神經網絡
Scikit-learn
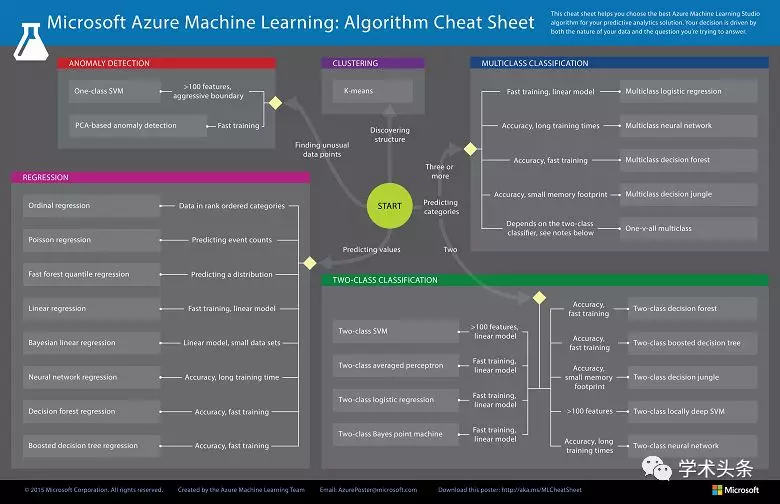
Microsoft Azure機器學習
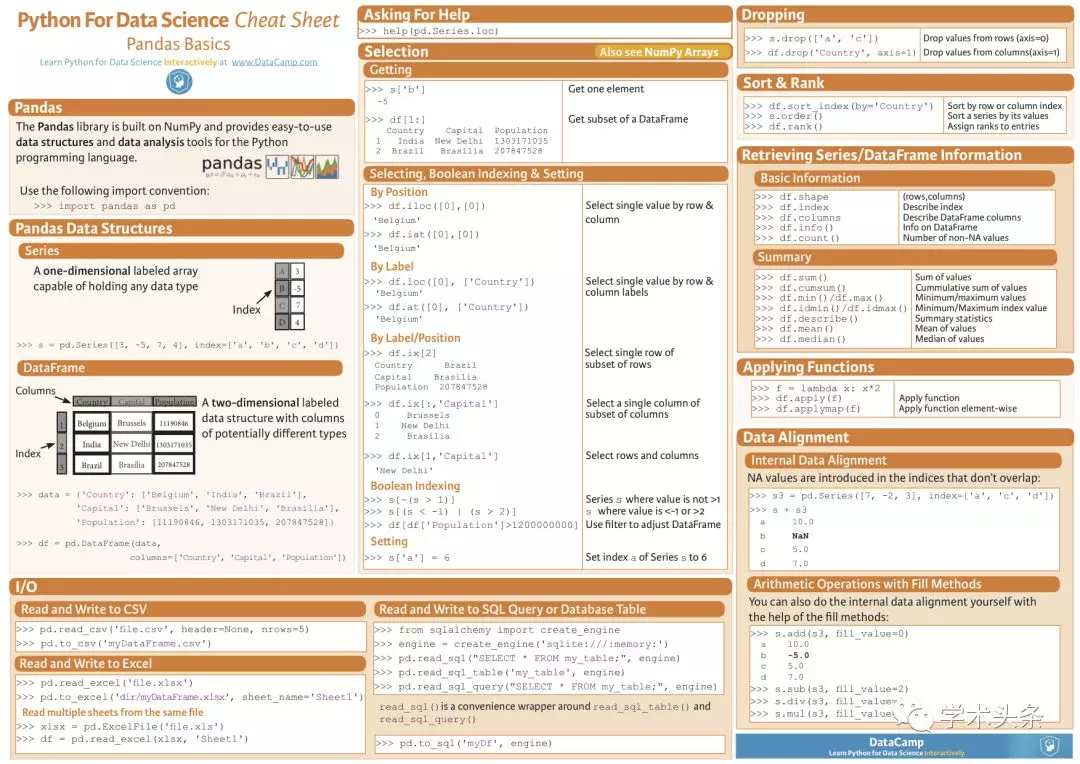
Python for Data Science
TensorFlow
Keras
NumPy
Pandas
Data Wrangling
Scipy
Matplotlib
Data Visualization
PySpark
Big-O

