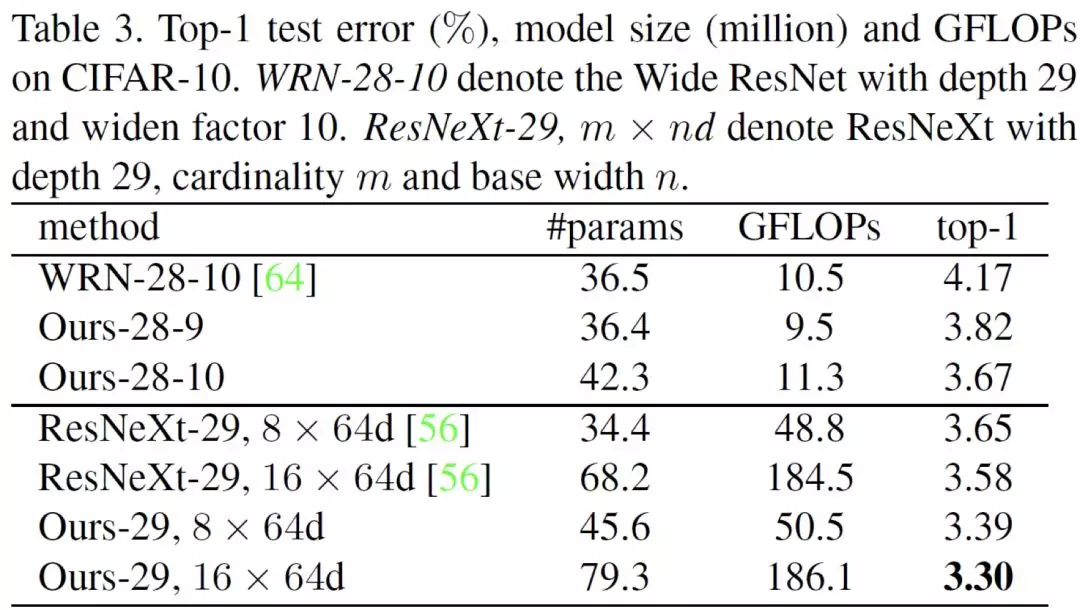
本文作者使 PRM 替代相應網絡的殘差模塊在 CIFAR-10 上進行訓練,得到最低的 Top-1 測試誤差,但網絡的大小和運算量稍有增加。
總結
本文的主題雖然是人體姿態估計,但提出的改進和創新較爲普適,在其他任務上也可以進嘗試。主要思想有如下:
1. 本提出了特徵金字塔殘差模塊,增強了深度神經網絡的尺度不變性;
2. 本文提出了多分支參數初始化方案,使得網絡訓練更順利;
3. 本文提出了通過在短接層增加一次卷積來減少殘差模塊輸出方差積累的問題。
PaddleFluid模型復現
注:代碼中的 bn_relu_convn*n 是對依次使用 PaddleFluid 的 batch norm、relu 和卷積核爲 n 的 conv2d 的封裝。
1. 定義特徵金字塔模塊:特徵金字塔首先將輸入進行不夠規模的下采樣,再進行特徵提取,然後將下采樣後提取的特徵上採樣回輸入大小。原文使用了 Fraction pool 進行下采樣,使得下采樣更加平滑,而 PaddleFluid 並沒有實現 Fraction pool,故只能使用簡單的二線性插值 Resize bilinear 進行代替。
def pyramid(input, out_ch, ngroup): output_res = input.shape[-1] scale_base = pow(2.0, 1.0/ngroup) # extract features in different resolution features = [] for i in range(1, ngroup+1): # subsample scale = round(1.0/pow(scale_base, i),4) feature = resize_bilinear(input, scale=scale) # extract the feature feature = bn_relu_conv3x3(feature,out_ch) # upsample feature = resize_bilinear(feature, out_shape=[output_res, output_res]) features.append(feature) # sum up features output = features[0] for i in range(1, ngroup): output = elementwise_add(output, features[i]) return output2. 定義 PRM 特徵金字塔殘差塊:在一般的 ResNet 殘差模塊的基礎上進行擴展,在進行完 3*3 的卷積後再加入一個特徵金字塔,這裏實現了上述的 PRM-B,即所有特徵金字塔分支使同一個輸入。
def conv_block(input, out_ch, type='prm-b', base_width=6, cardinality=30): # 1*1 conv conv_out = bn_relu_conv1x1(input,out_ch//2) # 3*3 conv conv_out = bn_relu_conv3x3(conv_out,out_ch//2) if type == 'res': output = bn_relu_conv1x1(conv_out,out_ch) return output elif