選自Stanford
參與:路雪、蔣思源
韓鬆,2017 年斯坦福大學電子工程系博士畢業,師從 NVIDIA 首席科學家 Bill Dally 教授。他的研究也廣泛涉足深度學習和計算機體系結構,他提出的 Deep Compression 模型壓縮技術曾獲得 ICLR'16 最佳論文,ESE 稀疏神經網絡推理引擎獲得 FPGA'17 最佳論文,對業界影響深遠。他的研究成果在 NVIDIA、Google、Facebook 得到廣泛應用,博士期間創立了深鑑科技,2018 年將任職 MIT 助理教授。本文對韓鬆博士的畢業論文做了介紹。
未來將出現大量廉價、低功耗的智能設備。深度神經網絡已經發展出適合機器學習任務的頂尖技術。但是,這些算法計算量很大,使得它們難以部署到硬件資源有限、能量預算緊張的嵌入式設備中。由於摩爾定律和工藝尺寸縮小正在變慢,僅依賴工藝進步無法解決這個問題。爲了解決該問題,我們研究高效的算法和專用體系架構。我們通過硬件在應用中執行全棧優化,從而通過更小的模型規模、更高的預測準確度、更快的預測速度和更低的電量消耗來提高深度學習的效率。我們的方法從使用「深度壓縮」改變算法開始,「深度壓縮」通過剪枝、量化訓練(trained quantization)和可變長度編碼(variable length coding)/霍夫曼編碼大幅減少參數數量和深度學習模型的計算要求。「深度壓縮」可以在不損害預測準確度的前提下把模型大小減小 18 倍 到 49 倍。我們還發現剪枝和稀疏約束(sparsity constraint)不僅能夠用於模型壓縮,還能夠用於正則化。我們提出 dense-sparse-dense 訓練(DSD),可以提高多種深度學習模型的預測準確度。爲了在硬件中高效實現「深度壓縮」,我們開發了一種特定領域的硬件加速器 EIE(Efficient Inference Engine,高效推斷機),它能夠在壓縮後的模型上直接執行推斷,顯著節約了內存帶寬。EIE 利用壓縮模型,能夠高效處理非常規計算模式,從而把速度提高了 13 倍,能量效率比 GPU 高出 3400 倍。
第一章 引言
