雷鋒網按:本文來源公衆號「極限元」,作者溫正棋,極限元技術副總裁、中國科學院自動化研究所副研究員,中科院—極限元「智能交互聯合實驗室」主任。雷鋒網(公衆號:雷鋒網)授權轉載。
語音作爲互聯網的一種入口方式,正在侵入我們的生活,人機交互的核心——對話系統,對交互的應用至關重要,人腦與機器智能的結合,能夠突破現有技術瓶頸嗎?這裏就有必要重點介紹下人機交互相關的核心技術。
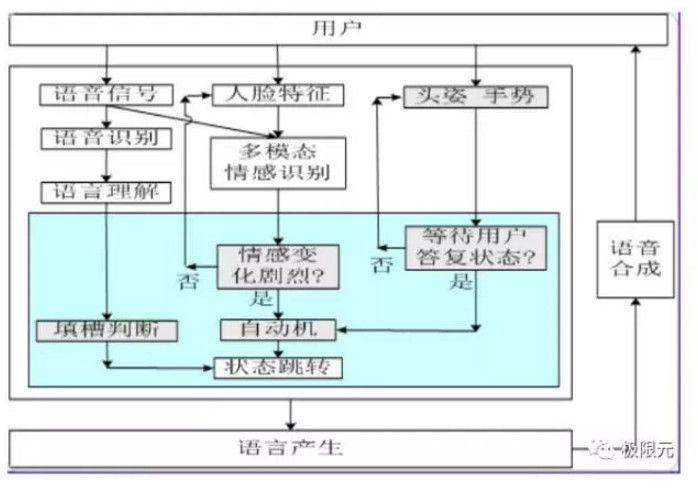
從整個交互系統接入用戶的輸入信息開始,包括語音、人臉、多模態情感相關的信息,我們在對話系統裏面對輸入的信息進行理解,通過這個對話部分以後產生輸出,最後用文字也可以用語音合成展現出來,這就是整個流程,其中我們關注的最主要的是語音部分以及對話系統部分,其他的多模態今天的分享不會涉及太多。
國內研究語音相關的團隊主要包括科研院所、語音技術公司以及互聯網公司三部分:
科研院所主要包括高校和科學院,比如科學院裏有聲學所、自動化所,高校裏面研究比較多的清華、北大、西工大、科大、上海交大等,這些都是在語音圈裏佔有較高位置的老牌隊伍。
語音技術公司包括我們比較熟悉的科大訊飛、雲知聲、思必馳、極限元等。
互聯網公司包括BAT、搜狗等擁有強大的語音技術團隊來支撐着其本身的很多業務。
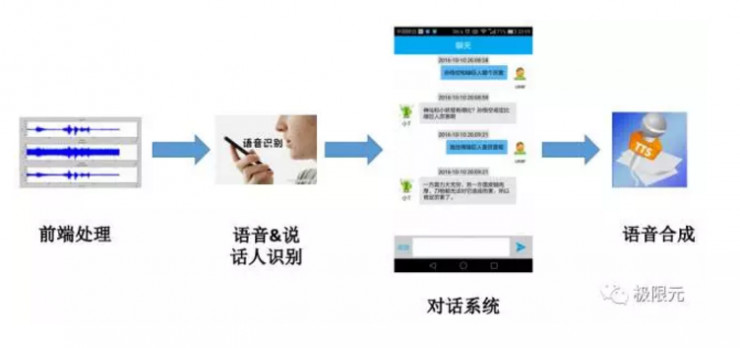
在應用對話系統時,首先從語音輸入開始要有一些前端處理,包括硬件和軟件的前期處理;接下來是語音內容,說話人識別等相關的內容進行判別,對話系統根據輸入信息來進行對話邏輯的分析,以及對應語言的產生,最後由語音合成系統來合成語音,在這裏重點介紹一下前端處理、語音識別、說話人識別語音合成等相關技術。
前端處理技術的研究進展
前端處理包括回升消除、噪聲抑制、混響抑制等技術,剛開始時研究前端處理的人員並不多。近年來特別是ECHO的推出,把一些遠場的問題融入到語音識別等系統中,所以這部分的研究在這幾年興起比較快。語音識別的研究從一些簡單的數據如手機的錄音擴展到遠場的語音識別,這些促進了前端處理技術的發展,在語音圈裏做前端處理比較牛的應該是陳景東老師。
