原標題 Understanding Neural Networks by embedding hidden representations,作者爲 Rakesh Chada。

從 https://rakeshchada.github.io/Neural-Embedding-Animation.html 交叉發佈。
可視化神經網絡總是很有趣的。例如,我們通過神經元激活的可視化揭露了令人着迷的內部實現。對於監督學習的設置,神經網絡的訓練過程可以被認爲是將一組輸入數據點變換爲可由線性分類器分離而表示的函數。所以,這一次,我打算通過利用這些(隱藏的)的表示來產生可視化,從而爲這個訓練過程帶來更多內部細節。這種可視化可以揭示和神經網絡性能相關的有趣的內部細節。
我集思廣益了幾個想法,最終從優秀的 Andrej Karpathy 的工作中獲得了很好的靈感。
這個想法很簡單,可以在下面的步驟中簡要說明:
訓練一個訓練網絡。
一旦訓練完成,就爲驗證/測試數據中的每個數據點生成最終的隱藏表示(嵌入)。這種隱藏的表示基本上是神經網絡中最後一層的權重。這種表示是神經網絡對數據進行分類的一種近似表示。
出於可視化目的,將這些權重的維度降低爲 2-D 或 3-D。然後,在散點圖上可視化這些點,以查看它們在空間中的分離情況。我們可以使用流行的降維技術,例如 T-SNE 或 UMAP。
雖然上面的插圖顯示了訓練結束後的數據點,但我認爲訓練過程中在多個點上對數據點進行可視化是一個有趣的擴展。然後,可以單獨檢查每個可視化,並獲得相關數據如何變化的一些細節。例如,我們可以在每個 epoch 之後產生一個這樣的可視化,直到訓練完成,並看看它們如何比較。對此的進一步擴展將是產生這些可視化的動畫。這可以通過採用這些數據點的靜態可視化並在它們之間插入點來完成--從而引起逐點過渡。
這個想法讓我很興奮,於是我繼續開發了基於 D3.js 的 Javascript 工具,使我們能夠生成這些可視化。它允許我們生成靜態可視化和動畫。對於動畫,我們需要上傳兩個包含我們想要比較的隱藏表示的 csv 文件,並且可以爲這些文件設置動畫。我們還可以控制動畫,因此我們可以觀察到一組特定數據點在訓練過程中如何移動。
鏈接到工具:神經嵌入動畫生成器https://bl.ocks.org/rakeshchada/raw/43532fc344082fc1c5d4530110817306/
工具的說明文檔:README https://bl.ocks.org/rakeshchada/43532fc344082fc1c5d4530110817306
這絕不是一個複雜的工具。我只是想快速可視化我的一些想法。
