雷鋒網(公衆號:雷鋒網)按:本文作者蘭徹, 文章詳細介紹了1)人工智能發展的七個重要階段;2)深度學習在人工智能的發展;3)最後也提出作者對於深度學習挑戰和未來發展的看法。
Dave Bowman: Hello, HAL do you read me, HAL? 哈爾,你看到我了嗎?
HAL: Affirmative, Dave, I read you. 大衛,我看到你了
Dave Bowman: Open the pod bay doors, HAL. 哈爾,打開艙門
HAL: I'm sorry Dave, I'm afraid I can't do that. 對不起,大衛,我不能這做
~《2001: A Space Odyssey》~
這兩年人工智能熱鬧非凡,不僅科技巨頭髮力AI取得技術與產品的突破,還有衆多初創企業獲得風險資本的青睞,幾乎每週都可以看到相關領域初創公司獲得投資的報道,而最近的一次春雷毫無疑問是Google旗下Deepmind開發的人工智能AlphaGo與南韓李世石的圍棋之戰,AiphaGo大比分的獲勝讓人們對AI刮目相看的同時也引發了對AI將如何改變我們生活的思考。其實,人工智能從上世紀40年代誕生至今,經歷了一次又一次的繁榮與低谷,首先我們來回顧下過去半個世紀里人工智能的各個發展歷程。
|人工智能發展的七大篇章
人工智能的起源:人工智能真正誕生於20世紀的40 - 50年代,這段時間裏數學類、工程類、計算機等領域的科學家探討着人工大腦的可能性,試圖去定義什麼是機器的智能。在這個背景下,1950年Alan Turing發表了題爲「機器能思考嗎」的論文,成爲劃時代之作,提出了著名的圖靈測試去定義何爲機器具有智能,他說只要有30%的人類測試者在5分鐘內無法分辨出被測試對象,就可以認爲機器通過了圖靈測試。
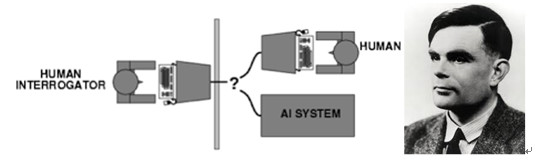
圖1:圖靈測試;Alan Turing本人
人工智能的第一次黃金時期:現在公認的人工智能起源是1956年的達特矛斯會議,在會議上計算機科學家John McCarthy說服了參會者接受「人工智能(Artificial Intelligence)」。達特矛斯會議之後的十幾年是人工智能的第一次黃金時代,大批研究者撲向這一新領域,計算機被應用於代數應用題、幾何定理證明,一些頂尖高校建立的人工智能項目獲得了ARPA等機構的大筆經費,甚至有研究者認爲機器很快就能替代人類做到一切工作。
人工智能的第一次低谷:到了70年代,由於計算機性能的瓶頸、計算複雜性的增長以及數據量的不足,很多項目的承諾無法兌現,比如現在常見的計算機視覺根本找不到足夠的數據庫去支撐算法去訓練,智能也就無從談起。後來學界將人工智能分爲兩種:難以實現的強人工智能和可以嘗試的弱人工智能。強人工智能是可以認爲就是人,可執行「通用任務」;弱人工智能則處理單一問題,我們迄今仍處於弱人工智能時代,而很多項目的停滯也影響了資助資金的走向,AI參與了長達數年之久的低谷。
專家系統的出現:1970年代之後,學術界逐漸接受新的思路:人工智能不光要研究解法,還得引入知識。於是,專家系統誕生了,它利用數字化的知識去推理,模仿某一領域的專家去解決問題,「知識處理」隨之成爲了主流人工智能的研究重點。在1977年世界人工智能大會提出的「知識工程」的啓發下,日本的第五代計算機計劃、英國的阿爾維計劃、歐洲的尤里卡計劃和美國的星計劃相機出臺,帶來專家系統的高速發展,涌現了卡內基梅隆的XCON系統和Symbolics、IntelliCorp等新公司。
人工智能的第二次經費危機:20世紀90年代之前的大部分人工智能項目都是靠政府機構的資助資金在研究室裏支撐,經費的走向直接影響着人工智能的發展。80年代中期,蘋果和IBM的臺式機性能已經超過了運用專家系統的通用型計算機,專家系統的風光隨之褪去,人工智能研究再次遭遇經費危機。
IBM的深藍和Watson:專家系統之後,機器學習成爲了人工智能的焦點,其目的是讓機器具備自動學習的能力,通過算法使得機器從大量歷史數據中學習規律並對新的樣本作出判斷識別或預測。在這一階段,IBM無疑是AI領域的領袖,1996年深藍(基於窮舉搜索樹)戰勝了國際象棋世界冠軍卡斯帕羅夫,2011年Watson(基於規則)在電視問答節目中戰勝人類選手,特別是後者涉及到放到現在仍然是難題的自然語言理解,成爲機器理解人類語言的里程碑的一步。
深度學習的強勢崛起:深度學習是機器學習的第二次浪潮,2013年4月,《麻省理工學院技術評論》雜誌將深度學習列爲2013年十大突破性技術之首。其實,深度學習並不是新生物,它是傳統神經網絡(Neural Network)的發展,兩者之間有相同的地方,採用了相似的分層結構,而不一樣的地方在於深度學習採用了不同的訓練機制,具備強大的表達能力。傳統神經網絡曾經是機器學習領域很火的方向,後來由於參數難於調整和訓練速度慢等問題淡出了人們的視野。
但是有一位叫Geoffrey Hinton的多倫多大學老教授非常執着的堅持神經網絡的研究,並和Yoshua Bengio、Yann LeCun(發明了現在被運用最廣泛的深度學習模型-卷積神經網CNN)一起提出了可行的deep learning方案。標誌性的事情是,2012年Hinton的學生在圖片分類競賽ImageNet上大大降低了錯誤率(ImageNet Classification with Deep Convolutional Neural Networks),打敗了工業界的巨頭Google,頓時讓學術界和工業界譁然,這不僅學術意義重大,更是吸引了工業界大規模的對深度學習的投入:2012年Google Brain用16000個CPU核的計算平臺訓練10億神經元的深度網絡,無外界干涉下自動識別了「Cat」;Hinton的DNN初創公司被Google收購,Hinton個人也加入了Google;而另一位大牛LeCun加盟Facebook,出任AI實驗室主任;百度成立深度學習研究所,由曾經領銜Google Brain的吳恩達全面負責。不僅科技巨頭們加大對AI的投入,一大批初創公司乘着深度學習的風潮涌現,使得人工智能領域熱鬧非凡。
|人工智能之主要引擎:深度學習
機器學習發展分爲兩個階段,起源於上世紀20年代的淺層學習(Shallow Learning)和最近幾年才火起來的深度學習(Deep Learning)。淺層學習的算法中,最先被髮明的是神經網絡的反向傳播算法(back propagation),爲什麼稱之爲淺層呢,主要是因爲當時的訓練模型是隻含有一層隱含層(中間層)的淺層模型,淺層模型有個很大的弱點就是有限參數和計算單元,特徵表達能力弱。
上世紀90年代,學術界提出一系列的淺層機器學習模型,包括風行一時的支撐向量機Support Vector Machine,Boosting等,這些模型相比神經網絡在效率和準確率上都有一定的提升,直到2010年前很多高校研究室裏都是用時髦的SVM等算法,包括筆者本人(當時作爲一名機器學習專業的小碩,研究的是Twitter文本的自動分類,用的就是SVM),主要是因爲這類淺層模型算法理論分析簡單,訓練方法也相對容易掌握,這個時期神經網絡反而相對較爲沉寂,頂級學術會議裏很難看到基於神經網絡算法實現的研究。
但其實後來人們發現,即使訓練再多的數據和調整參數,識別的精度似乎到了瓶頸就是上不去,而且很多時候還需要人工的標識訓練數據,耗費大量人力,機器學習中的5大步驟有特徵感知,圖像預處理,特徵提取,特徵篩選,預測與識別,其中前4項是不得不親自設計的(筆者經過機器學習的地獄般的折磨終於決定轉行)。在此期間,我們執着的Hinton老教授一直研究着多隱層神經網絡的算法,多隱層其實就是淺層神經網絡的深度版本,試圖去用更多的神經元來表達特徵,但爲什麼實現起來這麼苦難的呢,原因有三點:
1. BP算法中誤差的反向傳播隨着隱層的增加而衰減;優化問題,很多時候只能達到局部最優解;
2. 模型參數增加的時候,對訓練數據的量有很高要求,特別是不能提供龐大的標識數據,只會導致過度複雜;
3. 多隱層結構的參數多,訓練數據的規模大,需要消耗很多計算資源。
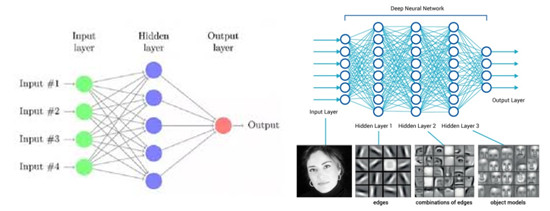
圖2:傳統神經網絡與多隱層神經網絡
2006年,Hinton和他的學生R.R. Salakhutdinov在《Science》上發表了一篇文章(Reducing the dimensionality of data with neural networks),成功訓練出多層神經網絡,改變了整個機器學習的格局,雖然只有3頁紙但現在看來字字千金。這篇文章有兩個主要觀點:1)多隱層神經網絡有更厲害的學習能力,可以表達更多特徵來描述對象;2)訓練深度神經網絡時,可通過降維(pre-training)來實現,老教授設計出來的Autoencoder網絡能夠快速找到好的全局最優點,採用無監督的方法先分開對每層網絡進行訓練,然後再來微調。
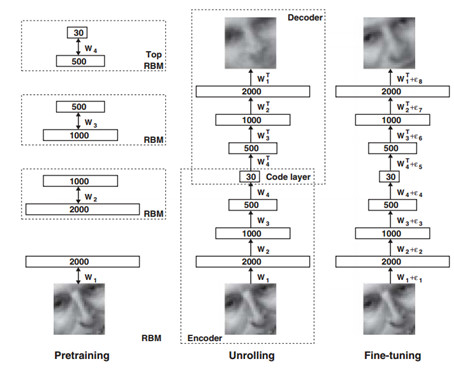
圖3:圖像的與訓練,編碼→解碼→微調
從圖3我們可以看到,深度網絡是逐層逐層進行預訓練,得到每一層的輸出;同時引入編碼器和解碼器,通過原始輸入與編碼→再解碼之後的誤差來訓練,這兩步都是無監督訓練過程;最後引入有標識樣本,通過有監督訓練來進行微調。逐層訓練的好處是讓模型處於一個接近全局最優的位置去獲得更好的訓練效果。
以上就是Hinton在2006年提出的著名的深度學習框架,而我們實際運用深度學習網絡的時候,不可避免的會碰到卷積神經網絡(Convolutional Neural Networks, CNN)。CNN的原理是模仿人類神經元的興奮構造:大腦中的一些個體神經細胞只有在特定方向的邊緣存在時才能做出反應,現在流行的特徵提取方法就是CNN。打個比方,當我們把臉非常靠近一張人臉圖片觀察的時候(假設可以非常非常的近),這時候只有一部分的神經元是被激活的,我們也只能看到人臉上的像素級別點,當我們把距離一點點拉開,其他的部分的神經元將會被激活,我們也就可以觀察到人臉的線條→圖案→局部→人臉,整個就是一步步獲得高層特徵的過程。
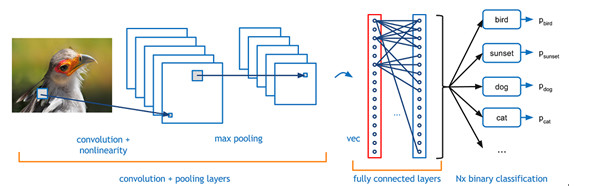
圖4:基本完整的深度學習流程
深度學習的「深」(有很多隱層),好處是顯而易見的 – 特徵表達能力強,有能力表示大量的數據;pretraining是無監督訓練,節省大量人力標識工作;相比傳統的神經網絡,通過逐層逐層訓練的方法降低了訓練的難度,比如信號衰減的問題。深度學習在很多學術領域,比淺層學習算法往往有20-30%成績的提高,驅使研究者發現新大陸一般涌向深度學習這一領域,弄得現在不說用了深度學習都不好意思發論文了。
|深度學習的重要發展領域
深度學習首先在圖像、聲音和語義識別取得了長足的進步,特別是在圖像和聲音領域相比傳統的算法大大提升了識別率,其實也很容易理解,深度學習是仿人來大腦神經感知外部世界的算法,而最直接的外部自然信號莫過於圖像、聲音和文字(非語義)。
圖像識別:圖像是深度學習最早嘗試的領域,大牛Yann LeCun早在1989年就開始了卷積神經網絡的研究,取得了在一些小規模(手寫字)的圖像識別的成果,但在像素豐富的圖片上遲遲沒有突破,直到2012年Hinton和他學生在ImageNet上的突破,使識別精度提高了一大步。2014年,香港中文大學教授湯曉鷗領導的計算機視覺研究組開發了名爲DeepID的深度學習模型, 在LFW (Labeled Faces in the Wild,人臉識別使用非常廣泛的測試基準)數據庫上獲得了99.15%的識別率,人用肉眼在LFW上的識別率爲97.52%,深度學習在學術研究層面上已經超過了人用肉眼的識別。
當然在處理真實場景的人臉識別時還是差強人意,例如人臉不清晰,光照條件,局部遮擋等因素都會影響識別率,所以在實際操作中機器學習與人工確認相結合,更加妥當。國內做人臉識別的公司衆多,其中Face++、中科奧森、Sensetime、Linkface、飛搜科技都是走在前面的,在真實環境運用或者在垂直細分領域中有着深厚的數據積累。在基於面部特徵識別技術的情緒識別領域,閱面科技與Facethink(Facethink爲天使灣早期投資項目)是國內少數進入該領域的初創公司。
語音識別:語音識別長期以來都是使用混合高斯模型來建模,在很長時間內都是佔據壟斷地位的建模方式,但儘管其降低了語音識別的錯誤率,但面向商業級別的應用仍然困難,也就是在實際由噪音的環境下達不到可用的級別。直到深度學習的出現,使得識別錯誤率在以往最好的基礎上相對下降30%以上,達到商業可用的水平。微軟的俞棟博士和鄧力博士是這一突破的最早的實踐者,他們與Hinton一起最早將深度學習引入語音識別並取得成功。由於語音識別的算法成熟,科大訊飛、雲知聲、思必馳在通用識別上識別率都相差不大,在推廣上科大訊飛是先行者,從軍用到民用,包括移動互聯網、車聯網、智能家居都有廣泛涉及。
自然語言處理(NLP):即使現在深度學習在NLP領域並沒有取得像圖像識別或者語音識別領域的成績,基於統計的模型仍然是NLP的主流,先通過語義分析提取關鍵詞、關鍵詞匹配、算法判定句子功能(計算距離這個句子最近的標識好的句子),最後再從提前準備的數據庫裏提供用戶輸出結果。顯然,這明顯談不上智能,只能算一種搜索功能的實現,而缺乏真正的語言能力。蘋果的Siri、微軟的小冰、圖靈機器人、百度度祕等巨頭都在發力智能聊天機器人領域,而應用場景在國內主要還是客服(即使客戶很討厭機器客戶,都希望能第一時間直接聯繫到人工服務),我認爲市場上暫時還沒出現成熟度非常高的產品。小冰衆多競爭對手中還是蠻有意思的,她的設想就是「你隨便和我聊天吧」,而其他競爭對手則專注於某些細分領域卻面臨着在細分領域仍是需要通用的聊天系統,個人認爲小冰經過幾年的數據積累和算法改善是具備一定優勢脫穎而出。
爲什麼深度學習在NLP領域進展緩慢:對語音和圖像來說,其構成元素(輪廓、線條、語音幀)不用經過預處理都能清晰的反映出實體或者音素,可以簡單的運用到神經網絡裏進行識別工作。而語義識別大不相同:首先一段文本一句話是經過大腦預處理的,並非自然信號;其次,詞語之間的相似並不代表其意思相近,而且簡單的詞組組合起來之後意思也會有歧義(特別是中文,比如說「萬萬沒想到」,指的是一個叫萬萬的人沒想到呢,還是表示出乎意料的沒想到呢,還是一部電影的名字呢);對話需要上下文的語境的理解,需要機器有推理能力;人類的語言表達方式靈活,而很多交流是需要知識爲依託的。很有趣,仿人類大腦識別機制建立的深度學習,對經過我們人類大腦處理的文字信號,反而效果差強人意。根本上來說,現在的算法還是弱人工智能,可以去幫人類快速的自動執行(識別),但還是不能理解這件事情本身。
|深度學習的挑戰和發展方向的探討
受益於計算能力的提升和大數據的出現,深度學習在計算機視覺和語音識別領域取得了顯著的成果,不過我們也看到了一些深度學習的侷限性,亟待解決:
1. 深度學習在學術領域取得了不錯的成果,但在商業上對企業活動的幫助還是有限的,因爲深度學習是一個映射的過程,從輸入A映射到輸出B,而在企業活動中我如果已經擁有了這樣的A→B的配對,爲什麼還需要機器學習來預測呢?讓機器自己在數據中尋找這種配對關係或者進行預測,目前還是有很大難度。
2. 缺乏理論基礎,這是困擾着研究者的問題。比如說,AlphaGo這盤棋贏了,你是很難弄懂它怎麼贏的,它的策略是怎樣的。在這層意思上深度學習是一個黑箱子,在實際訓練網絡的過程中它也是個黑箱子:神經網絡需要多少個隱層來訓練,到底需要多少有效的參數等,都沒有很好的理論解釋。我相信很多研究者在建立多層神經網絡的時候,還是花了很多時間在枯燥的參數調試上。
3. 深度學習需要大量的訓練樣本。由於深度學習的多層網絡結構,其具備很強的特徵表達能力,模型的參數也會增加,如果訓練樣本過小是很難實現的,需要海量的標記的數據,避免產生過擬合現象(overfitting)不能很好的表示整個數據。
4. 在上述關於深度學習在NLP應用的篇章也提到,目前的模型還是缺乏理解及推理能力。
因此,深度學習接下來的發展方向也將會涉及到以上問題的解決,Hinton、LeCun和Bengio三位AI領袖曾在合著的一篇論文(Deep Learning)的最後提到:
(https://www.cs.toronto.edu/~hinton/absps/NatureDeepReview.pdf)
1. 無監督學習。雖然監督學習在深度學習中表現不俗,壓倒了無監督學習在預訓練的效果,但人類和動物的學習都是無監督學習的,我們感知世界都是通過我們自己的觀察,因此若要更加接近人類大腦的學習模式,無監督學習需要得到更好的發展。
2. 強化學習。增強學習指的是從外部環境到行爲映射的學習,通過基於回報函數的試錯來發現最優行爲。由於在實際運用中數據量是遞增的,在新數據中能否學習到有效的數據並做修正顯得非常重要,深度+強化學習可以提供獎勵的反饋機制讓機器自主的學習(典型的案例是AlphaGo)。
3. 理解自然語言。老教授們說:趕緊讓機器讀懂語言吧!
4. 遷移學習。把大數據訓練好的模型遷移運用到有效數據量小的任務上,也就是把學到的知識有效的解決不同但相關領域的問題,這事情顯得很性感,但問題就在遷移過程已訓練好的模型是存在自我偏差的,所以需要高效的算法去消除掉這些偏差。根本上來說,就是讓機器像人類一樣具備快速學習新知識能力。
自深度學習被Hinton在《Science》發表以來,短短的不到10年時間裏,帶來了在視覺、語音等領域革命性的進步,引爆了這次人工智能的熱潮。雖然目前仍然存在很多差強人意的地方,距離強人工智能還是有很大距離,它是目前最接近人類大腦運作原理的算法,我相信在將來,隨着算法的完善以及數據的積累,甚至硬件層面仿人類大腦神經元材料的出現,深度學習將會更進一步的讓機器智能化。
最後,我們以Hinton老先生的一段話來結束這篇文章:「It has been obvious since the 1980s that backpropagation through deep autoencoders would be very effective for nonlinear dimensionality reduction, provided that computers were fast enough, data sets were big enough, and the initial weights were close enough to a good solution. All three conditions are now satisfied.」(自從上世紀80年代我們就知道,如果有計算機足夠快、數據足夠大、初始權重值足夠完美,基於深度自動編碼器的反向傳播算法是非常有效的。現在,這三者都具備了。)
雷鋒網注:文章由作者授權首發,如需轉載請聯繫原作者。蘭徹來自於天使灣創投,專注於人工智能與機器人領域投資,曾在日本學習工作十年,深研AI機器人業務,愛好黑科技,歡迎各類AI和機器人領域創業者勾搭,微信hongguangko-sir。
雷鋒網特約稿件,未經授權禁止轉載。詳情見轉載須知。