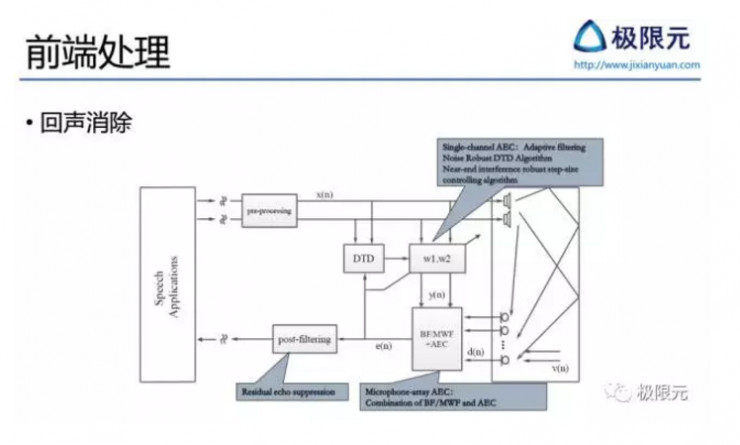
回聲消除
回聲消除在遠場語音識別中是比較典型功能,最典型的應用是在智能終端播放音樂的時候,遠場揚聲器播放的音樂會回傳給近端麥克風,此時就需要有效的回聲消除算法來抑制遠端信號的干擾,這是在智能設備如音響、智能家居當中都需要考慮的問題。比較複雜的回聲消除系統,近端通過麥克風陣列採集信號,遠端是雙聲道揚聲器輸出,因此近端需要考慮如何將播出形成算法跟回聲消除算法對接,遠端需要考慮如何對立體聲信號相關。
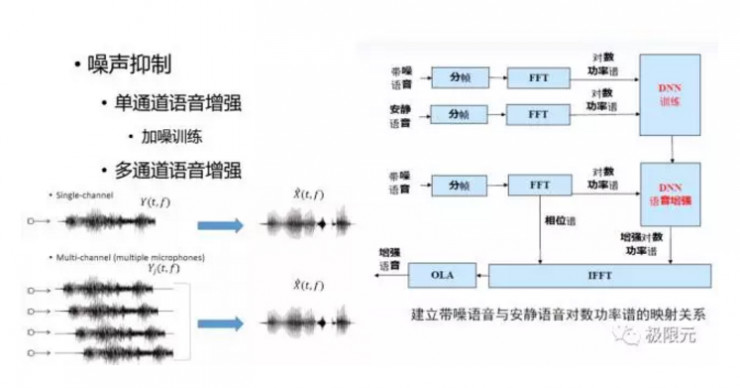
噪聲抑制
噪聲抑制可以有多通道的也可以有單通道的,今天主要介紹單通道噪聲抑制,單通道語音增強通過DNN的方法進行增強,語音信號是有一個諧波結構的,通過加入噪聲這個諧波結構會被破壞掉,語音增強的主要目的就是擡高波峯,降低波谷,這個訓練對DNN來說是比較容易的。但是也有實驗研究表明,基於DNN的語音增強對濁音段效果會比較好,但對輕音段效果並不是很好,語音的濁音段有顯著諧波結構,因此要有目的去訓練這個模型。
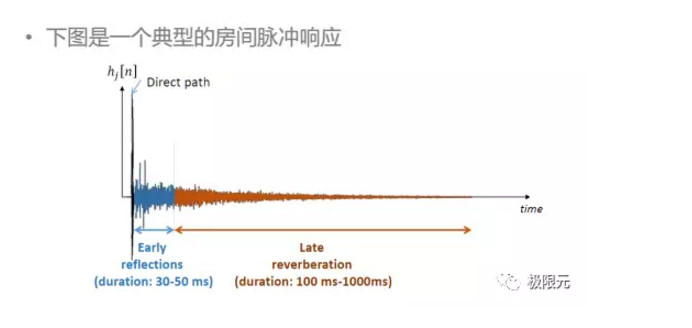
混響抑制
聲音在房間傳輸過程中經過牆壁或者其他障礙物的反射後到達麥克風,從而生成混響語音,混響的語音會受到房間大小、聲源麥克風的位置、室內障礙物等因素的影響,大多數的房間內混響時間大概在200--1000毫秒範圍內,如果混響時間過短,聲音會發幹,枯燥無味,不具備清晰感,混響時間過長會使聲音含混不清,需要合適的聲音才能圓潤動聽。
前端處理涉及的內容比較多,除了前面提到的還包括多說話人分離、說話人移動過程中的聲音採集、不同的麥克風陣列結構、各種噪聲和房間模型如何更好的建模等。
音識別技術的研究進展
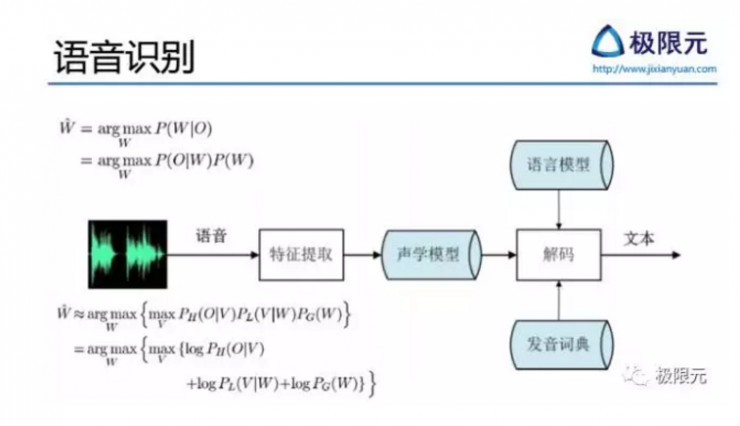
