1. 簡介
人工智能的一個主要目標就是構建能夠對感官環境進行強有力並且靈活地推理的系統 [1]。視覺提供了一個極其豐富和高度實用的領域,我們可以在其中通過建立系統對複雜的刺激執行邏輯推理 [2,3,4,5]。研究視覺推理的一個途徑是對視覺問答 ( VQA ) 數據集進行建模,模型可以從中學習正確地回答關於靜態圖像的挑戰性自然語言問題 [6,7,8,9]。儘管這些多模態數據集已經有了很大進步,但是目前的方法還存在幾個侷限性。首先,與推理一個問題的邏輯組成不一樣,在 VQA 數據集上訓練的模型剛好遵循圖像中的固有統計特性的程度是不確定的 [10,11,12,13]。其次,這些數據集都避開了時間和記憶的複雜性,而這兩者都是智能體設計 [1,14,15,16] 與視頻分析、總結 [17,18,19] 中不可或缺的因素。

圖 1. COG 數據集中的樣本序列和指令。COG 數據集中的任務是測試目標識別、關係理解以及爲解決問題而進行的記憶操作和適應。所有問題都可能涉及到當前圖像和之前圖像中的目標。注意在最後一個例子中,指令涉及到最後一個但不是最近一個「b」。前者排除了在當前圖像中尋找「b」。白色箭頭表示每個圖像的目標響應。
爲了解決 VQA 數據集中與空間關係的邏輯推理相關的缺點,Johnson 等人 [10] 最近提出了 CLEVER 來直接用於基本視覺推理模型的測試,以便與其他 VQA 數據集相結合 (例如,[6,7,8,9])。CLEVR 數據集提供了人工靜態圖像和關於這些圖像的自然語言問題,讓模型學習執行邏輯和視覺推理。最近研究中人們開發出來的網絡能夠達到幾乎完美的準確率 [5,4,20]。
在這項工作中,研究者解決了視覺推理中的第二項限制,即關於時間和記憶的限制。推理智能體必須記住它的視覺歷史中相關的片段,忽略不相關的細節,基於新的信息來更新和操作記憶,以及在後面的時間裏利用這些記憶來作出決策。作者的方法就是創建一個人工的數據集,它具有時變數據中存在的很多複雜性,同時也避免了處理視頻時的很多視覺複雜性和技術難題(例如,視頻解碼、時間平滑幀之間的冗餘)。