選自xcelerit
RNN 是處理量化金融、風險管理等時序數據的主要深度學習模型,但這種模型用 GPU 加速的效果並不好。本文使用 RNN 與 LSTM 基於 TensorFlow 對比了英偉達 Tesla P100(Pascal)和 V100(Volta)GPU 的加速性能,且結果表明訓練和推斷過程的加速效果並沒有我們預期的那麼好。

循環神經網絡(RNN)
很多深度學習的應用都涉及到使用時序數據作爲輸入。例如隨時間變化的股價可以作爲交易預測算法、收益預測算法的輸入而對未來某個時間點的可能狀態進行推斷。循環神經網絡(RNN)非常是適合於建模長期或短期的時間依賴項,因此是本文測試的理想模型。
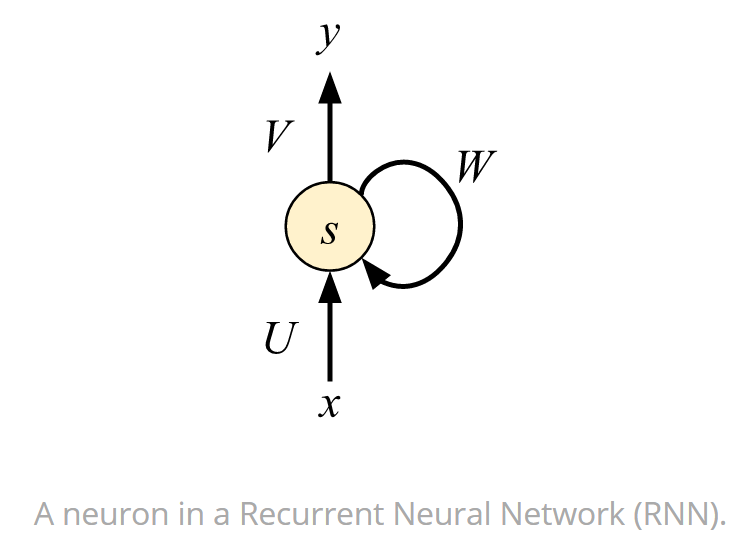
下圖展示了 RNN 中的一個神經元,它不僅是最基礎的組成部分,同時還是其它更復雜循環單元的基礎。下圖可以看出該神經元的輸出 y 不僅取決於當前的輸入 x,同時還取決於儲存的前面狀態 W,前面循環的狀態也可以稱之爲反饋循環。正是這種循環,RNN 能夠學習到時序相關的依賴性。
如下圖所示,RNN 單元可以組織成一個個層級,然後再堆疊這些層級以組織成一個完整的神經網絡。
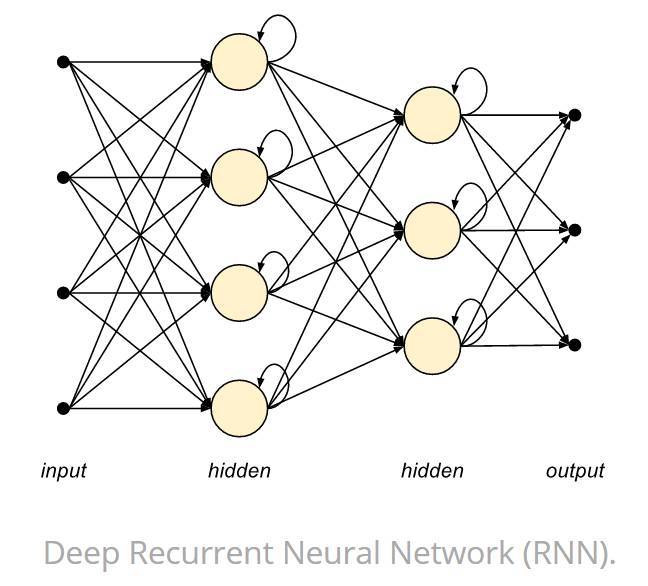
深度循環神經網絡
由於梯度消失和爆炸問題,RNN 很難學習到長期依賴關係。這兩個問題主要發生在訓練時期的反向傳播過程中,其中損失函數的梯度由輸出向輸入反向地計算。由於反饋循環,較小的梯度可能快速消失,較大的梯度可能急劇增加。
梯度消失問題阻止了 RNN 學習長期時間依賴關係,而長短期記憶模型(LSTM)正是 RNN 的一種變體以解決該問題。LSTM 引入了輸入門、遺忘門、輸入調製門和記憶單元。這允許 LSTM 在輸入數據中學習高度複雜的長期依賴關係,因此也十分適用於學習時序數據。此外,LSTM 也可以堆疊多層網絡形成更復雜的深度神經網絡。