動畫可視化的一大特色 -- 我應該提前說明 -- 在執行 T-SNE/UMAP 之後會出現每個 2-D/3-D 表示中的不一致性。首先,在設置超參數、隨機種子等時必須格外小心。其次,據我所知,T-SNE 只是試圖嵌入類似物體出現在附近而將不同物體在遠處分開。因此,當我們對兩個可視化進行動畫處理時,比如 epoch1 和 epoch2,可能不容易區分純隨機性引起的變化與來自神經網絡實際學習的權重變化。也就是說,在我的實驗中,我有時能夠製作合理的動畫,幫助我獲得有趣的見解。
此可視化框架有多個有趣的應用程序,以下是分類問題的一些背景:
更好地理解模型的行爲 w.r.t 數據
瞭解神經網絡訓練過程中數據表示的變化
比較給定數據集上的模型 - 包括超參數變化甚至架構變化
瞭解嵌入在訓練過程中如何及時(在調整時)發生變化
本文的其餘部分通過具體的示例說明了上述背景。
更好地理解模型的行爲 w.r.t 數據
惡意評論分類任務
我們在這裏使用的第一個例子是來自 Kaggle 的這個有趣的自然語言處理競賽,當時我正在開發這個工具。目標是將文本評論分爲不同類別 - 有毒,淫穢,威脅,侮辱等。這是一個多標籤分類問題。
在神經網絡模型中,我嘗試了幾種架構,從簡單的(沒有卷積/重複的前饋神經網絡)到複雜的架構。我在神經網絡的最後一層使用了二進制交叉熵損失和 sigmoid 激活。這樣 -- 它只爲每個標籤輸出兩個概率 -- 從而實現多標籤分類。我們將使用來自雙向 LSTM 的隱藏表示,該雙向 LSTM 使用未經訓練的預訓練詞嵌入進行初始化,來完成此次演示。
所以我做了上述相同的步驟 -- 從最後一層提取驗證集中的每個文本註釋的隱藏表示,到執行 T-SNE/UMAP 將它們縮小到 2 維並使用該工具可視化它們。在停止之前每個訓練持續了 5 個 epoch。使用 UMAP 的一個優點是它的速度提高了一個數量級,並且仍能產生高質量的表現。谷歌確實發佈了實時 TSNE,但我還沒有去探索。
這是在第 5 個 epoch 結束時可視化的放大版本。可視化的類是侮辱。所以紅點是侮辱,綠點是非侮辱。
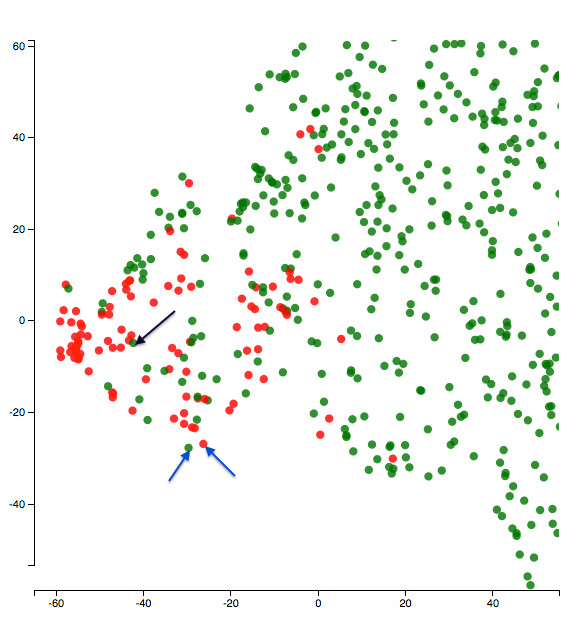
關於惡意評論分類任務的第 5 個 epoch 後的隱藏表示。
讓我們從一個有趣的地方開始,看看上面藍色箭頭指向的兩個點。其中一個是侮辱,另一個則不是。文本說了什麼?
文本 1(帶藍色箭頭的綠點):「廢話廢話廢話廢話廢話廢話」。
文本 2(帶藍色箭頭的紅點):「我討厭你我討厭你我討厭你我討厭你我討厭你我討厭你我恨你」。
模型如何將兩個重複的文本放在一起,這很有趣。而且侮辱的概念在這裏似乎很微妙!
我也好奇地看着紅色星團中心的一些綠點。爲什麼模型會對它們感到困惑?他們的文本會是什麼樣的?例如,這是上圖中黑色箭頭指向的點的文字:
「不要把我稱爲麻煩製造者,你和他一樣,你就像 XYZ 一樣是種族主義的右翼分子」(審查和名稱遺漏是我的 -- 他們在文本中不存在)。
嗯,這似乎是一種侮辱 -- 所以它看起來像一個糟糕的標籤!應該用一個紅點代替!
