選自DeepMind
作者:Max Jaderberg
參與:蔣思源、劉曉坤
近日,DeepMind 發表論文提出一種新型的超參數調優方法,該方法從遺傳算法獲得啓發大大提升了最優超參數搜索的效率。它的性能要比貝葉斯優化好很多,且在各種前沿模型的測試中很大程度上提升了當前最優的性能。
從圍棋、Atari 遊戲到圖像識別與語言翻譯,神經網絡都取得了巨大的成功。但我們常常忽略的是,神經網絡在特定應用上的成功通常取決於研究開始時所做的一系列選擇,包括使用什麼樣的神經網絡架構、數據與方法進行訓練等。目前,這些選擇或者說超參數都是通過實驗經驗、隨機搜索或計算密集型的搜索過程實現。
在我們近日發佈的論文 Population Based Training of Neural Networks 中,我們引進了一種訓練神經網絡的新方法,它允許實驗者針對不同的任務快速選擇最佳的參數集和模型。這種技術稱爲基於種羣的訓練(Population Based Training/PBT),它會同時訓練並優化一系列網絡,從而可以快速地搜索最佳的配置。更重要的是,這並不會增加計算開銷,它可以像傳統技術一樣快速地完成,並可以輕易地集成到現有的機器學習流程中。
該技術是隨機搜索和手動調整這兩種最常見超參數最優化方法的混合體。在隨機搜索中,算法會並行地訓練一組獨立的神經網絡,並在訓練結束時選擇性能最好的模型。一般情況下,這意味着只有一小部分的網絡會使用經過精調的超參數進行訓練,而大多數仍然使用並不太優秀的超參數進行訓練,因此這會造成計算資源的浪費。
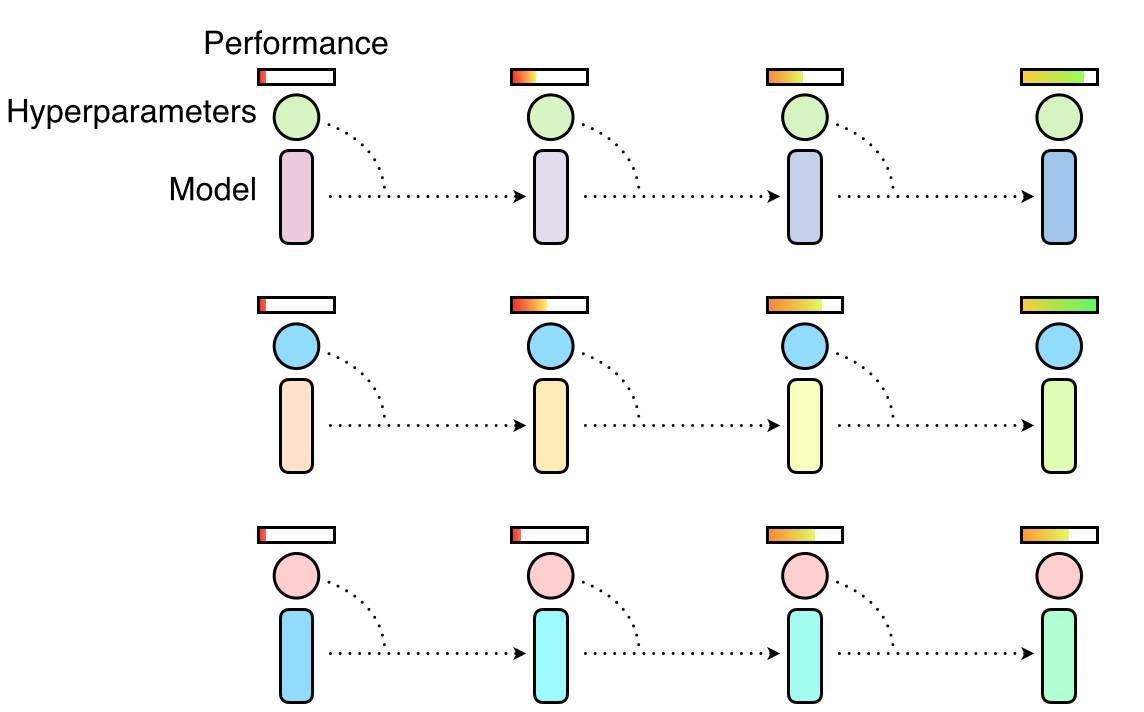
隨機搜索超參數,其中很多超參數是通過並行選擇的,它們之間是互相獨立的。一些超參數會產生良好的性能,但另一些並不會。
對於手動調參而言,研究者必須根據經驗選擇可能的最好超參數,然後再訓練和評估模型。這需要一遍又一遍地完成,直到研究者對網絡的性能總體上感到滿意。雖然這可能會產生較好的性能,但缺點是可能需要非常長的時間,有時甚至需要數週或數月才能找到完美的配置。雖然目前有一些如貝葉斯優化等方法自動完成這一過程,但仍然需要很長的時間和很多連續的訓練任務才能找到最好的超參數。