有了前端處理以後,反饋回來的信息會加到訓練語音識別模型,語音識別主要是建立一個聲學參數到發音單元的映射模型或者叫判別模型,現在的方法從傳統的GMM-HMM模型到DNN-HMM混合模型,再到最新的端到端的CTC相關的。語音信號經過特徵提取得到聲學特徵,再通過聲學特徵訓練得到聲學模型,聲學模型結合語言模型以及發音辭典構建聲碼器以後,最終識別出文本。
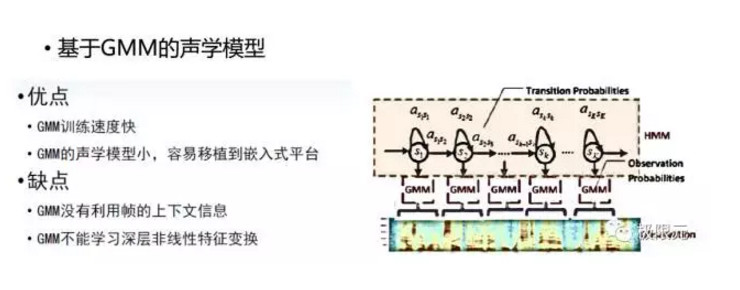
GMM用來對每個狀態進行建模,HMM描述每個狀態之間的轉移概率,這樣就構建了一個音素或三因子的HMM模型建模單元,GMM訓練速度相對較快,而且GMM聲學模型可以做得比較小,可以移植到嵌入式平臺上,其缺點是GMM沒有利用真的上下文信息,同時GMM不能學習深層的非線性特徵變換,建模能力有限。
隨着深度神經網絡的興起,深度神經網絡也應用到了語音識別裏面聲學建模,主要是替換了GMM-HMM模型裏的GMM模型,上端仍然是HMM模型加狀態轉移,在GMM模型裏面可能有500至1萬個狀態,這個狀態可以通過DNN模型預測出每個的概率,輸出的就是一個三因子,我們兩者結合起來構建基於DNN-HMM的聲學模型。
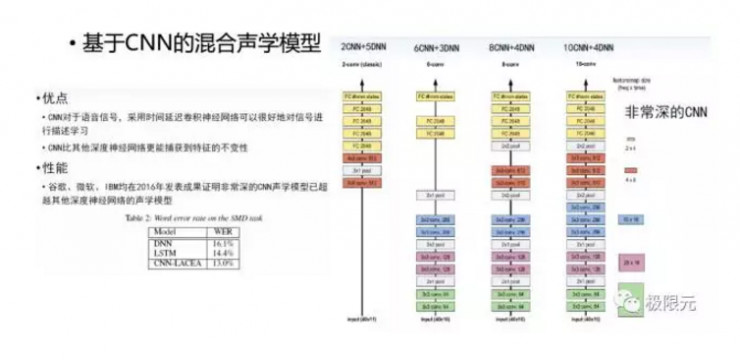
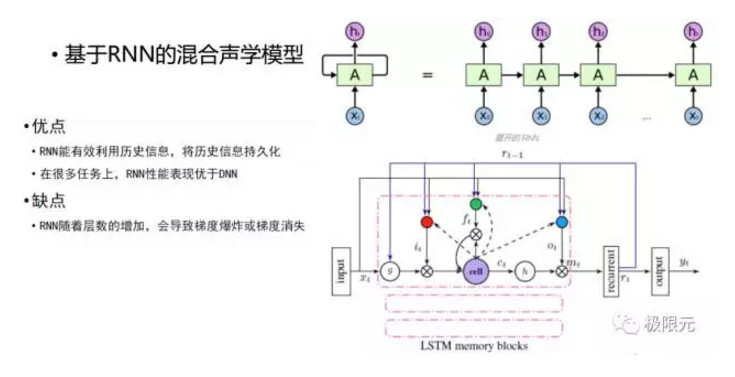
DNN能利用的上下文系統在輸入端進行擴幀,同時又非線性變換可以學習到,但DNN不能利用歷史信息捕捉當前的任務,因爲擴幀是有限的,不可能無限擴下去,所以他輸入的歷史信息還是有限的。因此,自然而然的有了基於RNN的混合聲學模型,將DNN模塊替換成RNN模塊,RNN能夠有效的對歷史信息進行建模,並且能夠將更多的歷史信息保存下來,可於將來的預測。但是在RNN訓練過程中會存在梯度消失和梯度膨脹的問題,梯度膨脹可以在訓練過程中加一些約束來實現,當梯度超過一定值以後設定一個固定值,但是梯度消失很難去把握,因此有很多方法解決這種問題,比較簡單的一個方法是將裏面的RNN單元變成長短時記憶模型LSTM,這樣長短時記憶模型能夠將記憶消失問題給很好的解決,但這樣會使計算量顯著增加,這也是在構建聲學模型中需要考慮的問題。