在假定隱藏層具有相同的寬度下,深度 RNN 網絡的計算複雜度與採用的層級數成線性縮放關係。因此,單層 RNN 或 LSTM 單元就可以看作是深度 RNN 中的基礎構建塊,這也就是爲什麼我們要選擇下面這樣的層級進行基礎測試。
硬件對比
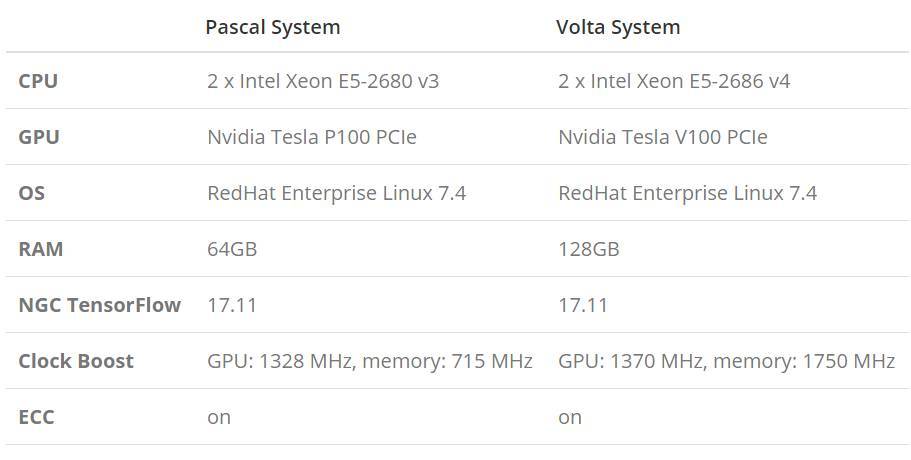
下表展示了英偉達 P100 和 V100 GPU 的關鍵性能與不同點。

請注意 FLOPs 的計算先假定純粹的加乘混合(fused multiply-add /FMA)運算指令記爲兩個運算,即使它們都只映射到一個處理器指令中。
在 P100 上,我們測試的是半精度(FP16)FLOPs。而在 V100 上,我們測試的是張量 FLOPs,它以混合精度的方式在 Tensor Cores 上運行:以 FP16 的精度執行矩陣乘法,而以 FP32 的精度進行累加。
也許 V100 GPU 在深度學習環境下最有意思的硬件特徵就是 Tensor Cores,它是能以半精度的方式計算 4×4 矩陣乘法的特定內核,並在一個時鐘週期內將計算結果累加到單精度(或半精度)4×4 矩陣中。這意味着一個 Tensor Cores 在每個時鐘週期內可以執行 128 FLOPs,並且帶有 8 個 Tensor Cores 的 Streaming Multiprocessor 能實現 1024 FLOPs/cycle 的速度。這比常規單精度 CUDA 核要快 8 倍。爲了從這種定製化的硬件中獲益,深度學習模型應該以混合精度(半精度與單精度)或純粹以半精度的方式編寫,因此才能利用深度學習框架高效地使用 V100Tensor Cores。
TensorFlow
TensorFlow 是一個谷歌維護的開源深度學習框架,它使用數據流圖進行數值計算。TensorFlow 中的 Tensor 代表傳遞的數據爲張量(多維數組),Flow 代表使用計算圖進行運算。數據流圖用「結點」(nodes)和「邊」(edges)組成的有向圖來描述數學運算。「結點」一般用來表示施加的數學操作,但也可以表示數據輸入的起點和輸出的終點,或者是讀取/寫入持久變量(persistent variable)的終點。邊表示結點之間的輸入/輸出關係。這些數據邊可以傳送維度可動態調整的多維數據數組,即張量(tensor)。
