1. 介紹
優秀的工程師確保其設計是實用的。目前我們已經知道解決序列分析問題最好的方式是長短期記憶(LSTM)循環神經網絡,接下來我們需要設計一個滿足資源受限的現實世界應用的實現。鑑於使用兩個門的門控循環單元(Cho 等,2014)的成功,第一種設計更硬件高效的 LSTM 的方法可能是消除冗餘門(redundant gate)。因爲我們要尋求比 GRU 更高效的模型,所以只有單門 LSTM 模型值得我們研究。爲了說明爲什麼這個單門應該是遺忘門,讓我們從 LSTM 的起源講起。
在那個訓練循環神經網絡(RNN)十分困難的年代,Hochreiter 和 Schmidhuber(1997)認爲在 RNN 中使用單一權重(邊)來控制是否接受記憶單元的輸入或輸出帶來了衝突性更新(梯度)。本質上來講,每一步中長短期誤差(long and short-range error)作用於相同的權重,且如果使用 sigmoid 激活函數的話,梯度消失的速度要比權重增加速度快。之後他們提出長短期記憶(LSTM)單元循環神經網絡,具備乘法輸入門和輸出門。這些門可以通過「保護」單元免受不相關信息(其他單元的輸入或輸出)影響,從而緩解衝突性更新問題。
LSTM 的第一個版本只有兩個門:Gers 等人(2000)首先發現如果沒有使記憶單元遺忘信息的機制,那麼它們可能會無限增長,最終導致網絡崩潰。爲解決這個問題,他們爲這個 LSTM 架構加上了另一個乘法門,即遺忘門,完成了我們今天看到的 LSTM 版本。