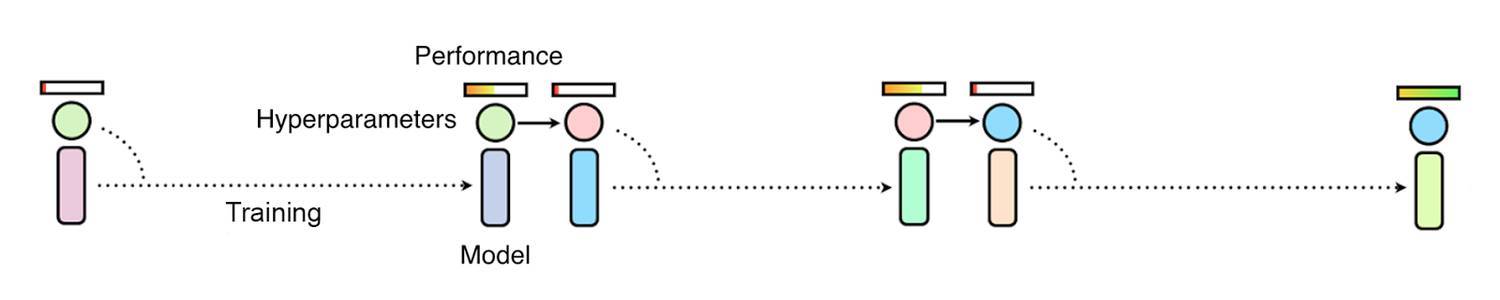
使用手動調參和貝葉斯優化的方法修正超參數需要依次觀察許多網絡的訓練結果,這一過程令這些方法很慢。
PBT 就像隨機搜索一樣,首先需要以隨機超參數的方式訓練許多並行的網絡。但是這些網絡並不是獨立訓練的,它們會使用其它網絡的訓練信息來修正這些超參數,並將計算資源傾向那些有潛力的模型。這一過程是從遺傳算法獲得的靈感,其中一組網絡(或稱爲種羣/population)中的每個神經網絡即一個個體(worker),它可以利用除自身外其餘網絡的信息。例如單個網絡(或稱爲個體)可能會從表現較好的個體中複製模型參數,它還能通過隨機修正當前的值而探索新的超參數組合。
隨着不斷地對神經網絡羣體進行訓練,不斷反覆進行開發和探索的步驟(詳見擬合目標函數後驗分佈的調參利器:貝葉斯優化),算法能確保所有的個體都有非常好的基礎性能水平,且都能進行一定的超參數新探索。這意味着 PBT 可以快速利用優秀的超參數,併爲有潛力的模型提供更多的訓練時間。因此這個算法的關鍵點在於它可以在整個訓練過程中調整超參數值,從而自動學習最優配置。
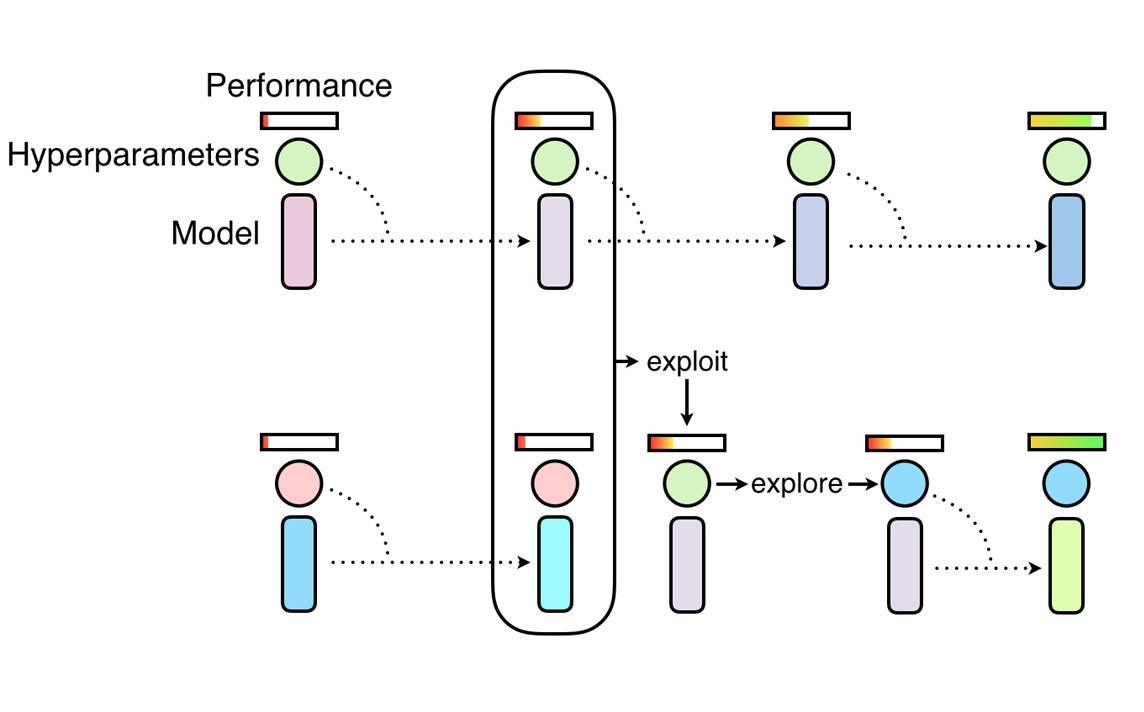
PBT 算法的起始階段類似隨機搜索,但允許一個個體利用其它個體的部分結果,並在訓練過程中探索新的超參數。
我們的實驗表明,PBT 在主要的任務和領域中都是非常有效的。例如,我們在 DeepMind Lab、Atari 和 StarCraft II 中的一系列有挑戰性的強化學習問題上使用當前最佳的方法嚴密地測試了該算法。在所有的案例中,PBT 都能穩定訓練過程,並快速找到好的超參數,得到超越當前最佳基線的結果。
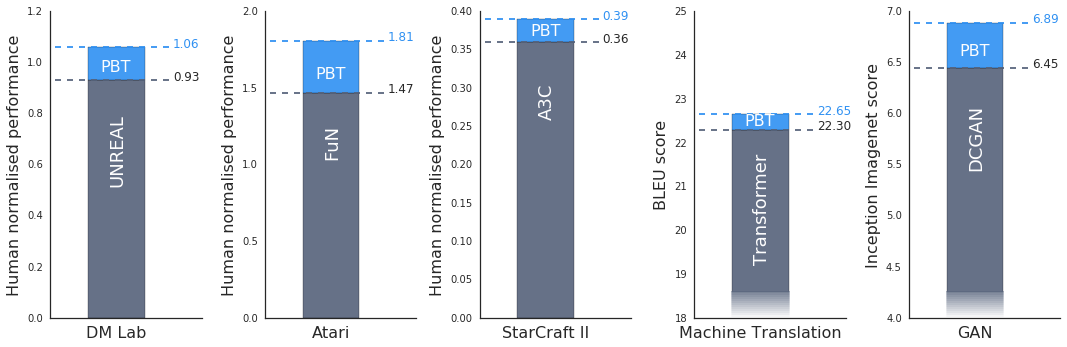
我們還發現 PBT 可以有效地訓練生成對抗網絡(GAN),衆所周知,該網絡是很難調整的。具體的說,我們是用 PBT 框架以最大化 Inception 分數(一種視覺保真度的度量),獲得了顯著的提升,即從 6.45 提高到 6.9。