TensorFlow 允許我們將模型部署到臺式電腦、服務器或移動設備上,並調用這些設備上的單個或多個 CPU 與 GPU。開發者一般使用 Python 編寫模型和訓練所需的算法,而 TensorFlow 會將這些算法或模型映射到一個計算圖,並使用 C++、CUDA 或 OpenCL 實現圖中每一個結點的計算。
從今年 11 月份發佈的 TensorFlow 1.4 開始,它就已經添加了對半精度(FP16)這種數據類型的支持,GPU 後端也已經爲半精度或混合精度的矩陣運算配置了 V100 Tensor Cores。除了 1.4 這個主線版本外,英偉達還在他們的 GPU Cloud Docker 註冊表以 Docker 容器的形式維護了一個定製化和優化後的版本。這個容器目前最新版爲 17.11,爲了實現更好的性能,我們將使用這個 HGC 容器作爲我們的測試基準。
基準測試
我們的基準性能測試使用含有多個神經元的單隱藏層網絡架構,其中隱藏層的單元爲分別爲原版 RNN(使用 TensorFlow 中的 BasicRNNCell)和 LSTM(使用 TensorFlow 中的 BasicLSTMCell)。網絡的所有權重會先執行隨機初始化,且輸入序列因爲基準測試的原因而採取隨機生成的方式。
我們比較了模型在 Pascal 和 VoltaGPU 上的性能,且系統所使用的配置如下所示:
性能
爲了度量性能,我們需要重複執行模型的訓練,然後再記錄每次運行的時鐘長度,直到估計的時間誤差低於特定值才停止。性能度量包括完整的算法執行時間(使用梯度下降的時間加上推斷的時間),訓練的輸入爲批量大小爲 128 的 10 萬批數據,且每一個序列長度爲 32 個樣本。訓練過程大概有 1300 萬的訓練樣本,且我們使用重疊的窗口進行序列分析。一個深度學習模型大概會依據 32 個以前樣本的狀態而預測未來的輸出,因此我們修正隱藏層中 RNN/LSTM 單元的數量以執行基線測試。