本文,我們協同設計了適合深度學習的算法和硬件,使之運行更快更節能。我們提出的技術能夠使深度學習的工作負載更加高效、緊密,然後我們設計了適合優化 DNN 工作負載的硬件架構。圖 1.1 展示了本文的設計方法。打破算法和硬件棧之間的界限創造了更大的設計空間(design space),研究者獲得之前從未有過的自由度,這使得深度學習能夠實現更好的優化。
在算法方面,我們研究如何簡化和壓縮 DNN 模型,以減少計算量和內存的佔用。在 ImageNet 上,我們在不損失預測準確度的情況下將 DNN 壓縮了 49 倍 [25,26]。我們還發現模型壓縮算法能夠去除冗餘、防止過擬合,可以作爲合適的正則化方法 [27]。
在硬件方面,壓縮後的模型具備提速和降低能耗的極大潛力,因爲它所需的算力和內存減少。然而,模型壓縮算法使計算模式變的非常規,很難並行化。因此,我們爲壓縮後的模型設計了一種定製化硬件,設計模型壓縮的數據結構和控制流程。該硬件加速器的能量效率比 GPU 高出 3400 倍,比之前的加速器高出一個數量級 [28]。該架構的原型在 FPGA 上,且已用於加速語音識別系統 [29]。
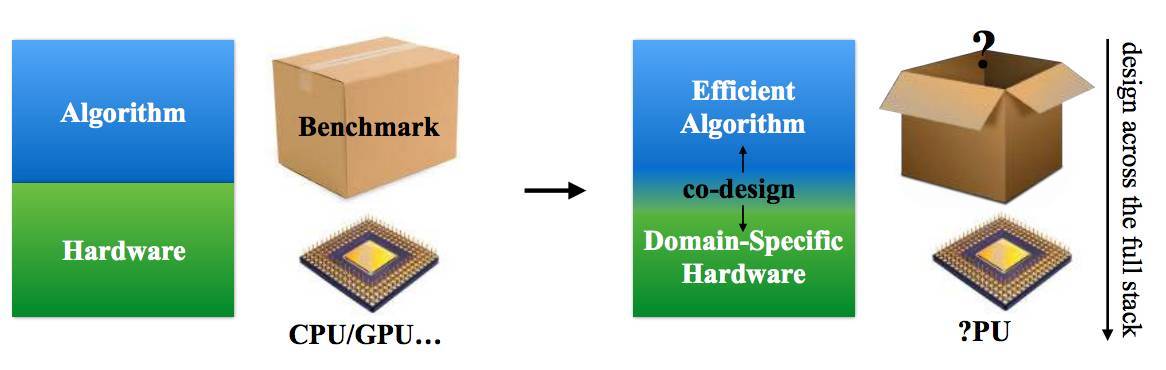
圖 1.1:本文重點是協同設計適合深度學習的算法和硬件。本文回答了兩個問題:哪些方法可以使深度學習算法更加高效,哪些硬件架構最適合這類算法。
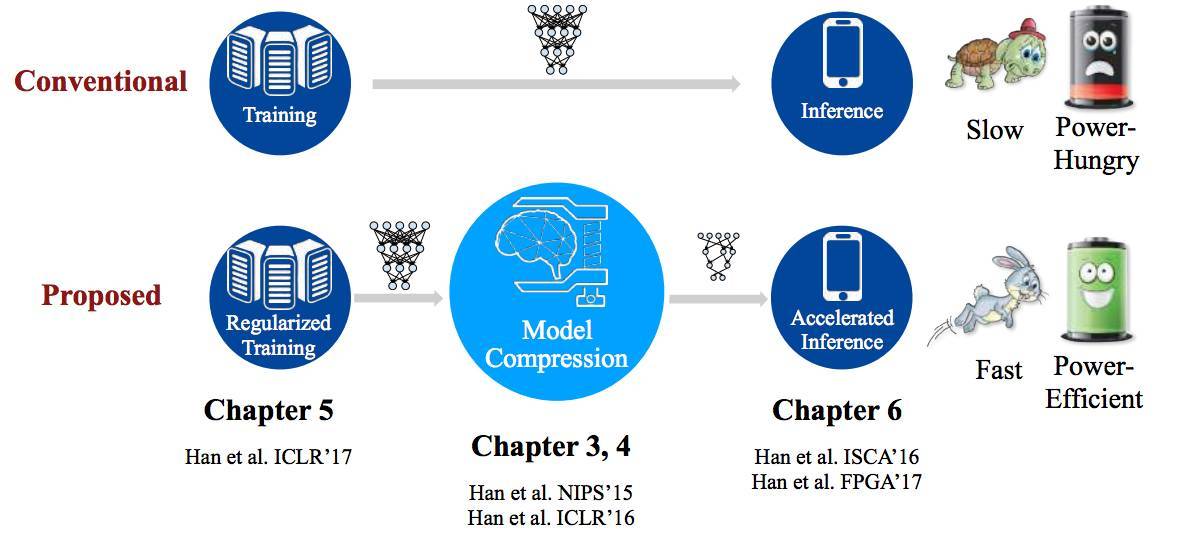
圖 1.2:論文主題貢獻:正則化訓練、模型壓縮、加速推理
第二章 背景
本章首先介紹什麼是深度學習以及它的工作原理和應用;然後介紹我們實驗所用的神經網絡架構、數據集、在數據集上訓練架構的框架。之後,我們介紹壓縮、正則化和加速方面之前的研究。
第三章 神經網絡剪枝
現代深度神經網絡使用非常多的參數以提供足夠強大的模型,因此這種方法在計算量和內存上都需要足夠的資源。此外,傳統的神經網絡需要在訓練前確定與修正架構,因此訓練過程並不會提升架構的性能。而若直接選擇複雜的架構,那麼過多的參數又會產生過擬合問題。因此,選擇適當容量(capacity)的模型和消除冗餘對計算效率和準確度的提升至關重要。
