上週 Geoffrey Hinton 等人公開了那篇備受關注的 NIPS 論文,而後很多研究者與開發者都閱讀了該論文並作出了一定的代碼實現。我們在本文中將詳細解釋該論文提出的結構與過程,並藉助 GitHub 上熱烈討論的項目完成了 CapsNet 的 TensorFlow 實現,並提供了主體架構的代碼註釋。
本文是我們的第三個 GitHub 項目,旨在解釋 CapsNet 的網絡架構與實現。爲了解釋 CapsNet,我們將從卷積層與卷積機制開始,從工程實踐的角度解釋卷積操作的過程與輸出,這對進一步理解 Capsule 層的處理十分有利,後面我們將基於對 Capsule 層的理解解釋 Geoffrey Hinton 等人最近提出來的 CapsNet 架構。最後我們會根據 naturomics 的實現進行測試與解釋。
GitHub 項目地址:https://github.com/jiqizhixin/ML-Tutorial-Experiment
卷積層與卷積機制
這一部分主要是爲不太瞭解卷積機制具體過程的讀者準備,因爲 CapsNet 的前面兩層本質上還是傳統的卷積操作。若讀者已經瞭解基本的卷積操作,那麼可以跳過這一章節直接閱讀 Capsule 層的結構與過程。
若要解釋卷積神經網絡,我們先要知道爲什麼卷積在圖像上能比全連接網絡有更好的性能,以下分別展示了全連接網絡和卷積網絡一般的架構:
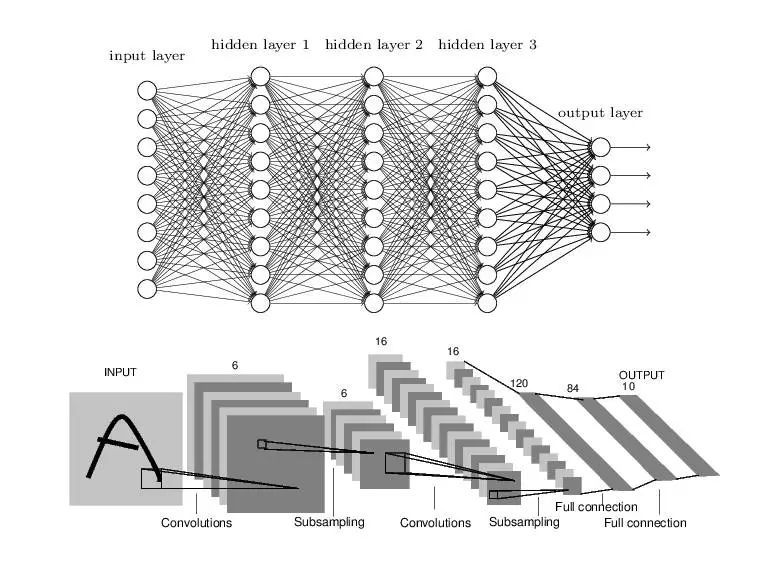
我們知道全連接網絡前一層的每個神經元(或單元)都會與後一層中每個神經元相連,連接的強弱可以通過相對應的權重控制。而所有連接權重就是該全連接神經網絡希望學到的。上圖可知卷積神經網絡也是由一層一層的神經元組織起來的,只不過全連接網絡相鄰兩層的神經元都有連接,所以可以將相同層的神經元排列爲一列,這樣可以方便顯示連接結構。而卷積網絡相連兩層之間只有部分神經元相連,爲了展示每一層神經元的維度,我們一般會將每一個卷積層的結點組織爲一個三維張量。
全連接網絡處理圖像最大的問題是每層之間的參數或權重太多了,主要是因爲兩層間的神經元都有連接。若使用一個隱藏層爲 500 個單元的全連接網絡(784×500×10)識別 MNIST 手寫數字,那麼參數的數量爲 28×28×500+5000+510=397510 個參數,這大大限制了網絡層級的加深。
而對於卷積網絡來說,每一個單元都只會和上一層部分單元相連接。一般每個卷積層的單元都可以組織成一個三維張量,即矩陣沿第三個方向增加一維數據。例如 Cifar-10 數據集的輸入層就可以組織成 32×32×3 的三維張量,其中 32×32 代表圖片的尺寸或像素數量,而 3 代表 RGB 三色通道。
卷積層
卷積層試圖將神經網絡中的每一小塊進行更加深入的分析,從而得出抽象程度更高的特徵。一般來說通過卷積層處理的神經元結點矩陣會變得更深,即神經元的組織在第三個維度上會增加。
下圖展示了卷積核或濾波器(filter)將當前層級上的一個子結點張量轉化爲下一層神經網絡上的一個長和寬都爲 1,深度不限的結點矩陣。下圖輸入是一個 32×32×3 的張量,中間的小長方體爲卷積核,一般可以爲 3×3 或 5×5 等,且因爲要計算乘積,那麼卷積核的第三個維度必須和其處理的圖像深度(即輸入張量第三個維度 3)相等。最右邊的矩形體的深度爲 5,即前面使用了五個卷積核執行卷積操作。這五個卷積核有不同的權重,但每一個卷積層使用一個卷積核的權重是一樣的,所以下圖五層特徵中每一層特徵都是通過一個卷積核得出來的,也就是該層共享了權重。
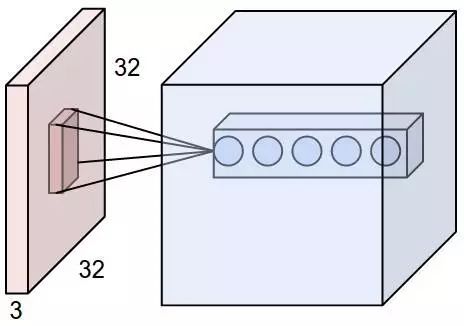
卷積操作
可能入門讀者對卷積的具體過程還是不夠了解,下面我們可以討論卷積操作的具體過程。如下所示,該圖展示了卷積的具體操作過程。首先我們的輸入爲 5×5×3 的張量,即 x[:, :, 0 : 3]。其次我們有兩個 3×3 的卷積核,即 W0 和 W1,第三個維度必須和輸入張量的第三個維度相等,所以一般只用兩個維度描述一個卷積核。最後卷積操作輸出 3×3×2 的張量,其中 o[:, :, 0] 爲第一個卷積核 W0 的卷積輸出,o[:, :, 1] 爲第二個卷積核的輸出。因爲輸入張量使用了 Padding,即每一個通道的輸入圖像周圍加 0,且卷積核移動的步幅爲 2,則每個卷積核輸出的維度爲 3×3(即 (7-3)/2)。
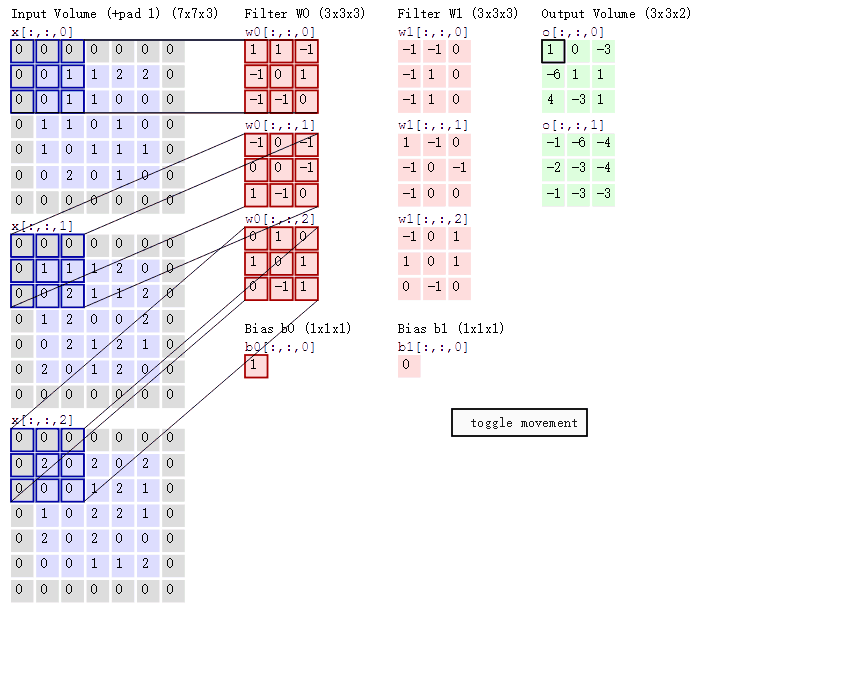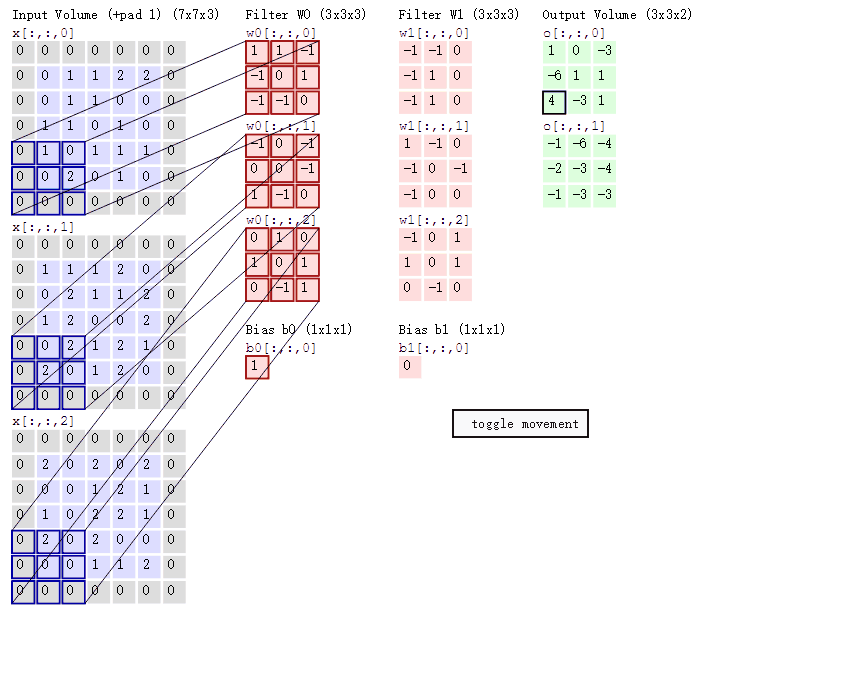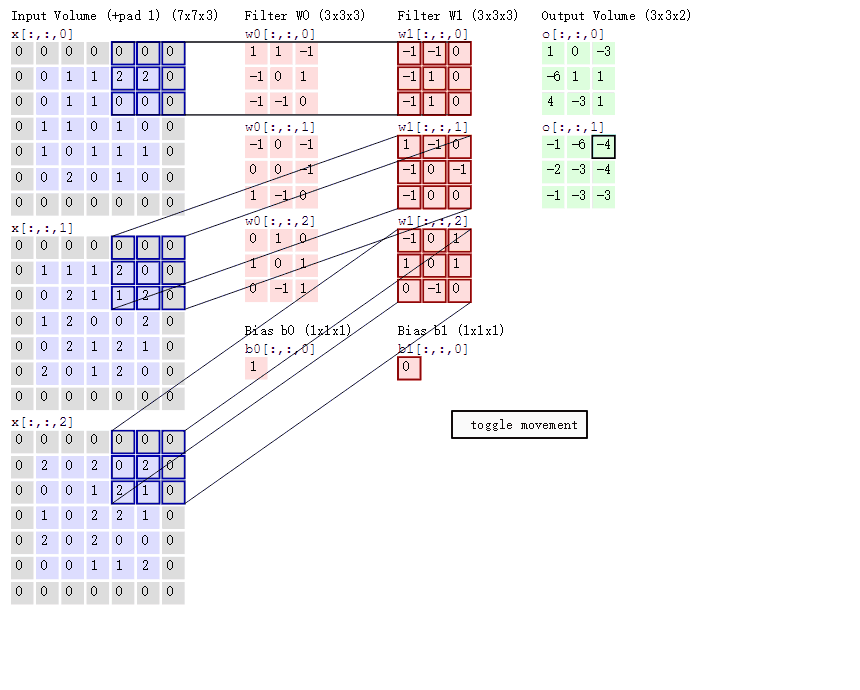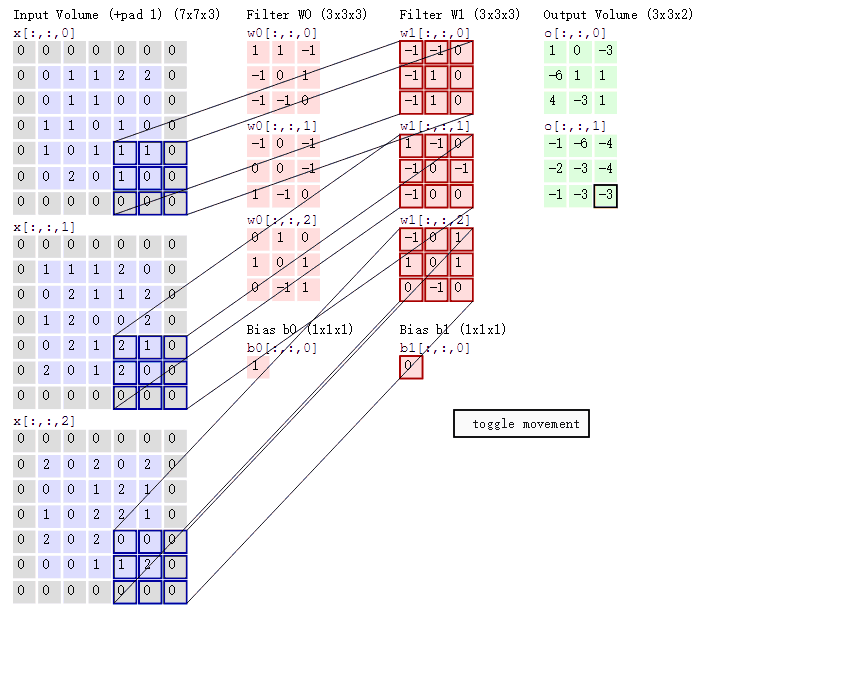
在上圖中,卷積核會與輸入張量對應相乘相加,然後再加上偏置項就等於輸出張量中對應位置的值。例如使用卷積和 W0 對輸入張量(深度爲 3 可看作圖像擁有的 RGB 三個通道)做卷積,卷積和三個層級將對應輸入張量的三個層級做乘積累計。w0[:, :, 0] 乘以 x[:, :, 0] 左上角的九個元素爲 1*0+1*0-1*0-1*0+0*0+1*1-1*0-1*0+0*1=1,同理 w0[:, :, 1] 乘以 x[:, :, 1] 左上角九個元素爲-1、w0[:, :, 2] 乘以 x[:, :, 2] 左上角九個元素爲 0,這三個值相加再加上偏置項 b0 就等於最右邊輸出張量 o[:, :, 0] 的左上角第一個元素,即 1-1+0+1=1。
