雷鋒網(公衆號:雷鋒網)按:本文作者鄔書哲, 中科院計算所智能信息處理重點實驗室VIPL課題組博士生,研究方向:目標檢測,尤其關注基於深度學習的目標檢測方法。
本文分上下兩篇,上篇主要介紹人臉檢測的基本流程,以及傳統的VJ人臉檢測器及其改進,下篇介紹基於深度網絡的檢測器,以及對目前人臉檢測技術發展的思考與討論。爲了讓本文更適合非計算機視覺和機器學習背景的讀者,文中對所涉及到的專業術語儘量以通俗的語言和用舉例的方式來進行解釋,同時力求嚴謹,以體現實事求是和一絲不苟的科學研究精神。
這是一個看臉的世界!自拍,我們要藝術美顏;出門,我麼要靚麗美妝。上班,我們要刷臉簽到;回家,我們要看臉相親。 當手機把你的臉變得美若天仙,當考勤機認出你的臉對你表示歡迎,你知道是什麼魔力讓冷冰冰的機器也變得溫情脈脈,讓呆呆的設備也變得善解人意嗎?今天就讓我們走近它們的內心,瞭解這些故事背後的一項關鍵技術:人臉檢測。
看人先看臉,走在大街上,我們可以毫不費勁地看到所有人的臉:棱角分明的國字臉,嬌小可人的瓜子臉,擦肩而過路人甲的臉,迎面走來明星乙的臉,戴着口罩被遮住的臉,斜向上45度仰角自拍的臉。可是,對於我們的計算機和各種終端設備而言,從眼前的畫面中把人臉給找出來,並不是一件容易的事情,原因就在於,一千個讀者就有一千個哈姆雷特,在你的眼裏,人臉是這樣的:

而在機器的眼裏,人臉是這樣的:

你沒看錯,圖像存儲在機器中不過就是一個由0和1組成的二進制串!更確切地說,機器看到的是圖像上每一個點的顏色值,因此對於機器來說,一張圖像就是一個由數排成的陣列。試想一下,如果我把每個點的顏色值都念給你聽,你能告訴我對應的這張圖像上有沒有人臉和人臉在哪裏嗎?很顯然,這並不是一個容易解決的問題。
如果手機沒法在自拍照中找到我們臉,那它就像一個失明的化妝師,沒法展現出我們最好的一面;如果考勤機沒法通過攝像頭看到我們的臉,那我們的笑就只是自作多情,它也根本不可能識別出我們到底是誰。人臉檢測架起了機器和我們之間溝通的橋樑,使得它能夠知道我們的身份(人臉識別),讀懂我們的表情(表情識別),和我們一起歡笑(人臉動畫),與我們一起互動(人機交互)。
人臉檢測的開始和基本流程
具體來說,人臉檢測的任務就是判斷給定的圖像上是否存在人臉,如果人臉存在,就給出全部人臉所處的位置及其大小。由於人臉檢測在實際應用中的重要意義,早在上世紀70年代就已經有人開始研究,然而受當時落後的技術條件和有限的需求所影響,直到上世紀90年代,人臉檢測技術纔開始加快向前發展的腳步,在新世紀到來前的最後十年間,涌現出了大量關於人臉檢測的研究工作,這時期設計的很多人臉檢測器已經有了現代人臉檢測技術的影子,例如可變形模板的設計(將人臉按照五官和輪廓劃分成多個相互連接的局部塊)、神經網絡的引入(作爲判斷輸入是否爲人臉的分類模型)等。這些早期的工作主要關注於檢測正面的人臉,基於簡單的底層特徵如物體邊緣、圖像灰度值等來對圖像進行分析,結合關於人臉的先驗知識來設計模型和算法(如五官、膚色),並開始引入一些當時已有的的模式識別方法。
雖然早期關於人臉檢測的研究工作離實際應用的要求還有很遠,但其中進行檢測的流程已經和現代的人臉檢測方法沒有本質區別。給定一張輸入圖像,要完成人臉檢測這個任務,我們通常分成三步來進行:
1.選擇圖像上的某個(矩形)區域作爲一個觀察窗口;
2.在選定的窗口中提取一些特徵對其包含的圖像區域進行描述;
3.根據特徵描述來判斷這個窗口是不是正好框住了一張人臉。
