在剛剛結束的 WMT2018 國際機器翻譯大賽上,阿里巴巴達摩院機器智能實驗室機器翻譯團隊打敗多個國外巨頭與研究機構,並在英文-中文翻譯、英文-俄羅斯語互譯、英文-土耳其語互譯這 5 個項目的自動評測指標 BLEU 分值都位居第一。阿里達摩院機器智能實驗室的陳博興博士和司羅教授向機器之心介紹了阿里在機器翻譯領域的佈局應用,以及如何通過對標準的 Transformer 模型進行改進和優化,而獲得更爲優秀的神經機器翻譯系統。
WMT 的全稱是 Workshop on Machine Translation,是國際公認的頂級機器翻譯賽事之一,也是各大科技公司與學術機構展示自身機器翻譯實力的平臺。由陳博興博士帶領的達摩院機器翻譯團隊,在此次比賽中使用業界最新的 Transformer 結構,進行了網絡結構的改進和對詞語位置信息的充分利用,全面改進了機器翻譯的性能。更重要的是,翻譯團隊充分利用了阿里的計算資源優勢,每一種翻譯任務都集成了幾十上百個基礎模型,這需要非常龐大的計算力而實現最優的性能。
在本文中,我們首先會介紹阿里達摩院爲什麼要做機器翻譯及它在 WMT 2018 所採用的基礎模型和修正方法,同時還會介紹達摩院所採用的模型集成方法。隨後我們還將介紹阿里在模型訓練中所採用的模型調優方法,它們可以令譯文具有更好的可讀性。最後,我們會介紹這一頂尖神經機器翻譯系統的部署與應用。
爲什麼阿里要做機器翻譯?
「機器翻譯是阿里國際化的生命線。」印度、拉美、東南亞等新興市場,都被認爲將產生「下一個五萬億美元」。作爲阿里達摩院機器智能實驗室 NLP 首席科學家,司羅不僅肩負着帶領團隊探索機器翻譯前沿技術的任務,更要支持阿里全球業務的快速發展,幫助阿里國際化跨過「語言」這道門檻。
「這也是爲什麼阿里在此次 WMT 比賽上,除了英中翻譯外,還參加中國企業很少涉足的英文-俄羅斯語互譯、英文-土耳其語互譯,並在這 4 個項目上戰勝諸多國外巨頭與研究機構,奪得冠軍。這背後的推動力量,正是機器翻譯在阿里國際化中體現的巨大業務價值。同時,背靠世界最大、質量最好的跨境電商語料庫,也讓阿里機器翻譯技術能在短時間內,取得世界領先。這就是我們期待看到的,研發與業務的協同發展。」
阿里在神經機器翻譯模型上的探索
近年來,基於編碼器解碼器框架的神經機器翻譯系統取得了很大的進步與應用。最開始我們基於循環神經網絡構建神經機器翻譯的標準模型,後來我們考慮使用卷積神經網絡提升並行訓練效果,而去年穀歌等研究團隊更是提出不使用 CNN 和 RNN 抽取特徵的 Transformer。儘管 Transformer 在解碼速度和位置編碼等方面有一些缺點,但它仍然是當前效果最好的神經機器翻譯基本架構。