鑑於遺忘門最新發現的重要性,那麼設想 LSTM 僅使用一個遺忘門,輸入和輸出門是否必要呢?本研究將探索單獨使用遺忘門的優勢。在五個任務中,僅使用遺忘門的模型提供了比使用全部三個 LSTM 門的模型更好的解決方案。
3 JUST ANOTHER NETWORK
我們提出了一個簡單的 LSTM 變體,其只有一個遺忘門。它是 Just Another NETwork,因此我們將其命名爲 JANET。我們從標準 LSTM(Lipton 等,2015)開始,其中符號具備標準含義,定義如下
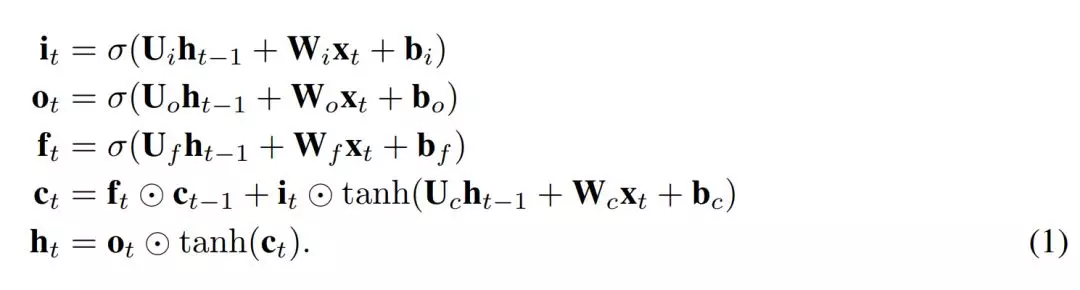
爲了將上述內容轉換成 JANET 架構,我們刪除了輸入和輸出門。將信息的累積和刪除關聯起來似乎是明智的,因此我們將輸入和遺忘調製結合起來,就像 Greff et al. (2015) 論文中所做的那樣,而這與 leaky unit 實現 (Jaeger, 2002, §8.1) 類似。此外,h_t 的 tanh 激活函數使梯度在反向傳播期間出現收縮,這可能加劇梯度消失問題。權重 U∗ 可容納 [-1,1] 區間外的值,因此我們可移除這個不必要且可能帶來問題的 tanh 非線性函數。得出的 JANET 結果如下:
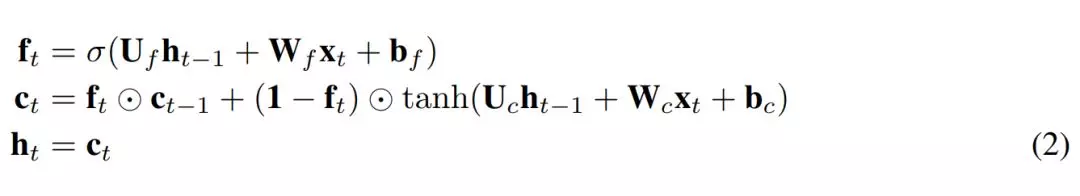
4 實驗與結果
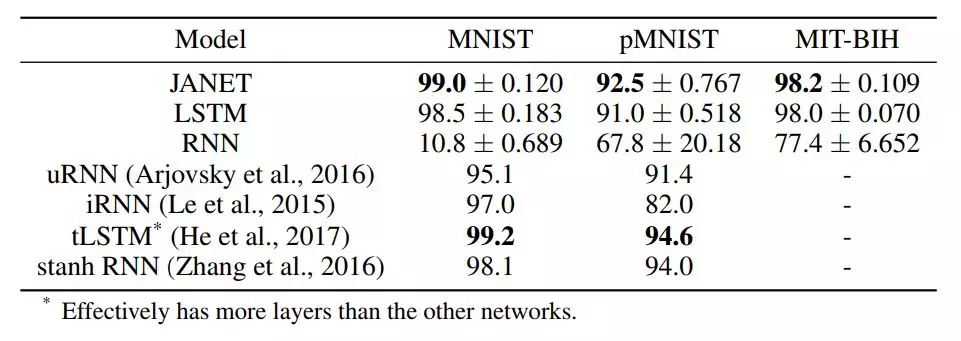
表 1:不同循環神經網絡架構的準確率 [%]。圖中展示了 10 次獨立運行得到的平均值和標準差。我們實驗中的最佳準確率結果以及引用論文中的最佳結果以粗體顯示。