CNN用於聲學模型的建模有一個比較老的方法,在DNN的前端加兩層的CNN變換,這樣只對參數做了一定的非線性變換,變化完以後輸入DNN和LSTM裏面,但是隨着非常深的CNN在圖象識別裏面成功應用,這些也被運用到了聲學模型中,比如說谷歌、微軟、IBM均在2016年發表成果證明非常深的CNN模型已經超越其他深度神經網絡的模型,其詞錯率是最低的。
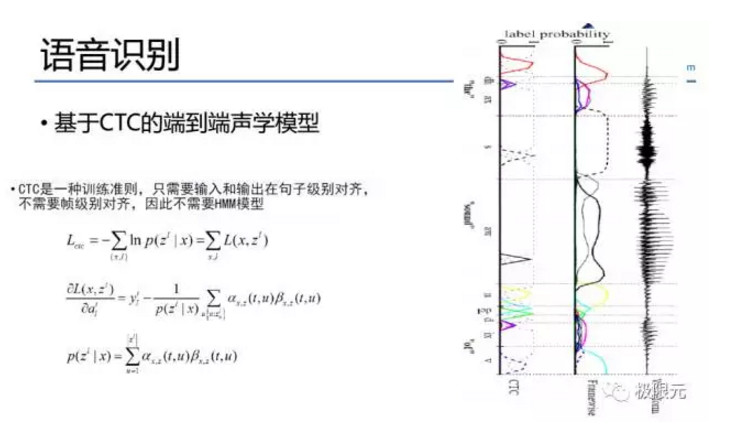
CTC本身是一個訓練準則並不算聲學模型,在DNN輸出中,每個phone他佔用的幀數可能有十幀二十幀。因爲它不是一個尖峯,但CTC會把它變成一個尖峯,CTC可以將每一幀變成一個senones或者對應一個因數,但每個因數只需幾幀就可以了,在解碼的時候可以把一些blank幀給去掉,這樣可以顯著的增加解碼速度。減少解碼幀有兩種方法,一種是通過減幀、跳幀的方法,另一種在解碼過程中有一個beam,特別是遇到beam的時候把並值減少,我們的實驗結果跳幀會比較好。
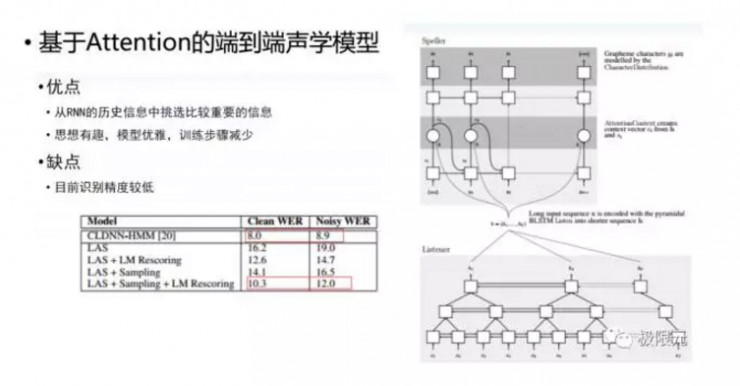
在NLP中應用較多的Attention端對端的聲學模型能夠從RNN歷史信息中挑選出比較重要的信息對詞學進行建模,目前的準確率比較低,這應該是一種趨勢,至少在NLP中證明了它是比較成功的。
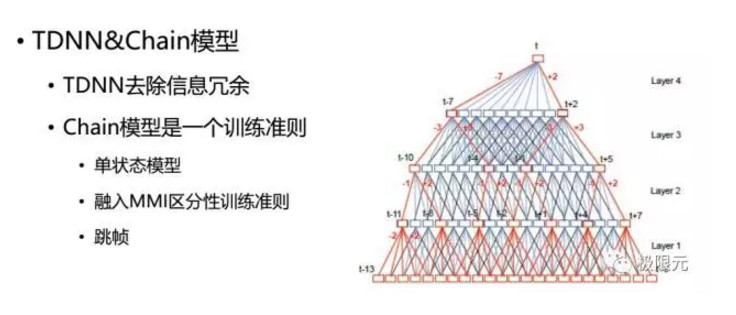
在聲學模型中還有TDNN和chain模型,在聲學模型中幀及運算過程中會有一些重疊,它有效的去除了信息冗餘,嵌入模型也是一個訓練準則,採用單狀態模型,融入了MMI區分信息鏈準則,在訓練過程中可以實現跳幀,這也加快了解碼速度。總結起來現在的語音識別模型更新特別快,最重要的核心內容就是數據,如果數據量足夠大的話,做出一個好的結果還是比較容易的,而且我們現在語音識別核心模塊主要是在一些解碼模塊上調優上,這相當於是一種藝術。
語音合成技術的研究進展
語音合成是建立文本參數到聲學參數的影射模型,目前的方法有拼接合成、參數合成還有端對端的語音合成。
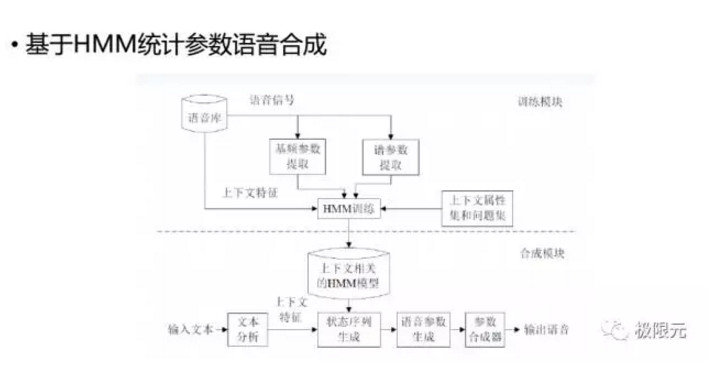
