轉載自螞蟻金服科技
作者:曹紹升 陸巍 周俊 李小龍
詞向量算法是自然語言處理領域的基礎算法,在序列標註、問答系統和機器翻譯等諸多任務中都發揮了重要作用。詞向量算法最早由谷歌在2013年提出的word2vec,在接下來的幾年裏,該算法也經歷不斷的改進,但大多是僅適用於拉丁字符構成的單詞(比如英文),結合中文語言特性的詞向量研究相對較少。本文介紹了螞蟻金服人工智能部與新加坡科技大學一項最新的合作成果:cw2vec——基於漢字筆畫信息的中文詞向量算法研究,用科學的方法揭示隱藏在一筆一劃之間的祕密。

AAAI大會(Association for the Advancement of Artificial Intelligence),是一年一度在人工智能方向的頂級會議之一,旨在彙集世界各地的人工智能理論和領域應用的最新成果。該會議固定在每年的2月份舉行,由AAAI協會主辦。
第32屆AAAI大會-AAAI 2018將於2月2號-7號在美國新奧爾良召開,其中螞蟻金服人工智能部和新加坡科技大學合作的一篇基於漢字筆畫信息的中文詞向量算法研究的論文「cw2vec: Learning Chinese Word Embeddings with Stroke n-grams」被高分錄用(其中一位審稿人給出了滿分,剩下兩位也給出了接近滿分的評價)。我們將在2月7日在大會上做口頭報告(Oral),歡迎大家一起討論交流。
單個英文字符(character)是不具備語義的,而中文漢字往往具有很強的語義信息。不同於前人的工作,我們提出了「n元筆畫」的概念。所謂「n元筆畫」,即就是中文詞語(或漢字)連續的n個筆畫構成的語義結構。

