選自TowardsDataScience
作者:Anuradha Wickramarachchi
在機器學習中,絕大多數任務會涉及到耗費時間的大量運算,而且隨着數據集的增加,運算量會越來越大。解決這個問題的一個方法就是使用多線程。在這篇文章中,我要結合代碼介紹一下 GPU 加速,它是如何完成的,以及用於 GPU 任務的簡單 API。下面以一個矩陣乘法開始全文內容。
矩陣乘法
上面給出了兩個矩陣,一個 3×6 的,一個 6×6 的。乘積的結果將會是一個 3×6 的矩陣。完成這個運算總共需要 3×6×6 次乘法運算。那麼,我們可以得到這樣的結論:這個任務的時間複雜度是 O(mn^2)。這也就意味着,2000×2000 的矩陣運算將會需要 8,000,000,000 次乘法運算。這會花費大量的 CPU 計算時間。
引入 GPU
通常 GPU 會包含大量的處理核心。核心數目從 384 個到幾千個。下面是 NVIDIA 幾款消費級 GPU 的比較(https://www.nvidia.com/en-us/geforce/products/10series/compare/):
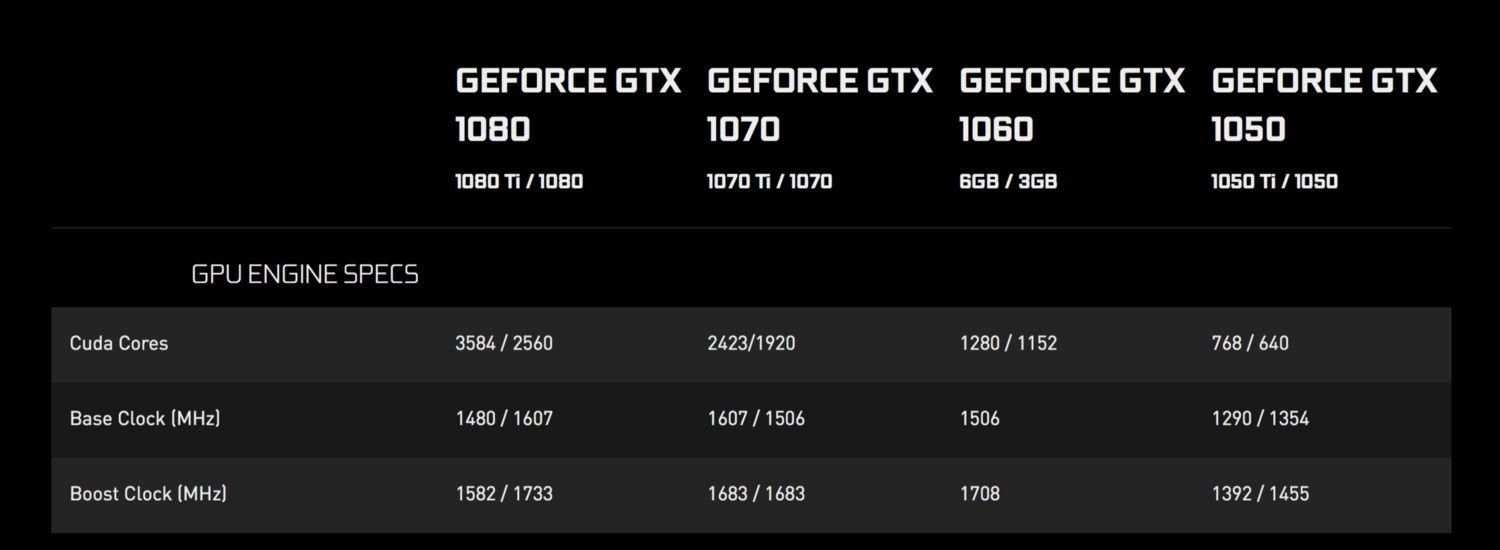
CUDA 核數目
CUDA 是統一計算設備架構(Compute Unified Device Architecture)的縮寫。它們以相對稍慢的速度運行,但是能夠通過使用大量運算邏輯單元(ALU)來提供很大的並行度。更詳細內容請參考鏈接(http://www.nvidia.com/object/what-is-gpu-computing.html)。
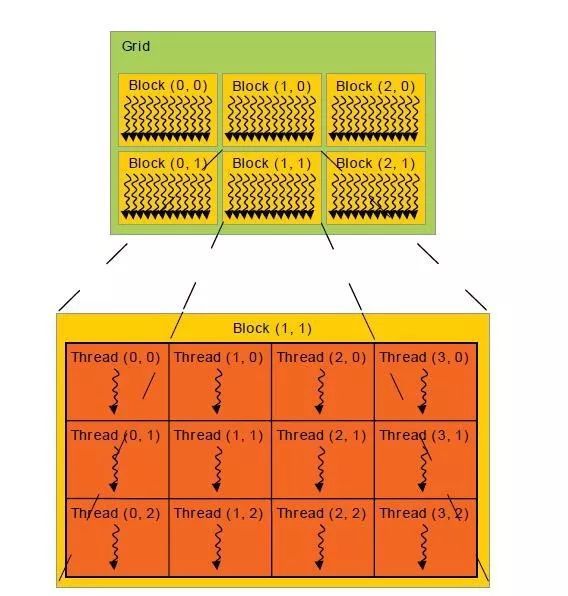
CUDA 線程模型
這張圖展示了 CUDA 的線程模型(這個和市場上其他的架構幾乎是相同的,例如 AMD)。簡單起見,我們假設一每個 CUDA 核一次只能運行一個線程。如果我們的數據集比較大,我們可以將它分成塊。上圖中的一個 Grid 包含多個 Block。Block 則是另一個包含與它維度相同個數的線程的矩陣。總之,由於這是一個簡介,所以我們要以一個用 Java 開發的簡單 API 來聚焦更大更復雜的結構。
GPU 的思考