隨着卷積核移動一個步長,我們可以計算出輸出矩陣移動一個元素的值。注意但卷積核在輸入張量上移動的時候,卷積核權重是相同的,也就是說這一層共享了相同的權重,即 o[:, :, 0] 和 o[:, :, 1] 分別共享了一組權重。這裏之所以強調權重的共享,不僅因爲它是卷積層核心的屬性,同時還有利於我們在後面理解 CapsNet 的 PrimaryCaps 層。
卷積還有很多性質沒有解釋,例如最大池化選取一個濾波器內數值最大的值代表該區域的特徵以減少輸出張量的尺寸,Inception 模塊將多組卷積核並聯地對輸入張量進行處理,然後再將並聯處理得到的多個輸出張量按序串聯地組成一個很深的輸出張量作爲 Inception 模塊的輸出等。讀者也可以繼續閱讀關於卷積的文章進一步瞭解。最後,我們提供了一個簡單的實現展示卷積操作的計算過程:
importtensorflow as tf
importnumpy as np
#輸入張量爲3×3的二維矩陣
M =np.array([
[[1],[-1],[0]],
[[-1],[2],[1]],
[[0],[2],[-2]]
])
#定義卷積核權重和偏置項。由權重可知我們只定義了一個2×2×1的卷積核
filter_weight =tf.get_variable('weights',[2,2,1,1],initializer =tf.constant_initializer([
[1,-1],
[0,2]]))
biases =tf.get_variable('biases',[1],initializer =tf.constant_initializer(1))
#調整輸入格式符合TensorFlow要求
M =np.asarray(M,dtype='float32')
M =M.reshape(1,3,3,1)
#計算輸入張量通過卷積核和池化濾波器計算後的結果
x =tf.placeholder('float32',[1,None,None,1])
#我們使用了帶Padding,步幅爲2的卷積操作,因爲filter_weight的深度確定了卷積核的數量
conv =tf.nn.conv2d(x,filter_weight,strides =[1,2,2,1],padding ='SAME')
bias =tf.nn.bias_add(conv,biases)
#使用帶Padding,步幅爲2的平均池化操作
pool =tf.nn.avg_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
#執行計算圖
withtf.Session()as sess:
tf.global_variables_initializer().run()
convoluted_M =sess.run(bias,feed_dict={x:M})
pooled_M =sess.run(pool,feed_dict={x:M})
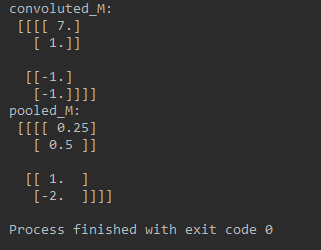
print ("convoluted_M: n",convoluted_M)
print ("pooled_M: n",pooled_M)
這一段代碼執行了卷積操作和平均池化,它的輸出如下:
Capsule 層與動態路由
這一部分主要是解釋 Capsule 層與動態路由(DynamicRouting)機制的大概原理,這一部分基於我們對 Hinton 原論文的理解完成,並採用了知乎 SIY.Z、Debarko De 等人的觀點。文末將給出更多的參考資料,讀者可進一步閱讀以瞭解更多。
前面我們已經知道卷積通過權重共享和局部連接可以減少很多參數,此外共享卷積核權重可以使圖像上的內容不受位置的影響。例如 Cifar-10 中的圖像爲 32×32×3,而由 16 個尺寸爲 5×5 的卷積核(或表述深度爲 16)所構成的卷積層,其參數共有 5*5*3*16+16=1216 個。但這這樣的卷積層單元還是太簡單了,它們也不能表徵複雜的概念。
例如當圖像進行一些旋轉、變形或朝向不同的方向,那麼 CNN 本身是無法處理這些圖片的。當然這個問題可以在訓練中添加相同圖像的不同變形而得到解決。在 CNN 中每一層都以非常細微的方式理解圖像,因爲我們卷積核的感受野一般使用 3×3 或 5×5 等像素級的操作來理解圖像,所以卷積層總是嘗試理解局部的特徵與信息。而當我們由前面低級特徵組合成後面複雜與抽象的特徵時,我們很可能需要使用池化操作來減少輸出張量或特徵圖的尺寸,而這種操作實際上會丟失一些信息,比如說位置信息。
而等變映射(Equivariance)可以幫助 CNN 理解旋轉或比例等屬性變換,並相應地調整自己,這樣圖像空間中的位置等屬性信息就不會丟失。而 Geoffrey Hinton 等人提出的 CapsNet 使用向量代替標量點,因此能獲取更多的信息。此外,我們感覺 Capsule 使用向量作爲輸入與輸出是這篇論文的亮點。
Capsule 層