爲了解決這些問題,我們發展了一種剪枝方法(pruning method)來移除冗餘並保證神經網絡連接的有效性,這種方法能降低計算量和內存的要求以提升推斷的效果。這種方法關鍵的挑戰是如何在模型剪枝後還保留原來的預測準確度。
我們的剪枝方法移除了冗餘連接,並僅通過重要的連接學習(下圖 3.1)。在該圖的案例中,共有三層神經網絡,剪枝前第 i 層和 i+1 層間的連接爲密集型連接,剪枝後第 i 層和 i+1 層間的連接爲稀疏連接。當所有與神經元相聯結的突觸都被移除掉,那麼該神經元也將移除。神經網絡剪枝將密集型神經網絡轉化爲稀疏型神經網絡,並且在減少了參數與計算量的情況下完全保留預測準確度。剪枝不僅提高了推斷速度,同時還降低了運行大型網絡所需要的計算資源與能源,因此它可以在電池受限的移動設備上使用。剪枝同樣有利於將深度神經網絡儲存並傳遞到移動應用中。
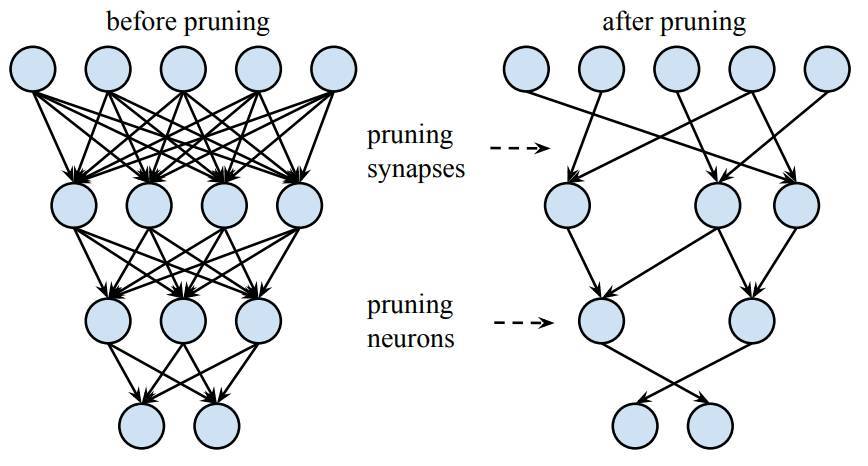
圖 3.1:對深度神經網絡的神經元與突觸進行剪枝。
在初始化訓練階段後,我們通過移除權重低於閾值的連接而實現 DNN 模型的剪枝,這種剪枝將密集層轉化爲稀疏層。第一階段需要學習神經網絡的拓撲結構,並關注重要的連接而移除不重要的連接。然後我們重新訓練稀疏網絡,以便剩餘的連接能補償移除的連接。剪枝和再訓練的階段可以重複迭代地進行以減少神經網絡複雜度。實際上,這種訓練過程除了可以學習神經網絡的權重外,還可以學習神經元間的連通性。這與人類大腦的發育過程 [109] [110] 十分相似,因爲生命前幾個月所形成的多餘突觸會被「剪枝」掉,神經元會移除不重要的連接而保留功能上重要的連接。
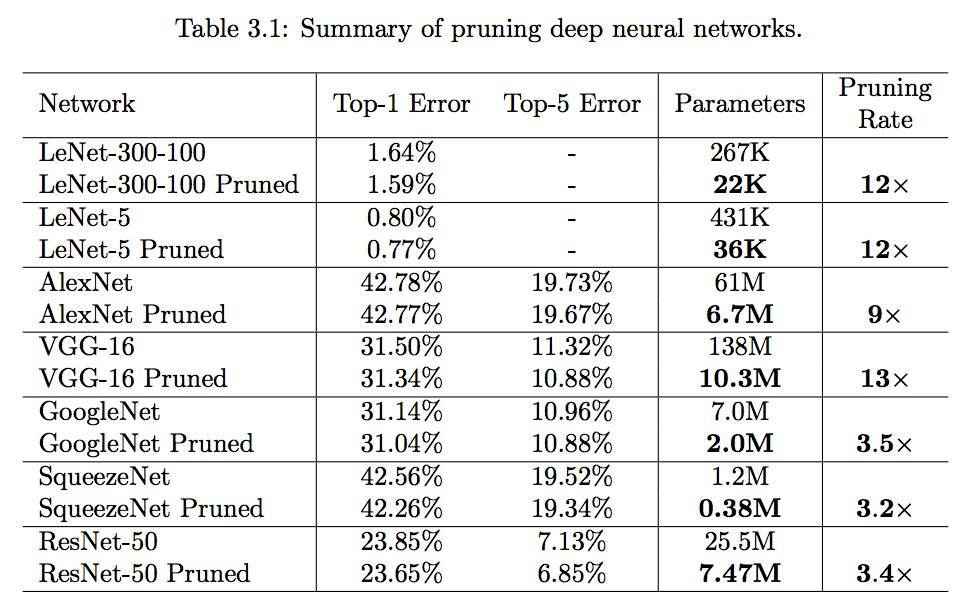
在 ImageNet 數據集中,剪枝方法可以將 AlexNet 的參數數量減少 9 倍(6100 萬降低爲 670 萬)而沒有準確度上的損失。VGG-16 同樣有類似的現象,參數總量可以減少 13 倍左右(1.38 億降低爲 1.03 千萬)而完全沒有準確度損失。我們還試驗了更多高效的全卷積神經網絡:GoogleNet(Inception-V1)、SqueezeNet 和 ResNet-50,它們不具有或有很少的全連接層。