正如我們討論到的,每個 GPU 核心都能運行一個獨立的線程。開始這個模擬的最簡單的方式就是假設最終結果數組中的每個元素都由一個 GPU 核來計算。因爲所有的核都是並行運行的,所有矩陣的所有元素也會被並行的計算。所以,我們現在的時間複雜度就變成了 O(n)。現在,對於 2000×2000 的矩陣乘法,我們只需要 2000 次運行,這對計算機而言是容易計算的。通常我們之前所說的每一個線程都知道自己的身份,也就是它所屬於的 block 和 Grid。或者,說得簡單一些就是元素在矩陣中的位置。此外,矩陣會被加載到 GPU 中共享它的內存,我們可以通過索引直接訪問元組中的數據。是不是很容易?我們對着代碼來看一看吧。
使用 APARAPI 進行 GPU 編程
APARAPI(A-PARallel-API)是一個基於 OpenCL 的用於 GPU 編程的 wrapper。它既支持 CUDA 架構,也支持 AMD 架構。此外,這個 API 還引入了 Java 中的偉大的面向對象思想,如果我們直接用 C++來完成這個任務的話也許會有些混亂。上手非常容易。雖然其中有內在依賴項,但是要確保你正確地設置了 OpenCL 或者 CUDA。簡單的 Google 一下會幫助到你。大多數設備都是自帶的(OSX 或者 windows 設備)。
pom.xml
xml version="1.0"encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0 modelVersion>
<groupId>cuda-aparapi groupId>
<artifactId>cuda artifactId>
<version>1.0-SNAPSHOT version>
<dependencies>
<dependency>
<groupId>com.aparapi groupId>
<artifactId>aparapi artifactId>
<version>1.4.1 version>
dependency>
dependencies>
project>
importcom.aparapi.Kernel;
importcom.aparapi.Range;
/**
*Createdby anuradhawick on 12/29/17.