檢測人臉的過程就是不斷地執行上面三步,直到遍歷所有需要觀察的窗口。如果所有的窗口都被判斷爲不包含人臉,那麼就認爲所給的圖像上不存在人臉,否則就根據判斷爲包含人臉的窗口來給出人臉所在的位置及其大小。
那麼,如何來選擇我們要觀察的窗口呢?所謂眼見爲實,要判斷圖像上的某個位置是不是一張人臉,必須要觀察了這個位置之後才知道,因此,選擇的窗口應該覆蓋圖像上的所有位置。顯然,最直接的方式就是讓觀察的窗口在圖像上從左至右、從上往下一步一步地滑動,從圖像的左上角滑動到右下角——這就是所謂的滑動窗口範式,你可以將它想象成是福爾摩斯(檢測器)在拿着放大鏡(觀察窗口)仔細觀察案發現場(輸入圖像)每一個角落(滑動)的過程。
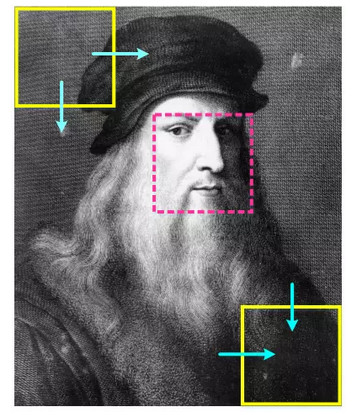
別看這種用窗口在圖像上進行掃描的方式非常簡單粗暴,它的確是一種有效而可靠的窗口選擇方法,以至於直到今天,滑動窗口範式仍然被很多人臉檢測方法所採用,而非滑動窗口式的檢測方法本質上仍然沒有擺脫對圖像進行密集掃描的過程。
對於觀察窗口,還有一個重要的問題就是:窗口應該多大?我們認爲一個窗口是一個人臉窗口當且僅當其恰好框住了一張人臉,即窗口的大小和人臉的大小是一致的,窗口基本貼合人臉的外輪廓。

那麼問題來了,即使是同一張圖像上,人臉的大小不僅不固定,而且可以是任意的,這樣怎麼才能讓觀察窗口適應不同大小的人臉呢?一種做法當然是採用多種不同大小的窗口,分別去掃描圖像,但是這種做法並不高效。換一個角度來看,其實也可以將圖像縮放到不同的大小,然後用相同大小的窗口去掃描——這就是所謂的構造圖像金字塔的方式。圖像金字塔這一名字非常生動形象,將縮放成不同大小的圖像按照從大到小的順序依次往上堆疊,正好就組成了一個金字塔的形狀。
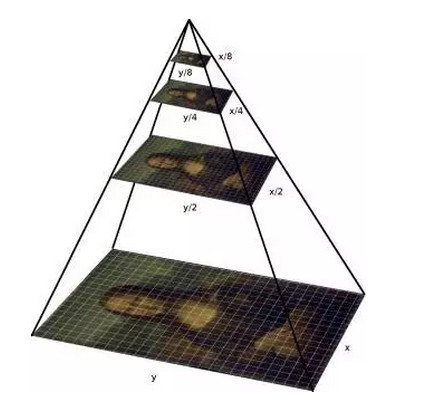
通過構建圖像金字塔,同時允許窗口和人臉的貼合程度在小範圍內變動,我們就能夠檢測到不同位置、不同大小的人臉了。另外需要一提的是,對於人臉而言,我們通常只用正方形的觀察窗口,因此就不需要考慮窗口的長寬比問題了。
選好了窗口,我們開始對窗口中的圖像區域進行觀察,目的是收集證據——真相只有一個,我們要依靠證據來挖掘真相!在處理圖像的過程中,這個收集證據的環節我們稱之爲特徵提取,特徵就是我們對圖像內容的描述。由於機器看到的只是一堆數值,能夠處理的也只有數值,因此對於圖像所提取的特徵具體表示出來就是一個向量,稱之爲特徵向量,其每一維是一個數值,這個數值是根據輸入(圖像區域)經由某些計算(觀察)得到的,例如進行求和、相減、比較大小等。總而言之,特徵提取過程就是從原始的輸入數據(圖像區域顏色值排列組成的矩陣)變換到對應的特徵向量的過程,特徵向量就是我們後續用來分析和尋找真相的證據。
特徵提取之後,就到了決斷的時刻:判別當前的窗口是否恰好包含一張人臉。我們將所有的窗口劃分爲兩類,一類是恰好包含人臉的窗口,稱之爲人臉窗口,剩下的都歸爲第二類,稱之爲非人臉窗口,而最終判別的過程就是一個對當前觀察窗口進行分類的過程。因爲我們的證據是由數值組成的特徵向量,所以我們是通過可計算的數學模型來尋找真相的,用來處理分類問題的數學模型我們通常稱之爲分類器,分類器以特徵向量作爲輸入,通過一系列數學計算,以類別作爲輸出——每個類別會對應到一個數值編碼,稱之爲這個類別對應的標籤,如將人臉窗口這一類編碼爲1,而非人臉窗口這一類編碼爲-1;分類器就是一個將特徵向量變換到類別標籤的函數。