阿里機器翻譯團隊在 WMT 2018 競賽上主要採用的還是 Transformer 模型,但是會根據最近的一些最新研究對標準 Transformer 模型進行一些修正。這些修正首先體現在將 Transformer 中的 Multi-Head Attention 替換爲多個自注意力分支,而模型會在訓練階段中將學習結合這些分支注意力模塊。其次,阿里採用了一種編碼相對位置的表徵以擴展自注意力機制,並令模型能更好地理解序列元素間的相對距離。
不過據陳博興博士介紹,在阿里集成的基礎模型中,也會有一些基於 RNN 的 Seq2Seq 模型,它會使用標準的編碼器-注意力機制-解碼器的架構。這些 Seq2Seq 模型在每項翻譯任務中大約佔所有集成模型中的 10%,集成模型的主體還是 Transformer 模型。
在 NMT 中,基於 Seq2Seq 的模型一般在編碼器中會使用多層 LTSM 對輸入的源語詞嵌入向量進行建模,並編碼爲一個上下文向量。但是這樣編碼的定長上下文向量很難捕捉足夠的語義信息,因此更好的方法即讀取整個句子或段落以獲取上下文和主旨信息,然後每一個時間步輸出一個翻譯的目標語詞,且每一個時間步都關注輸入語句的不同部分以獲取翻譯下一個詞的語義細節。這種關注輸入語句不同部分的方法即注意力機制。Seq2Seq 模型的最後一部分即將編碼器與注意力機制提供的上下文信息輸入到由 LSTM 構成的解碼器中,並輸出預測的目標語。
雖然基於 RNN 的 Seq2Seq 模型非常簡潔明瞭,但目前最優秀的神經機器翻譯模型並沒有採用這種架構。例如去年 Facebook 在 Convolutional Sequence to Sequence Learning 論文中提出的用 CNN 做神經機器翻譯,它在準確度尤其是訓練速度上都要超過最初基於 RNN 的模型。而後來谷歌在論文 Attention is all you need 中所提出的 Transformer 更進一步利用自注意力機制抽取特徵而實現當前最優的翻譯效果。
Transformer 基本架構
阿里在翻譯系統中主要採用的模型架構還是谷歌原論文所提出的 Transformer。陳博士表示,目前無論是從性能、結構還是業界應用上,Transformer 都有很多優勢。例如,自注意力這種在序列內部執行 Attention 的方法可以視爲搜索序列內部的隱藏關係,這種內部關係對於翻譯以及序列任務的性能有顯著性提升。
