在 NIPS 2017 大會正式開始前,我們將選出數篇優質論文,邀請論文作者來做線上分享,聊聊理論、技術和研究方法。上週,我們進行了線上分享的第二期,邀請到了中國科大—微軟亞洲研究院聯合培養博士生夏應策講解了一篇有關神經機器翻譯的 NIPS 論文。本文將對該論文內容進行簡要介紹。
線上分享視頻回顧
神經機器翻譯(Neural Machine Translation,NMT)基於深度神經網絡,爲機器翻譯提供了端到端的解決方案,在研究社區中受到了越來越多的關注,且近幾年已被逐漸應用到了產業中。NMT 使用基於 RNN 的編碼器-解碼器框架對整個翻譯過程建模。在訓練過程中,它會最大化目標語句對給定源語句的似然度。在測試的時候,給定一個源語句 x,它會尋找目標語言中的一個語句 y*,以最大化條件概率 P(y|x)。由於目標語句的可能數目是指數量級的,找到最優的 y*是 NP-hard 的。因此通常會使用束搜索(beam search)以找到合理的 y。
束搜索是一種啓發式搜索算法,會以從左向右的形式保留得分最高的部分序列擴展。特別是,它保存了一羣候選的部分序列。在在每個時間步上,該算法將都會通過添加新詞的方法擴展每一個候選部分語句,然後保留由 NMT 模型評分最高的新候選語句。當達到最大解碼深度或者所有的語句都完全生成的時候(即所有的語句都包含 EOS 符號後綴的時候),算法就會終止。
雖然 NMT 結合束搜索是很成功的,但也存在幾個明顯的問題,已經被研究過的包括曝光偏差(exposure bias)、損失評估失配(loss-evaluation mismatch)和標籤偏差(label bias)。然而我們觀察到,其中仍然有一個很重要的問題被廣泛忽視,即短視偏差(myopic bias)。束搜索傾向於更關注短期獎勵。例如,在第 t 次迭代中,對於候選語句 y_1,...,y_t-1(記爲 y_