在這些實驗中,我們發現在準確度降低前它們有相似的剪枝率,即 70% 左右的全卷積神經網絡參數可以被剪枝。GoogleNet 從 700 萬參數降低到 200 萬參數,SqueezeNet 從 120 萬參數降低到 38 萬參數,而 ResNet-50 從 2550 萬參數降低到 747 萬參數,這些網絡在 ImageNet Top-1 和 Top-5 準確度上都完全沒有損失。
在本章節以下部分中,我們提供瞭如何剪枝神經網絡和再訓練模型以保留預測準確度的方法。我們還展示了剪枝後模型在商業化硬件上運行所產生的速度與能源效率提升。
第四章 量化訓練與深度壓縮
本章節介紹了用於壓縮深度神經網絡的量化訓練(trained quantization)技術,但它與前一章所介紹的剪枝技術相結合時,我們就能構建「深度壓縮」[26],即一種深度神經網絡的模型壓縮流程。深度壓縮(Deep Compression)由剪枝、量化訓練和可變長度編碼(variable-length coding)組成,它可以壓縮深度神經網絡數個量級而沒有什麼預測準確度損失。這種大型壓縮能使機器學習在移動設備上運行。
「深度壓縮」是一種三階段流程(圖 4.1),它可以在保留原始準確度的情況下減小深度神經網絡的模型大小。首先我們可以移除冗餘連接而剪枝網絡,這一過程只需要保留提供最多信息的連接(如第三章所述)。下一步需要量化權重,並令多個連接共享相同的權重。因此只有 codebook(有效權重)和索引需要儲存,且每個參數只需要較少的位就能表示。最後,我們可以應用可變長度編碼(Huffman 編碼)來利用有效權重的不均勻分佈,並在沒有訓練準確度損失情況下使用可變長度編碼表徵權重。
我們最重要的觀點是,剪枝與量化訓練可以在不相互影響的情況下壓縮神經網絡,因此可以產生驚人的高壓縮率。深度壓縮令存儲需求變得很小(兆字節空間),所有的權重都可以在芯片上緩存而不需要芯片外的 DRAM。而動態隨機儲存器不僅慢同時能耗還比較高,因此深度壓縮可以令模型更加高效。深度壓縮是第六章高效推斷機(efficient inference engine/EIE)的基礎,其通過壓縮模型實現了顯著的速度和能源效率提升。