在論文中,Geoffrey Hinton 介紹 Capsule 爲:「Capsule 是一組神經元,其輸入輸出向量表示特定實體類型的實例化參數(即特定物體、概念實體等出現的概率與某些屬性)。我們使用輸入輸出向量的長度表徵實體存在的概率,向量的方向表示實例化參數(即實體的某些圖形屬性)。同一層級的 capsule 通過變換矩陣對更高級別的 capsule 的實例化參數進行預測。當多個預測一致時(本論文使用動態路由使預測一致),更高級別的 capsule 將變得活躍。」
Capsule 中的神經元的激活情況表示了圖像中存在的特定實體的各種性質。這些性質可以包含很多種不同的參數,例如姿勢(位置,大小,方向)、變形、速度、反射率,色彩、紋理等等。而輸入輸出向量的長度表示了某個實體出現的概率,所以它的值必須在 0 到 1 之間。
爲了實現這種壓縮,並完成 Capsule 層級的激活功能,Hinton 等人使用了一個被稱爲「squashing」的非線性函數。該非線性函數確保短向量的長度能夠縮短到幾乎等於零,而長向量的長度壓縮到接近但不超過 1 的情況。以下是該非線性函數的表達式:

其中 v_j 爲 Capsule j 的輸出向量,s_j 爲上一層所有 Capsule 輸出到當前層 Capsule j 的向量加權和,簡單說 s_j 就爲 Capsule j 的輸入向量。該非線性函數可以分爲兩部分,即
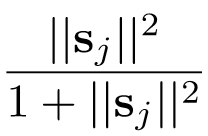
和
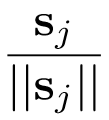
,前一部分是輸入向量 s_j 的縮放尺度,第二部分是輸入向量 s_j 的單位向量,該非線性函數既保留了輸入向量的方向,又將輸入向量的長度壓縮到區間 [0,1) 內。s_j 向量爲零向量時 v_j 能取到 0,而 s_j 無窮大時 v_j 無限逼近 1。該非線性函數可以看作是對向量長度的一種壓縮和重分配,因此也可以看作是一種輸入向量後「激活」輸出向量的方式。
那麼如上所述,Capsule 的輸入向量就相當於經典神經網絡神經元的標量輸入,而該向量的計算就相當於兩層 Capsule 間的傳播與連接方式。輸入向量的計算分爲兩個階段,即線性組合和 Routing,這一過程可以用以下公式表示:
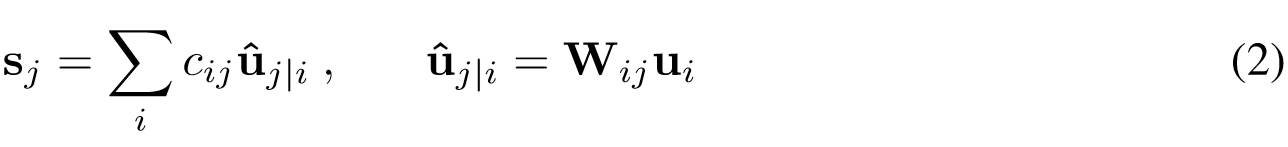
其中 u_j|i hat 爲 u_i 的線性組合,這一點可以看作是一般全連接網絡前一層神經元以不同強弱的連接輸出到後一層某個神經元。只不過 Capsule 相對於一般神經網絡每個結點都有一組神經元(以生成向量),即 u_j|i hat 表示上一層第 i 個 Capsule 的輸出向量和對應的權重向量相乘(W_ij 表示向量而不是元素)而得出的預測向量。u_j|i hat 也可以理解爲在前一層爲第 i 個 Capsule 的情況下連接到後一層第 j 個 Capsule 的強度。
在確定 u_j|i hat 後,我們需要使用 Routing 進行第二個階段的分配以計算輸出結點 s_j,這一過程就涉及到使用動態路由(dynamic routing)迭代地更新 c_ij。通過 Routing 就能獲取下一層 Capsule 的輸入 s_j,然後將 s_j 投入「Squashing」非線性函數後就能得出下一層 Capsule 的輸出。後面我們會重點解釋 Routing 算法,但整個 Capsule 層及它們間傳播的過程已經完成了。
所以整個層級間的傳播與分配可以分爲兩個部分,第一部分是下圖 u_i 與 u_j|i hat 間的線性組合,第二部分是 u_j|i hat 與 s_j 之間的 Routing 過程。若讀者對傳播過程仍然不是太明晰,那麼可以看以下兩層 Capsule 單元間的傳播過程,該圖是根據我們對傳播過程的理解而繪製的:
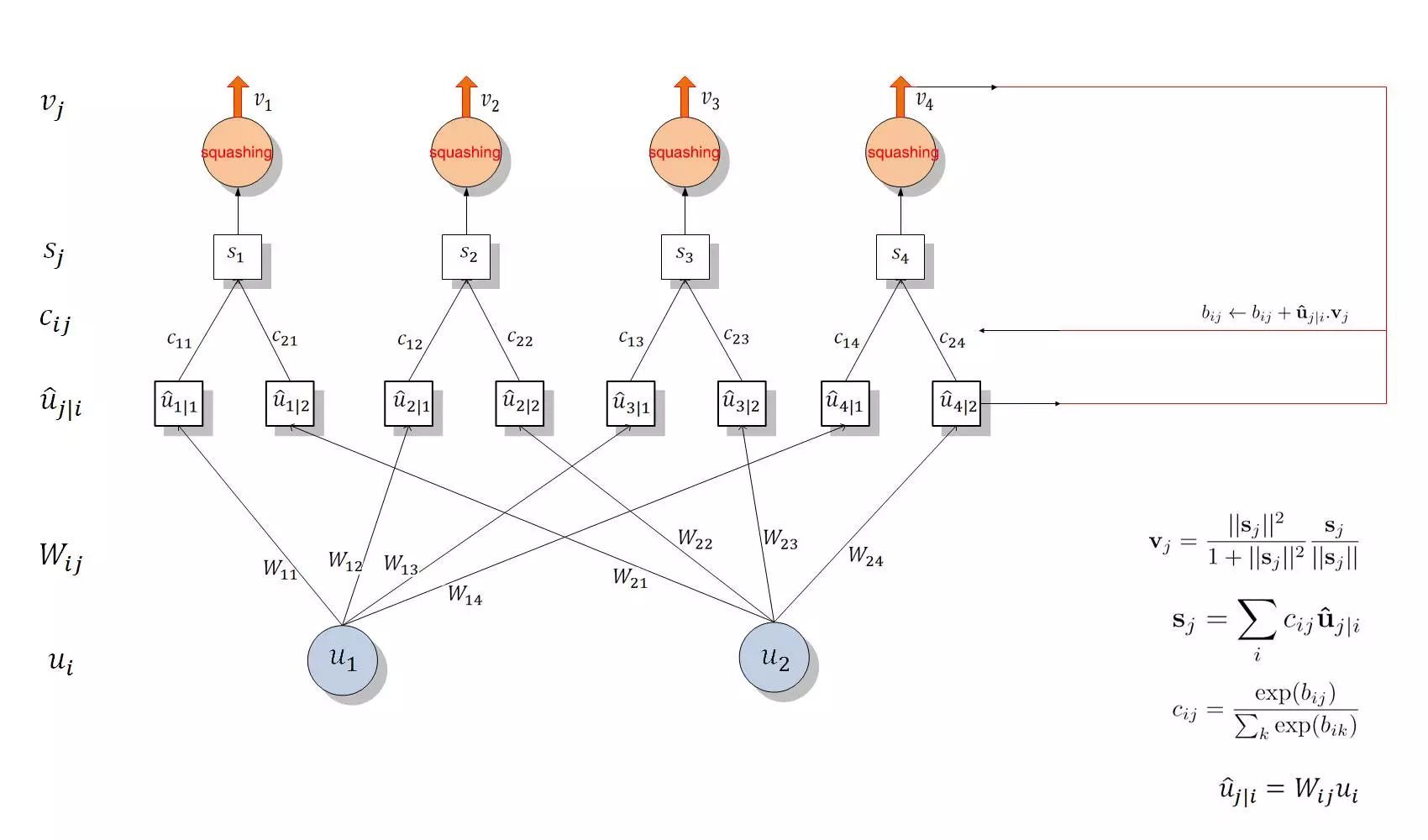
Capsule 層級結構圖
如上所示,該圖展示了 Capsule 的層級結構與動態 Routing 的過程。最下面的層級 u_i 共有兩個 Capsule 單元,該層級傳遞到下一層級 v_j 共有四個 Capsule。u_1 和 u_2 是一個向量,即含有一組神經元的 Capsule 單元,它們分別與不同的權重 W_ij(同樣是向量)相乘得出 u_j|i hat。例如 u_1 與 W_12 相乘得出預測向量 u_2|1 hat。隨後該預測向量和對應的「耦合係數」c_ij 相乘並傳入特定的後一層 Capsule 單元。不同 Capsule 單元的輸入 s_j 是所有可能傳入該單元的加權和,即所有可能傳入的預測向量與耦合係數的乘積和。隨後我們就得到了不同的輸入向量 s_j,將該輸入向量投入到「squashing」非線性函數就能得出後一層 Capsule 單元的輸出向量 v_j。然後我們可以利用該輸出向量 v_j 和對應預測向量 u_j|i hat 的乘積更新耦合係數 c_ij,這樣的迭代更新不需要應用反向傳播。
Dynamic Routing 算法
因爲按照 Hinton 的思想,找到最好的處理路徑就等價於正確處理了圖像,所以在 Capsule 中加入 Routing 機制可以找到一組係數 c_ij,它們能令預測向量 u_j|i hat 最符合輸出向量 v_j,即最符合輸出的輸入向量,這樣我們就找到了最好的路徑。