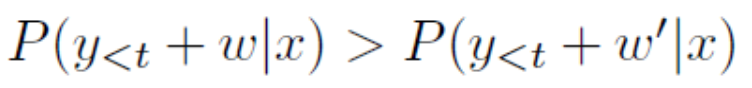
則新的候選語句 y_
爲了解決短視偏差,對每一個詞 w 和每一個候選語句 y_
在本研究中我們開發了一個基於神經網絡的預測模型,即爲 NMT 設計的價值網絡。該價值網絡將源語句與任何部分序列作爲輸入,並輸出預測值以估計 NMT 模型生成這一部分序列的期望總回報(例如 BLEU 分值)。在所有解碼的步驟中,我們不僅基於該部分序列的條件概率選擇最優的候選譯文,同時還基於價值網絡估計翻譯效果的長期回報。
該項工作的主要貢獻如下。首先我們開發了一個考慮長期回報的解碼方案,它會爲機器翻譯逐一生成譯文,這在 NMT 中是比較新的方案。在每個步驟中,新的解碼方案不僅考慮源語句的條件概率,同時還依賴於未來的預測回報。我們相信考慮這兩個部分將導致更好的翻譯效果。
其次,我們設計了一種新穎的價值網絡。在 NMT 編碼器-解碼器層的頂部,我們爲價值網絡開發了另外兩個模塊,即一個語義匹配模塊和一個上下文覆蓋(context-coverage)模塊。語義匹配模塊旨在估計源語句與目標語句之間的相似度,該模塊直接有助於翻譯質量的提升。不過我們經常觀察到,隨着注意力機制使用更多的上下文信息,模型能生成更好的翻譯 [14, 15]。因此我們構建了一個上下文覆蓋模塊來度量編碼器-解碼器層中的上下文覆蓋範圍。通過這兩個模塊的輸出,模型最終的預測將由全連接層完成。
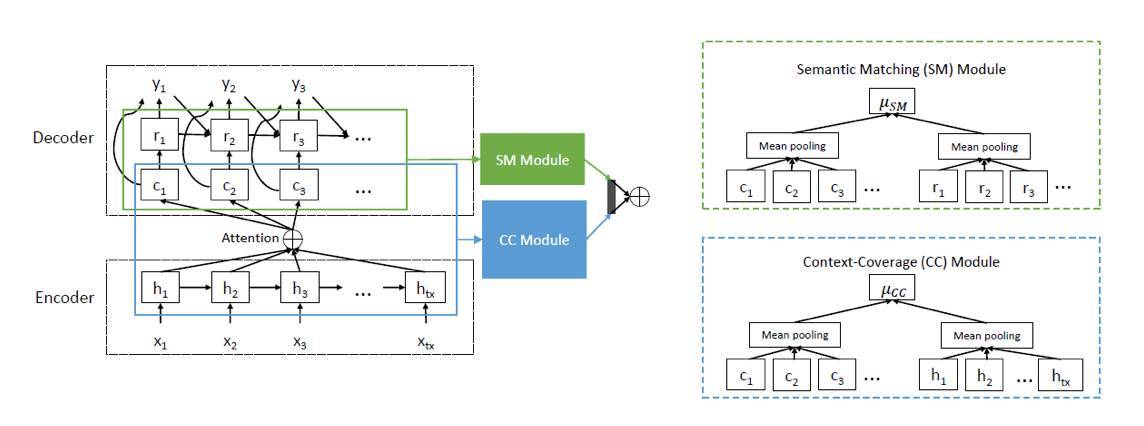