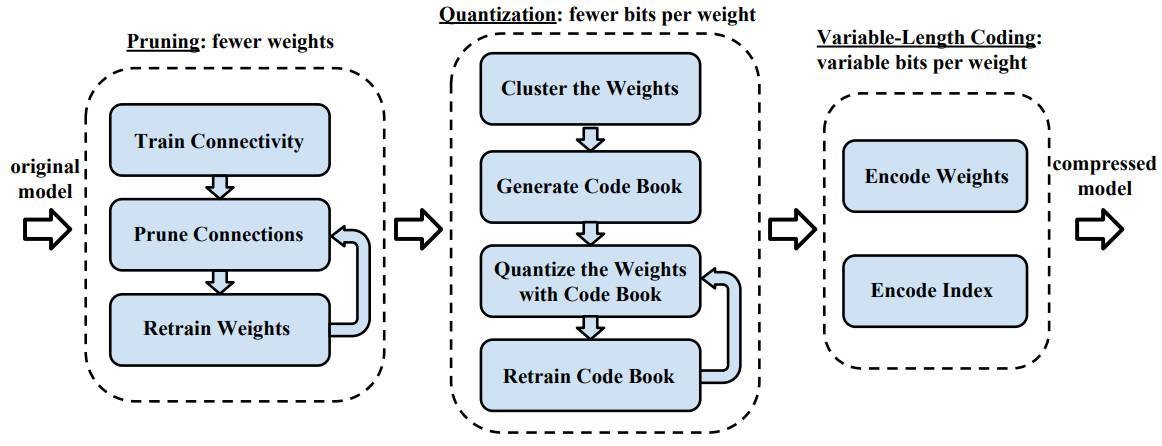
圖 4.1:深度壓縮的流程:剪枝、量化學習和可變長度編碼
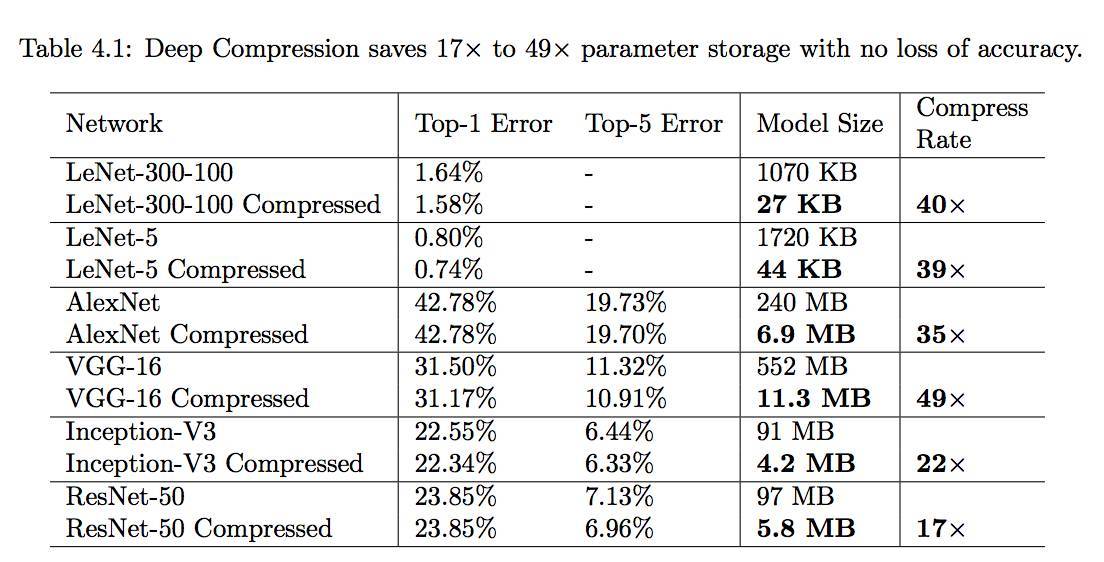
表 4.1:深度壓縮在沒有準確度損失的情況下節約了 17 倍到 49 倍的參數存儲需求。
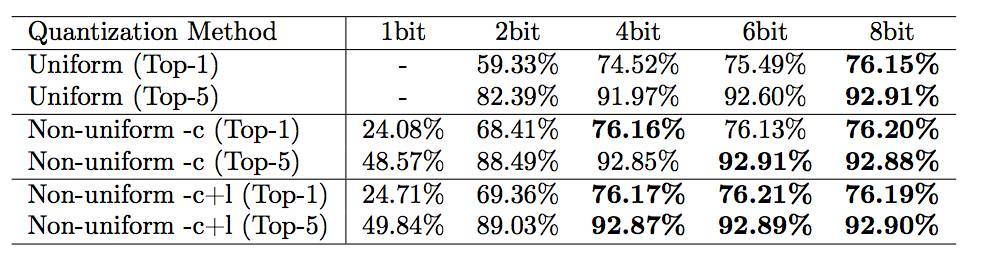
表 4.9:使用不同更新方法比較均勻量化和非均勻量化的結果。-c 僅更新形心(centroid),-c+1 同時更新形心和標籤。ResNet-50 的基線準確度分別爲 76.15% 和 92.87%。所有結果都經過再訓練。
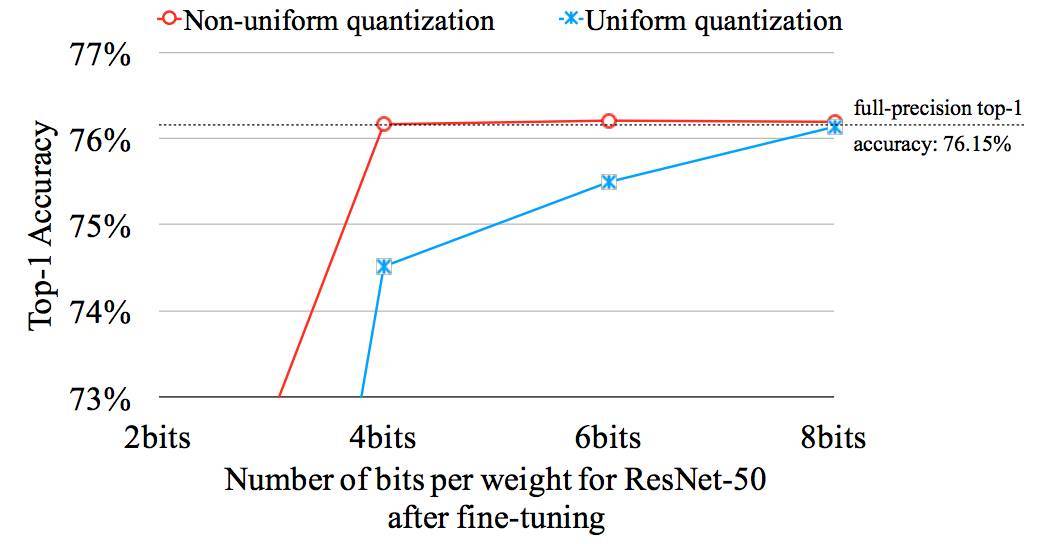
圖 4.10:非均勻量化的表現要好於均勻量化。
圖 4.10 和表 4.9 比較了均勻量化和非均勻量化的性能。非均勻量化指的是相鄰編碼的距離不爲常數。量化訓練是非均勻量化的一種形式,因爲其不同編碼的距離並不相同。對於非均勻量化(本研究),基線 ResNet-50 所有層級的參數可以壓縮爲 4 比特而沒有準確度損失。然而對於均勻量化,基線 ResNet 所有層的參數只能壓縮到 8 比特而沒有準確度損失(壓縮到 4 比特會產生 1.6% 的 Top-1 準確度損失)。非均勻量化可以很好的捕捉到權重的不均勻分佈,而均勻量化不能很好的實現這一點。
第五章 DSD: Dense-Sparse-Dense Training
現代高性能硬件的出現使得訓練複雜、模型容量巨大的 DNN 模型變得更加簡單。複雜模型的優勢是它們對數據的表達能力很強並且能捕捉到特徵和輸出之間的高度非線性的關係。而複雜模型的劣勢在於,比起訓練數據中所需要的模式,它們更容易捕捉到噪聲。這些噪聲並不會在測試數據中生成,從而使模型產生過擬合和高方差。
然而,只是簡單的減少模型容量會導致另一個極端:欠擬合和高偏差(機器學習系統不能準確捕捉特徵和輸出之間的關係)。所以,偏差和方差很難同時優化。爲了解決這個問題,我們提出了 dense-sparse-dense(DSD)訓練流,以正則化深度神經網絡,防止過擬合併達到更高的準確度。
