最近,我們宣佈推出神經網絡機器學習(ML) 軟件 Arm NN,這是一項關鍵技術,可在基於 Arm 的高能效平臺上輕鬆構建和運行機器學習應用程序。

實質上,該軟件橋接了現有神經網絡框架(例如 TensorFlow 或 Caffe)與在嵌入式 Linux 平臺上運行的底層處理硬件(例如 CPU、GPU 或新型 Arm 機器學習處理器)。這樣,開發人員能夠繼續使用他們首選的框架和工具,經 Arm NN 無縫轉換結果後可在底層平臺上運行。
機器學習需要一個訓練階段,也就是學習階段(「這些是貓的圖片」),另外還需要一個推理階段,也就是應用所學的內容(「這是貓的圖片嗎?」)。訓練目前通常在服務器或類似設備上發生,而推理則更多地轉移到網絡邊緣,這正是新版本 Arm NN 的重點所在。
對象識別是在嵌入式平臺上運行的衆多機器學習工作負載之一
一切圍繞平臺
機器學習工作負載的特點是計算量大、需要大量存儲器帶寬,這正是移動設備和嵌入式設備面臨的最大挑戰之一。隨着運行機器學習的需求日益增長,對這些工作負載進行分區變得越來越重要,以便充分利用可用計算資源。軟件開發人員面臨的可能是很多不同的平臺,這就帶來一個現實問題:CPU 通常包含多個內核(在 Arm DynamIQ big.LITTLE 中,甚至還有多種內核類型),還要考慮 GPU,以及許多其他類型的專用處理器,包括 Arm 機器學習處理器,這些都是整體解決方案的一部分。
Arm NN 這時就能派上用場。
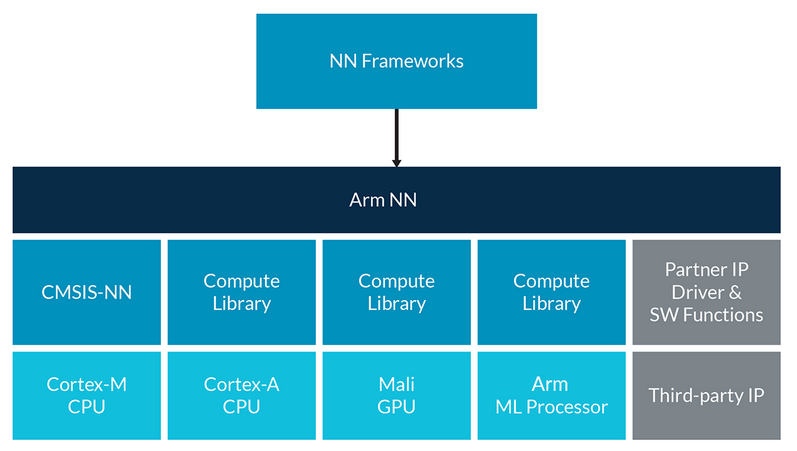
下圖中可以看出,Arm NN 扮演了樞紐角色,既隱藏了底層硬件平臺的複雜性,同時讓開發人員能夠繼續使用他們的首選神經網絡框架。
| 使用機器學習的應用程序 |
需要機器學習的已編寫應用程序 |
| TensorFlow、Caffe 等 |
繼續使用現有的高級別機器學習框架和支持工具 |
| Arm NN |
自動將上述格式轉換爲 Arm NN,優化圖表,並使用 Compute Library 中的函數,使其面向目標硬件 |
| Compute Library |
低級別的機器學習函數,針對各種硬件內核(目前爲 Cortex-A 和 Mali GPU)進行了優化 |
| CMSIS-NN |
低級別 NN 函數,針對 Cortex-M CPU 進行了優化 |
| 平臺 |
包含多個內核和內核類型(例如 CPU、GPU,今後還有 Arm 機器學習處理器) |

Arm NN SDK 概覽(首次發佈版本)
您可能已經注意到,Arm NN 的一個關鍵要求是 Compute Library,它包含一系列低級別機器學習和計算機視覺函數,面向 Arm Cortex-A CPU 和 Arm Mali GPU。我們的目標是讓這個庫彙集針對這些函數的一流優化,近期的優化已經展示了顯著的性能提升 – 比同等 OpenCV 函數提高了 15 倍甚至更多。如果您是Cortex-M CPU 的用戶,現在還有一個機器學習原語庫 – 也就是近期發佈的 CMSIS-NN。
