
作爲 Facebook 人工智能部門主管, Yann LeCun 是 AI 領域成績斐然的大牛,也是行業內最有影響力的專家之一。
近日,LeCun在卡內基梅隆大學機器人研究所進行了一場 AI 技術核心問題與發展前景的演講。他在演講中提到三點乾貨:
1. 無監督學習代表了 AI 技術的未來。
2. 當前 AI 應用的熱點集中在卷積神經網絡。
3. 用模擬器提高無監督學習的效率是大勢所趨。
演講完整視頻如下。該視頻長 75 分鐘,幷包含大量專業術語,因此雷鋒網節選關鍵內容做了視頻摘要,以供讀者瀏覽。
以下爲視頻摘要:
一、無監督學習的重要性
AI 技術的飛速進步很大程度上是由於深度學習和神經網絡領域的突破,還得益於大型數據庫的建立和更快的 GPU。我們現在已有了圖像識別能力可與人類相比的 AI 系統 (例如下文中 Facebook 的識別系統)。這會導致自動化交通,醫療圖像解析在內的多個領域的革命。但這些系統現在用的都是監督學習(supervised learning),輸入的數據被人爲加上標籤。
接下來的挑戰在於,怎麼讓機器從未經處理的、無標籤無類別的數據中進行學習,比方說視頻和文字。而這就是無監督學習(unsupervised learning)。
二、神經網絡的規模越大越好
傳統的思想認爲,如果你沒有大量的數據,神經網絡應該控制在較小的規模。Yann LeCun 指出這完全是錯誤的。他的團隊在數據不變的情況下擴展了神經網絡,得到了更好的結果。他說,神經網絡越大,效果就越好(當然前提是數據庫大小達到了臨界值)。至於爲什麼會這樣,目前仍是一個謎,相關理論研究正在開展。
三、卷積神經網絡在識別領域的廣闊前景
Yann LeCun 特別強調了卷積神經網絡的重要性和應用:」我們很早就認識到,卷積神經網絡可以被用來處理多種任務——不單單是識別單個物體(比如字母數字),還可以識別多個物體,同時進行物體識別、分組和解釋。比方說,可以用卷積神經網絡訓練 AI 系統識別並標註(攝像頭所拍攝)圖像中的每一個像素,以此分析前方路徑是否可通過。在英偉達最近的自動駕駛項目中,他們就使用了卷積神經網絡來訓練自動駕駛系統。系統分析攝像頭提供的圖像,據此模仿人類的轉向角度。「
他還介紹了卷積神經網絡在 Facebook 圖像識別系統中的應用。「有了它之後,Facebook 的系統不僅能識別圖像,還能繪製出圖像的輪廓,並根據輪廓影像對物體進行分類。該系統甚至可以挑出中國菜裏面的西蘭花(如下圖)。」

下面是對同一幅圖像識別前後的對比:


Yann LeCun 表示這是一個巨大的進步,如果你在幾年前問一個 AI 專家:」我們什麼時候才能做到這樣?」,答案會是「不清楚」。
「 想讓 AI 技術繼續進步,我們就必須要讓機器能夠分析、推理、記憶,把現象和文字轉化爲運行知識。」
他接着作出預測,下一個將會十分流行的技術是記憶增強神經網絡。它可被理解爲用記憶增強的遞歸神經網絡,其中,記憶本身是一個能被區分的迴路,並可以作爲學習中的一部分用於訓練。Yann LeCun 接下來對該技術進行了深入探討,這裏不贅述,詳情請見視頻。
四、強化學習、監督學習、無監督學習的數據要求
進行強化學習、監督學習、無監督學習的所需數據規模相差數個數量級。強化學習每次驗證(trial)所需的信息可能只有幾比特,監督學習是十到一萬比特的信息量,而無監督學習則需要數百萬比特。所以,Yann LeCun 做了一個比喻:假設機器學習是一個蛋糕,強化學習是蛋糕上的一粒櫻桃,監督學習是外面的一層糖衣,無監督學習則是蛋糕糕體。無監督學習的重要性不言而喻。爲了讓強化學習奏效,也離不開無監督學習的支持。