我們還將 PBT 應用到谷歌的一種當前最佳的機器翻譯神經網絡(通常需要花費數月時間進行細緻的手動調整超參數方案)上。通過 PBT 我們可以自動地獲得超參數方案以得到甚至超越當前性能,在過程中不需要任何人爲調整,並且它通常只需要運行單次訓練。
GAN 在 CIFAR-10 上和 Feudal Networks(FuN)在 Ms Pacman 上的訓練過程中的羣體演化。粉色點表示初始智能體,藍色點表示最終智能體。
我們相信這僅僅是這項技術的開端。在 DeepMind,我們還發現 PBT 能特別有效地用於訓練新的算法和具有新的超參數的神經網絡架構。隨着我們對該算法的進一步打磨,PBT 將爲尋找和開發更加複雜和強大的神經網絡模型提供助力。
論文:Population Based Training of Neural Networks

論文地址:https://deepmind.com/documents/135/population_based_training.pdf
摘要:神經網絡在機器學習領域占主導地位,但其訓練過程和成功率仍然受到對超參數(如模型架構、損失函數和優化算法等)的經驗選擇的敏感度的限制。我們在這裏提出基於種羣的訓練(Population Based Training,PBT),這是一種簡單的異步優化算法,可以有效地利用固定的計算開銷聯合優化一羣/多個模型和其超參數以最大化性能。重要的是,PBT 可以發現一個超參數配置的方案,而不是像通常那樣使用子優化策略,即嘗試尋找單個固定的超參數集用於整個訓練過程。只需要對一種典型的分佈式超參數訓練框架做少量修改,我們的方法就能對模型進行魯棒性的和可靠的訓練。我們展示了 PBT 應用於深度強化學習問題的有效性,通過優化一系列超參數,表明可以達到小時級別的收斂速度並獲得更高性能的智能體。此外,我們展示了該方法還可以應用於機器翻譯的監督學習(其中 PBT 可以直接最大化 BLEU 分數),以及生成對抗網絡的訓練(最大化生成圖像的 Inception 分數)。在所有的案例中,PBT 都能自動獲得超參數的配置方案和模型的選擇方案,從而使訓練過程變得穩定,並獲得更好的最終性能。
原文鏈接:https://deepmind.com/blog/population-based-training-neural-networks/