基於HMM統計參數的語音合成是在訓練過程中建立文本參數,如韻律參數、普參數和基頻參數的映射模型,通過決策數聚類的方法對每一個上下文相關的文本特徵構建GMM模型,訓練其GMM模型,在合成時對輸入文本預測出它的GMM以後,通過參數生成算法,生成語音參數然後再輸出語音。在這個過程中,有三個地方會產生語音音質的下降,第一是決策樹的聚類,第二是聲碼器,第三是參數生成算法,針對這三個問題,我們接下來看看各位研究者提出的解決方法。
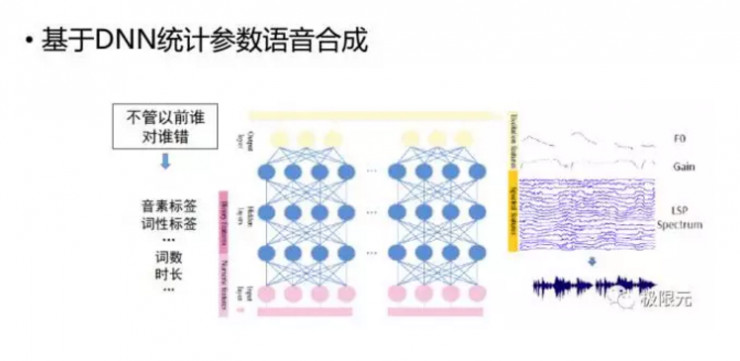
針對決策樹聚類的問題,我們可以將裏面的HMM決策樹據類變成一個DNN模型,文本參數到語音參數的一個映射可以很容易通過DNN來實現,而且在實驗效果會比決策樹好一點,但是並沒有達到我們理想中的那種很驚豔的一些結果。
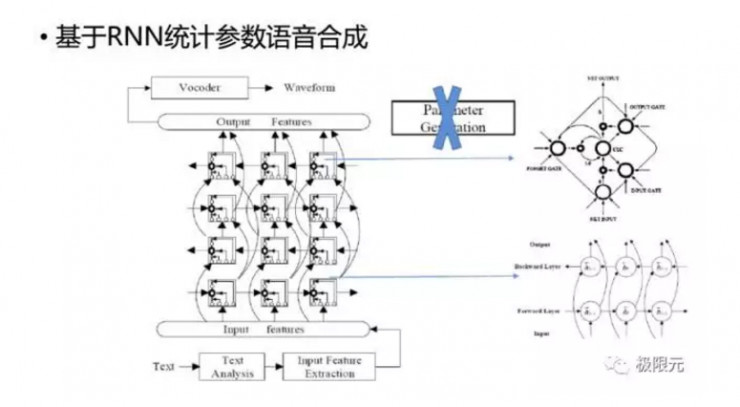
除了DNN,RNN也用到了統計參數語音合成中,而且RNN裏面單元採用LSTM模型,我們可以把參數生成算法這個模塊從統計參數語音合成中去掉,這樣在基於LSTM-RNN中直接預測出語音參數,通過聲碼器就可以合成語音,跟RNN-LSTM預測出一階二階統計量以後,採用參數生成算法,生成語音參數合成語音的話效果差不多,所以RNN-LSTM可以把裏面的參數生成算法給去掉。
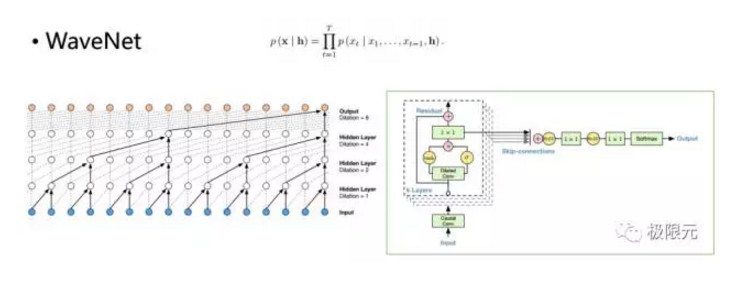
最近幾年大家在這方面聲碼器問題上做了很多工作,比如WaveNet其實也屬於聲碼器的模型,建立一個現今預測的模型,通過前面採樣點預測出後面的採樣點,但是存在幾個問題:比如剛開始速度比較慢,這個問題後期被很多公司都解決了,而且它並不是一個傳統的vocoder,需要文本參數作爲它的輸入。它有好處是在輸入過程中,可以很容易的在後端控制說話人的特徵,比如不同說話人情感特徵這些屬於外部特徵我們都可以進行很好的加入。
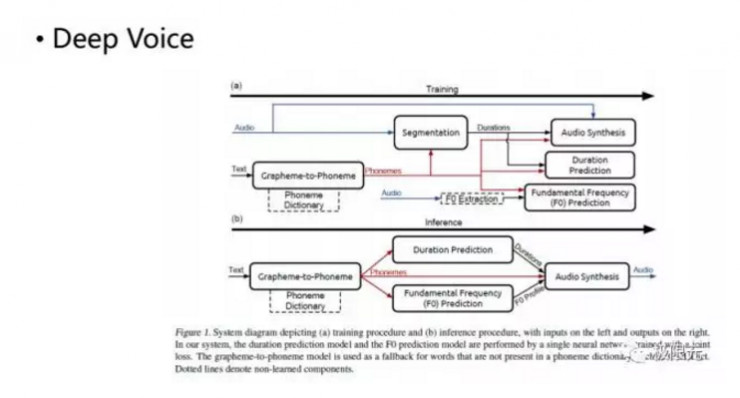