考慮一個最簡單的分類器:將特徵向量每一維上的數值相加,如果得到的和超過某個數值,就輸出人臉窗口的類別標籤1,否則輸出非人臉窗口的類別標籤-1。記特徵向量爲,
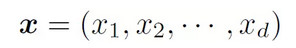
分類器爲函數f(x),那麼有:
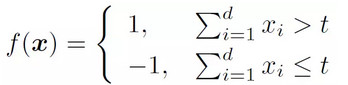
這裏的t就是前面所說的「某個數值」,其決定了分類器在給定特徵向量下的輸出結果,我們稱其爲分類器的參數。不同形式和類型的分類器會有不同的參數,一個分類器可以有一個或者多個參數,參數或者其取值不同則對應到不同的分類器。選定了一個分類器之後,緊接着的一個問題就是:參數該怎麼設置?具體到我們正在考慮的情況,就是:t的值該如何選取?
要做出選擇,就要有一個目標,在分類問題中,目標當然就是儘可能正確地進行分類,即分類的準確率儘可能高。然而,儘管我們對目標非常明確,我們也仍然沒法給出一個最優的參數取值,因爲我們並不使用機器所採用的二進制語言系統,我們並不懂什麼纔是對機器最好的。於是我們只有一種選擇:把我們的目標告訴機器,舉一些例子向其進行解釋,然後讓機器自己去學習這個參數,最後我們給機器設計一場考試,測試其是否滿足了我們的要求。我們從一些圖像上選出一部分人臉和非人臉窗口的樣例,用對應的類別標籤對其進行標註,然後將這些樣例劃分成兩個集合,一個集合作爲分類器學習所使用的訓練集,另一個集合作爲最終考查分類器能力的測試集,同時我們設定一個目標:希望分類的準確率能夠在80%以上。
學習過程開始時,我們先給分類器的參數設定一個初始值,然後讓分類器通過訓練集中帶有「答案」(類別標籤)的樣例,不斷去調整自己參數的取值,以縮小其實際的分類準確率和目標準確率之間的差距。當分類器已經達到了預先設定的目標或者其它停止學習的條件——期末考試的時間是不會因爲你沒有學好而推遲的,或者分類器覺得自己已經沒有辦法再調整了,學習過程就停止了,這之後我們可以考查分類器在測試集上的準確率,以此作爲我們評判分類器的依據。這一過程中,分類器調整自己參數的方式和分類器的類型、設定的目標等都有關,由於這部分內容超出了本文所討論的範疇,也並不影響讀者對人臉檢測方法的理解,因此不再展開進行講述。
在確定了選擇窗口的策略,設計好了提取特徵的方式,並學習了一個針對人臉和非人臉窗口的分類器之後,我們就獲得了構建一個人臉檢測系統所需要的全部關鍵要素——還有一些小的環節相比之下沒有那麼重要,這裏暫且略去。
由於採用滑動窗口的方式需要在不同大小的圖像上的每一個位置進行人臉和非人臉窗口的判別,而對於一張大小僅爲480*320的輸入圖像,窗口總數就已經高達數十萬,面對如此龐大的輸入規模,如果對單個窗口進行特徵提取和分類的速度不夠快,就很容易使得整個檢測過程產生巨大的時間開銷,也確實就因爲如此,早期所設計的人臉檢測器處理速度都非常慢,一張圖像甚至需要耗費數秒才能處理完成——視頻的播放速度通常爲每秒25幀圖像,這給人臉檢測投入現實應用帶來了嚴重的障礙。
人臉檢測技術的突破:VJ人臉檢測器及其發展
人臉檢測技術的突破發生在2001年,兩位傑出的科研工作者Paul Viola和Michael Jones設計了出了一個快速而準確的人臉檢測器:在獲得相同甚至更好準確度的同時,速度提升了幾十上百倍——在當時的硬件條件下達到了每秒處理15張圖像的速度,已經接近實時速度25fps(即25幀每秒)。這不僅是人臉檢測技術發展的一個里程碑,也標誌着計算機視覺領域的研究成果開始具備投入實際應用的能力。爲了紀念這一工作,人們將這個人臉檢測器用兩位科研工作者的名字命名,稱之爲Viola-Jones人臉檢測器,或者簡稱爲VJ人臉檢測器。
