雷鋒網消息:2017年10月4日,Google Deepmind發表博客稱,其一年前提出的生成原始音頻波形的深層神經網絡模型WaveNet已正式商用於Google Assistant中,該模型比起一年前的原始模型效率提高1000倍,且能比目前的方案更好地模擬自然語音。
以下爲Deepmind博客所宣佈的詳細信息,雷鋒網摘編如下
一年之前,我們提出了一種用於生成原始音頻波形的深層神經網絡模型WaveNet,可以產生比目前技術更好和更逼真的語音。當時,這個模型是一個原型,如果用在消費級產品中的計算量就太大了。
在過去12個月中,我們一直在努力大幅度提高這一模型的速度和質量,而今天,我們自豪地宣佈,WaveNet的更新版本已被集成到Google Assistant中,用於生成各平臺上的所有英語和日語語音。
新的WaveNet模型可以爲Google Assistant提供一系列更自然的聲音。
爲了理解WaveNet如何提升語音生成,我們需要先了解當前文本到語音(Text-to-Speech,
TTS)或語音合成系統的工作原理。
目前的主流做法是基於所謂的拼接TTS,它使用由單個配音演員的高質量錄音大數據庫,通常有數個小時的數據。這些錄音被分割成小塊,然後可以將其進行組合以形成完整的話語。然而,這一做法可能導致聲音在連接時不自然,並且也難以修改,因爲每當需要一整套的改變(例如新的情緒或語調)時需要用到全新的數據庫。
另一方案是使用參數TTS,該方案不需要利用諸如語法、嘴型移動的規則和參數來指導計算機生成語音並進行語音拼接。這種方法即便宜又快捷,但這種方法生成的語音不是那麼自然。
WaveNet採取完全不同的方法。在原始論文中,我們描述了一個深層的生成模型,可以以每秒處理16000個樣本、每次處理一個樣本黨的方式構建單個波形,實現各個聲音之間的無縫轉換。

WaveNet使用卷積神經網絡構建,在大量語音樣本數據集上進行了訓練。在訓練階段,網絡確定了語音的底層結構,比如哪些音調相互依存,什麼樣的波形是真實的以及哪些波形是不自然的。訓練好的網絡每次合成一個樣本,每個生成的樣本都考慮前一個樣本的屬性,所產生的聲音包含自然語調和如嘴脣形態等參數。它的「口音」取決於它接受訓練時的聲音口音,而且可以從混合數據集中創建任何獨特聲音。與TTS系統一樣,WaveNet使用文本輸入來告訴它應該產生哪些字以響應查詢。
原始模型以建立高保真聲音爲目的,需要大量的計算。這意味着WaveNet在理論上可以做到完美模擬,但難以用於現實商用。在過去12個月裏,我們團隊一直在努力開發一種能夠更快地生成聲波的新模型。該模型適合大規模部署,並且是第一個在Google最新的TPU雲基礎設施上應用的產品。

(新的模型一秒鐘能生成20秒的音頻信號,比原始方法快1000倍)
WaveNet團隊目前正在準備一份能詳細介紹新模型背後研究的論文,但我們認爲,結果自己會說話。改進版的WaveNet模型仍然生成原始波形,但速度比原始模型快1000倍,每創建一秒鐘的語音只需要50毫秒。該模型不僅僅速度更快,而且保真度更高,每秒可以產生24,000個採樣波形,同時我們還將每個樣本的分辨率從8bit增加到16bit,與光盤中使用的分辨率相同。
這些改進使得新模型在人類聽衆的測試中顯得發聲更爲自然。新的模型生成的第一組美式英語語音得到的平均意見得分(MOS)爲4.347(滿分5分),而真實人類語音的評分只有4.667。
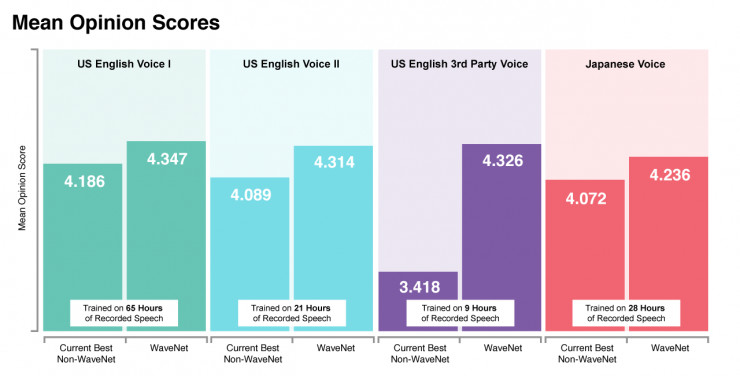
新模式還保留了原始WaveNet的靈活性,使我們能夠在訓練階段更好地利用大量數據。具體來說,我們可以使用來自多個語音的數據來訓練網絡。這可以用於生成高質量和具有細節層次的聲音,即使在所需輸出語音中幾乎沒有訓練數據可用。
我們相信對於WaveNet來說這只是個開始。我們爲所有世界語言的語音界面所能展開的無限可能而興奮不已。
(Via Deepmind,雷鋒網(公衆號:雷鋒網)編譯)