▲圖1 n元筆畫生成的例子
如上圖,n元筆畫的生成共有四個步驟。比如說,「大人」這個詞語,可以拆開爲兩個漢字「大」和「人」,然後將這兩個漢字拆分成筆畫,再將筆畫映射到數字編號,進而利用窗口滑動產生n元筆畫。其中,n是一個範圍,在上述例子中,我們將n取值爲3, 4和5。
在論文中我們提出了一種基於n元筆畫的新型的損失函數,如下:
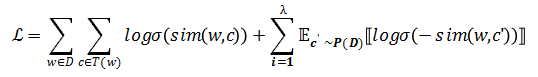
其中,W和C分別爲當前詞語和上下文詞語,σ是sigmoid函數,T(w)是當前詞語劃窗內的所有詞語集合,D是訓練語料的全部文本。爲了避免傳統softmax帶來的巨大計算量,這篇論文也採用了負採樣的方式。C'爲隨機選取的詞語,稱爲「負樣例」,λ是負樣例的個數,而則表示負樣例C'按照詞頻分佈進行的採樣,其中語料中出現次數越多的詞語越容易被採樣到。相似性sim(·,·)函數被按照如下構造:
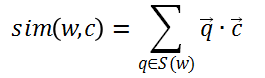
其中,爲當前詞語對應的一個n元筆畫向量,而是其對應的上下文詞語的詞向量。這項技術將當前詞語拆解爲其對應的n元筆畫,但保留每一個上下文詞語不進行拆解。S(w)爲詞語w所對應的n元筆畫的集合。在算法執行前,這項研究先掃描每一個詞語,生成n元筆畫集合,針對每一個n元筆畫,都有對應的一個n元筆畫向量,在算法開始之前做隨機初始化,其向量維度和詞向量的維度相同。
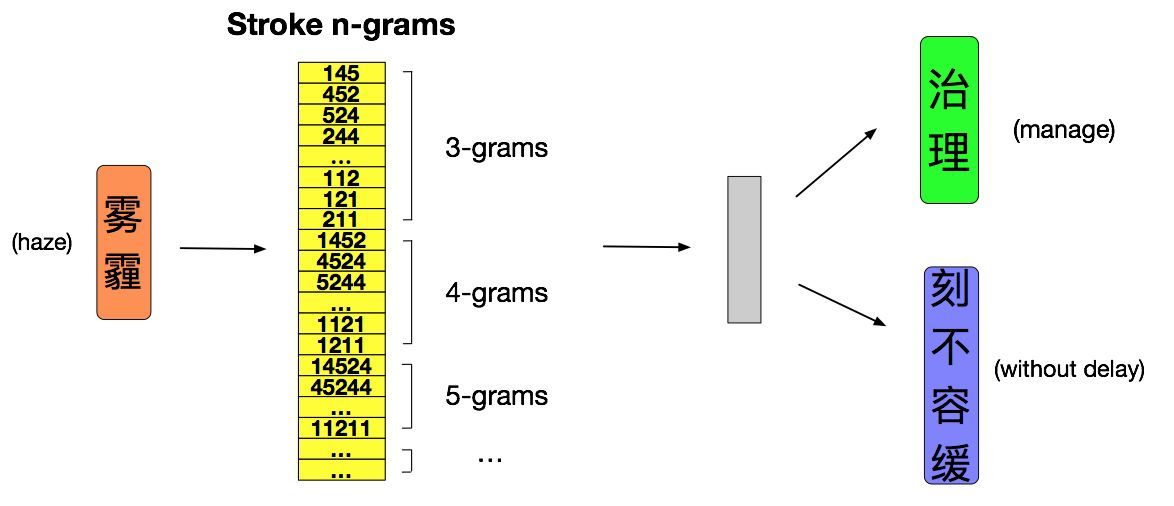
▲圖2 算法過程的舉例