VJ人臉檢測之所以器能夠獲得成功,極大地提高人臉檢測速度,其中有三個關鍵要素:特徵的快速計算方法——積分圖,有效的分類器學習方法——AdaBoost,以及高效的分類策略——級聯結構的設計。VJ人臉檢測器採用Haar特徵來描述每個窗口,所謂Haar特徵,其實就是在窗口的某個位置取一個矩形的小塊,然後將這個矩形小塊劃分爲黑色和白色兩部分,並分別對兩部分所覆蓋的像素點(圖像上的每個點稱爲一個像素)的灰度值求和,最後用白色部分像素點灰度值的和減去黑色部分像素點灰度值的和,得到一個Haar特徵的值。
Haar特徵反映了局部區域之間的相對明暗關係,能夠爲人臉和非人臉的區分提供有效的信息,例如眼睛區域比周圍的皮膚區域要暗,通過Haar特徵就可以將這一特點表示出來。但是由於提取Haar特徵時每次都需要計算局部區域內多個像素點灰度值之和,因此在速度上其並不快,爲此VJ人臉檢測器引入了積分圖來加速Haar特徵的提取。
積分圖是一張和輸入圖像一樣大的圖,但其每個點上不再是存放這個點的灰度值,而是存放從圖像左上角到該點所確定的矩形區域內全部點的灰度值之和。
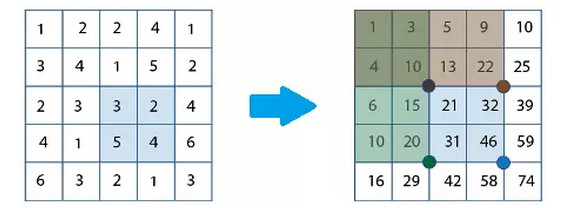
積分圖所帶來的好處是兩方面的,一方面它使得每次計算局部區域像素點的灰度值之和僅需要做4次加減法,與局部區域的大小無關;另一方面它避免了在相同像素點上重複求和,只在最開始計算一次——相鄰的窗口有很大的重疊部分,對應的Haar特徵也會重疊,如果每次都重新計算像素點的灰度值之和,則重疊部分的計算是重複的。積分圖極大地加速了Haar特徵的提取,向快速的檢測器邁出了第一步。
除了特徵提取,分類過程的速度對於檢測的速度也至關重要。分類的速度取決於分類器的複雜程度,也即從特徵向量變換到類別標籤的計算過程的複雜程度。複雜的分類器往往具有更強的分類能力,能夠獲得更好的分類準確度,但是分類時的計算代價比較高,而簡單的分類器雖然計算代價小,但是分類準確度也較低。那麼有沒有兼顧計算代價和分類準確度兩方面的辦法呢?當然有,這就是AdaBoost方法。希望計算代價小,所以只用簡單的分類器,但是又希望分類準確度高,於是把多個簡單的分類器組合起來——聚弱爲強,將多個弱分類器組合成一個強分類器,這就是AdaBoost方法的核心理念。通過AdaBoost方法來學習分類器,達到了以更小的計算代價換取同樣的分類準確度的目的。
造成人臉檢測速度慢的根本原因還在於輸入規模過大,動輒需要處理幾十上百萬的窗口,如果這樣的輸入規模是不可避免的,那麼有沒有可能在處理的過程中儘快降低輸入規模呢?如果能夠通過粗略地觀察快速排除掉大部分窗口,只剩下少部分窗口需要進行仔細的判別,則總體的時間開銷也會極大地降低。從這樣的想法出發,VJ人臉檢測器採用了一種級聯結構來達到逐步降低輸入規模的目的。
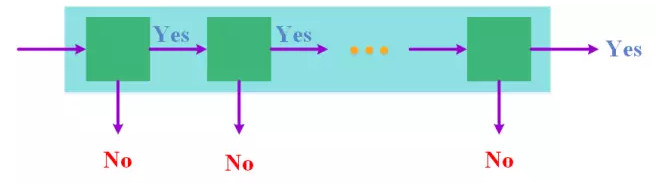