*/
public classMatrixMultiplication{
public static void main(String[]args){
//Widthof the matrix
final int SIZE =5000;
//Weshould use linear arrays assupported by the API
final int[]a =new int[SIZE *SIZE];
final int[]b =new int[SIZE *SIZE];
int[]c =new int[SIZE *SIZE];
final int[]d =new int[SIZE *SIZE];
int val;
//Creatingrandom matrices
for(int i =0;i <SIZE;i++){
for(int j =0;j <SIZE;j++){
a[i *SIZE +j]=(int)(Math.random()*100);
b[i *SIZE +j]=(int)(Math.random()*100);
}
}
long time =System.currentTimeMillis();
//CPU multiplication
System.out.println("Starting single threaded computation");
for(int i =0;i <SIZE;i++){
for(int j =0;j <SIZE;j++){
val =0;
for(int k =0;k <SIZE;k++){
val +=a[i *SIZE +k]*b[k *SIZE +j];
}
c[i *SIZE +j]=val;
}
}
System.out.println("Task finished in "+(System.currentTimeMillis()-time)+"ms");
//Kernelformultiplication
Kernelkernel =new Kernel(){
@Override
public void run(){
int row =getGlobalId()/SIZE;
int col =getGlobalId()%SIZE;
if(row >SIZE ||col >SIZE)return;
d[row *SIZE +col]=0;
for(int i =0;i <SIZE;i++){
d[row *SIZE +col]+=a[row *SIZE +i]*b[i *SIZE +col];
}
}
};
//Arraysize forGPU to know
Rangerange =Range.create(SIZE *SIZE);
System.out.println("Starting GPU computation");
time =System.currentTimeMillis();
kernel.execute(range);//Runningthe Kernel
System.out.println("Task finished in "+(System.currentTimeMillis()-time)+"ms");
//Verifyingthe result
for(int i =0;i <SIZE;i++){
for(int j =0;j <SIZE;j++){
if(c[i *SIZE +j]!=d[i *SIZE +j]){
System.out.println("ERROR");
return;
}
}
}
}
}
上述代碼的精簡化
Kernel 就是在 GPU 上運行的代碼部分。Kernel 可見的變量將會被拷貝到 GPU 的 RAM 中。我們因爲 GPU 支持線性數組,所以我們不能以 2D 數組的形式輸入數據。GPU 不能處理 2D 數組,但是它們是通過維度的概念來處理的(此處暫且不討論這個內容)。
Rangerange =Range.create(SIZE *SIZE);
上述代碼在 GPU 中分配了小於等於 SIZE × SIZE 個線程。
int row =getGlobalId()/SIZE;
int col =getGlobalId()%SIZE;
上述代碼從私有內存中得到了線程的 ID。我們可以通過這個 ID 來區分這個線程單元的位置。對每個線程我們做以下處理:
for(int i =0;i <SIZE;i++){
d[row *SIZE +col]+=a[row *SIZE +i]*b[i *SIZE +col];
}
這是兩個矩陣對應單元相乘相加的最簡單的形式。我們只爲使用線程索引的單個線程定義了 Kernel,它將會在所有的線程上並行運行。
結果
運算是很快的,但是有多快呢?這個是上述代碼的輸出:
1200 × 1200
Startingsingle threaded computation
Taskfinished in25269ms
StartingGPU computation
Taskfinished in1535ms
由於下面的矩陣比較大,所以我們只在 GPU 上運行以下的運算。
2000 × 2000 的矩陣運算耗時 3757ms
5000 × 5000 的矩陣運算耗時 5402ms
自己也嘗試一下?
原文鏈接:https://towardsdatascience.com/an-introduction-to-gpu-optimization-6ea255ef6360
GPU Taiwan Facebook關注AI與人工智慧、智慧城市、智能駕駛、智慧機器、Fintech、未來醫療、AR/VR、智能硬件、物聯網
https://www.facebook.com/groups/marketing.gpu