如 Seq2Seq 一樣,原版 Transformer 也採用了編碼器-解碼器框架,但它們會使用多個 Multi-Head Attention、前饋網絡、層級歸一化和殘差連接等。下圖從左到右展示了原論文所提出的 Transformer 架構、Multi-Head Attention 和標量點乘注意力。本文只簡要介紹這三部分的基本概念與結構,更詳細的 Transformer 解釋與實現請查看機器之心的 GitHub 項目:基於注意力機制,機器之心帶你理解與訓練神經機器翻譯系統。
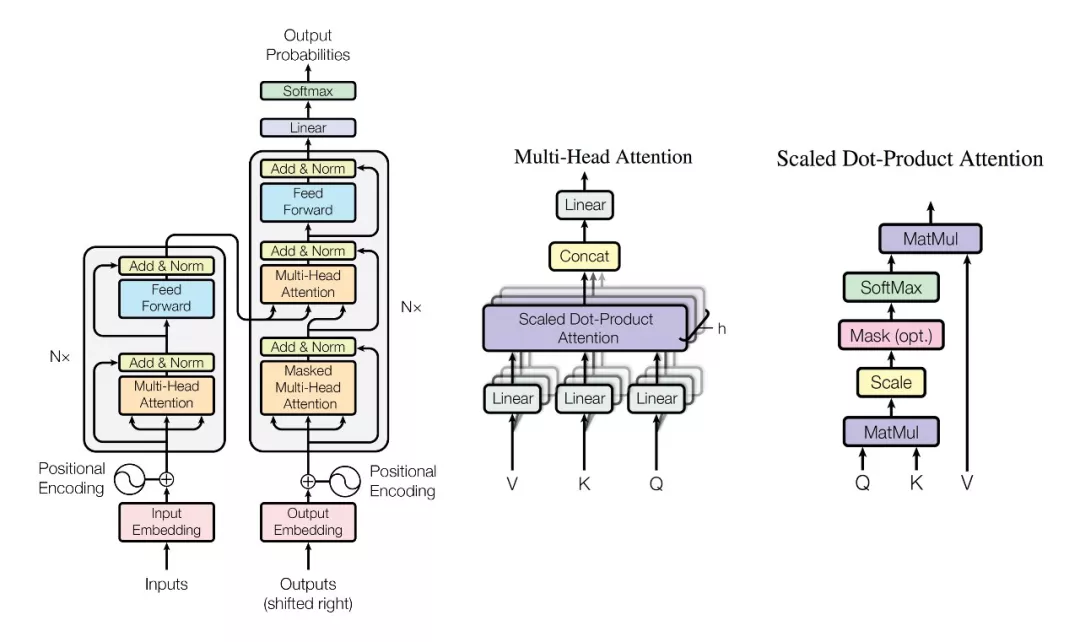
正如與陳博士所討論的,上圖右邊的標量點乘注意力其實就是標準 Seq2Seq 模型中的注意力機制。其中 Query 向量與 Value 向量在 NMT 中相當於目標語輸入序列與源語輸入序列,Query 與 Key 向量的點乘相當於餘弦相似性,經過 SoftMax 函數後可得出一組歸一化的概率。這些概率相當於給源語輸入序列做加權平均,即表示在翻譯一個詞時源語序列哪些詞是重要的。
上圖中間的 Multi-head Attention 其實就是多個點乘注意力並行地處理並最後將結果拼接在一起。一般而言,我們可以對三個輸入矩陣 Q、V、K 分別進行 h 個不同的線性變換,然後分別將它們投入 h 個點乘注意力函數並拼接所有的輸出結果。這種注意力允許模型聯合關注不同位置的不同表徵子空間信息,我們可以理解爲在參數不共享的情況下,多次執行點乘注意力。阿里的翻譯系統其實會使用另一種組合點乘注意力的方法,即不如同 Multi-head 那樣拼接所有點乘輸出,而是對點乘輸出做加權運算。
最後上圖左側爲 Transformer 的整體架構。輸入序列首先會轉換爲詞嵌入向量,在與位置編碼向量相加後可作爲 Multi-Head 自注意模塊的輸入,該模塊的輸出再與輸入相加後將投入層級歸一化函數,得出的輸出再饋送到全連接層後可得出編碼器模塊的輸出。這樣相同的 6 個編碼器模塊(N=6)可構成整個編碼器架構。解碼器模塊首先同樣構建了一個自注意力模塊,然後再結合前面編碼器的輸出實現 Multi-Head Attention,最後投入全連接網絡並輸出預測詞概率。此外,每一個編碼器與解碼器的子層都會帶有殘差連接與 Dropout 正則化。
加權的 Transformer 網絡
阿里根據論文 WEIGHTED TRANSFORMER NETWORK FOR MACHINE TRANSLATION 修正原版網絡架構,陳博士表示:「我們首先將谷歌原論文中的 Multi-Head 改進爲 Multi-Branch,也就是在每次執行注意力計算時,模型會考慮多個分支以獲得更多的信息。這種機制修正原版 Transformer 中等價處理每一個點乘注意力的方式,而允許爲不同點乘注意力分配不同的權重。Multi-Branch 的方法因爲簡化了優化過程而能提升收斂速度 15 − 40%,且還能提升 0.5 個 BLEU 分值。」