傳統的訓練方法通常是同時訓練所有的參數,而 DSD 訓練法會週期性的修剪和恢復神經連接,訓練過程中的有效連接數量是動態變化的。剪枝連接允許在低維空間中進行優化,捕捉到魯棒性特徵;恢復連接允許增大模型的容量。傳統的訓練方法只在訓練開始的時候將所有權重初始化一次,而 DSD 訓練法允許連接在週期性剪枝和恢復的中有多於一次的機會執行初始化。
DSD 的一個優勢是最後的神經網絡仍然擁有和初始的密集模型同樣的架構和維度,因此 DSD 訓練不會產生任何額外的推斷成本。使用 DSD 模型進行推斷不需要指定專門的硬件或專門的深度學習框架。實驗證明 DSD 可以可以提高多種 CNN、RNN 和 LSTM 在圖像分類、生成文字描述和語音識別任務的性能。在 ImageNet 上,DSD 提升了 GoogleNet Top-1 準確度 1.1%、VGG-16 Top-1 準確度 4.3%、ResNet-18 Top-1 準確度 1.2%、ResNet-50 Top-1 準確度 1.1%。在 WSJ』93 數據集上,DSD 把 DeepSpeech 和 DeepSpeech2 的錯誤率(WER)分別降低了 2.0% 和 1.1%。在 Flickr-8K 數據集上,DSD 將 NeuralTalk BLEU 的分數提高了 1.7 以上。
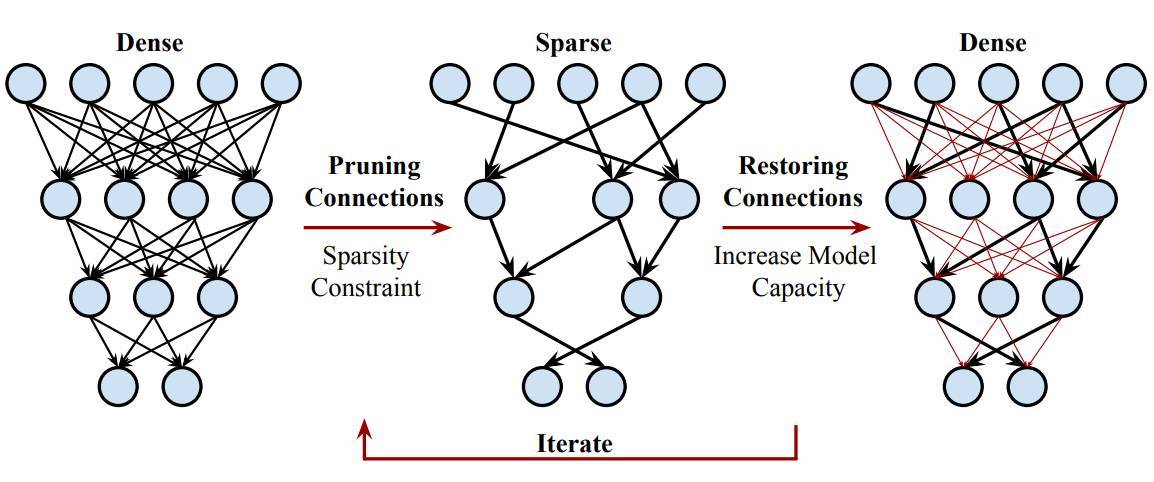
圖 5:DSD(Dense-Sparse-Dense)訓練法中迭代進行剪枝和恢復權重的過程。
第六章 EIE:用於稀疏神經網絡的高效推斷機
6.1 介紹
第三、四、五章介紹了三種提高深度學習效率的方法,本章着重介紹高效實現這些方法的硬件,「高效推斷機」(EIE)[28]。該機器可以在稀疏的壓縮模型上直接執行推斷,節省內存帶寬,實現大幅加速和能耗節約。