按照原論文所述,c_ij 爲耦合係數(coupling coefficients),該係數由動態 Routing 過程迭代地更新與確定。Capsule i 和後一層級所有 Capsule 間的耦合係數和爲 1,即圖四 c_11+c_12+c_13+c_14=1。此外,該耦合係數由「routing softmax」決定,且 softmax 函數中的 logits b_ij 初始化爲 0,耦合係數 c_ij 的 softmax 計算方式爲:

b_ij 依賴於兩個 Capsule 的位置與類型,但不依賴於當前的輸入圖像。我們可以通過測量後面層級中每一個 Capsule j 的當前輸出 v_j 和 前面層級 Capsule i 的預測向量間的一致性,然後藉助該測量的一致性迭代地更新耦合係數。本論文簡單地通過內積度量這種一致性,即 ,這一部分也就涉及到使用 Routing 更新耦合係數。
Routing 過程就是上圖 4 右邊表述的更新過程,我們會計算 v_j 與 u_j|i hat 的乘積並將它與原來的 b_ij 相加而更新 b_ij,然後利用 softmax(b_ij) 更新 c_ij 而進一步修正了後一層的 Capsule 輸入 s_j。當輸出新的 v_j 後又可以迭代地更新 c_ij,這樣我們不需要反向傳播而直接通過計算輸入與輸出的一致性更新參數。
該 Routing 算法更具體的更新過程可以查看以下僞代碼:

對於所有在 l 層的 Capsule i 和在 l+1 層的 Capsule j,先初始化 b_ij 等於零。然後迭代 r 次,每次先根據 b_i 計算 c_i,然後在利用 c_ij 與 u_j|i hat 計算 s_j 與 v_j。利用計算出來的 v_j 更新 b_ij 以進入下一個迭代循環更新 c_ij。該 Routing 算法十分容易收斂,基本上通過 3 次迭代就能有不錯的效果。
CapsNet 架構
Hinton 等人實現了一個簡單的 CapsNet 架構,該架構由兩個卷積層和一個全連接層組成,其中第一個爲一般的卷積層,第二個卷積相當於爲 Capsule 層做準備,並且該層的輸出爲向量,所以它的維度要比一般的卷積層再高一個維度。最後就是通過向量的輸入與 Routing 過程等構建出 10 個 v_j 向量,每一個向量的長度都直接表示某個類別的概率。
以下是 CapsNet 的整體架構:
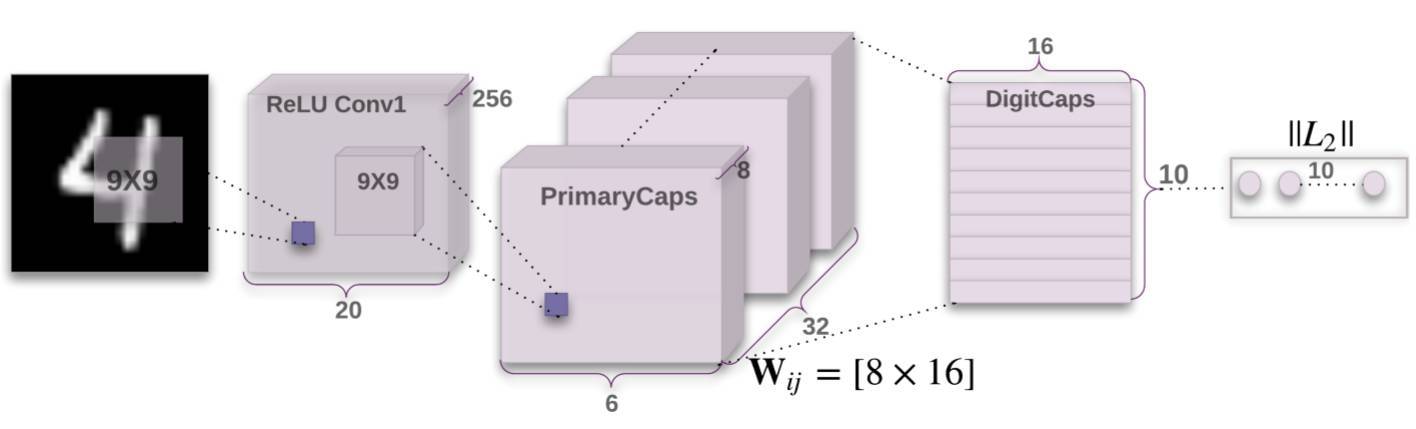
第一個卷積層使用了 256 個 9×9 卷積核,步幅爲 1,且使用了 ReLU 激活函數。該卷積操作應該沒有使用 Padding,輸出的張量才能是 20×20×256。此外,CapsNet 的卷積核感受野使用的是 9×9,相比於其它 3×3 或 5×5 的要大一些,這個能是因爲較大的感受野在 CNN 層次較少的情況下能感受的信息越多。這兩層間的權值數量應該爲 9×9×256+256=20992。
隨後,第二個卷積層開始作爲 Capsule 層的輸入而構建相應的張量結構。我們可以從上圖看出第二層卷積操作後生成的張量維度爲 6×6×8×32,那麼我們該如何理解這個張量呢?雲夢居客在知乎上給出了一個十分形象且有意思的解釋,如前面章節所述,如果我們先考慮 32 個(32 channel)9×9 的卷積核在步幅爲 2 的情況下做卷積,那麼實際上得到的是傳統的 6×6×32 的張量,即等價於 6×6×1×32。
因爲傳統卷積操作每次計算的輸出都是一個標量,而 PrimaryCaps 的輸出需要是一個長度爲 8 的向量,因此傳統卷積下的三維輸出張量 6×6×1×32 就需要變化爲四維輸出張量 6×6×8×32。如下所示,其實我們可以將第二個卷積層看作對維度爲 20×20×256 的輸入張量執行 8 次不同權重的 Conv2d 操作,每次 Conv2d 都執行帶 32 個 9×9 卷積核、步幅爲 2 的卷積操作。
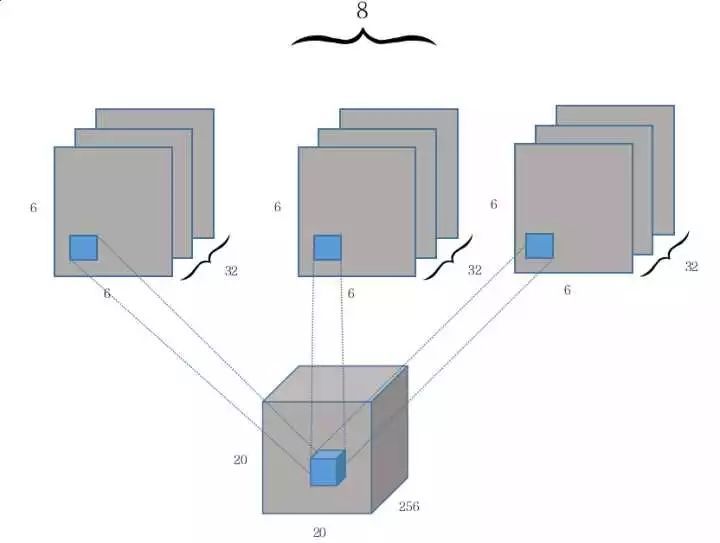
由於每次卷積操作都會產生一個 6×6×1×32 的張量,一共會產生 8 個類似的張量,那麼將這 8 個張量(即 Capsule 輸入向量的 8 個分量)在第三個維度上合併在一起就成了 6×6×8×32。從上可知 PrimaryCaps 就相當於一個深度爲 32 的普通卷積層,只不過每一層由以前的標量值變成了長度爲 8 的向量。
此外,結合 Hinton 等人給出的 Capsule 定義,它就相當於一組常見的神經元,這些神經元封裝在一起形成了新的單元。在本論文討論的 CapsNet 架構中,我們將 8 個卷積單元封裝在一起成爲了一個新的 Caosule 單元。PrimaryCaps 層的卷積計算都沒有使用 ReLU 等激活函數,它們以向量的方式預備輸入到下一層 Capsule 單元中。
PrimaryCaps 每一個向量的分量層級是共享卷積權重的,即獲取 6×6 張量的卷積核權重爲相同的 9×9 個。這樣該卷積層的參數數量爲 9×9×256×8×32+8×32=5308672,其中第二部分 8×32 爲偏置項參數數量。