還有一個比較成功的是百度的Deep Voice,它將裏面的很多模塊用深度神經網絡去實現,而且做到了極致,這樣我們在最後通過類似WaveNet的合成器來合成,效果也是比較理想的。
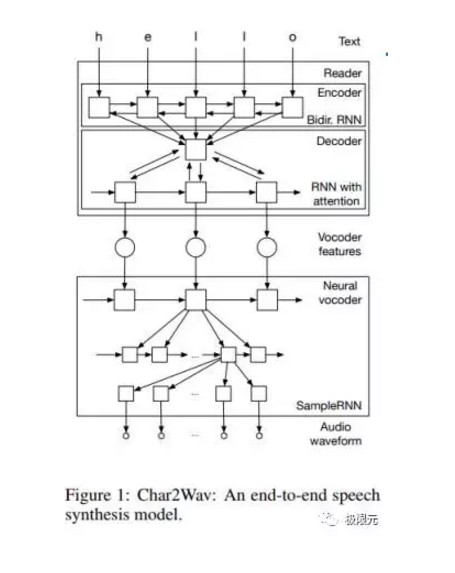
下面兩個端對端的語音合成:
第一個是Char2Wav,這個模型是直接對輸入的文本他進行編碼,採用的模型。對輸入的直接對輸入的叫字母進行編碼,然後生成中間的一個編碼信息放到解碼器裏進行最後的合成,合成採用SimpleRNN的合成器來合成語音,效果也是比較理想的,而且是純粹的End-To-End的一個語音合成模型。
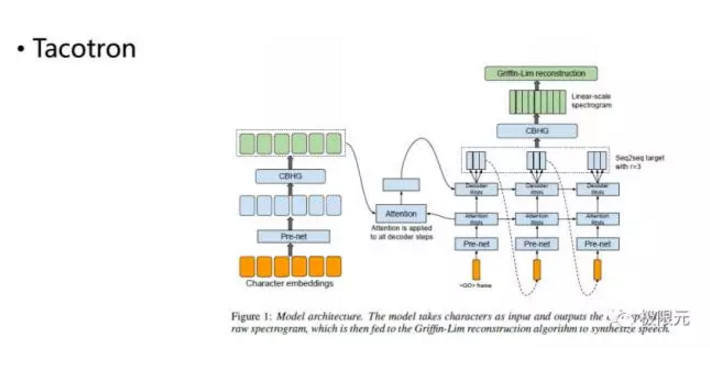
再一個是谷歌提出的端對端的語音合成系統,它跟Char2Wav比較類似,輸入的也是Embeddings,合成更加直接比RNN更好。
語音合成前期工作主要放在前端文本分析上,因爲我們在聽感上可能更關注,但是如果有一些很好的End-to-End的模型出來以後,文本分析的工作並不是很重要,我們也可以在後端中加入一些文本分析的結果進行預測,這即是一種嘗試,也是一種很好的辦法。現有的合成器的音質不再首先考慮我們採用哪種聲碼器,我們採用直接生成的方法在實域上直接進行合成。
語音合成更重要的是一些音庫,我們不能忽略音庫在語音合成中所佔據的位置,以及它的重要性。目前,極限元智能科技語音合成定製化支持錄音人選型、錄音採集、語料標註,還能實現模型迭代訓練、合成引擎優化,支持在線、離線模式,適用多種平臺
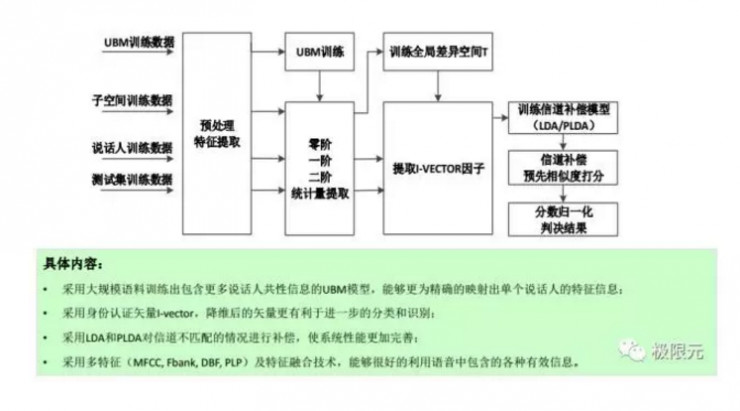
說話人識別也就是聲紋識別,簡單介紹一下現有的I-vector的系統以及如何將DNN應用到對應的I-vector系統,同時我們也跟蹤了最近end to end的一種方法。基於Ivector的系統,通過UBM模型來訓練數據,然後訓練得到混合高斯模型,通過統計量的提取,比如零階一階二階我們來訓練它的差異空間T,從而提取出它的Ivector,最後考慮到不同的補償方式進行信道補償,使性能更加完善,同時我們在合成端、最後識別端也可以考慮不同系統的融合提高最終的準確率。