具體說來,VJ人臉檢測器將多個分類器級聯在一起,從前往後,分類器的複雜程度和計算代價逐漸增大,對於給定的一個窗口,先由排在最前面也最簡單的分類器對其進行分類,如果這個窗口被分爲非人臉窗口,那麼就不再送到後面的分類器進行分類,直接排除,否則就送到下一級分類器繼續進行判別,直到其被排除,或者被所有的分類器都分爲人臉窗口。這樣設計的好處是顯而易見的,每經過一級分類器,下一級分類器所需要判別的窗口就會減少,使得只需要付出非常少的計算代價就能夠排除大部分非人臉窗口。從另一個角度來看,這實際上也是根據一個窗口分類的難度動態地調整了分類器的複雜程度,這顯然比所有的窗口都用一樣的分類器要更加高效。
VJ人臉檢測器通過積分圖、AdaBoost方法和級聯結構取得的巨大成功對後續的人臉檢測技術研究產生了深遠的影響,大量的科研工作者開始基於VJ人臉檢測器進行改進,這些改進也分別覆蓋了VJ人臉檢測器的三個關鍵要素。
特徵的改進和變遷
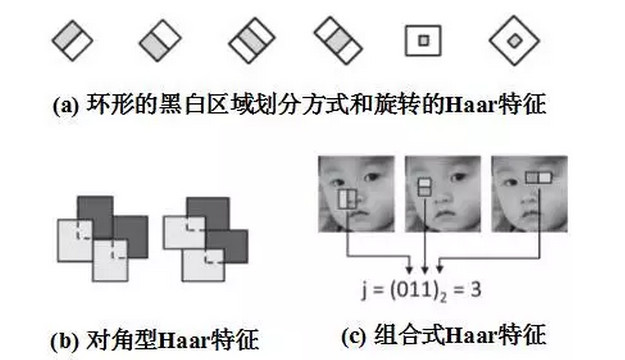
雖然Haar特徵已經能夠刻畫人臉的一些特點,但是相比於人臉複雜的變化模式,VJ人臉檢測器所採用的5種Haar特徵還是過於簡單。光考慮姿態上的變化,人臉可能是斜着的(平面內旋轉),也可能是仰着的或者側着的(平面外旋轉),同一個Haar特徵在不同姿態的人臉上差異可能非常大,而同時又可能和非人臉區域上的特徵更相近,這就很容易在分類的時候引起誤判。於是人們開始對Haar特徵進行擴展,使得其能夠刻畫更加豐富的變化模式:
1. 環形的黑白區域劃分模式,而不僅僅是上下或者左右型;
2. 旋轉的Haar的特徵,即將原來提取Haar特徵的局部小塊順時針或逆時針旋轉45度;
3. 分離的Haar特徵,即允許一個Haar特徵由多個互相分離的黑白區域來計算,而不要求黑白區域必須處於一個矩形小塊中;
4. 對角型Haar特徵;
5. 組合Haar特徵,即對多個不同的Haar特徵進行組合和二值編碼;
6. 局部組合二值特徵,即在局部對特定的Haar特徵按照一定的結構進行組合和二值編碼;
7. 帶權多通道Haar特徵,即一個Haar特徵不再只包含黑白兩種塊,而允許有多種不同形狀和不同顏色的塊,其中不同的顏色對應着不同的權值,表示像素點上求和之後所佔的比重——原來只有1和-1兩種,多通道指的是在像素點上求和不僅僅是在灰度這一個通道上計算,而是同時在其它通道上計算(如RGB三個顏色通道;事實上,基於原圖計算而來和原圖同樣大小的任何一張圖都可以是圖像的一個通道)。
這些擴展極大地增強了Haar特徵的表達能力,使得人臉窗口和非人臉窗口之間具有更好的區分性,從而提高了分類的準確度。
除了直接對Haar特徵進行改進,人們也同時在設計和嘗試其它特徵。Haar特徵本質上是局部區域像素值的一種線性組合,其相對應的更一般的形式則是不指定線性組合的係數,允許係數爲任意實數,這被稱之爲線性特徵——這裏的組合係數可以基於訓練樣例來進行學習,類似於學習分類器參數的過程。稀疏粒度特徵也是一種基於線性組合來構造的特徵,與線性特徵所不同的是,稀疏粒度特徵是將不同尺度(將100*100的圖像放大到200*200,它和原本大小就爲200*200的圖像是處於不同的尺度上)、位置和大小的局部區域進行組合,而線性特徵只是組合同一個局部區域內的像素值。