第三層 DigitCaps 在第二層輸出的向量基礎上進行傳播與 Routing 更新。第二層共輸出 6×6×32=1152 個向量,每一個向量的維度爲 8,即第 i 層共有 1152 個 Capsule 單元。而第三層 j 有 10 個標準的 Capsule 單元,每個 Capsule 的輸出向量有 16 個元素。前一層的 Capsule 單元數是 1152 個,那麼 w_ij 將有 1152×10 個,且每一個 w_ij 的維度爲 8×16。當 u_i 與對應的 w_ij 相乘得到預測向量後,我們會有 1152×10 個耦合係數 c_ij,對應加權求和後會得到 10 個 16×1 的輸入向量。將該輸入向量輸入到「squashing」非線性函數中求得最終的輸出向量 v_j,其中 v_j 的長度就表示識別爲某個類別的概率。
DigitCaps 層與 PrimaryCaps 層之間的參數包含兩類,即 W_ij 和 c_ij。所有 W_ij 的參數數量應該是 6×6×32×10×8×16=1474560,c_ij 的參數數量爲 6×6×32×10×16=184320,此外還應該有 2×1152×10=23040 個偏置項參數,不過原論文並沒有明確指出這些偏置項。最後小編計算出該三層 CapsNet 一共有 5537024 個參數,這並不包括後面的全連接重構網絡參數。(算錯了不要怪小編呦~)
損失函數與最優化
前面我們已經瞭解 DigitCaps 層輸出向量的長度即某個類別的概率,那麼我們該如何構建損失函數,並根據該損失函數迭代地更新整個網絡?前面我們耦合係數 c_ij 是通過一致性 Routing 進行更新的,他並不需要根據損失函數更新,但整個網絡其它的卷積參數和 Capsule 內的 W_ij 都需要根據損失函數進行更新。一般我們就可以對損失函數直接使用標準的反向傳播更新這些參數,而在原論文中,作者採用了 SVM 中常用的 Margin loss,該損失函數的表達式爲:
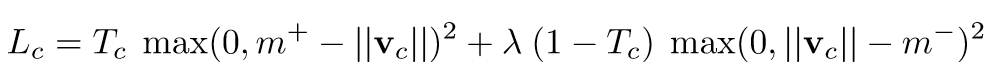
其中 c 是分類類別,T_c 爲分類的指示函數(c 存在爲 1,c 不存在爲 0),m+ 爲上邊界,m- 爲下邊界。此外,v_c 的模即向量的 L2 距離。
因爲實例化向量的長度來表示 Capsule 要表徵的實體是否存在,所以當且僅當圖片裏出現屬於類別 k 的手寫數字時,我們希望類別 k 的最頂層 Capsule 的輸出向量長度很大(在本論文 CapsNet 中爲 DigitCaps 層的輸出)。爲了允許一張圖裏有多個數字,我們對每一個表徵數字 k 的 Capsule 分別給出單獨的 Margin loss。
構建完損失函數,我們就能愉快地使用反向傳播了。
重構與表徵
重構即我們希望利用預測的類別重新構建出該類別代表的實際圖像,例如我們前面部分的模型預測出該圖片屬於一個類別,然後後面重構網絡會將該預測的類別信息重新構建成一張圖片。
前面我們假設過 Capsule 的向量可以表徵一個實例,那麼如果我們將一個向量投入到後面的重構網絡中,它應該能重構出一個完整的圖像。因此,Hinton 等人使用額外的重構損失(reconstruction loss)來促進 DigitCaps 層對輸入數字圖片進行編碼。下圖展示了整個重構網絡的的架構:
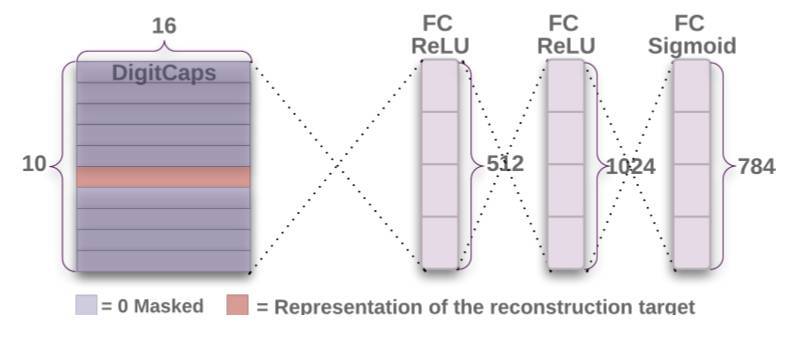
我們在訓練期間,除了特定的 Capsule 輸出向量,我們需要矇住其它所有的輸出向量。然後,使用該輸出向量重構手寫數字圖像。DigitCaps 層的輸出向量被饋送至包含 3 個全連接層的解碼器中,並以上圖所示的方式構建。這一過程的損失函數通過計算 FC Sigmoid 層的輸出像素點與原始圖像像素點間的歐幾里德距離而構建。Hinton 等人還按 0.0005 的比例縮小重構損失,以使它不會主導訓練過程中的 Margin loss。
Capsule 輸出向量的重構與表徵除了能提升模型的準確度以外,還能提升模型的可解釋性,因爲我們能修正需要重構向量中的某個或某些分量而觀察重構後的圖像變化情況,這有助於我們理解 Capsule 層的輸出結果。
以上就是本論文構建的 CapsNet 架構,當然 Hinton 還描述了很多試驗結果與發現,感興趣的讀者可以查閱論文的後一部分。
CapsNet 的 TensorFlow 實現
以下定義構建 CapsNet 後面兩層的方法。在 CapsNet 架構中,我們能訪問該類中的對象和方法構建 PrimaryCaps 層和 DigitCaps 層。
#通過定義類和對象的方式定義Capssule層級
classCapsLayer(object):
''' Capsule layer 類別參數有:
Args:
input: 一個4維張量
num_outputs: 當前層的Capsule單元數量
vec_len: 一個Capsule輸出向量的長度
layer_type: 選擇'FC' 或 "CONV", 以確定是用全連接層還是卷積層
with_routing: 當前Capsule是否從較低層級中Routing而得出輸出向量
Returns:
一個四維張量
'''
def__init__(self,num_outputs,vec_len,with_routing=True,layer_type='FC'):
self.num_outputs =num_outputs
self.vec_len =vec_len
self.with_routing =with_routing
self.layer_type =layer_type
def__call__(self,input,kernel_size=None,stride=None):