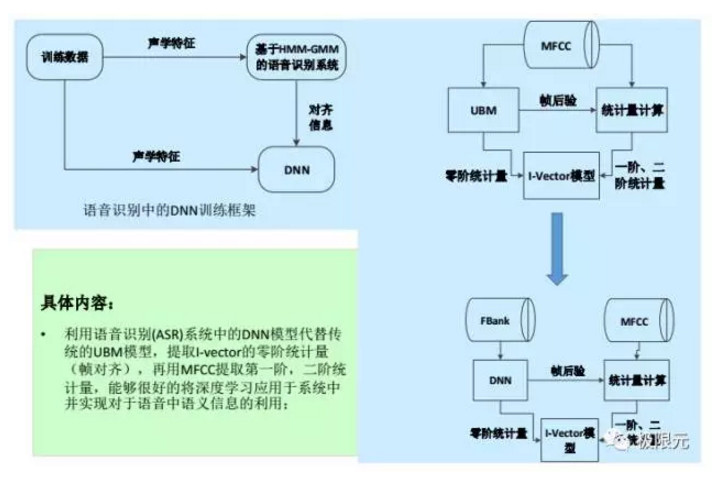
將DNN用到說話人識別,主要是針對Ivector的系統,UBM訓練是一個無監督的訓練方式。不考慮音速相關的信息,因此就不考慮每個人說話音速在聲學空間上法人不同,我們可以將這部分信息運用到說話人識別中,將前面提到的Ivector需要提到的臨界統計量,通過DNN模型的輸出把臨界統計量來進行替換,在訓練Ivector的過程中,考慮了每個人音速,發音音速相關的不同特徵,這樣會更好的對說話人進行識別。
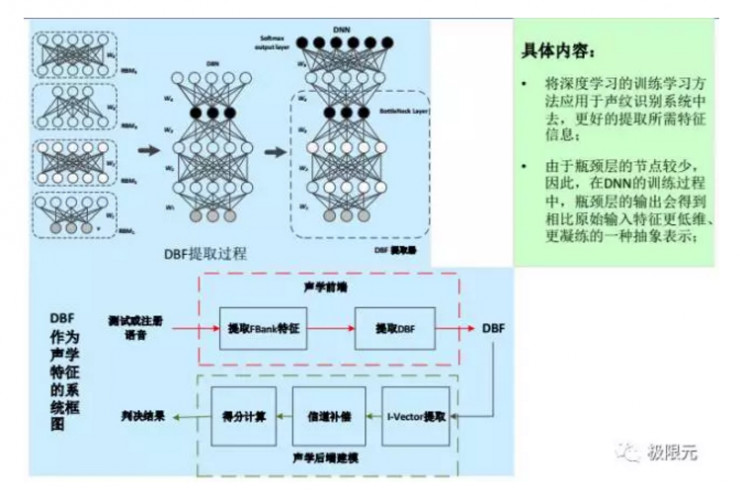
DNN還有一種應用形式,採用bottleneck特徵替換掉原來的MFCC,PLP相關的特徵,這也是從音速區分性,每個人發音音速不一樣來考慮的。
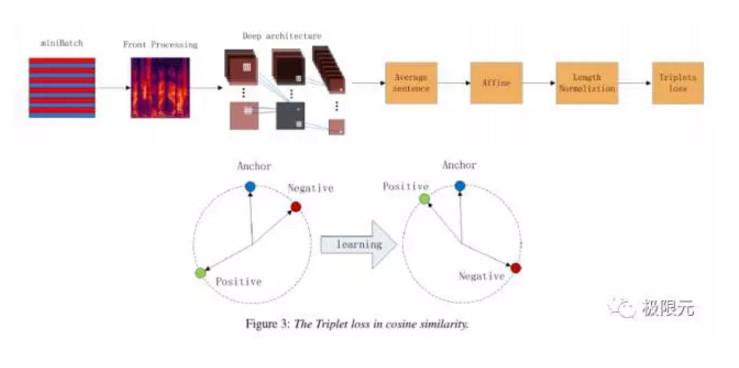
百度前段時間提到的一個Deep Speaker,這部分最主要的優點是採用了Triple Loss這種方法,能很好的用於訓練中。原來如果要訓練一個說話人可能是輸出是一個one-hot,但是speaker的訓練語並不是很多,所以訓練效果並不是很好,如果我們採用這種訓練誤差的,可以構建很多對訓練參數來進行訓練,這樣模型會更加棒。
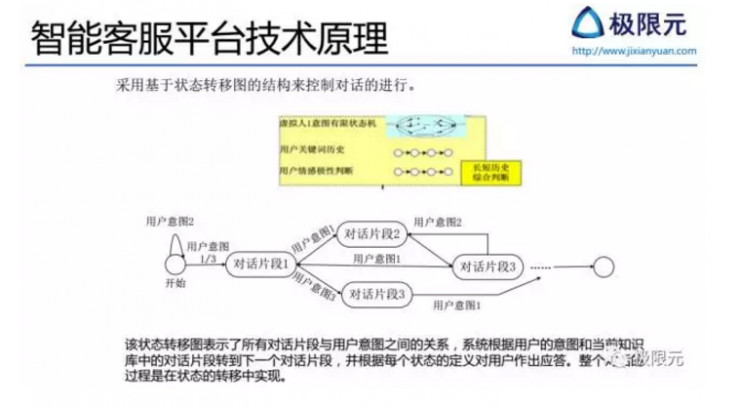
以一個簡單的智能客服平臺技術原理說明它採用了基於狀態轉移圖的結構來控制對話的進行,在這個狀態轉移圖中,表示了所有對話片斷與用戶意圖之間的關係,系統根據用戶的意圖和當前知識庫中的對話片斷轉到下一個對話片斷,並根據每個狀態的定義對用戶做出應答,整個對話的過程是在狀態轉移中實現的。
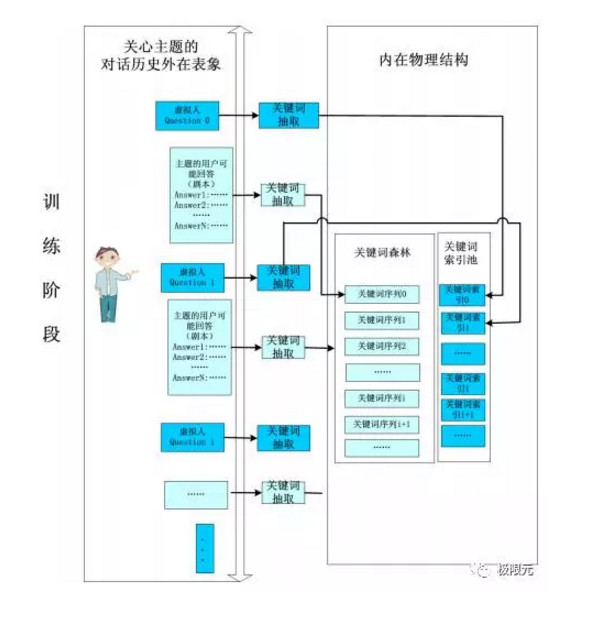
智能客服平臺訓練階段主要針對本身已有的系統進行簡單的數,包括兩個虛擬人,在運行過程中對虛擬人的提問,通過關鍵詞抽取對關鍵詞進行匹配,然後找到對應的它的狀態相關的信息,得到最優問題解答再進行返回。