神經網絡清單

神經網絡圖清單


神經網絡清單

該流程圖將幫助您查看每個估算器的文檔和粗略指南,以幫助您瞭解有關問題的更多信息以及解決方法。
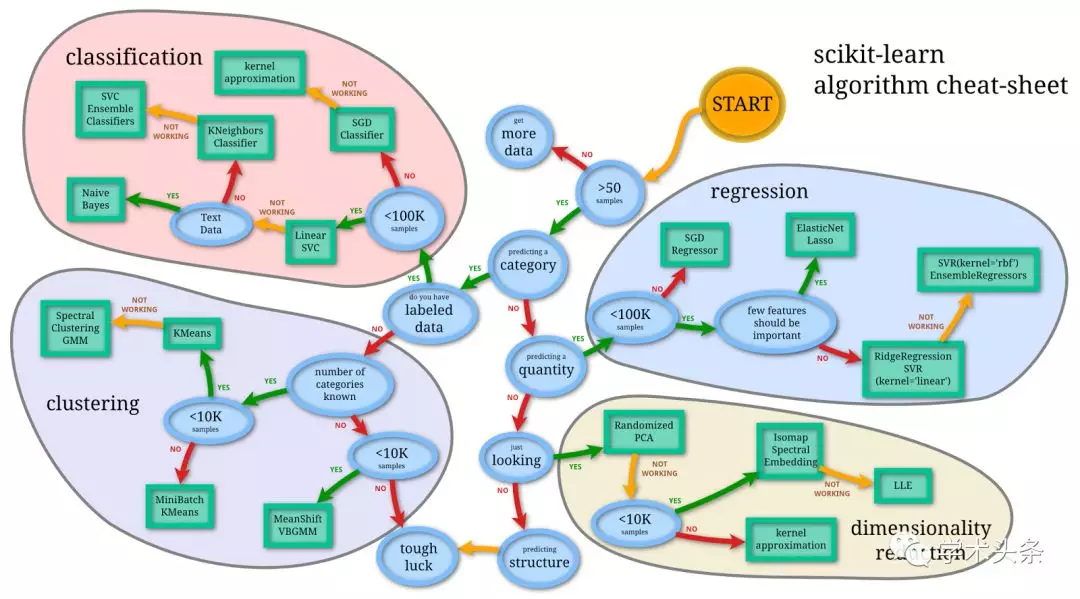
Scikit-learn(以前稱爲scikits.learn)是一個用於Python編程語言的免費軟件機器學習庫。它有各種分類、迴歸和聚類算法,包括支持向量機、隨機森林、梯度增強、k -means和DBSCAN,旨在與Python數值、科學庫NumPy和SciPy能互操作。

