選自GitHub
ICLR 2018 大會的論文評審已經於 11 月 27 日截止。在明年 1 月 5 日之前,人們將對目前提交的論文進行討論。根據評審得分,我們整理了排名前五的論文。目前,斯坦福大學探究神經網絡對抗樣本的論文 Certifiable Distributional Robustness with Principled Adversarial Training 名列第一。
今年的 ICLR 大會接收到了 981 篇有效論文。截至 12 月 1 日,有 979 篇論文至少經過了一次打分。近日,大會官方給出了論文雙盲評審的評分結果。統計數據顯示,平均分爲 5.24,中位數爲 5.33(滿分 10 分)。
論文評分前一百名結果:http://search.iclr2018.smerity.com/
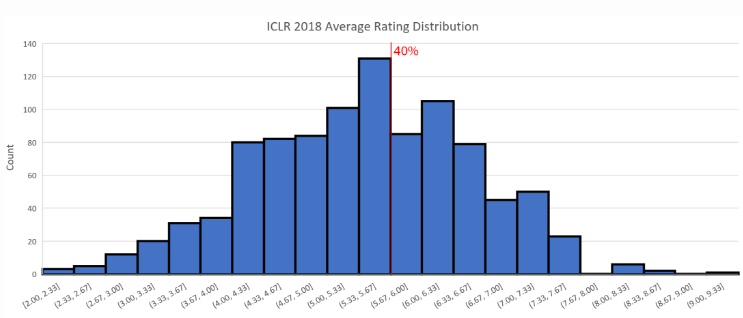
根據 Andrej Karpathy 的介紹,在今年 4 月的 ICLR 2017 大會上,提交論文的數量爲 491 篇,而被接受的情況爲:15 篇 oral(3%),183 篇 poster(37.3%)。所以上圖中我們給出了 40% 的接收線作爲參考。
分數分佈
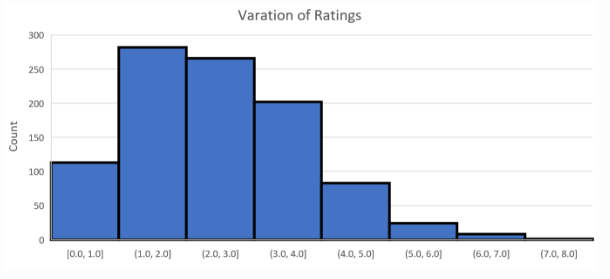
下圖顯示了相同論文得到評分的最大差值。我們觀察到,對於大多數(約 87%)論文來說,最大差值小於 3。
論文得分 Top 10
在雙盲評審打分過後,我們得到了十篇得分最高的論文。其中部分論文已在其他平臺提交,因此我們可以得知其作者與研究機構了。
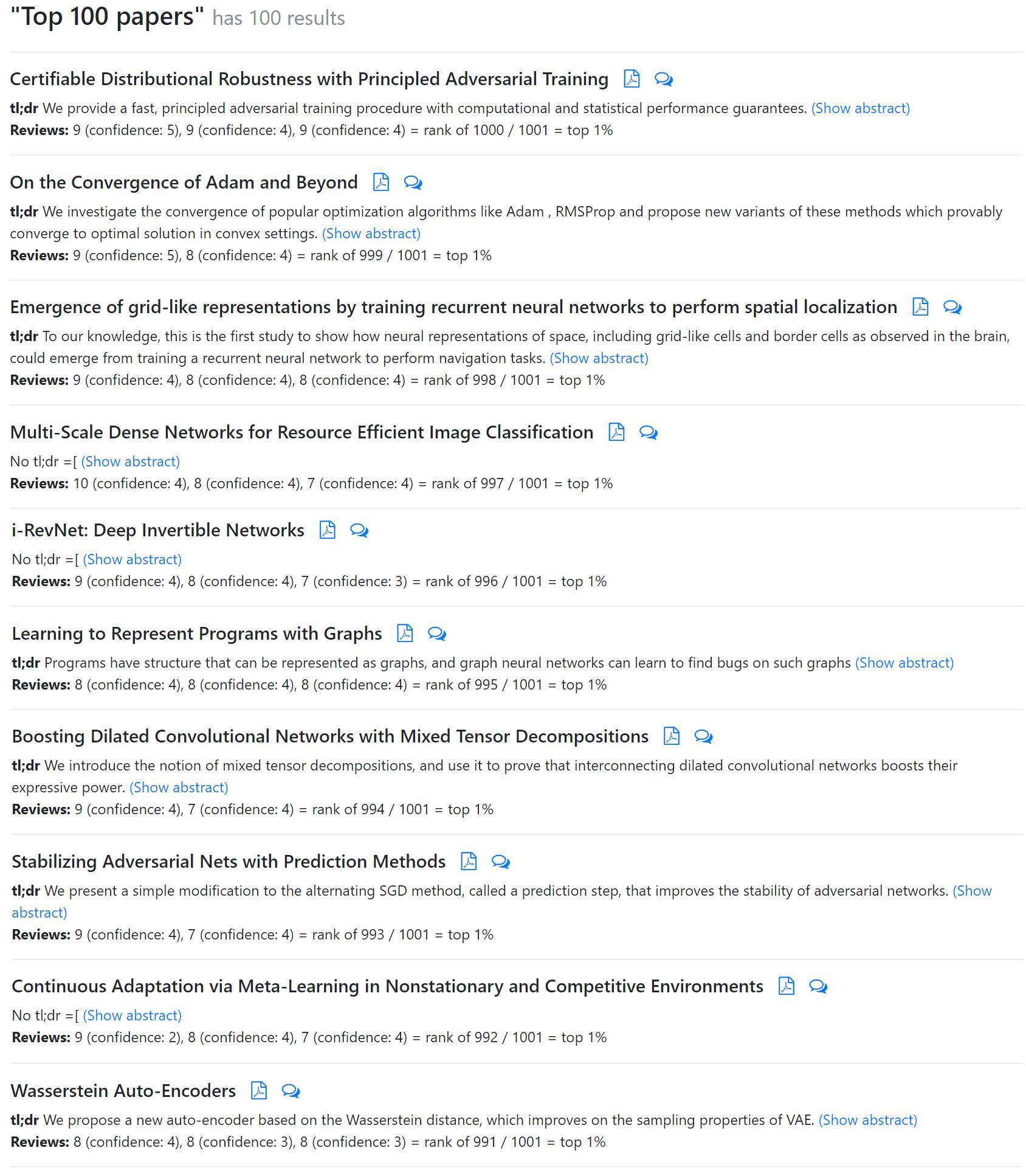