特別是,作者從認知心理學 [21,22,23,24,25] 和現代系統神經科學 [26,27,28,29,30,31] 最近幾十年的研究中得到啓發。這些領域有着基於空間和邏輯推理、記憶組成和語義理解將視覺推理分解爲核心組件的悠久研究傳統。爲此,作者建立了一個稱爲 COG 的人工數據集,它也能用於人類的認知實驗 [32,33,34],並能夠及時地訓練視覺推理。
COG 數據集是基於一種能夠構建三元組任務集的編程語言開發的:三元組包含圖像序列、語言指令以及正確答案的序列。這些隨機生成的三元組能夠在大量的任務序列中訓練視覺推理,解決它們需要對文本的語義理解,對圖像序列中每張圖像的視覺認知,以及決定時變答案的工作記憶(圖 3)。研究者在編程語言中特別強調了幾個參數,開發者可以通過這些參數來從易到難地設定挑戰性環境,從而對問題難度進行調製。
最後,作者引入了用於有記憶視覺推理的多模態循環架構。該網絡將語義、視覺模塊與狀態控制器相結合,狀態控制器調節視覺注意力和記憶,以便正確執行視覺任務。他們證明了該模型在 CLEVER 數據集上取得當前最佳的性能。此外,該網絡還提供了穩健的基線,其可以在 COG 數據集的一系列設置中實現良好的性能。通過控制變量研究和對網絡的動態分析,他們發現網絡採用人類可解釋的注意力機制來解決這些視覺推理任務。作者希望 COG 數據集、與之對應的網絡架構和相關的基線結果能夠爲研究時變視覺刺激下的推理提供一個有用的基準。
3.COG 數據集
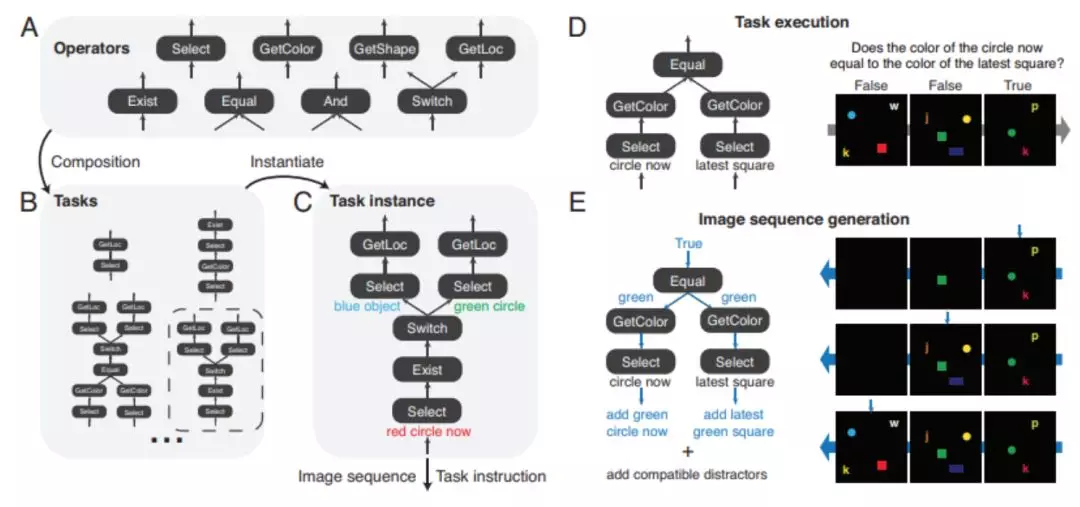
圖 2. 生成綜合的 COG 數據集。COG 數據集基於一系列的運算符(A), 這些運算符被組合以形成各種任務圖 ( B )。( C ) 通過在任務圖中指定所有運算符的屬性來實例化任務。任務實例用於生成圖像序列和語義任務指令。( D ) 正向傳遞圖形和圖像序列以用於正常任務執行。( E ) 生成一致的、偏差最小化的圖像序列需要以反向拓撲順序向後傳遞任務圖,並且以反向時間順序向後傳遞圖像序列。