對於加權的 Transformer 來說,我們需要修改谷歌原版中的 Multi-Head 與 FFN。首先計算多個點乘注意力 head_i 的方式是一樣的,不過 Multi-Branch 如下會計算 head_i bar 而不是將所有 head 拼接在一起。head_i bar 即歸一化的點乘注意力,它輸入前饋網絡 FFN 並將結果做加權和就能得出 Multi-Branch 的最後輸出。
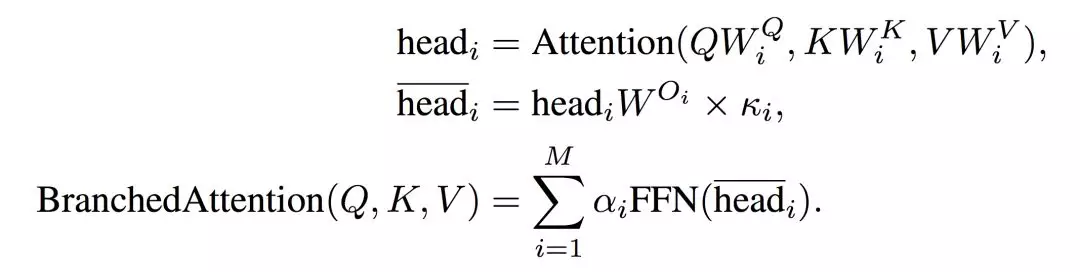
其中所有 k_i 與α_i 的和分別都等於 1,M 表示總的分支數,且表達式 BranchedAttention 會計算所有獨立分支注意力值的加權和。如下所示爲阿里翻譯系統所採用的 Multi-Branch 結構,其中 k 是可學習的參數以縮放所有分支對後續運算的貢獻大小,α 同樣也評估各注意力分支對結果的貢獻大小。
如下所示編碼器與解碼器的架構基本一致,只不過解碼器會增加一個 Mask 層以控制模型能訪問的目標語序列,即避免當前位置注意到後面位置的信息。這種 Multi-Branch 的修正結構每一個模塊只會增加 M 個參數,即 α 的數量,這對於整體模型來說基本是可忽略不計的。
相對位置表徵
除了採用 Multi-branch 代替 Multi-head,阿里在 WMT 2018 競賽上採用的模型還有一處比較大的修改,即使用一種可以表徵相對位置方法代替谷歌原論文中所採用的位置編碼。這種位置信息在注意力機制中非常重要,因爲 Transformer 僅採用注意力機制,而它本身並不能像 RNN 或 CNN 那樣獲取序列的位置順序信息。所以如果語句中每一個詞都有特定的位置,那麼每一個詞都可以使用向量編碼位置信息,這樣注意力機制就能分辨出不同位置的詞。
陳博士說:「我們另一個改進是參考了谷歌最近發表的一篇論文,在自注意力機制中加入相對位置信息。在 Transformer 原論文中,位置編碼使用的是絕對位置信息,也就是說每一個位置會給一個固定的描述。但是我們在實踐中發現語言中的相對位置非常重要,例如在英語到法語的翻譯中,英語是形容詞加名詞,而法語是名詞加形容詞。這種位置結構其實與短語所在的絕對位置沒有太大的關係,相反相對位置對正確的翻譯會有很大的影響。」
在原版 Transformer 中,谷歌研究者使用不同頻率的正弦和餘弦函數實現位置編碼:
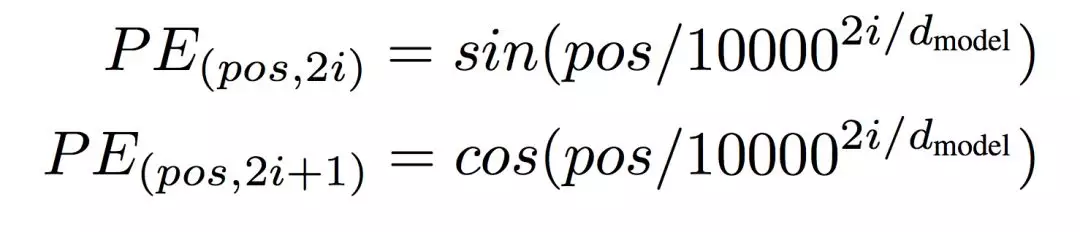