可能並非所有這些錯位都是壞標籤,但如上所述,我們可以通過可視化深入挖掘數據的所有這些特徵。
我也認爲這有助於我們找到諸如標記化/預處理之類的事物對模型性能的影響。在上面的文本 2 中,如果有適當的標點符號,它可能對模型有所幫助 -- 在每次」討厭你「之後可能是一個句號。還有其他一些例子,我認爲大寫可能有所幫助。
Yelp 審查情緒分類任務
我還想在不同的數據集上嘗試這種方法。所以我選擇了來自 Kaggle 的 yelp 評論數據集並決定實現一個簡單的情緒分類器。我將星級評分轉換爲二進制 -- 使事情變得更容易一些。所以 -- 1,2 和 3 星是負面的,4 星,5 星是積極的評論。同樣,我從一個簡單的前饋神經網絡架構開始,該架構對嵌入進行操作,展平它們,發送給全連接層並輸出概率。這是 NLP 分類任務的非常規架構 -- 但我很想知道它是如何做的。在提前停止前我們完成了 10 個 epoch 的訓練。
這是最後一個 epoch 可視化的內容:
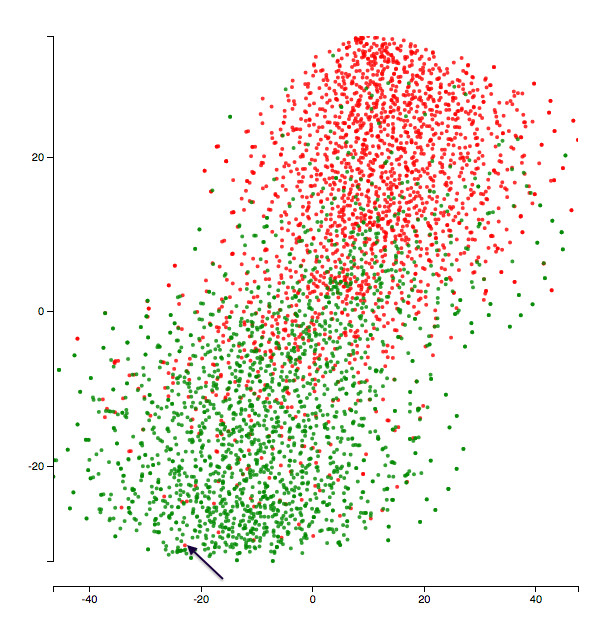
yelp 二元情緒分類任務在第 10 個 epoch 之後的隱藏表示。
黑色箭頭指出的文字說:
每次去這裏的時候,食物一直很美味。不幸的是服務不是很好。所以我再次光顧只是因爲我喜歡這裏的食物。
它看起來像箇中性的評價甚至更傾向於積極面。所以模型把這個點歸類在積極類也不是毫無道理。此外,這個模型將每個單詞單獨處理(沒有 n-gram 模型),這可能解釋了爲什麼模型會漏掉上面「不太好」中的「不」字之類的東西。下面是與上述負面點最接近的積極點的文本。
「喜歡這個地方。 簡單的拉麪與非常基本的菜單,但總是有美味和優質的服務相伴。 價格合理,氣氛優雅。 絕對將其歸類爲附近的精品店。「
模型將上面的兩個文本置於非常接近空間的事實可能重新證實了模型的侷限性(諸如不捕獲 n-gram 之類的東西)。
我有時想象這種分析可以幫助我們理解哪些例子對於模型來說是「困難」vs「簡單」。可以通過對比錯誤分類的點和它們附近的點來理解這個問題。一旦我們有了一些理解,我們就可以使用這些知識來添加更多個性化的功能,以幫助模型更好地理解這些示例,或者更改模型的結構以便更好地理解那些「困難」示例。
瞭解神經網絡訓練過程中數據表示的演變
我們將使用動畫來理解這一點。我通常理解動畫可視化的方式是選擇一個點的子集並觀察他們的鄰域如何在訓練過程中發生變化。我想象當神經網絡逐漸學習時,鄰域變得越來越代表手頭進行的分類任務。或者換句話說,如果我們定義相對於分類任務的相似性,那麼當網絡學習時,類似的點將在空間中越來越接近。上面工具中的滑塊可幫助我們控制動畫,同時密切關注一組點的變化。
下面的動畫顯示了在毒性評論分類任務中,數據的隱藏表示如何在 4 個 epoch(第 2-5 個 epoch)的過程中進化。我選擇了一小組點,因此很容易觀察它們是如何移動的。綠點代表無毒類,紅點代表有毒類。

第 2-5 epoch 中隱藏表示的動畫
有一些點對(如 F 和 G 、 C 和 I)在四處舞動,而另一些點對(如 D 和 K、 N 和 O)始終離的很近。
因此,當我手動查看與這些點相對應的句子時,我有時可以瞭解到那個 epoch 神經網絡可能學到了什麼。如果我看到兩個完全不相關的句子靠近在一起(例如,在 epoch2 中的 E 和 F),那麼我想模型還需要再進行一些學習。我有時會看到神經網絡將有相似的單詞的句子放在一起 - 儘管整個句子的含義是不同的。我確實看到這種影響隨着訓練的進行(驗證損失減少)逐漸消失。
正如帖子開頭所提到的,這種行爲並不能保證一致。 絕對存在一些時候一個點的鄰域根本沒有任何意義。 但我確實希望 - 通過製作這些動畫 - 並注意點數運動的任何顯着變化,我們將能夠得出一些有用的見解。