LBP特徵是一種二值編碼特徵,其直接基於像素灰度值進行計算,特點是在編碼時考慮的是兩個值的相對大小,並且按照一定的空間結構來進行編碼,局部組合二值特徵就是在LBP特徵的啓發下設計的;從計算上來看,提取LBP特徵比提取Haar特徵要快,但是Haar特徵對於人臉和非人臉窗口的區分能力更勝一籌。簡化的SURF特徵是一種和Haar特徵相類似的特徵,但是其計算的是局部區域中像素點的梯度和,並在求和的過程中考慮了梯度方向(所謂梯度,最簡單的一種情形就是指同一行上兩個不同位置像素值的差比上它們水平座標的差);SURF特徵比Haar特徵更爲複雜,因此計算代價更高,但是由於其表達能力更強,因此能夠以更少數目的特徵來達到相同的區分度,在一定程度上彌補了其在速度上的不足。HOG特徵也是一種基於梯度的特徵,其對一個局部區域內不同方向的梯度進行統計,計算梯度直方圖來表示這個區域。積分通道特徵和多通道的Haar特徵有些類似,但是其使用的通道更加多樣化,將通道的概念推廣爲由原圖像變換而來並且空間結構和原圖像對應的任何圖像。聚合通道特徵則在積分通道特徵的基礎上進一步加入了對每個通道進行下采樣的操作,實現局部區域信息的聚合。
在過去十幾年的探索過程中,涌現出的特徵不勝枚舉,這裏只選取了部分比較有代表性和反映了人們探索思路的特徵進行舉例。這裏所有列舉的特徵都有一個共同的特點:都由科研工作者根據自己的經驗手工設計,這些特徵的設計反映了人們對問題的理解和思考。雖然隨着不斷的改進,設計出的特徵已經日臻完善,但直到現在,人們在特徵上的探索還遠沒有結束。
分類器及其學習方法的改進
分類器能力的強弱直接決定了分類準確度的高低,而分類的計算代價是影響檢測速度的一個關鍵因素,因此,人們探索的另一個方向就是對分類器及其學習方法的改進。
採用AdaBoost方法由弱分類器構建強分類器,這是一個順序執行的過程,換言之,一旦一個弱分類器被選中,其就必定會成爲強分類器的組成部分,不允許反悔,這其實是假設增加弱分類器一定會使得強分類器的分類準確度更高,但是,這個假設並不總是成立。事實上,每次對弱分類器的選擇只是依照當時的情況決定,而隨着新的弱分類器被增加進來,從整體上來看,之前的選擇未必最優。基於這樣的想法,出現了允許回溯的FloatBoost方法。FloatBoost方法在選擇新的弱分類器的同時,也會重新考查原有的弱分類器,如果去掉某個弱分類器之後強分類器的分類準確度得到了提升,那說明這個弱分類器帶來了負面影響,應該被剔除。
VJ人臉檢測器中,相級聯的多個分類器在學習的過程中並不會產生直接的聯繫,其關聯僅體現在訓練樣例上:後一級分類器的訓練樣例一定要先通過前一級分類器。不同分類器在學習時的獨立性會帶來兩方面的壞處:一是在每個分類器都是從頭開始學習,不能借鑑之前已經學習好的分類器的經驗;二是每個分類器在分類時都只能依靠自己,不能利用其它分類器已經獲得的信息。爲此,出現了兩種改進的方案:鏈式Boosting方法和嵌套式Boosting方法。兩種方案都在學習新一級的分類器時,都考慮之前已經學好的分類器,區別在於鏈式Boosting方法直接將前面各級分類器的輸出進行累加,作爲基礎得分,新分類器的輸出則作爲附加得分,換言之,前面各級分類器實際上是新分類器的一個「前綴」,所有的分類器通過這種方式鏈在了一起;嵌套式Boosting方法則直接將前一級分類器的輸出作爲新分類器第一個弱分類器的特徵,形成一種嵌套的關係,其特點是隻有相鄰的分類器纔會互相影響。還有一種和嵌套式Boosting方法相類似的方案:特徵繼承,即從特徵而不是分類器的角度來關聯不同的分類器,具體而言,新的分類器在學習時會先繼承前一級分類器的所有特徵,基於這些特徵學習弱分類器,再此基礎上再考慮增加新的弱分類器,這一方案的特點在於其只引入了分類器學習時的相互影響,而在分類時分類器之間仍然是相互獨立的。