請注意,目前評審分數的提交尚未完全結束。現在評分最高的論文是斯坦福大學 Aman Sinha 等人的 Certifiable Distributional Robustness with Principled Adversarial Training。另有一篇值得注意的論文,英偉達 Tero Karras 等人的 Progressive Growing of GANs for Improved Quality, Stability, and Variation。收到了 8,8,1 的評分。此外,我們比較關注的第二篇 Capsule 論文:Matrix capsules with EM routing 並沒有太高的評分,該論文目前的評分大約在前 40% 左右。
下面,我們將簡要介紹目前 ICLR 2018 大會評審中排名前五的論文。
論文 1:Certifiable Distributional Robustness with Principled Adversarial Training

鏈接:https://arxiv.org/pdf/1710.10571.pdf
摘要:神經網絡很容易受到對抗樣本的干擾,因此研究人員提出了許多啓發式的攻擊與防禦機制。我們採取了分佈式魯棒優化的原則,以保證模型在對抗性擾動輸入的條件下保持性能。我們通過給予 Wasserstein ball 上的潛在數據分佈一個擾動來構建 Lagrangian 罰項,並且提供一個訓練過程以加強模型在最壞的訓練數據擾動情況下能持續正確地更新參數。對於平滑的損失函數,我們的過程相對於經驗風險最小化可以證明有適度的魯棒性,且計算成本或統計成本也相對較小。此外,我們的統計保證允許我們高效地證明總體損失的魯棒性。因此,該研究結果至少匹配或超越監督學習和強化學習任務中的啓發式方法。
如下所示,魯棒性的模型在原版的馬爾科夫決策過程(MDP)中要比一般的模型學習更高效:
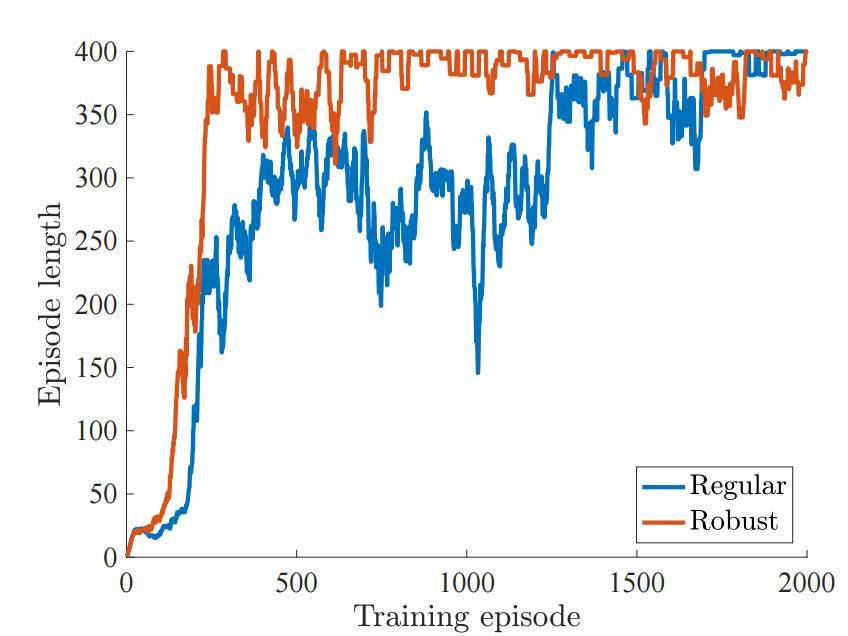
圖 4:訓練中 Episode 的長度,其中環境設置最大爲 400 Episode 的長度。
論文 2:ON THE CONVERGENCE OF ADAM AND BEYOND