我還使用yelp數據集重複了相同的實驗並發現了類似的東西。
在訓練了一個 epoch 以後的神經網絡是這樣的:
Yelp - epoch 1之後的表示(綠色爲積極情緒,紅色爲負面情緒)
這兩個類之間有很多重疊,網絡還沒有真正學會一個清晰的邊界。
以下一個動畫,表示在 5 個 epoch 訓練之後表現形式的演變:

Yelp - epoch1 到 5 中隱藏表示的動畫
你可以看到兩類點在各自的類方面變得更密集,並且網絡在分離這兩個類方面做得更好。
旁註:我現在做的動畫是爲了表示 epoch 之間代表性變化。但是沒有理由表示人們不可以進一步細化 - 比如使用迷你批次或半個 epoch 或者其他的。這可能有助於發現更細微的變化。
模型比較
這同樣是一個比較直觀的做法。我們僅僅選取想比較模型在最後一個 epoch 結束時模型的表示,並將它們插入到工具中。
在這裏我用於比較的兩個模型是一個簡單的前饋神經網絡(沒有卷積和循環)和一個雙向的 LSTM 模型。它們都使用預先訓練的詞嵌入進行初始化。
因此對於毒性和淫穢類評論的分類挑戰,以下是模型之間表示的變化。
所有紅點表示淫穢類,綠點代表非淫穢類。

前饋神經網絡和雙向LSTM網絡隱層展示的動畫
可以看出雙向LSTM在區分這兩類上表現更好。
詞嵌入可視化
我應該說我喜歡詞嵌入,在任何 NLP 相關分析中它們都是我必須嘗試的。 這個框架應該特別適合詞嵌入。那麼讓我們看看我們可以如何理解它的使用。
下面這個例子是有關詞嵌入在 yelp 任務上如何變化的動畫。它們使用 50 維度的 Glove 詞向量進行初始化。
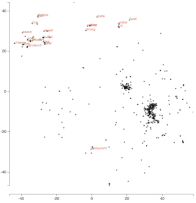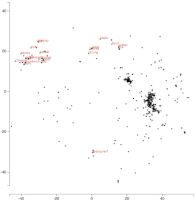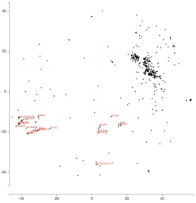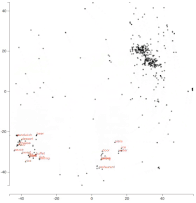
詞嵌入隨着在 yelp 數據集上調整的變化
令人着迷的是,「食物」這一詞一開始與「拉麪」,「豬肉」等實際的食物相距甚遠。隨着我們對嵌入物進行調整,它們之間的距離逐漸開始縮小。所以這個模型可能學習到了所有那些「拉麪」,「豬肉」等都是食物實例。同樣,我們也看到「餐桌」靠近「餐廳」等等。動畫可以很容易地發現這些有趣的模式。
另一個可以嘗試的有趣的事情是對工具進行反向工程並進行一些自定義分析。例如,我很好奇有毒詞的嵌入如何在上述毒性評論分類任務中發生變化。我在上面的毒性評論分類任務中創建了一個模型,從頭開始學習嵌入(因此沒有使用預先訓練的嵌入進行權重初始化)。我想在給定數據量的情況下對模型有點困難 - 但我認爲這值得一試。該架構與雙向 LSTM 相同。因此,我只是將所有有毒詞彙染成紅色並在動畫中跟蹤它們。這是嵌入式如何變化的動畫:(PG-13 預警!!)

在有害評論數據中從頭開始學習的詞嵌入的變化
這看起來不是很迷人嗎?該模型將咒罵詞(代表毒性)分成一個漂亮的小簇。
我希望這篇文章能夠闡明以不同方式可視化數據點的隱藏表示以及它們如何揭示有關模型的有用見解。我期待將這些分析應用於越來越多的機器學習問題。並希望其他人考慮相同並從中獲益。我相信他們會幫助機器學習模型更不像一個黑盒子!
如果您認爲合適,請隨時提供任何反饋!
PS:我嘗試使用PCA將隱藏表示降維到2維,然後從中生成動畫。PCA的一個好處是它不具有概率性,因此最終的表示是一致的。然而,PCA中的局部鄰域不如T-SNE那樣可解釋。 所以這是一個權衡,但如果有人對如何充分利用這兩個方面有其他想法,非常感謝!