type == 'prm-b': pyra_depth = out_ch//base_width ngroup = cardinality # extract feature pyramid # 1 branch in, ngroup branches out pyra_out = bn_relu_conv1x1(input, pyra_depth,in_branches=1,out_branches=ngroup) pyra_out = pyramid(pyra_out, pyra_depth, ngroup) # ngroup braches in, 1 branch out pyra_out = bn_relu_conv1x1(pyra_out, out_ch//2,in_branches=ngroup,out_branches=1) # 2 branches in, 1 branch out output = elementwise_add(conv_out, pyra_out) output = bn_relu_conv1x1(output, out_ch,in_branches=2,out_branches=1) return output # TODO: PRM-A/PRM-C/PRM-D return output3. 按照 Stacked Hourglass Network 的方式定義沙漏模塊和堆疊沙漏模塊(代碼略)。值得注意的是 Hourglass 是一個遞歸的結構,因此可以使用遞歸函數來建立網絡結構。
4. 定義初始化方案 Branch initializer,筆者使用 Xavier 進行泛化,加入了輸入輸出分支數。
def branch_initializer(in_units=1,out_units=1,in_branches=1,out_branches=1,act='relu',uniform=False,seed=0): # it might be alpha instead of alpha**2 in formula.15 # in this case, when in_branches=out_branches=1, it degenrates to Xavier alphax2 = 0.5*2 if act=='relu' else 1.0*2 fan_in = in_units*in_branches*alphax2 fan_out = out_units*out_branches*alphax2 return Xavier(uniform,fan_in,fan_out)5. 網絡訓練:實驗使用 PaddleFluid v0.14 環境,Titan Xp 單 GPU,在 MPII 數據集上進行訓練,訓練圖片 20k 張,測試圖片 2k 張,訓練時進行了數據增強。PyraNet 堆疊沙漏數 nstack=2,殘差模塊使用 PRM-B 結構,特徵金字塔分支數 cardinality=4,通道基數 base_width=9,批大小 batch_size=8,訓練輪述 epoch=150,使用 Adam 優化器,學習率 2.5*10^-4 且每 10 輪衰減至 90%,初始化使用 Xavier 泛化後的多分支初始化。對照組除了殘差模塊爲普通 res 模塊其他參數均相同。
6. 實驗結果:本次復現結果使用 PRM-B 模塊的 PyraNet 並沒有比使用 Res 模塊的堆疊沙漏網絡效果要好。準確率使用 PCKh@0.5 進行評估。