圖 1:價值網絡的架構
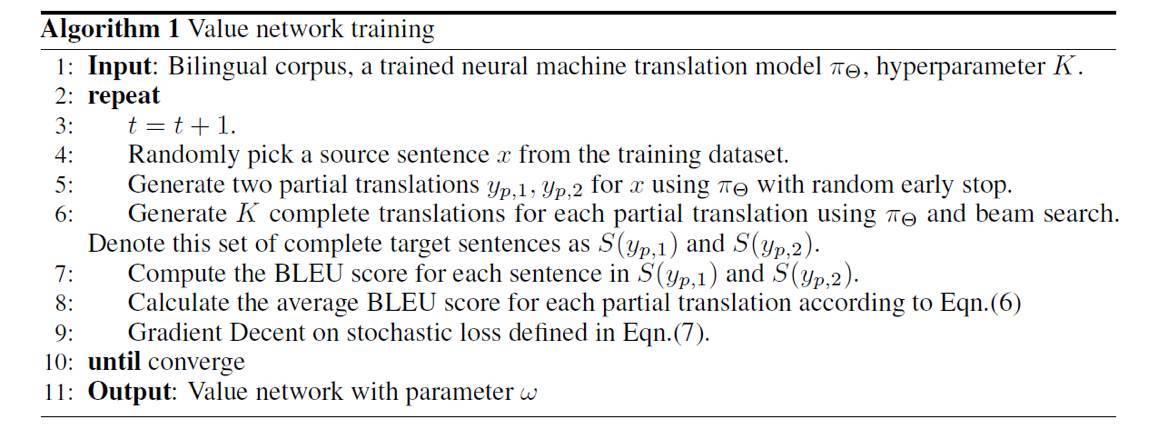
算法 1:價值網絡訓練

算法 2:NMT 中用價值網絡的束搜索
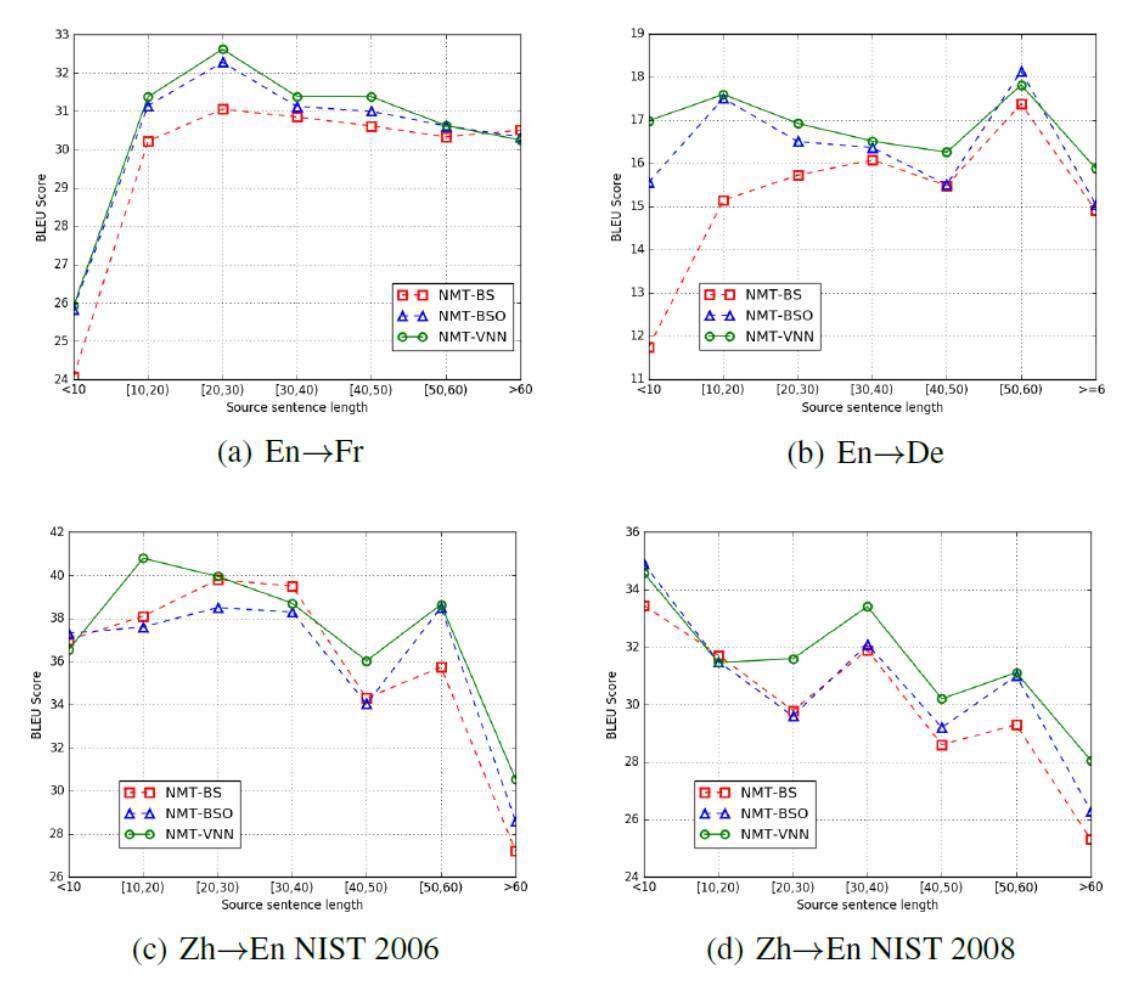
圖 2:在三種任務的測試集上的翻譯結果
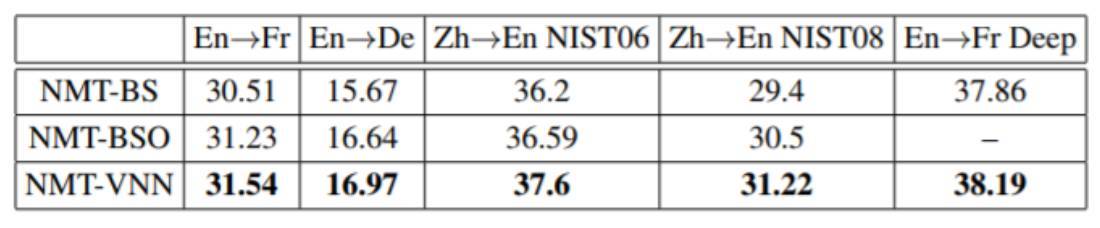
表 1 :整體表現
對價值網絡的分析
我們進一步觀察了學習到的價值網絡,並做了一些分析從而有更好的理解。
首先,因爲我們在解碼過程中使用一種附加組件,它會影響到翻譯過程的效率。也因爲設計的價值網絡架構類似於基礎的 NMT 模型,所以其計算複雜性也類似於 NMT 模型,且兩個流程可並行運行。
其次,可以看到 NMT 的準確率在特定任務上有時對束搜索的大小極爲敏感。我們在英語到德語的翻譯上觀察到了這一現象。Zhaopeng Tu 等人的論文《Neural Machine Translation with Reconstruction》認爲,這是因爲 NMT 的訓練喜歡短小但不合適的翻譯候選內容。然而,我們證明,通過使用價值網絡,我們可以極大地避免這一缺陷。我們用不同的束大小測試了該算法的準確率,如圖 3 所示。可以看到,NMT-VNN 要比沒有價值網絡的原始 NMT 更穩定:在不同大小的束搜索下,它的準確率只有略微不同,但 NMT-BS 在束大小變大的情況下準確率下降了超過 0.5 個點。
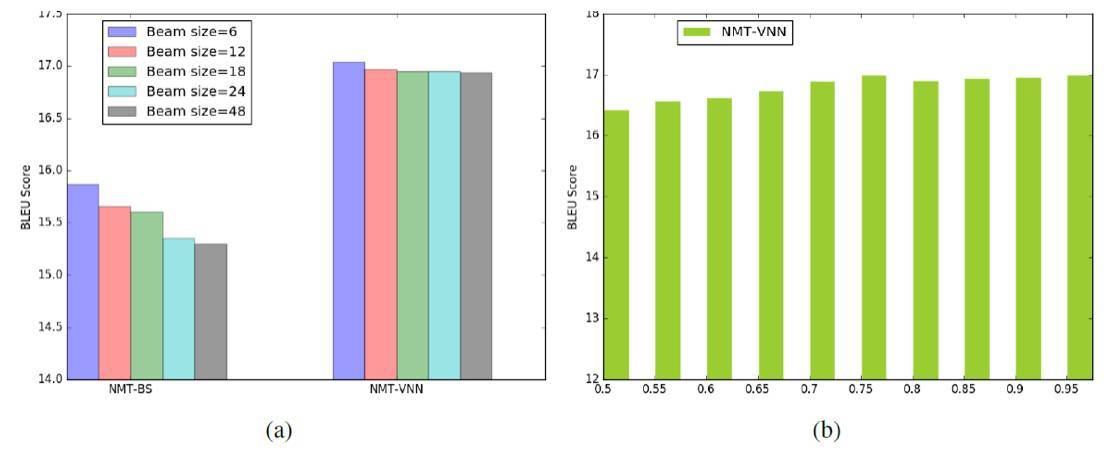
圖 3:(a)英語到德語翻譯任務關於不同束搜索的 BLEU 分值。(b)英語到德語翻譯任務關於不同超參數 α 的 BLEU 分值。