Microsoft Azure的這款機器學習備忘單將幫助您爲預測分析解決方案選擇合適的機器學習算法。首先,備忘單將詢問您數據的性質,然後爲該作業建議最佳算法。
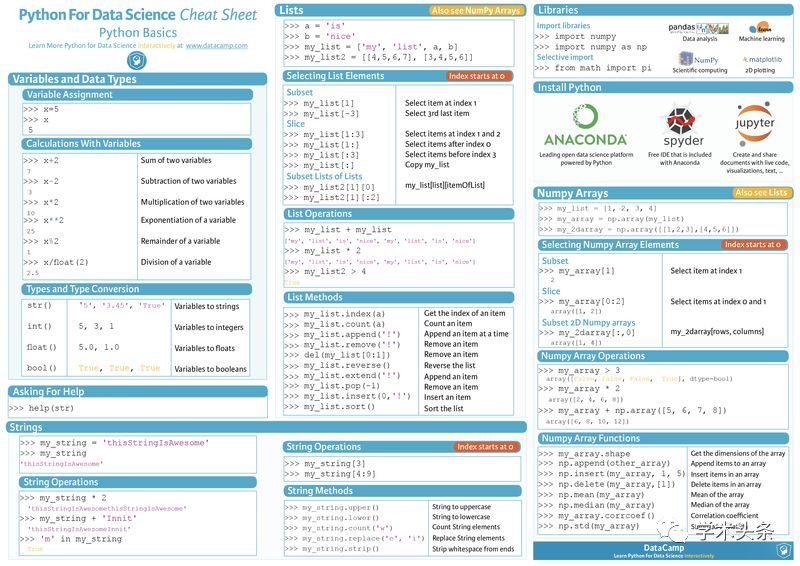
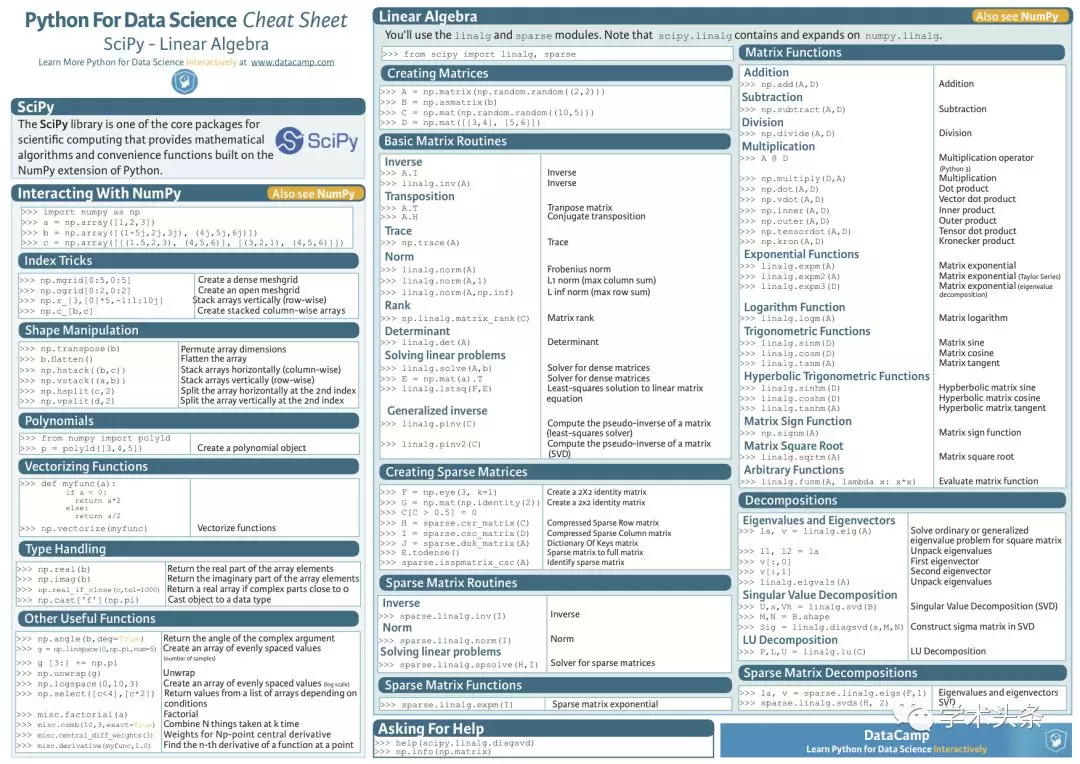
Python數據科學備忘單

大數據備忘單
2017年5月,Google發佈了第二代TPU,以及Google Compute Engine中 TPU的可用性。第二代TPU可提供高達180 teraflops的性能,當組織成64個TPU的簇時,可提供高達11.5 petaflops的性能。