準確率曲線如下:使用 PRM-B 由於發生了過擬合,在 Epoch=110 處進行了早停,而使用 Res 則在 Epoch=110 時接近收斂。
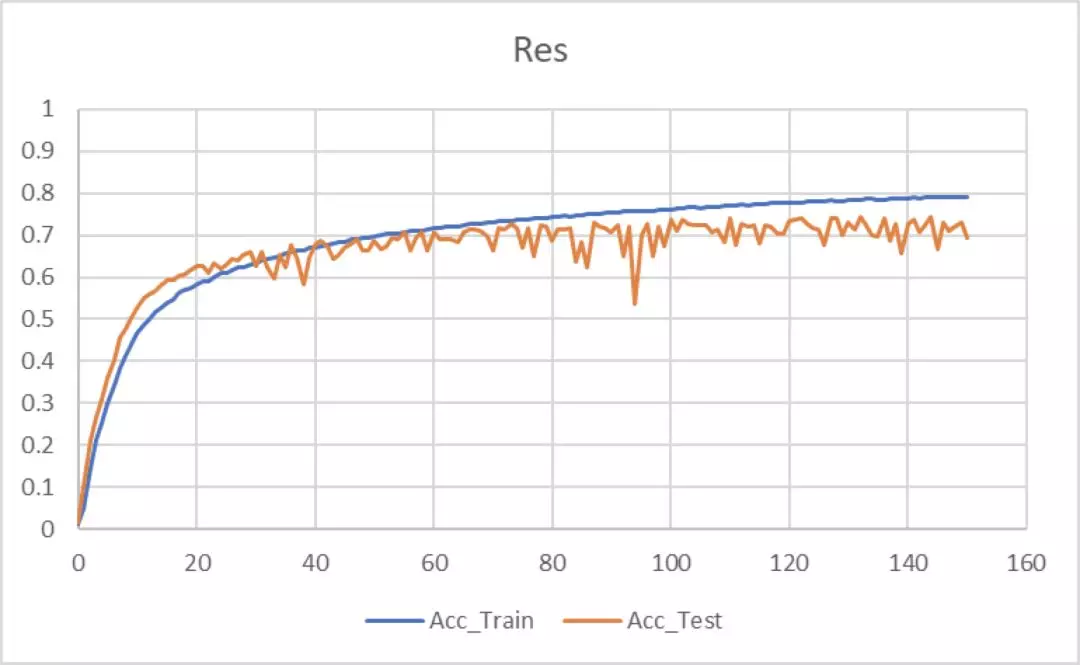
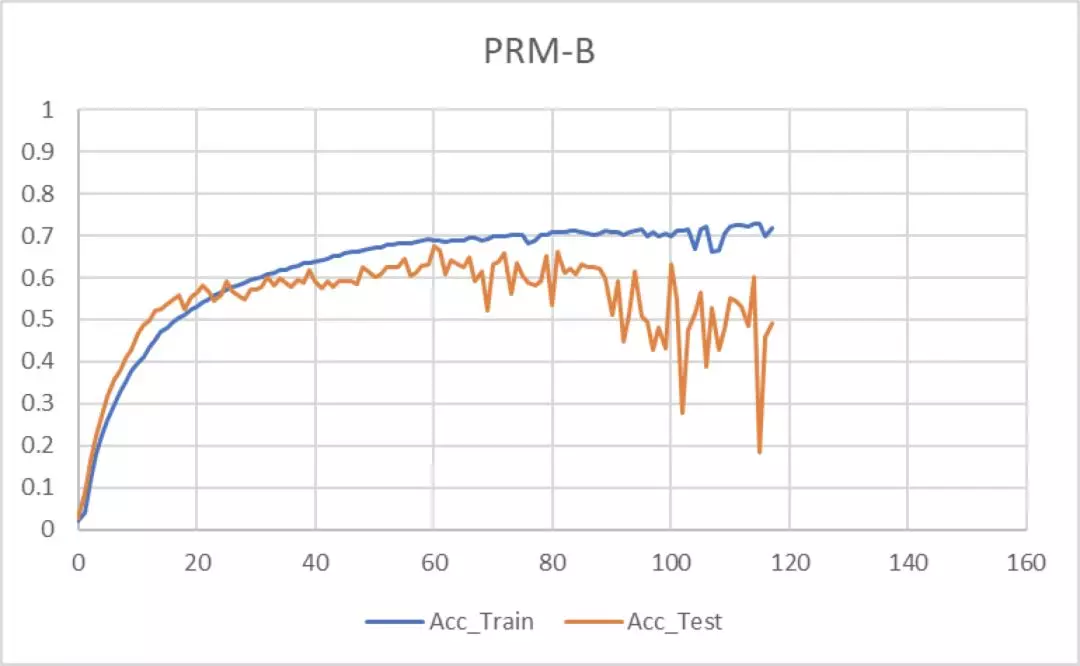
7. 結果對比分析:復現結果本應是使用 PRM-B 模塊的 PyraNet 要好於使用 Res 模塊的堆疊沙漏網絡,但結果卻相反。
在訓練時發現一個問題,即 PyraNet 很容易過擬合,調整多次都沒有得到很好的結果,而普通的堆疊沙漏網絡訓練則非常穩定。推測是由於加入了特徵金字塔結構,分支數太多,網絡變得複雜,所以難以訓練。由於時間關係,也沒有將網絡調試到最好狀態。

8. 結果可視化:下面是幾個使用 Res 模塊的堆疊沙漏網絡實驗結果的可視化,可以看到預測出了基本的人體姿勢。

關於PaddlePaddle
這是筆者第一次接觸並復現有關人體姿態預測的論文,也是首次嘗試使用 PaddlePaddle,並沒有取得很好的結果。
人體姿態檢測相比於簡單的圖片識別、生成,數據處理過程更復雜,計算量更大,網絡結構一旦變得複雜,就會變得難以訓練。同時網絡變得更大參數數量急劇增加,只能用很小的批大小進行訓練,也容易使得網絡陷入局部最小值。
而 PaddlePaddle 則是極具潛力的深度學習框架,很容易上手,目前還只是實現了最基本、最常見的一些操作,對於實現純卷積網絡來說非常便利,期待未來版本有更強大的功能和更好的使用體驗。
參考文獻
[1]. Newell A, Yang K, Deng J. Stacked Hourglass Networks for Human Pose Estimation[J]. 2016:483-499.
[2]. He K, Zhang X, Ren S, et al. Deep Residual Learning for Image Recognition[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2016:770-778.
[3]. Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions[J]. 2014:1-9.
[4]. Xie S, Girshick R, Dollar P, et al. Aggregated Residual Transformations for Deep Neural Networks[J]. 2016:5987-5995.
[5]. Chen L C, Papandreou G, Kokkinos I, et al. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs.[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2018, 40(4):834-848.
[6]. Glorot X, Bengio Y. Understanding the difficulty of training deep feedforward neural networks[J]. Journal of Machine Learning Research, 2010, 9:249-256.