如上圖所示,對於「治理 霧霾 刻不容緩」這句話,假設此刻當前詞語恰好是「霧霾」,上下文詞語是「治理」和「刻不容緩」。首先將當前詞語「霧霾」拆解成n元筆畫並映射成數字編碼,然後劃窗得到所有的n元筆畫,根據設計的損失函數,計算每一個n元筆畫和上下文詞語的相似度,進而根據損失函數求梯度並對上下文詞向量和n元筆畫向量進行更新。
爲了驗證這項研究提出的cw2vec算法的效果,在公開數據集上,與業界最優的幾個詞向量算法做了對比:
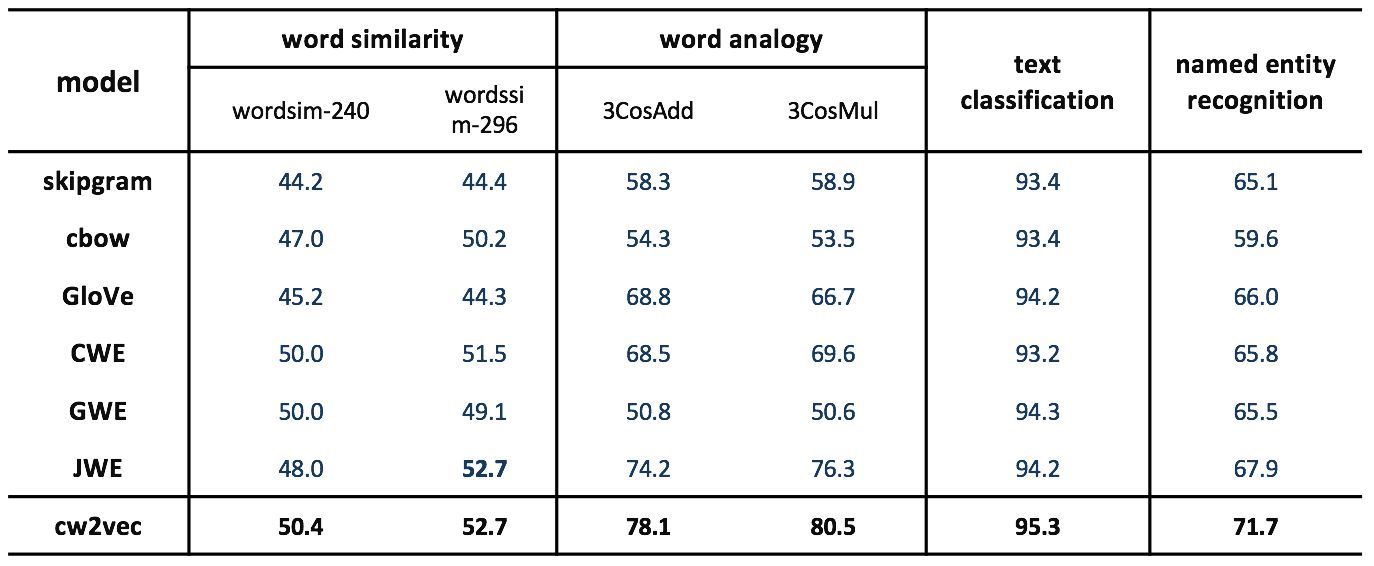
▲圖3 實驗結果
上圖中包括2013年穀歌提出的word2vec的兩個模型skipgram和cbow,2014年斯坦福提出的GloVe算法,2015年清華大學提出的基於漢字的CWE模型,以及2017年最新發表的基於像素和偏旁的中文詞向量算法,可以看出cw2vec在word similarity,word analogy,以及文本分類和命名實體識別的任務中均取得了一致性的提升。同時,這篇文章也展示了不同詞向量維度下的實驗效果:
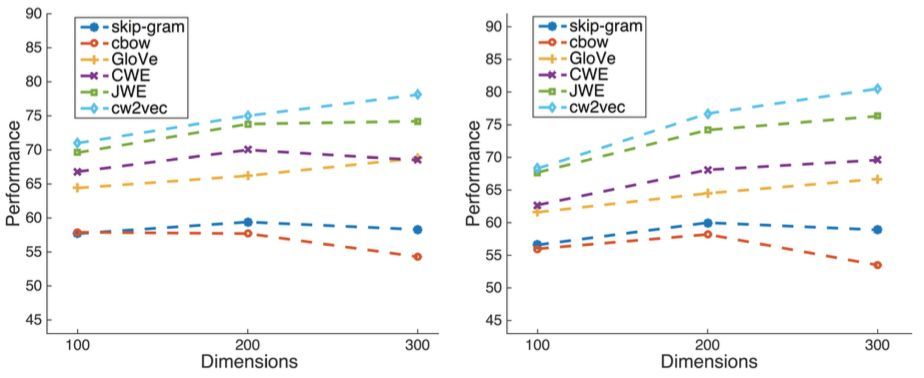
▲圖4 不同詞向量維度下的實驗結果
上圖爲不同維度下在word analogy測試集上的實驗結果,左側爲3cosadd,右側爲3cosmul的測試方法。可以看出這項算法在不同維度的設置下均取得了不錯的效果。此外,也在小規模語料上進行了測試:
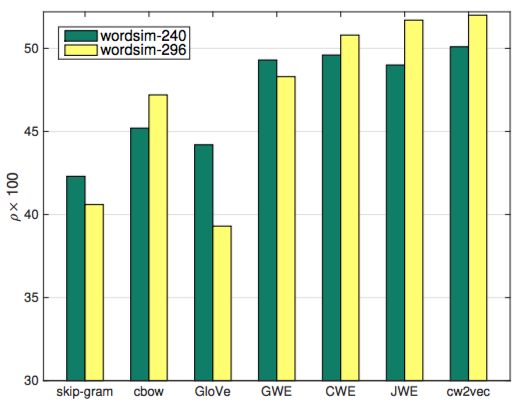
▲圖5 小訓練數據下的實驗結果
上圖是僅選取20%中文維基百科訓練語料,在word similarity下測試的結果,skipgram, cbow和GloVe算法由於沒有利用中文的特性信息進行加強,所以在小語料上表現較差,而其餘四個算法取得了不錯的效果,其中cw2vec的算法在兩個數據集上均取得的了最優效果。