4. 網絡
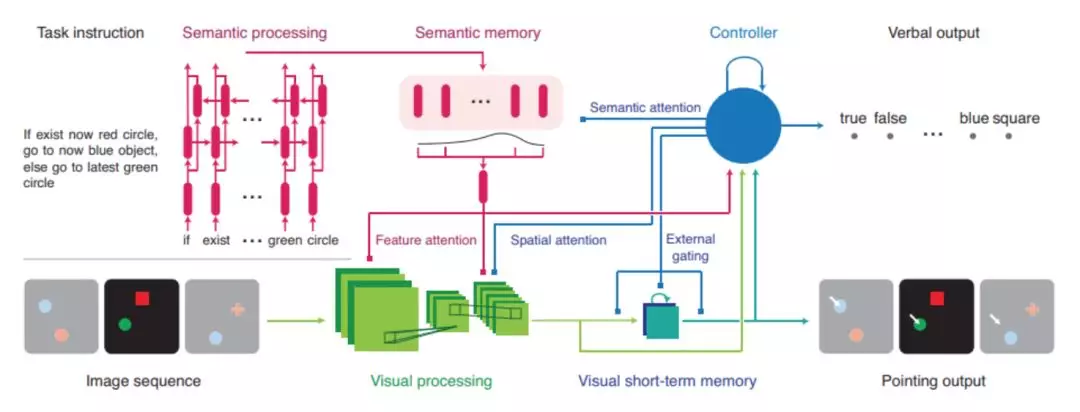
圖 3. 本文提出的網絡。圖像序列被用來作爲卷積神經網絡 ( 綠色部分) 的輸入。英語文本形式的指令被輸入到順序嵌入網絡 (紅色) 中。視覺短期記憶 ( vSTM ) 網絡及時保存視覺空間信息並提供指向輸出 ( 藍綠色 )。vSTM 模塊可以被認爲是具有外部門控的卷積 LSTM 網絡。狀態控制器 (藍色部分) 直接或間接提供所有注意和門控信號。網絡的輸出是離散的 (語言) 或 2D 連續的 (指向的)。
5. 結果
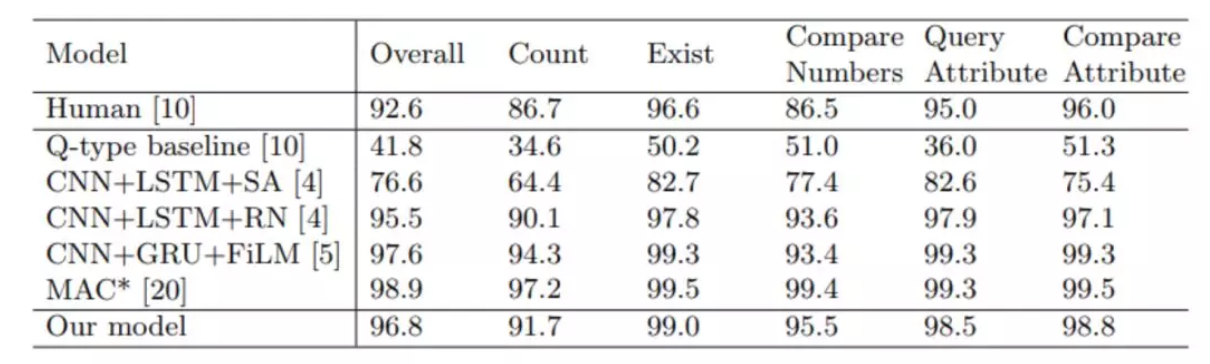
表 1. CLEVER 上的測試準確率:人類、基線、僅靠訓練中的任務指令和像素輸入的性能頂尖模型,以及本文提出的模型。(*)代表的是所用的預訓練模型。
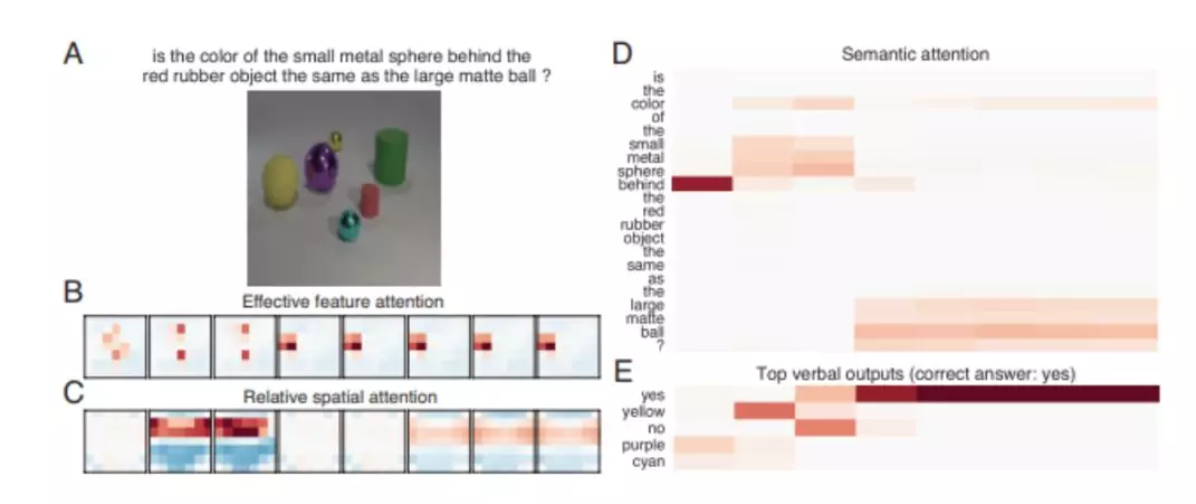
圖 4. 本文提出網絡的工作時的思想過程,通過可視化單個 CLEVER 樣本的注意力和輸出來展示。( A ) 來自 CLEVER 驗證集的示例問題和圖像。( B ) 每個思考步驟的有效特徵注意圖。(C) 相關的空間注意力圖。(D) 語義注意力。( E ) 排名前 5 的語詞輸出。紅色和藍色分別表示較強和較弱。在同時特徵注意到「小金屬球」和空間注意到「位於紅色橡膠目標之後」,被關注物體的顏色 (黃色) 反映在語詞輸出中。在後來的思考過程中,網絡特徵注意的是「大亞光球」,而正確的答案 (是) 出現在語詞輸出中。
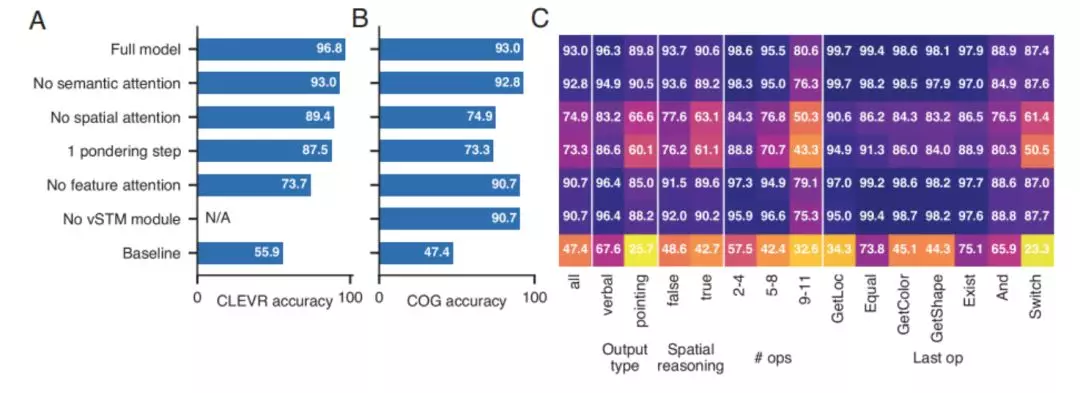 圖 5. 控制變量研究。CLEVER 測試集在不同的模型上的總體準確率; A 和 B 分別是 CLEVER 數據集和 COG 數據集:CLEVR 數據集的相關模型中未包含任何 vSTM 模塊。(C)基於輸出類型、是否涉及空間推理、操作符的數量以及任務圖中的最後一個操作符來分析 COG 的準確率。