鏈接:https://openreview.net/pdf?id=ryQu7f-RZ
摘要:近來提出的幾種隨機優化方法已經成功地應用於深度網絡的訓練,如 RMSPROP、ADAM、ADADELTA 和 NADAM 等方法,它們都是基於使用前面迭代所產生梯度平方的指數滑動平均值,在對該滑動平均值取平方根後用於縮放當前梯度以更新權重。根據經驗觀察,這些算法有時並不能收斂到最優解(或非凸條件下的臨界點)。我們證明了導致這樣問題的一個原因是這些算法中使用了指數滑動平均(exponential moving average)操作。本論文提供了一個簡單的凸優化案例,其中 ADAM 方法並不能收斂到最優解。此外,我們還描述了過去文獻中分析 ADAM 算法所存在的精確問題。我們的分析表明,收斂問題可以通過賦予這些算法對前面梯度的「長期記憶」能力而得到解決。因此本論文提出了一種 ADAM 算法的新變體,其不僅解決了收斂問題,同時還提升了經驗性能。
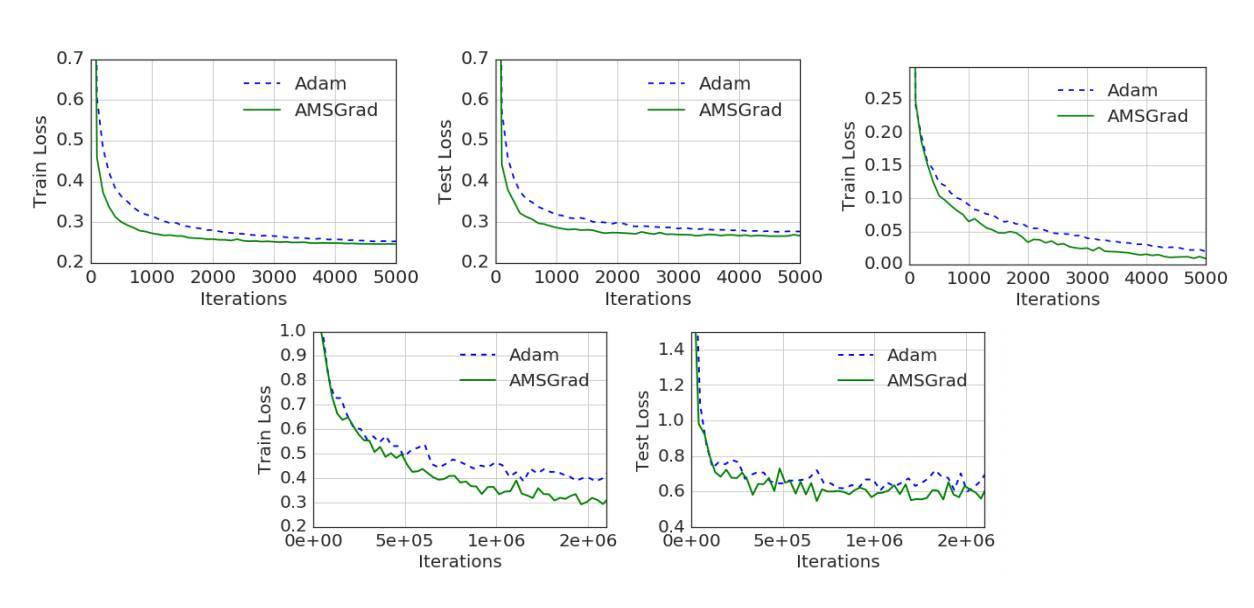
圖 2:ADAM 和 AMSGRAD 算法在 Logistic 迴歸、前饋神經網絡和 CIFARNET 上的性能對比。
論文 3:Emergence of grid-like representations by training recurrent neural networks to perform spatial localization

鏈接:https://openreview.net/pdf?id=B17JTOe0-
摘要:幾十年來關於空間導航的神經編碼研究揭示了一系列不同的神經反應特性。哺乳動物大腦的內嗅皮層(Entorhinal Cortex/EC)含有豐富的空間關聯性,包括網格細胞(grid cell)使用完全嵌入模式(tessellating patterns)編碼空間。然而,這些空間表徵的機制和功能仍然非常神祕。