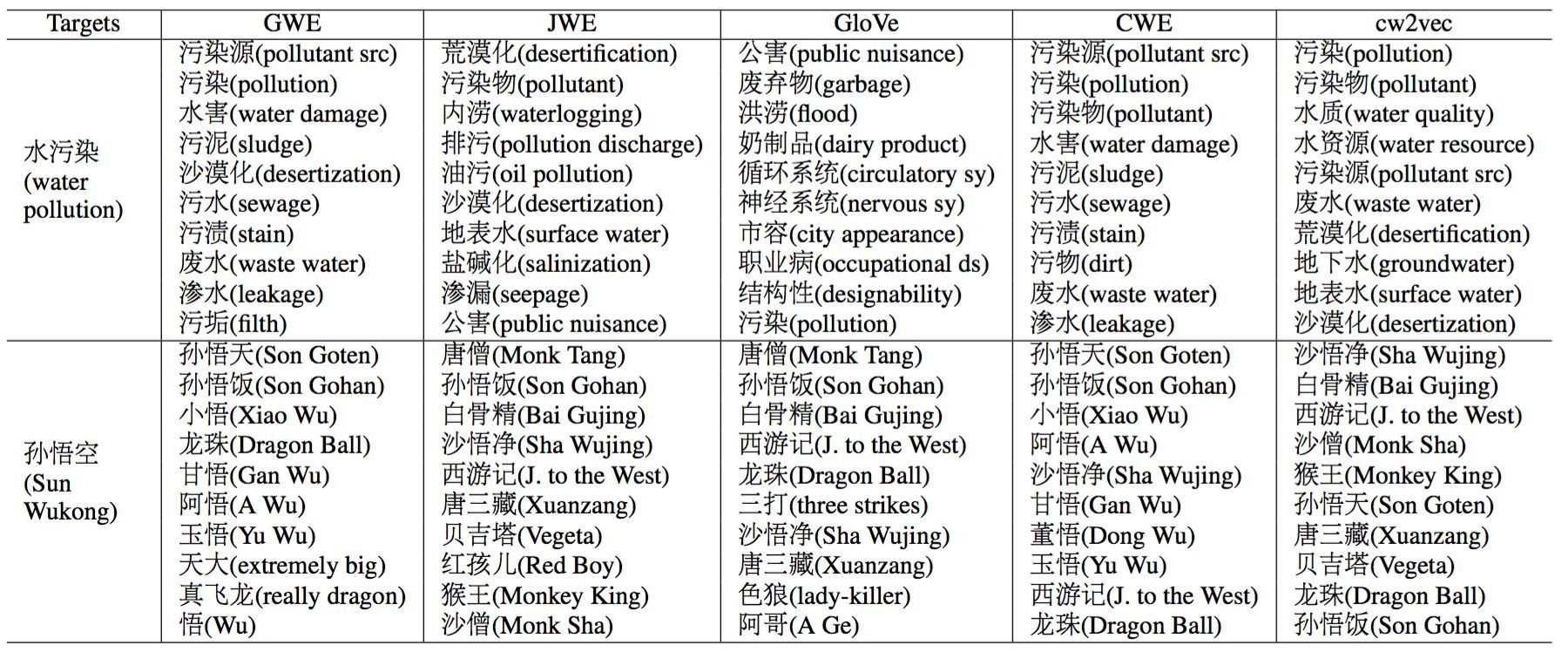
▲圖6 案例分析結果
爲了更好的探究不同算法的實際效果,這項研究專門選取了兩個詞語做案例分析。第一個是環境相關的「水污染」,然後根據詞向量利用向量夾角餘弦找到與其語義最接近的詞語。GWE找到了一些和「污」字相關的詞語,比如「污泥」,「污漬」和「污垢」,而JWE則更加強調後兩個字「污染」GloVe找到了一些奇怪的相近詞語,比如「循環系統」,「神經系統」。CWE找到的相近詞語均包含「水」和「污」這兩個字,猜測是由於其利用漢字信息直接進行詞向量加強的原因。此外,只有cw2vec找到了「水質」這個相關詞語,分析認爲是由於n元筆畫和上下文信息對詞向量共同作用的結果。第二個例子,特別選擇了「孫悟空」這個詞語,該角色出現在中國的名著《西遊記》和知名日本動漫《七龍珠》中,cw2vec找到的均爲相關的角色或著作名稱。
作爲一項基礎研究成果,cw2vec在螞蟻和阿里的諸多場景上也有落地。在智能客服、文本風控和推薦等實際場景中均發揮了作用。此外,不單單是中文詞向量,對於日文、韓文等其他語言也進行類似的嘗試,相關的發明技術專利已經申請近二十項。
我們希望能夠在基礎研究上追趕學術界、有所建樹,更重要的是,在具體的實際場景之中,能夠把人工智能技術真正的賦能到產品裏,爲用戶提供更好的服務。
論文下載鏈接:
https://github.com/ShelsonCao/cw2vec/blob/master/cw2vec.pdf