通過剪枝和量化訓練 [25] [26] 實現的深度壓縮能夠大幅降低模型大小和讀取深度神經網絡參數的內存帶寬。但是,在硬件中利用壓縮的 DNN 模型是一項具有挑戰性的任務。儘管壓縮減少了運算的總數,但是它引起的計算不規則性對高效加速帶來阻礙。例如,剪枝導致的權重稀疏使並行變的困難,也使優秀的密集型線性代數庫無法正常實現。此外,稀疏性激活值依賴於上一層的計算輸出,這隻有在算法實施時才能知道。爲了解決這些問題,實現在稀疏的壓縮 DNN 模型上高效地運行,我們開發了一種專門的硬件加速器 EIE,它通過共享權重執行自定義的稀疏矩陣乘法,從而減少內存佔用,並在執行推斷時實現大幅加速和能耗節約。
EIE 是處理單元(processing element/PE)的一種可擴展數組(scalable array)。它通過在處理單元上交織(interleave)矩陣的行來分配稀疏矩陣並實現並行計算。每個處理單元在 SRAM 中存儲一個網絡分區,與子網絡共同執行計算。EIE 利用了靜態權重稀疏性、動態激活向量稀疏性、相對索引(relative indexing)、共享權重和極窄權重(4 比特/extremely narrow weights)。
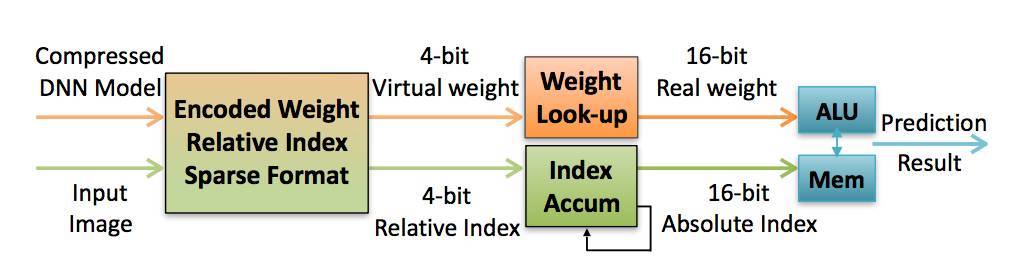
圖 6.1:壓縮 DNN 模型在 EIE 上運行。
EIE 架構如圖 6.1 所示。EIE 以壓縮稀疏列(compressed sparse column,CSC)格式存儲權重不爲零的稀疏權重矩陣 W。EIE 只在權重和激活值都不爲零的情況下執行乘法。EIE 以遊程編碼(run-length encoded)格式存儲每個權重的地址索引。在量化訓練和共享權重之後,每個權重只佔用 4 比特,它們可訪問由 16 個寄存器實現的查找表以解碼成 16 比特權重。
爲評估 EIE 的性能,我們創建了行爲級仿真和 RTL 模型,然後將 RTL 模型綜合、佈局佈線,以提取準確的能量和時鐘頻率。將 EIE 在九個 DNN 基準上進行評估,它的速度分別是未壓縮 DNN 的 CPU 和 GPU 實現的 189 和 13 倍。EIE 在稀疏網絡上的處理能力爲 102 GOPS/s,相當於在同等準確度的稠密網絡上 3 TOPS/s 的處理能力,且僅耗散 600mW 的能量消耗。EIE 的能耗分別比 CPU 和 GPU 少了 24,000 倍和 3,400 倍。EIE 的貢獻如下:
稀疏權重:EIE 是第一個用於稀疏和壓縮深度神經網絡的加速器。直接在稀疏壓縮模型上運行可使神經網絡的權重適應芯片上 SRAM,比訪問外部 DRAM 節省 120 倍的能耗。通過跳過零權重,EIE 節省了 10 倍的計算週期。
稀疏激活值:EIE 利用激活函數的動態稀疏性來節約算力和內存。EIE 通過避免在 70% 的激活函數上的計算節約了 65.16% 的能量,這些激活函數在典型深度學習應用中的值爲零。
權重編碼:EIE 是第一個用非統一量化、極窄權重(每個權重 4 比特)利用查找表執行推斷的加速器。與 32 比特浮點相比,它獲取權重節約了 8 倍的內存佔用,與 int-8 相比,它節約了 2 倍的內存佔用。
並行化:EIE 引入了在多個處理單元上分配存儲和算力的方法,以並行化稀疏層。EIE 還引入架構改變以達到負載平衡和優秀的擴展性。
第七章 結論
深度神經網絡改變了大量 AI 應用,也正在改變我們的生活。但是,深度神經網絡需要大量的計算量和內存。因此,它們很難部署到計算資源和能源預算有限的嵌入式系統中。爲了解決該問題,我們提出了改善深度學習效率的方法和硬件。
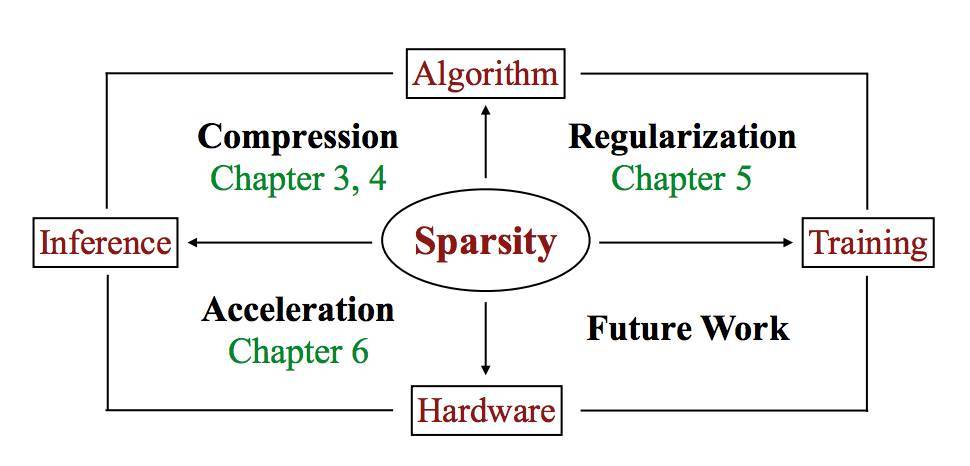
圖 7.1:論文總結
本文從三方面研究如何提高深度學習的效率:利用深度壓縮實現更小的模型大小、利用 DSD 正則化實現更高的預測準確度,以及利用 EIE 加速實現快速、能耗低的推斷(圖 7.1)。這三個方面遵循相同的原則:利用神經網絡的稀疏性進行壓縮、正則化和加速。
論文地址:https://stacks.stanford.edu/file/druid:qf934gh3708/EFFICIENT%20METHODS%20AND%20HARDWARE%20FOR%20DEEP%20LEARNING-augmented.pdf

百度AI實戰營·深圳站將於 10 月 19 日在深圳科興科學園國際會議中心舉行,AI 開發者與希望進入 AI 領域的技術從業者請點擊「閱讀原文」報名,與百度共同開創人工智能時代。
責任編輯: