
雷鋒網(公衆號:雷鋒網)AI科技評論按:微信羣是目前我們最常用的多人聊天方式之一,不過在習以爲常的建羣拉人過程中,一個有意思的問題是,一個微信羣建立起來了,根據社會關係所構建起來的網絡關係,誰更可能是下一步被邀請入羣的人呢?來自清華大學的唐傑團隊和騰訊公司一起對這個問題進行了深入細緻的研究,工作發表在IJCAI17上,論文題目爲《Who to Invite Next? Predicting Invitees of Social Groups》,作者包括韓矞(清華),唐傑(清華),葉浩(騰訊),陳波(騰訊)。雷鋒網邀請第一作者韓矞對論文進行了解讀。
論文地址:https://www.ijcai.org/proceedings/2017/0519.pdf
該工作基於微信平臺研究羣組邀請問題,就是預測針對某一個羣,哪些人會被邀請至這個羣。針對這個問題,我們先來看下面一個例子。
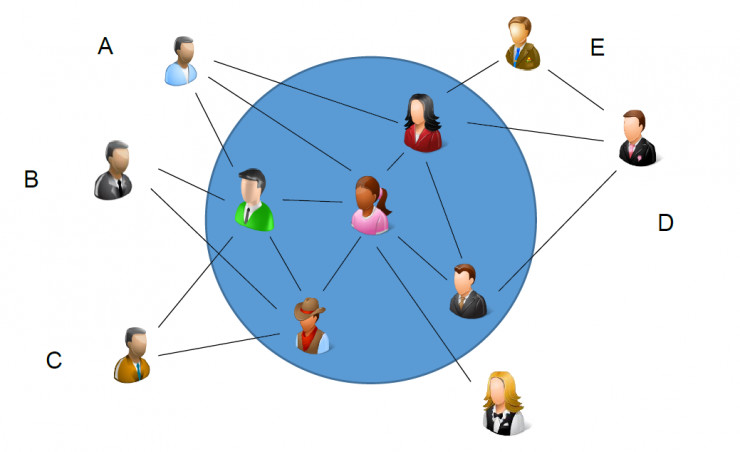
圖 1
上面這張圖表示某一個時刻的一個社交網絡的羣組及其相關的用戶,比如我們可以把它看作一個微信聊天羣,每個頭像表示一個用戶,用戶之間的邊可以看作微信好友關係。處於藍色圓圈內的用戶是這個微信羣的成員,我們把不屬於微信羣但與羣成員有好友關係的用戶稱爲這個羣的「邊緣用戶」,也就是問題中的可能被邀請者。那麼根據這張圖展現的網絡結構關係,我們直觀地感覺哪一個用戶將會在下一個時刻被邀請?也許用戶 A 的可能性大一些,因爲他有三個好友在羣裏。那麼再提一個問題,如果用戶 B 在下一個時刻被邀請入羣,那麼誰更可能會被邀請入羣?結論也許是 C,因爲 B 與 C 有兩個共同好友。這給我們解決預測被邀請者提供了一些思路,不過我們還是需要在實際數據上驗證我們的直覺。
我們在真實的微信社交平臺上提取了數據進行觀察。我們提取了微信在半個小時內新建的有名字的羣進行研究,共涉及到了 300 多萬個用戶,400 多萬條邊和將近 100 多萬條邀請記錄。爲了分析羣組的變化過程,我們在羣組產生時刻到一後之間的時間段中設置了 7 個觀察點進行觀察,分別是羣組新建後的半小時,1 小時,3 小時,24 小時,1 個月,3 個月,6 個月以及 1 年後。見下圖:
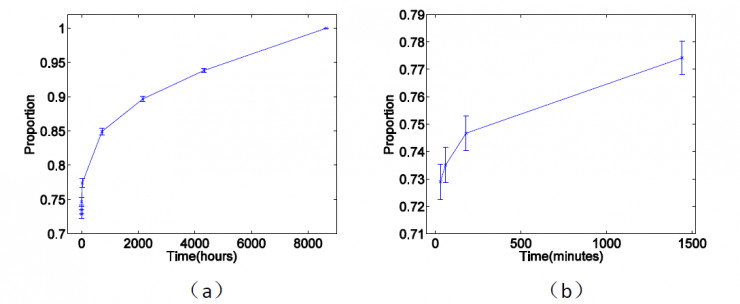
圖 2
圖 2(a)表示的是羣組成員數一年的變化情況。我們以最後一個觀察點爲基準,計算之前每個觀察點的羣組成員數的百分比。橫軸是時間軸,縱軸是百分比。爲了更好展示羣組在前四個觀察點的變化情況,我們專門把前四個觀察點畫在圖 2(b)中。我們可以看到,羣組隨着時間變化呈現出不斷增大的趨勢,而且時間越靠前,增大速度越快,時間過去越久,增大速度越慢。而隨着微信羣的增大,用戶被邀請進羣的概率也隨之變小,如圖 3 所示。
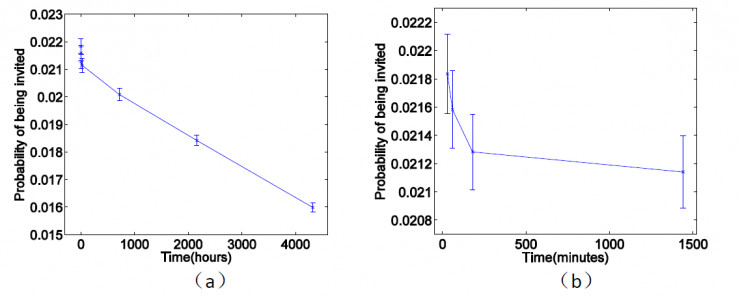
圖 3
圖 3(a)表示的是用戶被邀請入羣的可能性隨時間變化的情況。同樣,圖 3(b)是前四個觀察點的放大版。所以我們可以得出一個結論,從羣的整體屬性角度講,它會對用戶的入羣可能性產生影響。
接着,我們進一步觀察用戶之間的互相影響。我們先設想如果兩個邊緣用戶針對某一個羣具有某種相近性,那麼我們就可以認爲這兩個用戶針對這個羣的被邀請可能性具有某種相關性。也就是說一個用戶被邀請後,另一個用戶隨即也會被邀請。我們把這種用戶稱爲這個羣的「夥伴邊緣用戶」。爲了更量化地分析這種相關性,我們這裏定義兩種夥伴用戶。第一種是這個羣的兩個邊緣用戶具有好友關係。第二種是這個羣的兩個邊緣用戶有不止一個共同好友是這個羣的成員。如圖 4 所示:
圖 1 中,用戶 D 和用戶 E 屬於第一種夥伴邊緣用戶,而用戶 B 和用戶 C 屬於第二種夥伴邊緣用戶。圖 4 量化展示了這兩種用戶被邀請入羣的可能性。
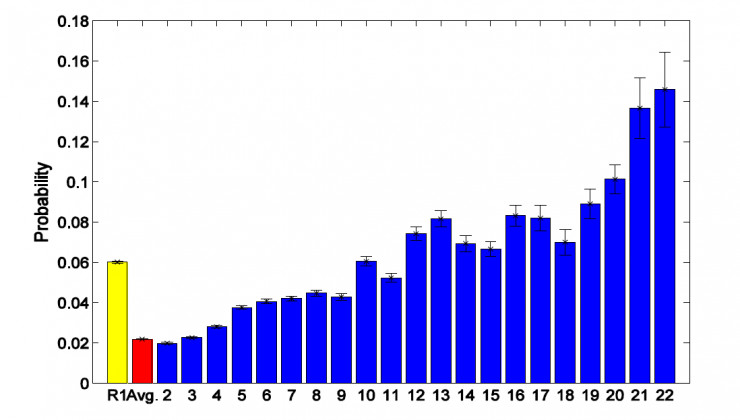
圖 4
圖 4 中,紅色柱體代表用戶的平均入羣概率,黃色柱體代表第一種夥伴邊緣用戶在有一個用戶入羣后另一個用戶入羣的可能性,藍色柱體代表第二種夥伴邊緣用戶在有一個用戶入羣后另一個用戶入羣的可能性,藍色柱體下面的數字標號代表這兩個用戶在羣中的共同好友個數。我們可以看到,這兩種夥伴邊緣用戶的入羣可能性要遠高於平均可能性。
我們還有一個假設是如果一個用戶和一個羣越「親密」,那麼這個用戶被邀入羣的可能性就越大。爲了驗證這個假設,我們先定義兩個指標來衡量這種親密程度。第一種是羣成員中用戶的好友數,第二種是羣成員中用戶的鄰接三角形數(即用戶的鄰接閉三角形中另兩個節點在羣中)。例如圖 1 中用戶 A 的第一種指標值是 3,第二種指標值是 2.
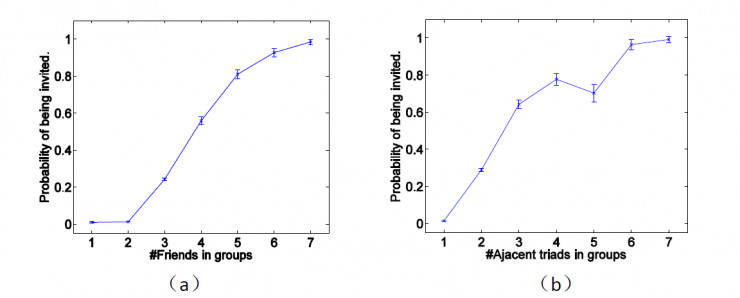
圖 5
圖 5(a)所示的是用戶第一種指標的可能性。橫軸是用戶的羣成員好友數,縱軸是入羣可能性。圖 5(b)展示的是用戶第二種指標的可能性。橫軸是用戶羣成員鄰接三角形數,縱軸是入羣可能性。很明顯,對於這兩種指標,都是值越大,入羣可能性總體上也是增大的趨勢。
因此,我們可以把影響用戶入羣可能性的因素歸結爲三大類,即羣整體因素,用戶之間的因素和用戶與羣關係的因素,分別用 g,h 和 f 表示。我們可以爲這三種因素分別建模,即:
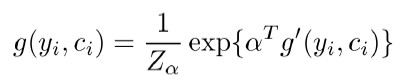
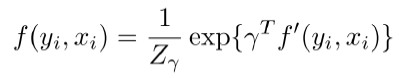
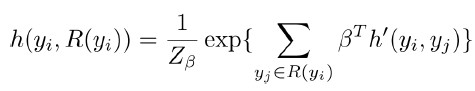
然後再把它們融合到一個統一框架中。如圖 6 所示。
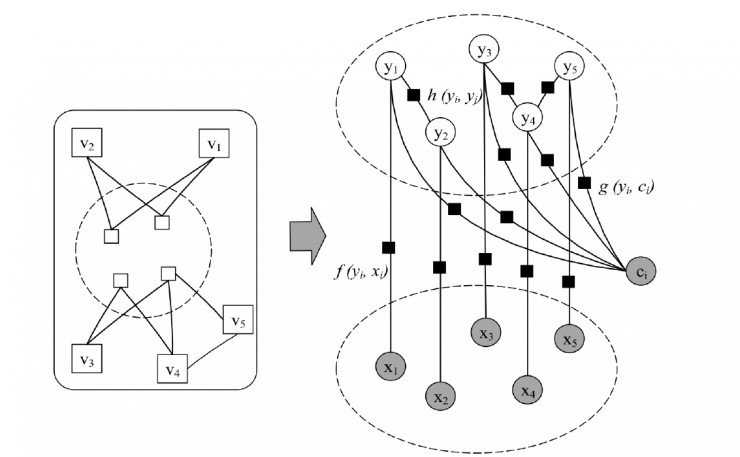
圖 6
根據因子圖模型理論我們可以將用戶入羣可能性分解爲這三種因素的乘積,即
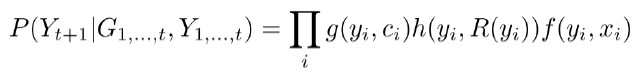
繼而得到目標函數,即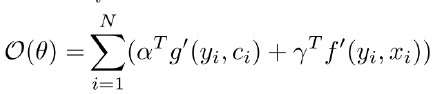
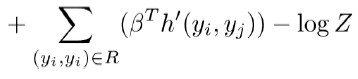 。
。
我們對目標函數求偏導,得到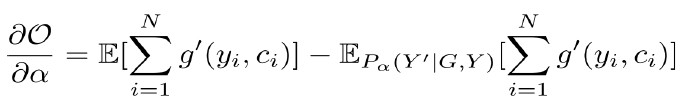
其他兩種因子參數與其類似,在此省略。此式中,等號右邊的第一項表示函數基於數據分佈的期望,這個比較好算,因爲數據是有限的。第二項是函數基於模型參數的期望,這個無法計算。我們採用信念傳播的方法來解決這個問題。有了偏導值,我們就可以採用梯度更新的方式來優化參數,即
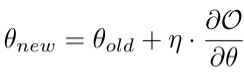
然後用優化好的參數來預測用戶是否被邀入羣。
我們用兩種基準方法來評估模型的性能。第一種是分類方法,第二種是鏈接預測方法。實驗結果如表 1 所示(ML-FGM 是文中所述模型)。
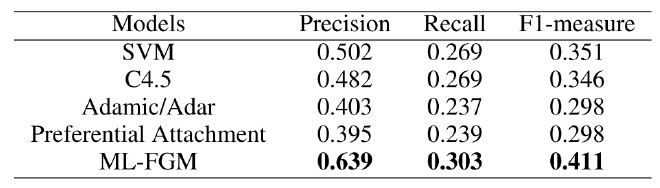
表 1
另外,爲了觀察每種因子的對模型性能的影響,我們分別移除羣因子,用戶互相影響因子來做實驗,如圖 7 所示。
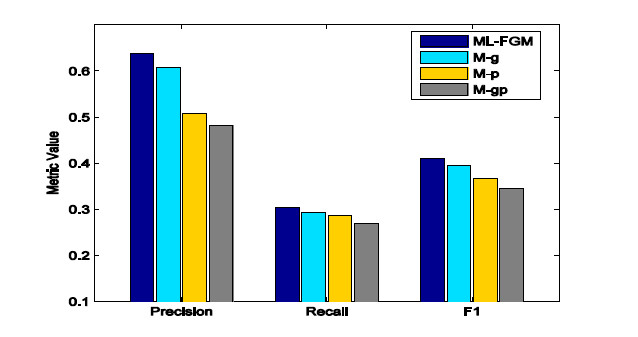
圖 7
四種顏色柱體分別表示無移除,只移除羣因子,只移除用戶互相影響因子和移除這兩種因子的性能。可以看到,移除用戶互相影響因子對性能的影響還是比較大的。
本文從影響用戶入羣的因素分析着手,採用一個概率因子圖模型將可能影響用戶被邀入羣的三種因素集成到一個框架中,提高了預測用戶入羣的概率。羣組是社交網絡中的一個重要概念,我們可以用用戶網絡結構來預測羣組的發展變化,另一方面,羣組的發展變化也影響着用戶網絡結構。因此,研究羣組對用戶網絡結構的影響並利用該信息預測網絡結構的發展變化也是本領域亟待解決的一個問題。