其中 pos 爲詞的位置,i 爲位置編碼向量的第 i 個元素。給定詞的位置 pos,我們可以將詞映射到 d_model 維的位置向量,該向量第 i 個元素就由上面兩個式子計算得出。也就是說,位置編碼的每一個維度對應於正弦曲線,波長構成了從 2π到 10000⋅2π的等比數列。
而阿里機器翻譯團隊採用的方法會考慮輸入序列中成對元素之間的位置關係,因此我們可以將輸入詞序列建模爲一個有向的全連接圖。在論文 Self-Attention with Relative Position Representations 中,作者們將詞 x_i 到詞 x_j 之間的有向邊表示爲 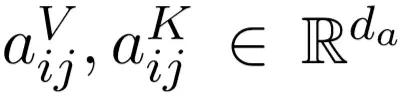 兩個向量,它們分別會與 Value 和 Key 向量相加而添加 x_i 到 x_j 的相對位置信息。
兩個向量,它們分別會與 Value 和 Key 向量相加而添加 x_i 到 x_j 的相對位置信息。
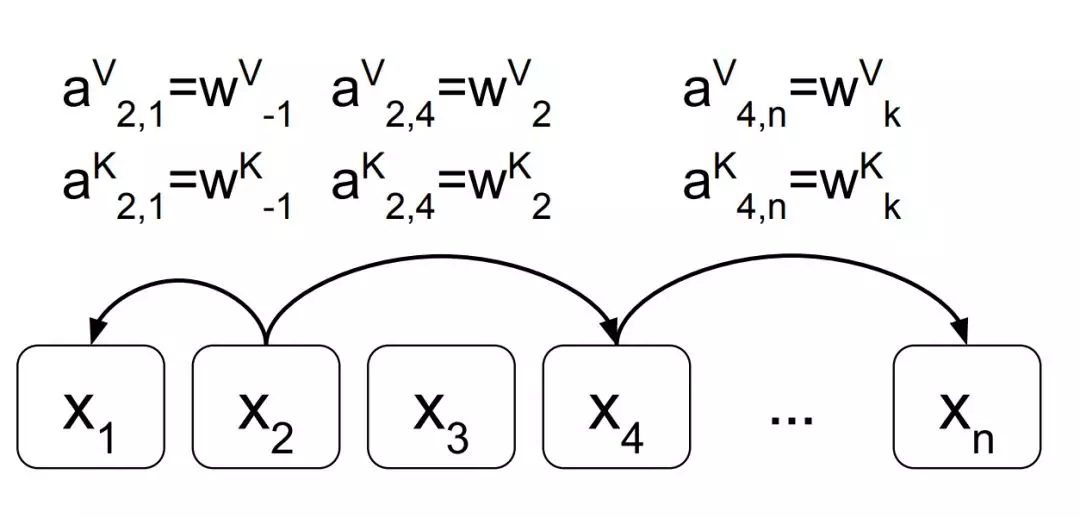
上圖展示了將輸入詞序列表示爲一個有向全連接圖,成對詞之間會有兩條有向邊。每條邊都編碼了相對位置信息,且相對位置信息的表達如上已經給出。
如下我們將向原版點乘自注意力運算中加入相對位置信息:
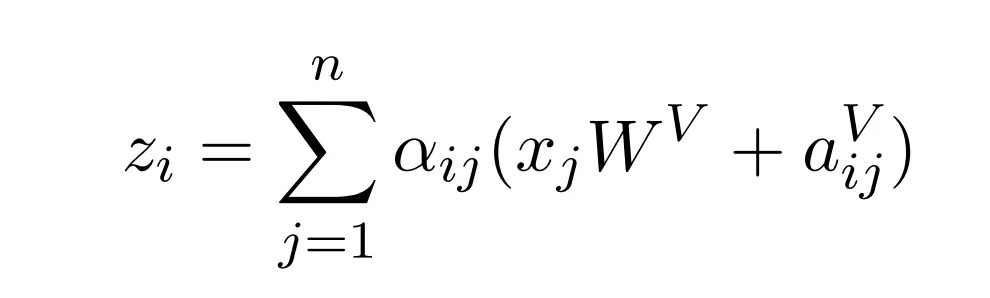
其中 z_i 表示一個點乘注意力,α 表示經過 Softmax 後的概率,它衡量了輸入序列需要注意哪些詞。後面即 Value 向量加上相對位置信息的過程,因爲是自注意力過程,所以 Value 向量等於輸入向量。因爲 Value 向量與 Key 向量是成對出現的,所以相對位置信息同時還應該添加到 Key 向量中,如下表達式在計算 Query 與 Key 向量間相似性的過程中實現了這一點:
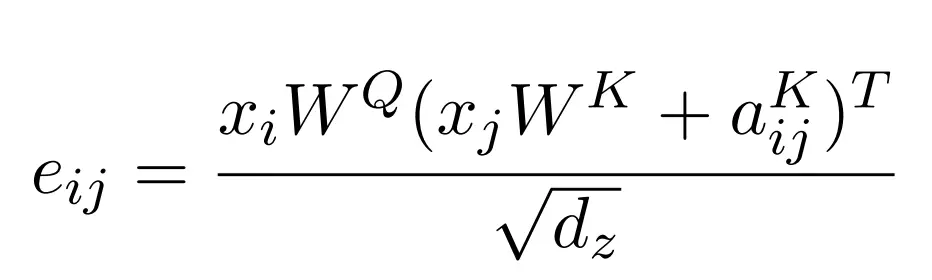
其中 e 爲 Query 向量與 Key 向量的內積,度量了它們之間的餘弦相似性,如果將這種相似性歸一化則可以度量翻譯某個詞時我們應該關注哪些重要的輸入詞。同樣因爲這是自注意力機制,那麼 Query 與 Key 向量都是輸入向量 x。上式分子中的相加項即將相對位置信息加入 Key 向量中。
除了上述這種標準的相對位置修正外,陳博士還表示阿里機器翻譯團隊在解碼部分也會添加這種相對位置信息,這種改進能提升大概 0.4 個 BLEU 分值。
模型集成