令人驚訝的是,結果表明 JANET 比標準 LSTM 的準確率更高。此外,JANET 是在所有分析數據集上表現最佳的模型之一。因此,通過簡化 LSTM,我們不僅節省了計算成本,還提高了測試集上的準確率!
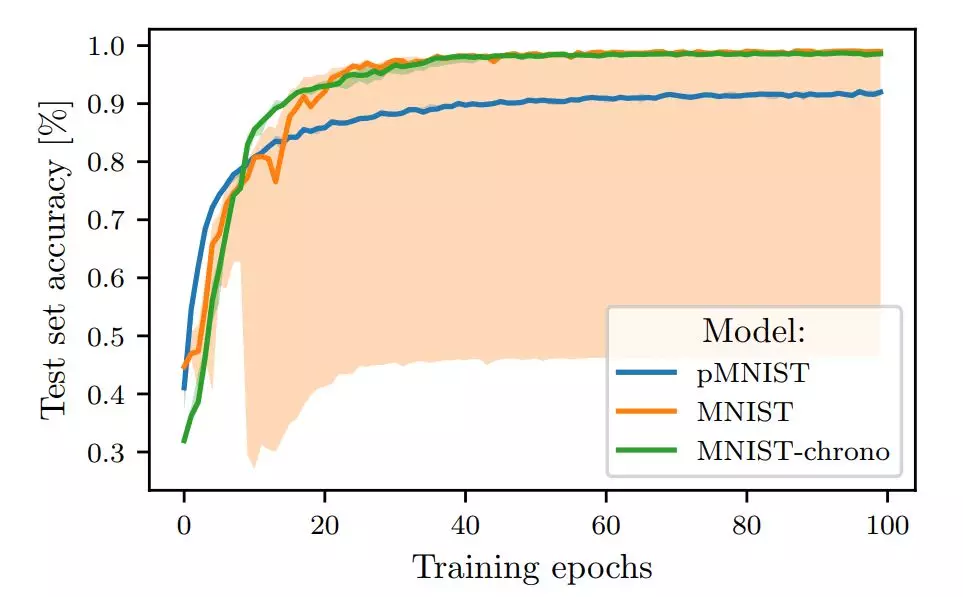
圖 1:在 MNIST 和 pMNIST 上訓練的 LSTM 的測試準確率。
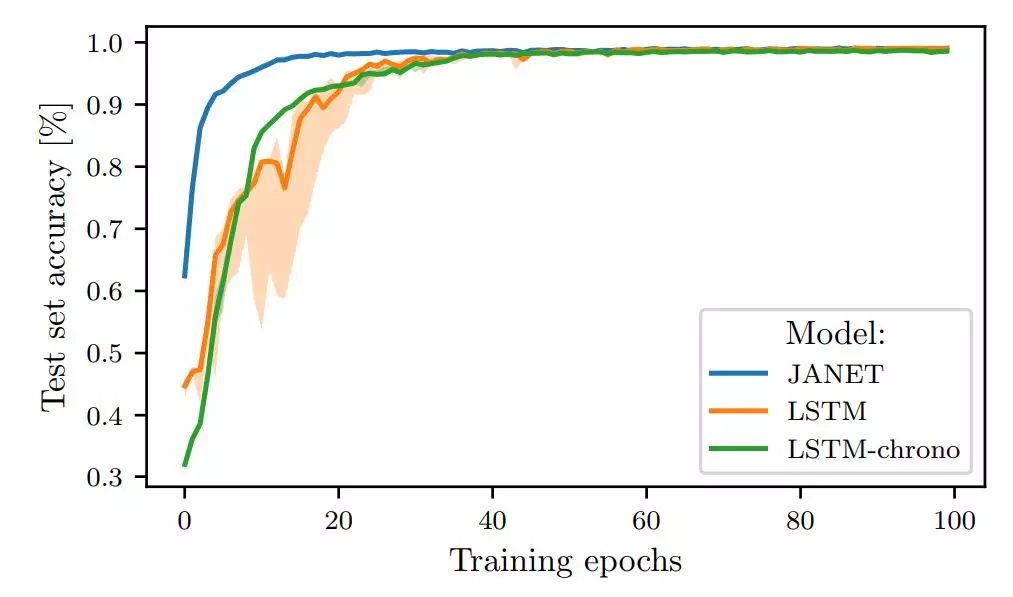
圖 2:JANET 和 LSTM 在 MNIST 上訓練時的測試集準確率對比。
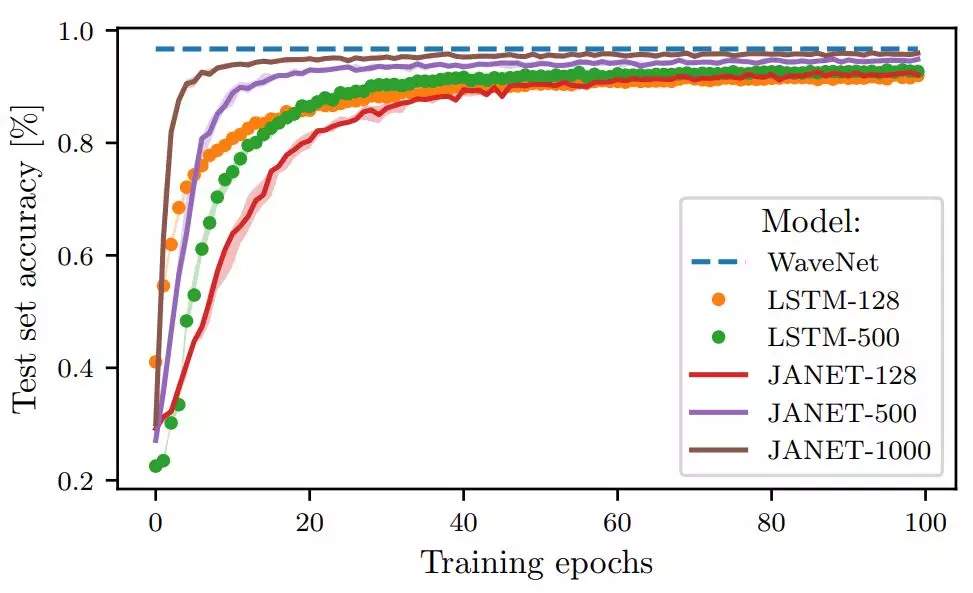
圖 3:不同層大小的 JANET 和 LSTM 在 pMNIST 數據集上的準確率(%)。
論文:THE UNREASONABLE EFFECTIVENESS OF THE FORGET GATE

論文鏈接:https://arxiv.org/abs/1804.04849
摘要:鑑於門控循環單元(GRU)的成功,一個很自然的問題是長短期記憶(LSTM)網絡中的所有門是否是必要的。之前的研究表明,遺忘門是 LSTM 中最重要的門之一。這裏我們發現,一個只有遺忘門且帶有 chrono-initialized 偏置項的 LSTM 版本不僅能節省計算成本,而且在多個基準數據集上的性能優於標準 LSTM,能與一些當下最好的模型競爭。我們提出的網絡 JANET,在 MNIST 和 pMNIST 數據集上分別達到了 99% 和 92.5% 的準確率,優於標準 LSTM 98.5% 和 91% 的準確率。