作爲理解這些神經表徵的新方法,我們訓練一個循環神經網絡(RNN),以在基於速率輸入的二維環境下執行導航任務。令人驚訝的是,我們發現類網格(grid-like)響應模式出現在訓練後的網絡中,它和其它空間相關的單元(包括邊緣(border cell)和帶狀細胞)一同出現。所有這些不同的功能性神經元都已經在實驗中觀察到。網格狀和邊緣細胞出現的順序也與發育性研究的觀察一致。總之,我們的結果表明,在 EC 中觀察到的網格細胞、邊緣細胞等可能是用於高效表示空間的自然解決方案,它們在神經迴路中給出了主要的循環連接。
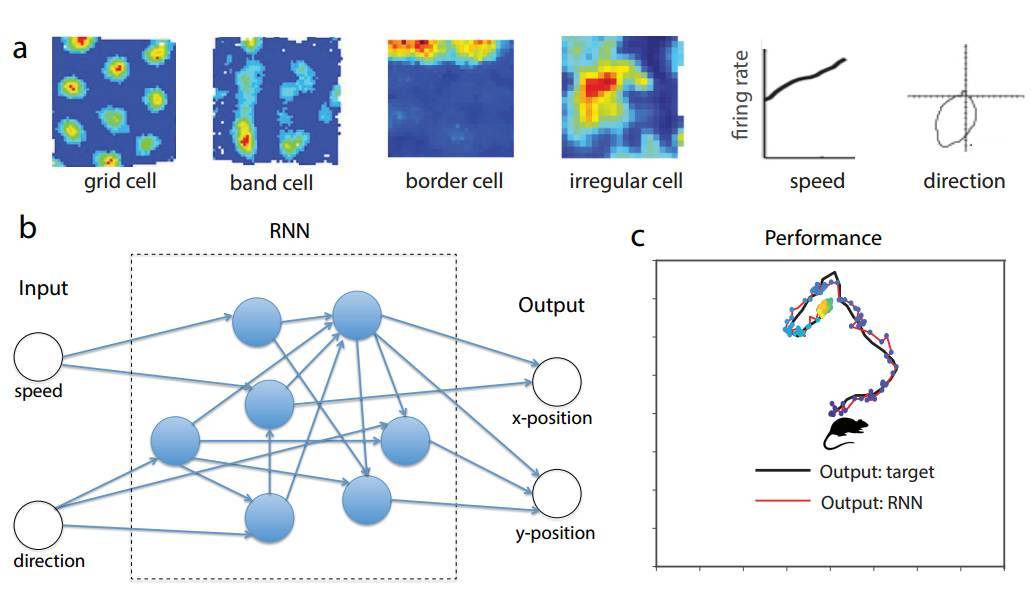
圖 1:其中 a)爲樣本神經數據表示 EC 空間導航任務中不同神經關聯性。b)中的循環網絡由 N = 100 個循環單元(或神經元)組成,它們接收兩個外部輸入,即代表動物的速度和方向。c)爲訓練後的典型軌跡,RNN 的輸出可以精確地在導航期間追蹤動物的位置。
論文 4:MULTI-SCALE DENSE NETWORKS FOR RESOURCE EFFICIENT IMAGE CLASSIFICATION

鏈接:https://arxiv.org/pdf/1703.09844.pdf
摘要:在本論文中,我們探究了圖像分類任務在給定時間內的計算資源消耗。實驗的兩個設定爲:1. 即時分類,其中網絡預測的示例圖會逐漸更新,以保證隨時輸出預測結果;2. 批預算分類,其中計算資源是有限的,而輸入的示例圖片存在「簡單的」和「困難的」。與大多數先前的工作相比(如流行的 Viola 和 Jones 算法)我們的方法基於卷積神經網絡。我們訓練多個具有不同資源需求的分類器,並在測試期間自適應地應用這些分類器。爲了最大化這些分類器計算資源的使用效率,我們將它們整合進一個深度卷積神經網絡中,使用密集連接將它們聯通。爲了更快實現高質量的分類,我們使用了二維混合比例網絡架構,在整個網絡中保持了粗糙與精細的特徵。三個圖像分類任務的實驗證明,我們的框架可以大大提升兩種設置目前的業內最佳水平。