對於追求極致準確度的模型來說,速度並不是阿里參賽系統所首要考慮的事情。陳博士說:「這個比賽系統追求性能上的最大化,因此我們會準備上百到幾百個基礎模型,然後再根據貪心算法從這些備選的基礎模型中獲取最優的集成方案。一般這樣的集成根據不同的任務會有幾十到上百個基礎模型。」
其實前面所述的新型 Transformer 架構與修正方案並不會引起翻譯質量的質變,阿里翻譯模型真正強大的地方在於大規模的模型集成,這強烈地需要阿里雲提供算力支持。這種大規模的集成模型除了需要海量的計算力,同時在調參與優化過程中會遇到很多困難。這一點,阿里雲與阿里機器翻譯團隊憑藉經驗有效地解決了它們。
據陳博士表示,阿里在選擇集成的基礎模型時會使用貪心算法。也就是說首先選擇第一個基於 Seq2Seq 或 Transformer 的基礎模型,然後從幾百個備選模型中依次選擇不同的基礎模型,並考慮能獲得最優性能的兩模型集成方法。有了前面兩個模型的集成,再考慮集成哪個模型能獲得最好的性能而確定三模型集成方法。這樣一直迭代下去,直到添加任何基礎模型都不能提升性能就結束集成策略。這一過程對於計算力的需求非常大,因此還是得益於阿里雲的支持。
最後在集成模型的聯合預測中,阿里機器翻譯團隊採取所有基礎模型預測結果的期望作爲下一個詞的預測結果。陳博士說:「在集成模型預測下一個詞的時候,各個基礎模型都會給下一個詞打分,而我們會取這些分值的加權平均值作爲最後的預測分值。其中各基礎模型所加的權也是模型自己學的,優秀基礎模型所賦予的權重會大一些,不那麼優秀的會賦予小的權重。」
調優與應用
提升譯文效果
阿里其實也用了兩種技術提升譯文的可讀性,首先是基於神經網絡的詞尾預測,這一研究成果阿里已經發表在了今年的 AAAI 上。其次是另一種干預神經網絡翻譯時間與日期的技術。第一種技術主要解決的是複雜詞形的翻譯,例如在英語到俄語的翻譯中,阿里會將詞幹與詞尾切分開,然後先預測詞幹再預測詞尾。這樣詞尾的預測能利用更多的信息而提升預測結果,因此也就能提升複雜詞形的譯文效果。
第二個技術關注於數字或日期等低頻詞的翻譯。因爲神經網絡很難從細節學習到數字或日期的翻譯,所以阿里在原文端使用命名實體識別標記它們,並基於簡單的規則系統進行翻譯。這樣就能提升譯文的流利程度與翻譯效果。
在 WMT 挑戰賽外,在真實場景的翻譯中,司羅教授表示:「阿里的翻譯團隊既包括機器翻譯團隊,也包括人工翻譯團隊。其中機器翻譯團隊完全是算法驅動的,而人工翻譯團隊會基於機器翻譯進行修正。這樣機器翻譯與人工翻譯就能成爲一種促進關係,人力可以對翻譯結果進行修正並反饋給系統而產生更流暢的譯文。」