五、用模擬機制提高強機器學習的效率
當下的主要問題是,AI 系統沒有「常識」。人類和動物通過觀察世界、行動和理解自然規律來獲得常識,機器也需要學會這麼做。包括 Yann LeCun 在內的許多專家,把無監督學習作爲賦予機器常識的關鍵,該過程如下:
AI 系統由兩部分組成:代理和目標(agent and objective)。代理做出行動,觀察該行動對現實的影響產生認知,然後再通過該認知來預測現實情況。代理進行這一系列活動的動機來自於實現目標,而最終的目的則是:以最高的效率達到該目標。在強化學習中,對代理行爲的獎勵(reward)來自於外部,無監督學習的獎勵則來自內部(對接近該目標的滿意)。
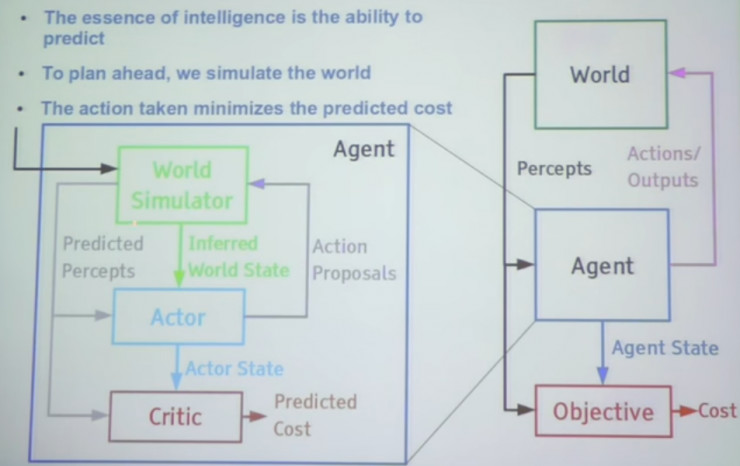
但這個過程存在一個很大的問題:代理進行無監督學習的方法是在現實生活中進行各種嘗試,這存在危險並且效率很低。比如,無人駕駛車不能嘗試所有可能的駕駛方法,會帶來安全隱患。這種嘗試又受到時間的限制,不能像計算機程序那樣每秒運行數千次。所以,Yann LeCun 解釋道,爲了提高機器學習的效率,我們需要基於模型的強化學習(model based reinforcement learning )。它由三部分組成:現實模擬器(world simulator),行動器(actor)和反饋裝置(critic)。現實模擬器對現實情況進行模擬,行動器生成行動預案(action proposals),然後反饋裝置對該行動的效果進行預測。這樣,AI 系統就可以對行動反覆推演,進行優化,而不受到現實中時間和成本的限制。
小結: 作爲業內大牛,Yann LeCun 的一舉一動都受到關注。他之前就發表過對 AI 前景和無監督學習的若干講話,這一次在卡內基梅隆的研究人員面前再次強調了他的觀點。雖然這不是我們第一次聽到專家強調無監督學習、甚至是卷積神經網絡的重要性;但此次演講中, Yann LeCun 借用許多技術細節和各大公司、研究院正在從事的研究作爲示例,爲無監督學習將來會怎樣發展作了全面的註解。正因如此,雷鋒網(公衆號:雷鋒網)建議關注 AI 領域未來發展方向的讀者,不妨抽出一個下午仔細聽一下演講,必定會有收穫。
【招聘】雷鋒網堅持在人工智能、無人駕駛、VR/AR、Fintech、未來醫療等領域第一時間提供海外科技動態與資訊。我們需要若干關注國際新聞、具有一定的科技新聞選題能力,翻譯及寫作能力優良的外翻編輯加入。工作地點深圳。簡歷投遞至 guoyixin@leiphone.com 。兼職及實習均可。
推薦閱讀:
大神 Yann LeCun:我們的使命是終結「填鴨式」 AI