2017年,Google的TensorFlow團隊決定在TensorFlow的核心庫中支持Keras。Chollet解釋說,Keras被認爲是一個界面,而不是端到端的機器學習框架。它提供了更高級別,更直觀的抽象集,無論後端科學計算庫如何,都可以輕鬆配置神經網絡。

NumPy的目標是Python 的CPython參考實現,它是一個非優化的字節碼解釋器。爲此版本的Python編寫的數學算法通常比編譯的等效算法慢得多。NumPy通過提供多維數組以及在數組上高效運行的函數和運算符來解決緩慢問題,需要重寫一些代碼,主要是使用NumPy的內部循環。

「Pandas」這個名稱來自術語「 面板數據 」,這是一個多維結構化數據集的計量經濟學術語。




SciPy構建於NumPy數組對象之上,包括Matplotlib/pandas和SymPy等工具,以及一組不斷擴展的科學計算庫。這個NumPy具有與其他應用程序類似的用戶,例如MATLAB、GNU Octave和Scilab。
matplotlib提供了一個面向對象的 API,用於使用通用GUI工具包(如Tkinter、wxPython、Qt或GTK +)將繪圖嵌入到應用程序中。


數據可視化備忘單

ggplot備忘單

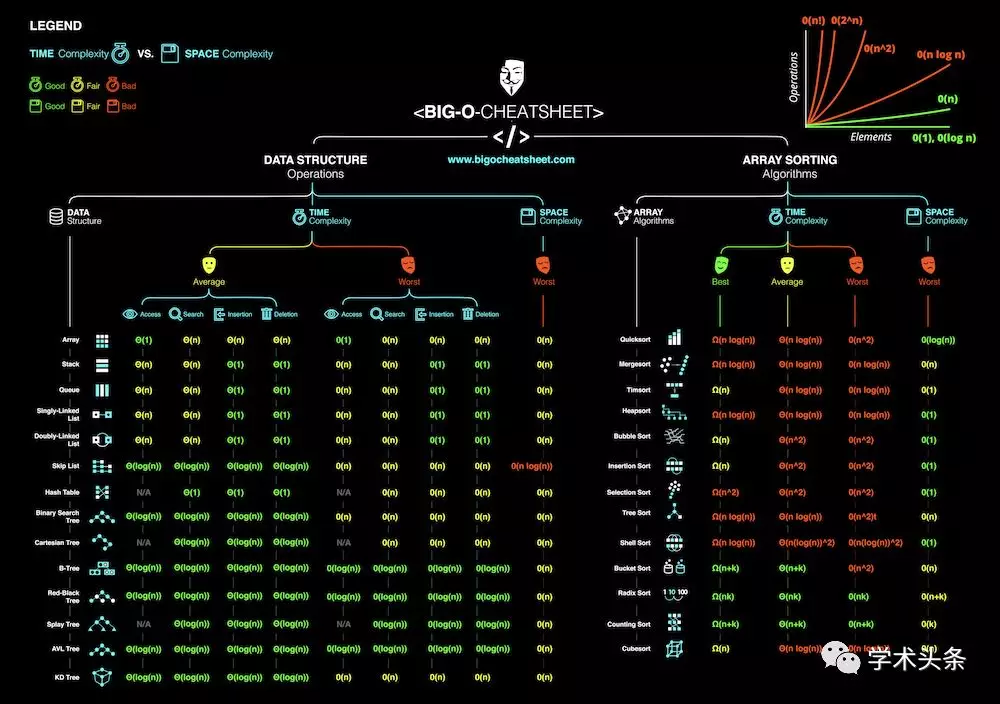