根據陳博士的解釋,阿里巴巴在論文 Improved English to Russian Translation by Neural Suffix Prediction 中提出的這種詞尾預測方法在解碼過程中會獨立地預測詞幹與詞尾,它的基本觀察即俄語和土耳其語等語言中的詞尾更多與前後詞的詞尾相關,而與前後詞的詞幹關係比較小。具體來說,在每一個解碼過程中都會先於詞尾生成詞幹。且在訓練過程中會使用兩種類型的目標端序列,即詞幹序列與詞尾序列,它們都是原目標端序列分割出來的。下圖展示了目標端(俄語)的這種詞幹與詞尾分割:
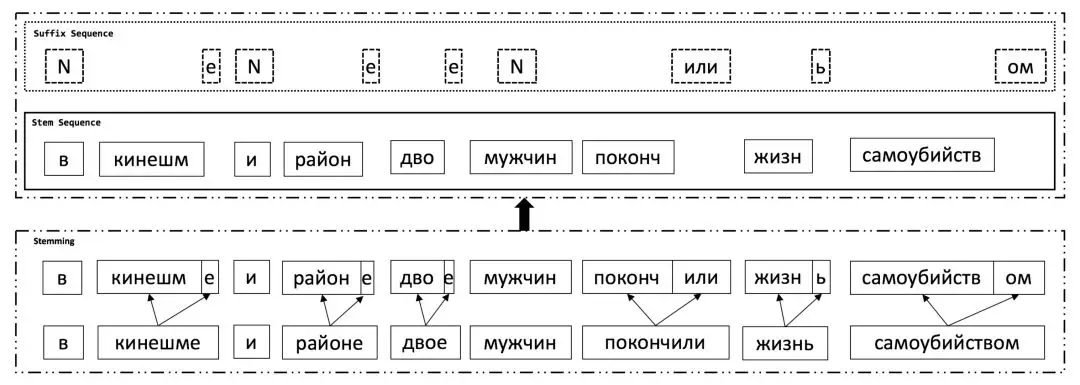
其中詞尾序列中的標記「N」代表對應詞幹沒有詞尾,上圖下部分的 stemming 表示從原目標序列切分爲詞幹和詞尾兩部分。由於詞幹的數量要遠少於詞的數量,且詞尾的數量甚至只有數百,這很大程度上降低了詞彙數據的稀疏性。此外,這種結構在預測詞尾時可以考慮前面生成的詞幹序列,這進一步提升了詞尾預測的準確性,也令譯文讀起來更加流暢。
部署與應用
其實模型在推斷過程中也會做一些如量化等模型壓縮方法,陳博士表示阿里在訓練中會使用 FP32,而在推斷中會使用 FP8 以節省計算成本。但爲 WMT 2018 準備的高性能模型並不能直接部署到應用中,因爲實際應用要求更低的延遲。
陳博士說:「如果要翻譯一個 30 詞的句子,我們需要控制響應時間在 200 毫秒左右。因此我們需要在效率和性能上找到一個平衡,一般已經應用的在線系統也使用相同的基礎模型,但不會如同競賽系統那樣實現大規模的集成。此外,在這一次的 WMT 競賽中,我們累積了非常多的經驗,因此隨後我們也會將這些經驗逐漸加到在線系統中去。」
阿里翻譯團隊選擇小語種作爲攻克對象是根據阿里巴巴業務而定的,不論是俄語還是土耳其語,阿里巴巴電商都需要將英文的產品描述翻譯到對應的小語種,所以有這樣優秀的翻譯平臺才能擴展業務。
據悉,阿里現在每天的電商機器翻譯總量已達 7.5 億次。以阿里巴巴國際站爲例,七成買家以英語溝通,還有 30% 爲小語種。而賣家端的調研數據顯示,大約 96% 的賣家對小語種無能爲力,需要藉助第三方軟件工具進行翻譯溝通。這一現狀,催生了對機器翻譯的巨大需求。
伴隨着阿里速賣通、全球站在俄羅斯、西班牙、巴西、土耳其等國的發展,目前阿里機器翻譯團隊已能支持包括俄語、西班牙語、泰語、印尼語、土耳其語在內的 21 種語言。包含跨境貿易所需的商品內容展示,跨語言搜索,買賣家實時溝通翻譯等 100 多個跨境電商服務場景。
司羅教授表示:「機器翻譯的發展無法脫離用戶與場景,阿里機器翻譯的不斷進步,得益於在電商、新零售、物流等領域積累的豐富場景和數據。特別是在俄語、土耳其語、西班牙語的探索上,讓我們看到了機器翻譯的巨大商業價值與應用潛力。」