'''
當「Layer_type」選擇的是「CONV」,我們將使用 'kernel_size' 和 'stride'
'''
# 開始構建卷積層
ifself.layer_type =='CONV':
self.kernel_size =kernel_size
self.stride =stride
# PrimaryCaps層沒有Routing過程
ifnotself.with_routing:
# 卷積層爲 PrimaryCaps 層(CapsNet第二層), 並將第一層卷積的輸出張量作爲輸入。
# 輸入張量的維度爲: [batch_size, 20, 20, 256]
assertinput.get_shape()==[batch_size,20,20,256]
#從CapsNet輸出向量的每一個分量開始執行卷積,每個分量上執行帶32個卷積核的9×9標準卷積
capsules =[]
fori inrange(self.vec_len):
# 所有Capsule的一個分量,其維度爲: [batch_size, 6, 6, 32],即6×6×1×32
withtf.variable_scope('ConvUnit_'+str(i)):
caps_i =tf.contrib.layers.conv2d(input,self.num_outputs,
self.kernel_size,self.stride,
padding="VALID")
# 將一般卷積的結果張量拉平,併爲添加到列表中
caps_i =tf.reshape(caps_i,shape=(batch_size,-1,1,1))
capsules.append(caps_i)
# 爲將卷積後張量各個分量合併爲向量做準備
assertcapsules[0].get_shape()==[batch_size,1152,1,1]
# 合併爲PrimaryCaps的輸出張量,即6×6×32個長度爲8的向量,合併後的維度爲 [batch_size, 1152, 8, 1]
capsules =tf.concat(capsules,axis=2)
# 將每個Capsule 向量投入非線性函數squash進行縮放與激活
capsules =squash(capsules)
assertcapsules.get_shape()==[batch_size,1152,8,1]
return(capsules)
ifself.layer_type =='FC':
# DigitCaps 帶有Routing過程
ifself.with_routing:
# CapsNet 的第三層 DigitCaps 層是一個全連接網絡
# 將輸入張量重建爲 [batch_size, 1152, 1, 8, 1]
self.input =tf.reshape(input,shape=(batch_size,-1,1,input.shape[-2].value,1))
withtf.variable_scope('routing'):
# 初始化b_IJ的值爲零,且維度滿足: [1, 1, num_caps_l, num_caps_l_plus_1, 1]
b_IJ =tf.constant(np.zeros([1,input.shape[1].value,self.num_outputs,1,1],dtype=np.float32))
# 使用定義的Routing過程計算權值更新與s_j
capsules =routing(self.input,b_IJ)
#將s_j投入 squeeze 函數以得出 DigitCaps 層的輸出向量
capsules =tf.squeeze(capsules,axis=1)
return(capsules)
下面是整個 CapsNet 的架構與推斷過程代碼,我們需要從 MNIST 抽出圖像並投入到以下定義的方法中,該批量的圖像將先通過三層 CapsNet 網絡輸出 10 個類別向量,每個向量有 16 個元素,且每個類別向量的長度爲輸出圖像是該類別的概率。隨後,我們會將一個向量投入到重構網絡中構建出該向量所代表的圖像。
# 以下定義整個 CapsNet 的架構與正向傳播過程
classCapsNet():
def__init__(self,is_training=True):
self.graph =tf.Graph()
withself.graph.as_default():
ifis_training:
# 獲取一個批量的訓練數據
self.X,self.Y =get_batch_data()
self.build_arch()
self.loss()
# t_vars = tf.trainable_variables()
self.optimizer =tf.train.AdamOptimizer()
self.global_step =tf.Variable(0,name='global_step',trainable=False)
self.train_op =self.optimizer.minimize(self.total_loss,global_step=self.global_step)# var_list=t_vars)
else:
self.X =tf.placeholder(tf.float32,
shape=(batch_size,28,28,1))
self.build_arch()
tf.logging.info('Seting up the main structure')
# CapsNet 類中的build_arch方法能構建整個網絡的架構
defbuild_arch(self):
# 以下構建第一個常規卷積層
withtf.variable_scope('Conv1_layer'):
# 第一個卷積層的輸出張量爲: [batch_size, 20, 20, 256]
# 以下卷積輸入圖像X,採用256個9×9的卷積核,步幅爲1,且不使用
conv1 =tf.contrib.layers.conv2d(self.X,num_outputs=256,
kernel_size=9,stride=1,
padding='VALID')
assertconv1.get_shape()==[batch_size,20,20,256]
# 以下是原論文中PrimaryCaps層的構建過程,該層的輸出維度爲 [batch_size, 1152, 8, 1]
withtf.variable_scope('PrimaryCaps_layer'):
# 調用前面定義的CapLayer函數構建第二個卷積層,該過程相當於執行八次常規卷積,
# 然後將各對應位置的元素組合成一個長度爲8的向量,這八次常規卷積都是採用32個9×9的卷積核、步幅爲2
primaryCaps =CapsLayer(num_outputs=32,vec_len=8,with_routing=False,layer_type='CONV')
caps1 =primaryCaps(conv1,kernel_size=9,stride=2)
assertcaps1.get_shape()==[batch_size,1152,8,1]
# 以下構建 DigitCaps 層, 該層返回的張量維度爲 [batch_size, 10, 16, 1]
withtf.variable_scope('DigitCaps_layer'):
# DigitCaps是最後一層,它返回對應10個類別的向量(每個有16個元素),該層的構建帶有Routing過程
digitCaps =CapsLayer(num_outputs=10,vec_len=16,with_routing=True,layer_type='FC')
self.caps2 =digitCaps(caps1)
# 以下構建論文圖2中的解碼結構,即由16維向量重構出對應類別的整個圖像
# 除了特定的 Capsule 輸出向量,我們需要矇住其它所有的輸出向量
withtf.variable_scope('Masking'):
#mask_with_y是否用真實標籤矇住目標Capsule
mask_with_y=True
ifmask_with_y:
self.masked_v =tf.matmul(tf.squeeze(self.caps2),tf.reshape(self.Y,(-1,10,1)),transpose_a=True)
self.v_length =tf.sqrt(tf.reduce_sum(tf.square(self.caps2),axis=2,keep_dims=True)+epsilon)
# 通過3個全連接層重構MNIST圖像,這三個全連接層的神經元數分別爲512、1024、784
# [batch_size, 1, 16, 1] => [batch_size, 16] => [batch_size, 512]
withtf.variable_scope('Decoder'):
vector_j =tf.reshape(self.masked_v,shape=(batch_size,-1))
fc1 =tf.contrib.layers.fully_connected(vector_j,num_outputs=512)
assertfc1.get_shape()==[batch_size,512]
fc2 =tf.contrib.layers.fully_connected(fc1,num_outputs=1024)
assertfc2.get_shape()==[batch_size,1024]
self.decoded =tf.contrib.layers.fully_connected(fc2,num_outputs=784,activation_fn=tf.sigmoid)
# 定義 CapsNet 的損失函數,損失函數一共分爲衡量 CapsNet準確度的Margin loss
# 和衡量重構圖像準確度的 Reconstruction loss
defloss(self):
# 以下先定義重構損失,因爲DigitCaps的輸出向量長度就爲某類別的概率,因此可以藉助計算向量長度計算損失
# [batch_size, 10, 1, 1]
# max_l = max(0, m_plus-||v_c||)^2
max_l =tf.square(tf.maximum(0.,m_plus -self.v_length))