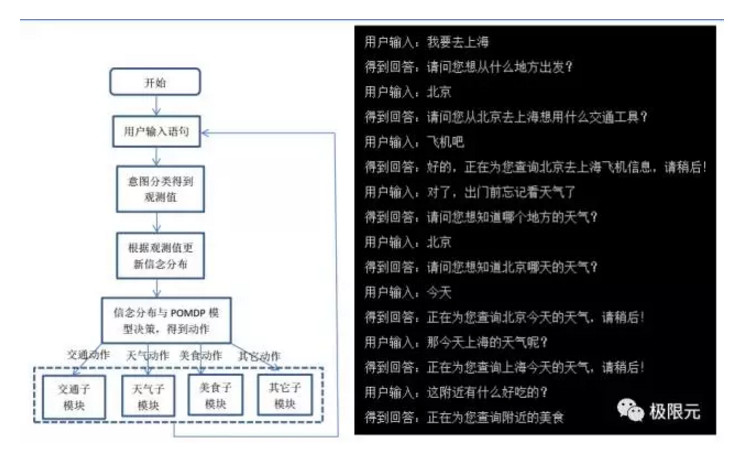
POMDP是一個六元組,包括狀態集合、觀察集合、行動集合、回報函數、轉移函數和觀測函數,根據用戶輸入語句來得到意圖分類,然後根據意圖分類得到觀測值,再通過對立面POMDP裏面的訓練分佈進行更新,訓練分佈與POMDP結合得到動作,分析各個子動作得到反饋後再接收新的數據。比如我要去上海,它會問你從哪裏出發,用什麼交通工具,對應一些信息,比如說查天氣,因爲查天氣的時候你需要反饋到是上海的天氣還是北京的天氣,這些都會根據上面的語句進行提問。
人機交互未來的研究方向
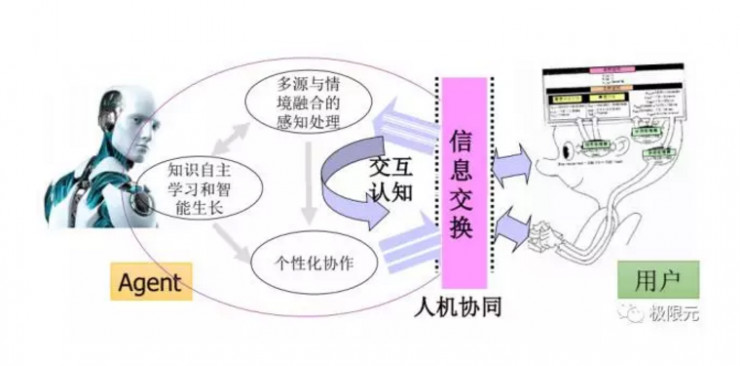
除了前面提到語音作爲主要接口的一種對話形式,我們也會考慮一些多模態相關的信息,比如對於用戶和機器人,當中有一個人機交換屬於人機協同,但是需要處理的信息會比較多,比如機器人會根據用戶輸出個性化聲音,同時融合多元情感融合的處理,機器人會根據你輸入的信息進行自主學習以及智能生長,這些都是將來人機交互這塊需要考慮的問題。
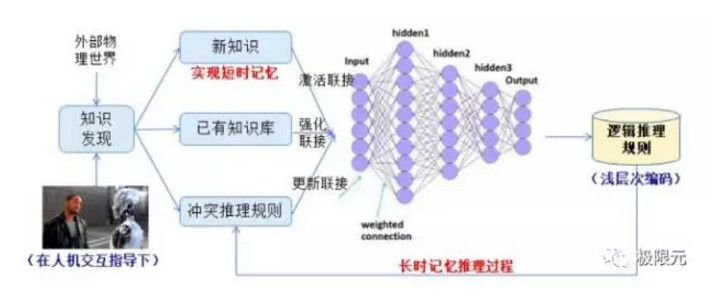
基於交互學習的知識問答和智能生長,目前最主要基於短時工作記憶,未來主要工作可能轉換到長時記憶的轉換,同時我們也能對新知識進行快速的學習和更新。
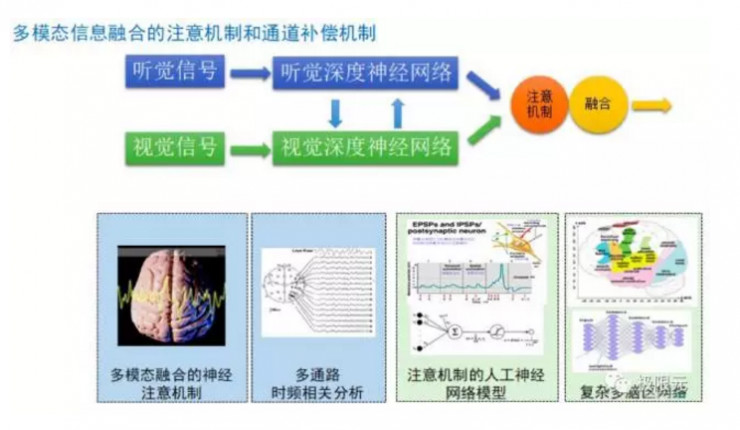
我們考慮的信息除了聽覺信息還有視覺信息,通過多模態融合的方法,我們也會研究在腦部這些腦區功能的一些主要關注點,這些都會成爲將來的研究點。對話平臺有了前面的多模態的信息輸入,我們希望把這些都融合起來做成一個多模態融合的一個對話系統。
語音作爲互聯網的重要入口,功能得到了大家越來越多的重視,當然語音產業也需要更多的人才去發展,目前對話系統的功能在體驗上有些不理想,這也是行業從業者需要考慮的問題,同時我們在將來會研究採用多模態智能生長等相關交互技術,促進人機交互的發展。
相關文章:
專訪阿里 iDST 語音組總監鄢志傑:智能語音交互從技術到產品,有哪些坑和細節要注意?