主要優勢
有了 Arm NN,開發人員可以即時獲得一些關鍵優勢:
- 更輕鬆地在嵌入式系統上運行 TensorFlow 和 Caffe
- Compute Library 內部的一流優化函數,讓用戶輕鬆發揮底層平臺的強大性能
- 無論面向何種內核類型,編程模式都是相同的
- 現有軟件能夠自動利用新硬件特性
與 Compute Library 相同,Arm NN 也是作爲開源軟件發佈的,這意味着它能夠相對簡單地進行擴展,從而適應 Arm 合作伙伴的其他內核類型。
適用於 Android 的 Arm NN
在五月舉行的 Google I/O 年會上,Google 發佈了針對 Android 的 TensorFlow Lite,預示着主要新型 API 開始支持在基於 Arm 的 Android 平臺上部署神經網絡。表面上,這與 Android 下的 Arm NN SDK 解決方案非常相似。使用 NNAPI 時,機器學習工作負載默認在 CPU 上運行,但硬件抽象層 (HAL) 機制也支持在其他類型的處理器或加速器上運行這些工作負載。Google 發佈以上消息的同時,我們的 Arm NN 計劃也進展順利,這是爲使用 Arm NN 的 Mali GPU 提供 HAL。今年晚些時候,我們還將爲 Arm 機器學習處理器提供硬件抽象層。
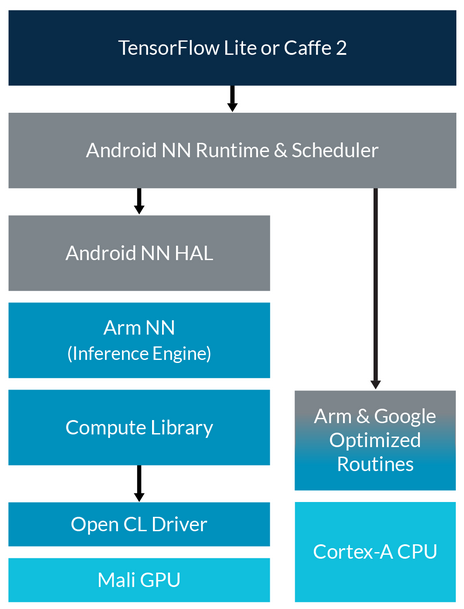
Arm 對 Google NNAPI 的支持概覽
您可以在此處閱讀有關這項工作的更多內容:Arm 對 Android NNAPI 的支持實現了 4 倍以上的性能提升
CMSIS-NN
CMSIS-NN 是一系列高效神經網絡內核的集合,其開發目的是最大程度地提升神經網絡的性能,減少神經網絡在面向智能物聯網邊緣設備的 Arm Cortex-M 處理器內核上的內存佔用。我們開發這個庫的目的是全力提升這些資源受限的 Cortex CPU 上的神經網絡推理性能。藉助基於 CMSIS-NN 內核的神經網絡推理,運行時/吞吐量和能效可提升大約 5 倍。
您可以在此處閱讀更多相關內容:新型 CMSIS-NN 神經網絡內核將微控制器性能提升大約 5 倍
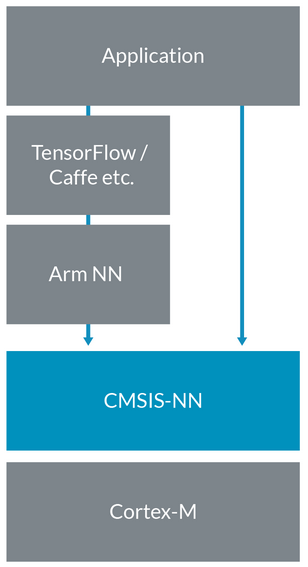
Arm NN 的未來發展
這只是 Arm NN 的第一步:我們還計劃添加其他高級神經網絡作爲輸入,對 Arm NN 調試程序執行進一步的圖形級別優化,覆蓋其他類型的處理器或加速器……請密切關注今年的發展!
有用的鏈接
相關內容
相關的機器學習資源