Big-O算法備忘單
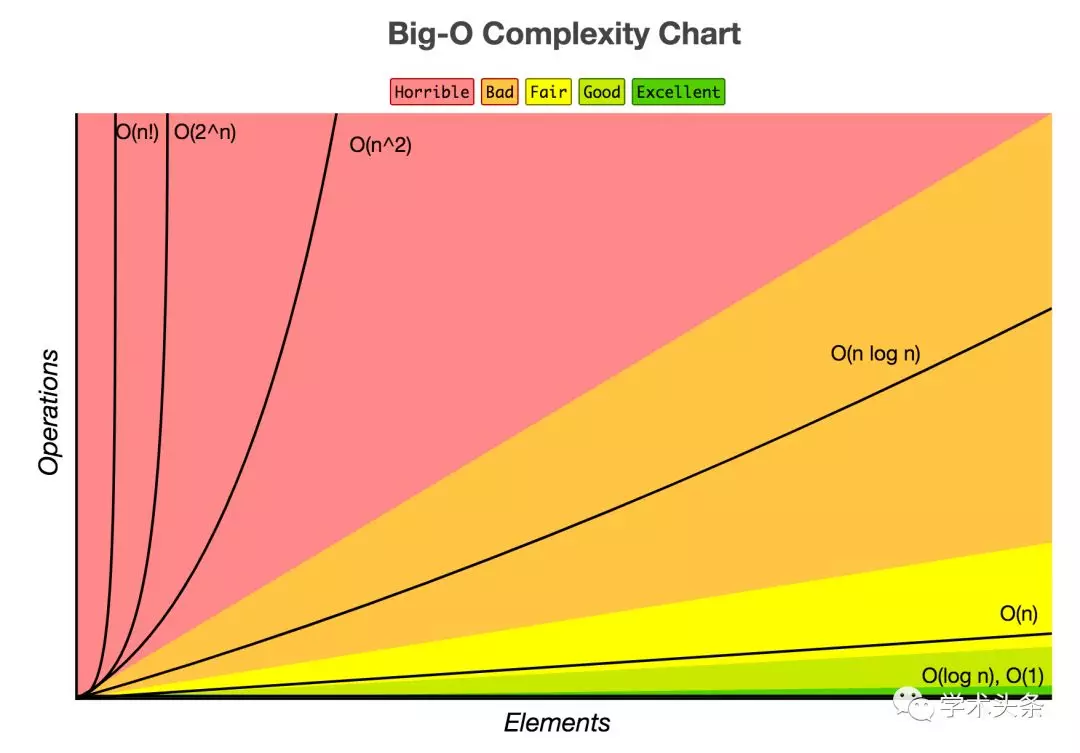
Big-O算法複雜度圖
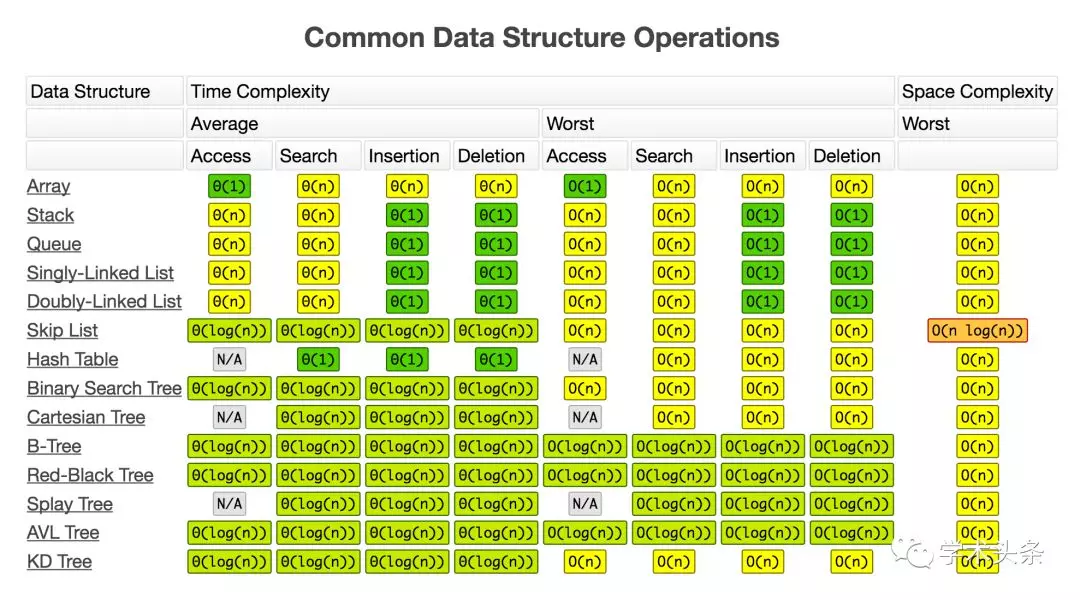
BIG-O算法數據結構操作
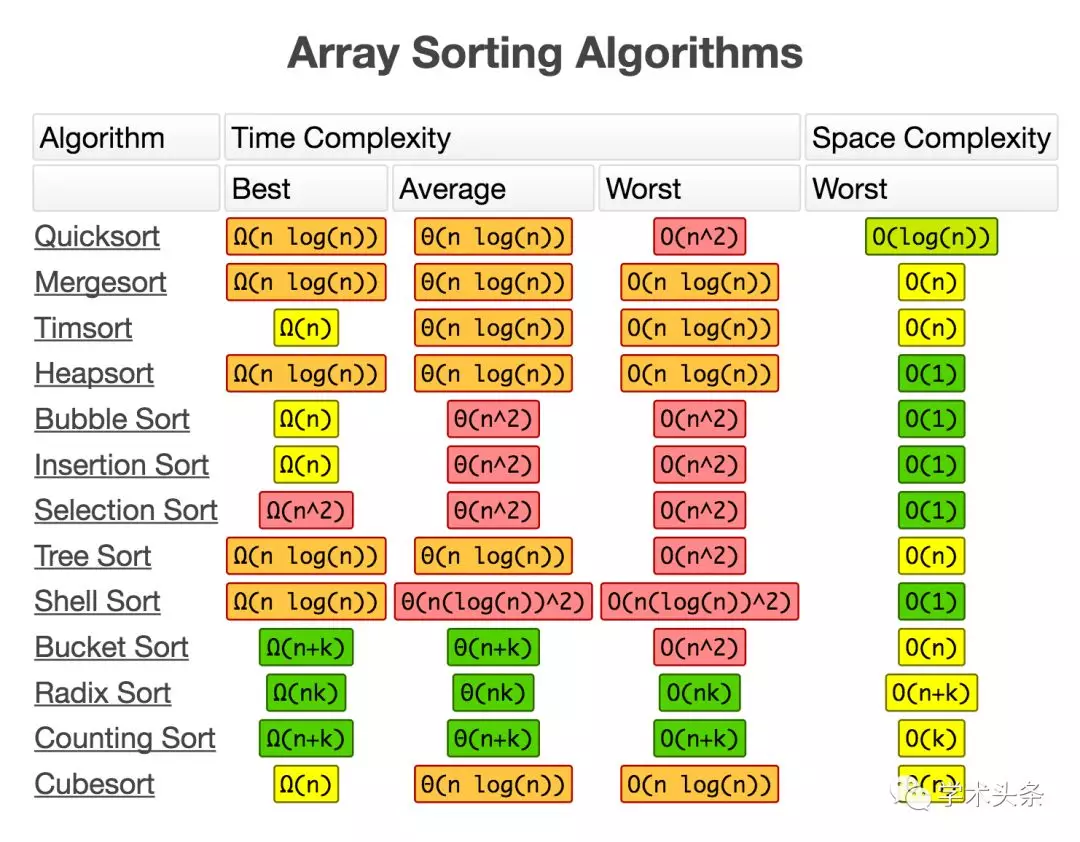
Big-O陣列排序算法
信息來源:https://becominghuman.ai/cheat-sheets-for-ai-neural-networks-machine-learning-deep-learning-big-data-678c51b4b463