# max_r = max(0, ||v_c||-m_minus)^2
max_r =tf.square(tf.maximum(0.,self.v_length -m_minus))
assertmax_l.get_shape()==[batch_size,10,1,1]
# 將當前的維度[batch_size, 10, 1, 1] 轉換爲10個數字類別的one-hot編碼 [batch_size, 10]
max_l =tf.reshape(max_l,shape=(batch_size,-1))
max_r =tf.reshape(max_r,shape=(batch_size,-1))
# 計算 T_c: [batch_size, 10],其爲分類的指示函數
# 若令T_c = Y,那麼對應元素相乘就是有類別相同纔會有非零輸出值,T_c 和 Y 都爲One-hot編碼
T_c =self.Y
# [batch_size, 10], 對應元素相乘並構建最後的Margin loss 函數
L_c =T_c *max_l +lambda_val *(1-T_c)*max_r
self.margin_loss =tf.reduce_mean(tf.reduce_sum(L_c,axis=1))
# 以下構建reconstruction loss函數
# 這一過程的損失函數通過計算FC Sigmoid層的輸出像素點與原始圖像像素點間的歐幾里德距離而構建
orgin =tf.reshape(self.X,shape=(batch_size,-1))
squared =tf.square(self.decoded -orgin)
self.reconstruction_err =tf.reduce_mean(squared)
# 構建總損失函數,Hinton論文將reconstruction loss乘上0.0005
# 以使它不會主導訓練過程中的Margin loss
self.total_loss =self.margin_loss +0.0005*self.reconstruction_err
# 以下輸出TensorBoard
tf.summary.scalar('margin_loss',self.margin_loss)
tf.summary.scalar('reconstruction_loss',self.reconstruction_err)
tf.summary.scalar('total_loss',self.total_loss)
recon_img =tf.reshape(self.decoded,shape=(batch_size,28,28,1))
tf.summary.image('reconstruction_img',recon_img)
self.merged_sum =tf.summary.merge_all()
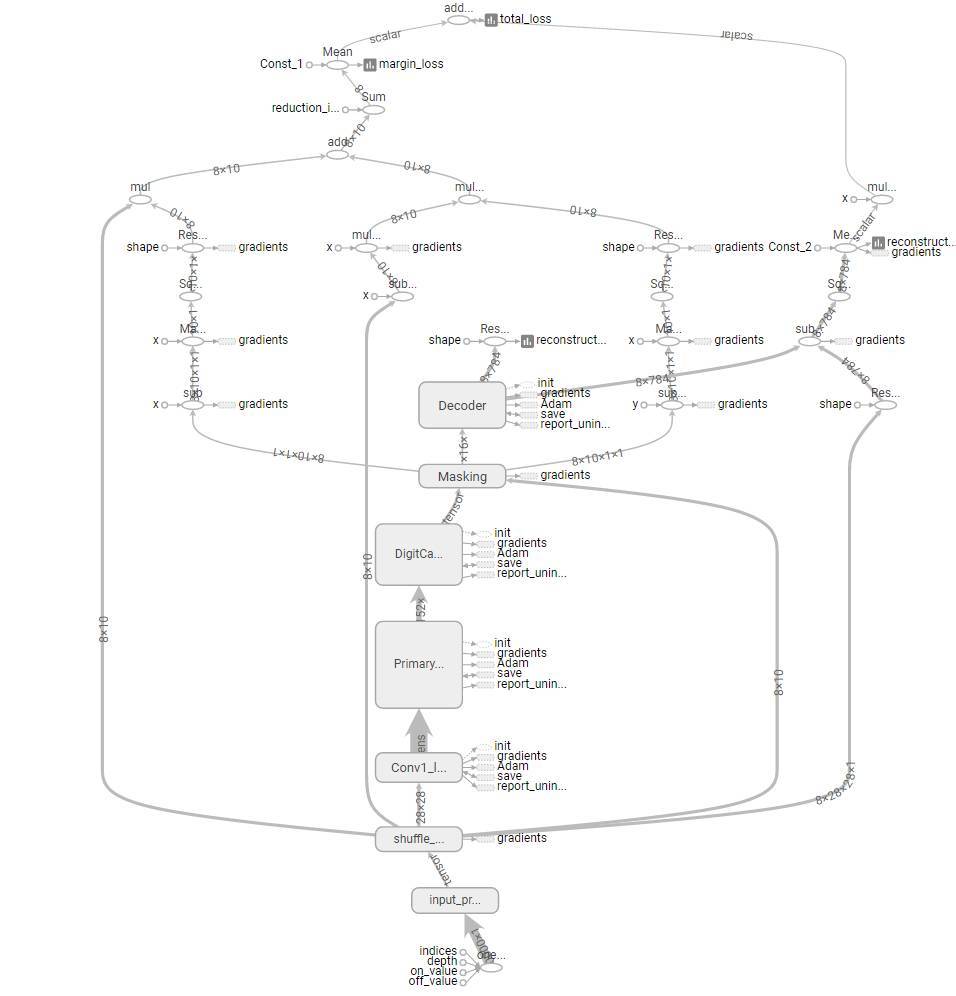
以上是該網絡的主體代碼,更多代碼請查看 naturomics 的 GitHub 地址,或我們的 GitHub 地址,我們上傳的是帶註釋的代碼,希望能幫助初學者更加理解 CapsNet 的過程與架構。以下是上面我們定義 CapsNet 的主體計算圖,即 TensorFlow 中的靜態計算圖:
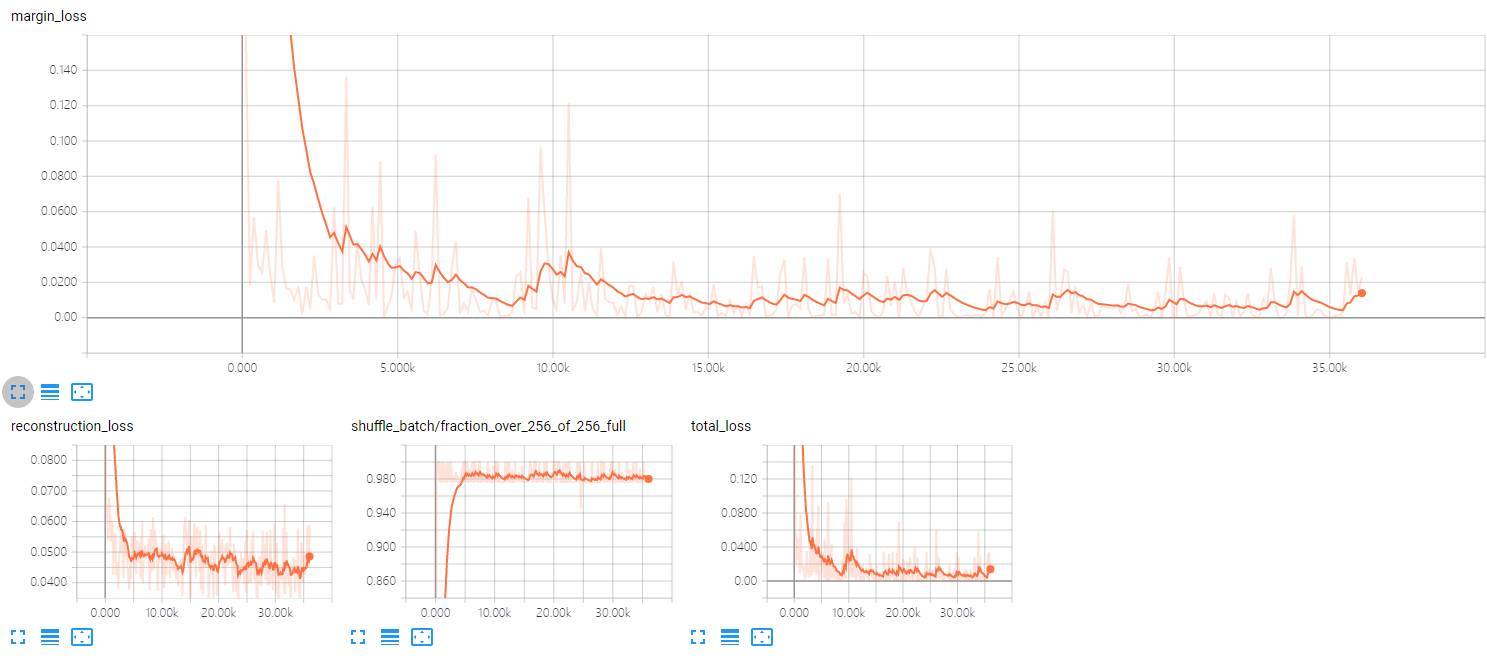
我們也迭代訓練了大概 3 萬多步,不過因爲使用的是 CPU,所以我們將批量大小調整爲 8 以減少單次迭代的計算壓力,以下是我們訓練時的損失情況,最上面是 Margin loss,下面還有重構損失和總損失:
最後放上兩張由 DigitCaps 層輸出向量重構出的對應圖像:

我們只是初步地探索了 CapsNet,它還存在很多的可能性,例如它以向量的形式應該能獲取非常多的圖像信息,這種優勢是否能在其它大型數據集或平面 3D 圖像數據集中進一步展現出非凡的表徵力?而且第二層 PrimaryCaps 的參數非常多,就像一組橫向並聯的卷積結構以產生向量(類似 Inception 模塊,但要寬地多),我們是否能通過某種方式的共享進一步減少該層級的參數?還有當前 Routing 過程的效果至少在 MNIST 數據集中並不好,它僅僅只能展示存在這個概念,那麼我們能否找到更加高效的 Routing 算法?此外,Capsule 是否能擴展到其他神經網絡結構如循環或門控單元?這些可能都是我們存在的疑惑,但向前走,時間總會給我們答案的。
歡迎大家留言討論,本文在我們網站上將持續更新與修正。
參考資料
原論文:Dynamic Routing Between Capsules(https://arxiv.org/abs/1710.09829)
知乎討論地址:https://www.zhihu.com/question/67287444/answer/251241736
naturomics 實現地址(TensorFlow):https://github.com/naturomics/CapsNet-Tensorflow
XifengGuo 實現地址(Keras):https://github.com/XifengGuo/CapsNet-Keras
leftthomas 實現地址(Pytorch):https://github.com/leftthomas/CapsNet