第三,在英語到德語的解碼過程中,我們測試了不同超參數α下的 NMT-VNN 的性能。從該圖我們可以看出當α處於 0.7 到 0.95 時,性能是比較穩定的,而採用更小的α性能會有一些降低。這表明我們的算法對於超參數來說是魯棒的。
論文:Decoding with Value Networks for Neural Machine Translation

論文鏈接:https://papers.nips.cc/paper/6622-decoding-with-value-networks-for-neural-machine-translation.pdf
摘要:神經機器翻譯(NMT)近幾年正變得流行起來。在解碼的時候,束搜索(beam search)能使得搜索空間縮小和計算複雜度降低,因而被廣泛採用。然而,由於其在解碼時只向前計算一步,所以只能在每個時間步搜索局部最優,而通常不能輸出全局最優的目標語句。受到 AlphaGo 的成功和方法論的啓發,在這篇論文中,我們提出了一種新方法,利用預測網絡提升束搜索準確率,即在第 t 步選取源語句 x、當前可用的解碼輸出 y_1,...,y_{t-1} 和一個候選詞 w 作爲輸入,並預測部分目標語句(假如它由 NMT 模型完成)的長期價值(例如,BLEU 分值)。根據強化學習的實踐經驗,我們將這個預測網絡稱爲價值網絡。具體來說,我們提出了價值網絡的循環結構,並使用雙語數據訓練其參數。在測試過程中,當需要解碼詞 w 的時候,需要同時考慮由 NMT 模型給定的條件概率和由價值網絡預測的長期價值。實驗證明,這種方法可以顯著提高多種翻譯任務的準確率。