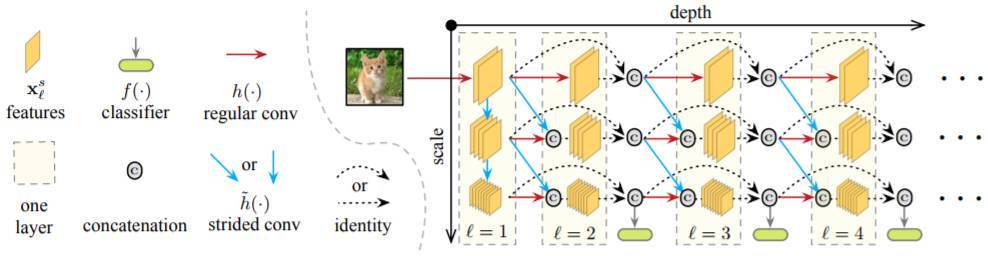
圖 2:具有三個比例的 MSDNet 的前四層圖示。水平方向對應於網絡的層方向(深度),垂直方向對英語特徵圖的比例。水平箭頭表示常規卷積操作,而對角線和垂直箭頭表示步進卷積操作。分類器僅在最粗糙比例的特徵映射上運行。跨越超過一層的連接未明確繪製:它們隱藏地通過遞歸串聯。
論文 5:i-RevNet: Deep Invertible Networks

鏈接:https://openreview.net/forum?id=HJsjkMb0Z
摘要:人們普遍認爲,目前深度卷積神經網絡的成功是建立在逐步拋棄輸入中對於當前問題無意義的變化而實現的。在大多數常用的網絡體系結構中,從隱藏表示中恢復圖像的難度獲得了實踐的證明。在本論文中,我們展示了這種信息損失並不是學習表示如何在 ImageNet 等複雜問題上得到通用性的必要條件。通過一系列的同胚層,我們構建了 i-RevNet 網絡——一個可以被完全倒置,直到最終投影到類上的網絡,在處理過程中沒有信息被丟棄。建立一個可逆的架構是困難的,例如局部倒轉是非常困難的,我們通過提供明確的反轉來克服這個問題。對於 i-RevNet 的學習表徵過程的分析證明了它可以通過漸進收縮和線性分離深度得到很高的準確性。此外,爲了解釋由 i-RevNet 學習到的模型的性質,我們重建了自然圖像表示之間的線性插值。
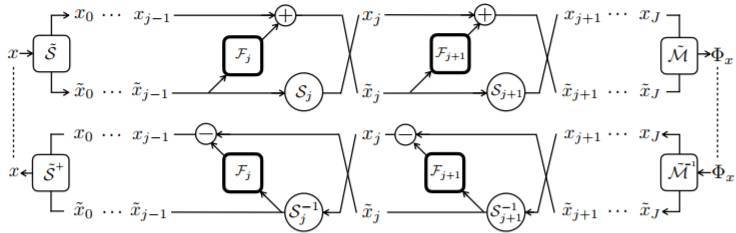
i-RevNet 及其僞逆結構
ICLR 2018 將於 4 月 30 日-5 月 3 日於加拿大溫哥華的 Vancouver Convention Center 舉行。我們將持續跟進本次大會的相關信息。
參考內容:https://liyaguang.github.io/iclr2018-stats