圖 5. 控制變量研究。CLEVER 測試集在不同的模型上的總體準確率; A 和 B 分別是 CLEVER 數據集和 COG 數據集:CLEVR 數據集的相關模型中未包含任何 vSTM 模塊。(C)基於輸出類型、是否涉及空間推理、操作符的數量以及任務圖中的最後一個操作符來分析 COG 的準確率。
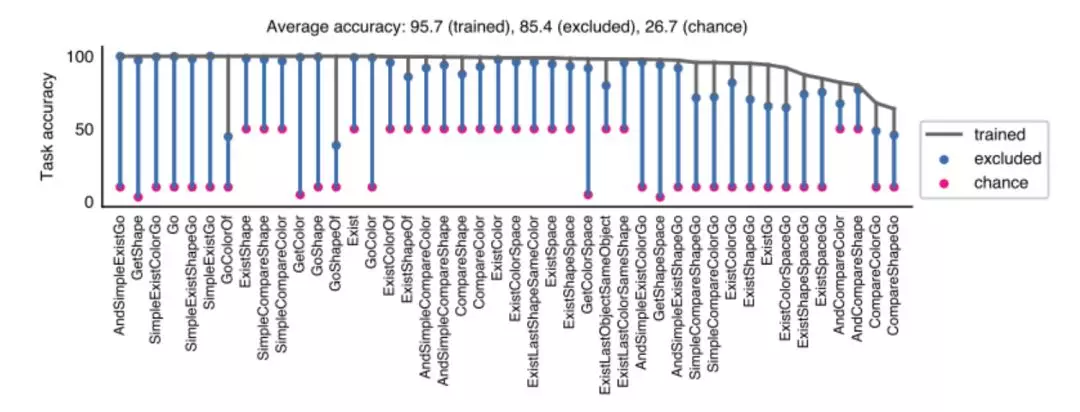
圖 7. 本文提出的網絡可以零樣本地推廣到新任務。用 44 個任務中的 43 個任務訓練了 44 個網絡。如圖所示是 43 個已訓練任務 (灰色) 的最大性能,遷移到一個沒有經過訓練的任務 (藍色) 的最大性能,以及在這個任務上的機會水平(紅色)。
論文:A dataset and architecture for visual reasoning with a working memory

論文鏈接::https://arxiv.org/pdf/1803.06092.pdf
摘要:人工智能中存在一個令人煩惱的問題,就是對複雜的、不斷變化的視覺刺激中發生的事件進行推理 (如視頻分析或遊戲)。受認知心理學和神經科學中豐富的視覺推理和記憶的傳統研究所啓發,我們開發了一個人工的、可配置的視覺問答數據集 ( COG ),這個數據集可用於人類和動物的實驗。儘管 COG 比視頻分析的一般問題簡單得多,但它解決了許多與視覺、邏輯推理以及記憶相關的問題,這些問題對現代深度學習架構來說仍然具有挑戰性。此外,我們還提出了一種深度學習架構,該架構在其他診斷 VQA 數據集 (即 CLEVER) 以及 COG 數據集的簡單設置上具有競爭力。但是,COG 的某些設置可以令數據集的學習越來越困難。經過訓練,該網絡可以零樣本地泛化到許多新任務。對在 COG 上訓練的網絡架構的初步分析表明,該網絡以人類可理解的方式完成任務。