訓練
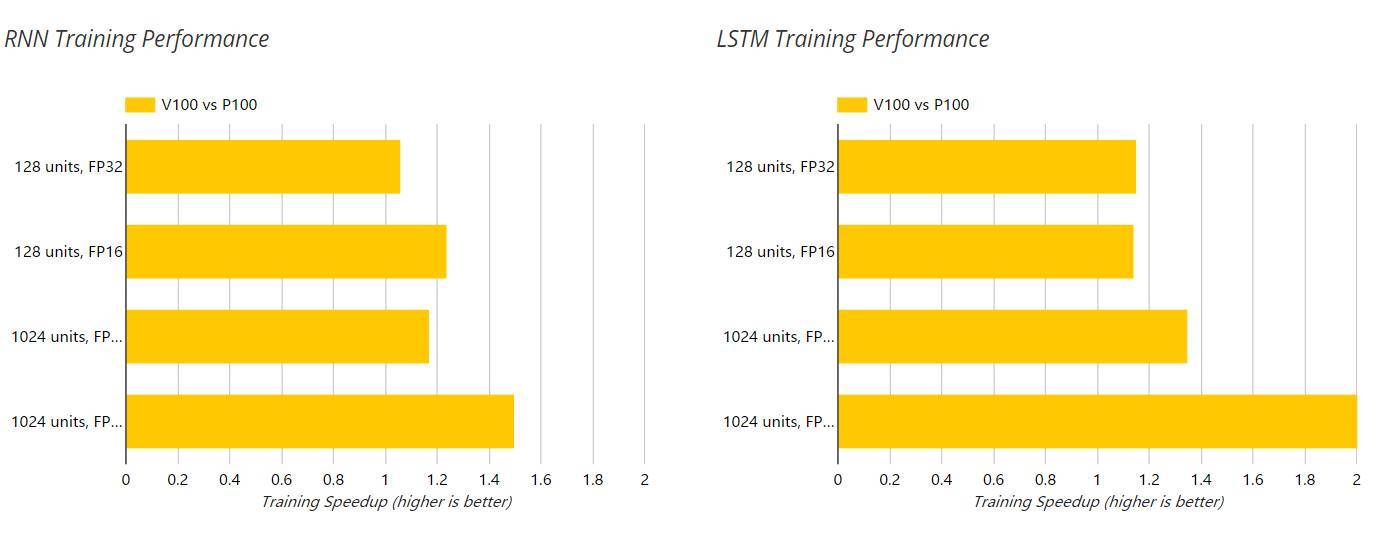
以下兩圖展示了 V100 和 P100 GPU 在訓練過程中對 RNN 和 LSTM 的加速,這個過程的單精度(FP32)和半精度(FP16)運算都是使用的 NGC 容器。此外,隱藏層單元數也在以下圖表中展示了出來。
推斷
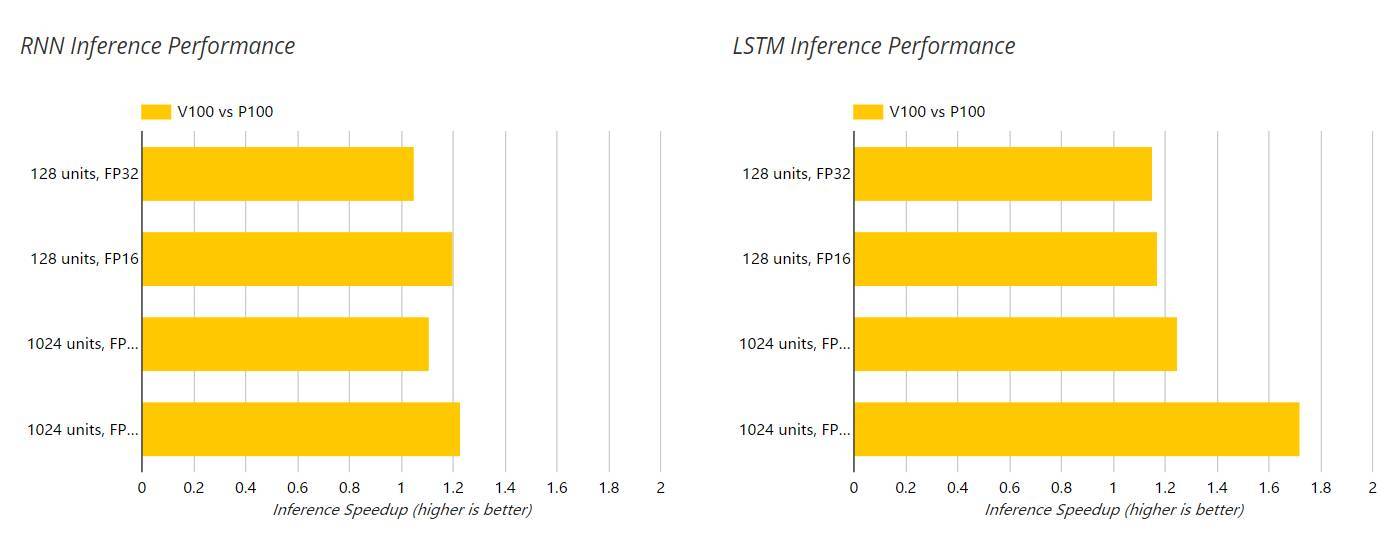
以下兩圖展示了 V100 和 P100 GPU 在推斷過程中對 RNN 和 LSTM 的加速,這個過程的單精度(FP32)和半精度(FP16)運算都是使用的 NGC 容器。此外,隱藏層單元數也在以下圖表中展示了出來。
結語
對於測試過的 RNN 和 LSTM 深度學習模型,我們注意到 V100 比 P100 的相對性能隨着網絡的規模和複雜度(128 個隱藏單元到 1024 個隱藏單元)的提升而增加。我們的結果表明 V100 相對於 P100 在 FP16 的訓練模式下最大加速比爲 2.05 倍,而推斷模式下實現了 1.72 倍的加速。這些數據比基於 V100 具體硬件規格的預期性能要低很多。
這一令人失望的性能比可能是因爲 V100 中強大的 Tensor Cores 只能用於半精度(FP16)或混合精度的矩陣乘法運算。而對這兩個模型進行分析的結果表示矩陣乘法僅佔 LSTM 總體訓練時間的 20%,所佔 RNN 總體訓練時間則更低。這與擅長於處理圖像數據的卷積神經網絡形成鮮明對比,它們的運行時間由大量的矩陣乘法支配,因此能更加充分地利用 Tensor Cores 的計算資源。
雖然 V100 與 P100 相比顯示出強大的硬件性能提升,但深度學習中擅於處理時序數據的循環神經網絡無法充分利用 V100 這種專門化地硬件加速,因此它只能獲得有限的性能提升。
原文地址:https://www.xcelerit.com/computing-benchmarks/insights/benchmarks-deep-learning-nvidia-p100-vs-v100-gpu/