相關的任務之間往往會相互產生促進作用,相輔相成,而和人臉檢測密切相關的一個任務就是特徵點定位:預測臉部關鍵點的位置,這些關鍵點可以是雙眼中心、鼻尖、嘴角等。基於這樣一種想法,在2014年出現了Joint Cascade,即把檢測人臉所需要的分類器和預測特徵點位置的迴歸器交替級聯,同時進行人臉檢測和特徵點定位兩個任務。用特徵點定位輔助人臉檢測的關鍵在於形狀索引特徵的引入,即特徵不再是在整個窗口中提取,而是在以各個特徵點爲中心的局部區域進行提取,這樣的好處就在於提高了特徵的語義一致性。不同的人臉其對應的特徵點位置是不同的,反過來看,也就是說相同的位置實際上對應於臉部的不同區域,那麼在相同區域提取的特徵實際上表示的是不同的語義,簡單地說,就是在拿鼻子去和嘴巴匹配。採用形狀索引特徵可以很好地避免這個問題,從而增大人臉和非人臉窗口之間的區分性。對於一個給定的窗口,我們並不知道特徵點的位置,因此採用一個「平均位置」作爲初始位置,即基於標註有特徵點座標的人臉樣例集,計算出的每個點座標的平均值;在平均位置的基礎上,我們提取特徵預測各個特徵點真實的位置,不過一次預測往往是不準確的,就好像跑步的時候我們沒法直接從起點跳到終點一樣,所以需要不斷基於當前確定的特徵點位置來預測新的位置,逐步向其真實的位置靠近。這個過程很自然地形成了一種級聯結構,從而能夠和人臉檢測器耦合在一起,形成一種不同模型交替級聯的形式。
針對分類器學習過程中的每一個環節,人們都進行了細緻而充分的探索,除了上面提到的幾個方向,在分類器分類閾值的學習、提升分類器學習的速度等問題上,也出現了很多出色的研究工作。大部分在分類器及其學習方法上進行改進的工作關注的還是Boosting方法(AdaBoost方法是Boosting方法的一個傑出代表)和相對簡單的分類器形式,如果能夠引入具有更強分類能力的分類器,相信能給檢測器帶來進一步的性能提升,這一點在後文會有所涉及。
級聯結構的演化
分類器的組織結構也是人們關心的一個重要問題,尤其是在面臨多姿態人臉檢測任務的時候。人臉的姿態是指人臉在三維空間中繞三個座標軸旋轉的角度,而多姿態人臉檢測就是要將帶旋轉的人臉給檢測出來,不管是斜着的(繞x軸旋轉)、仰着的(繞y軸旋轉)還是側着的(繞z軸旋轉)。不同姿態的人臉在表觀特徵上存在很大的差異,這給檢測器帶來了非常大的挑戰,爲了解決這一問題,通常採用分治的策略,即分別針對不同姿態的人臉單獨訓練分類器,然後組合起來構建成多姿態人臉檢測器。
最簡單的多姿態人臉檢測器就是將針對不同姿態人臉的分類器採用並列式的結構進行組織,其中並列的每一個分類器仍然採用原來的級聯結構(我們稱這種分類器爲級聯分類器);在檢測人臉的過程中,一個窗口如果被其中一個級聯分類器分爲人臉窗口,則認爲其確實是一個人臉窗口,而只有當每一個級聯分類器都將其判別爲非人臉窗口時,纔將其排除掉。這種並列式的組織架構存在兩方面的缺陷:一是造成了檢測時間的成倍增長,因爲絕大部分窗口是非人臉窗口,這些窗口需要經過每一個級聯分類器的排除;二是容易造成整體分類準確度的降低,因爲整個檢測器分錯的窗口包含的是所有級聯分類器分錯的窗口。
有人設計了一種金字塔式的級聯結構,金字塔的每一層對應於對人臉姿態(旋轉角度)的一個劃分,從頂層到底層劃分越來越細,級聯的每個分類器只負責區分非人臉和某個角度範圍內的人臉。對於一個待分類的窗口,從最頂層的分類器開始對其進行分類,如果其被分爲人臉窗口,則送入到下一層的第一個分類器繼續進行分類,如果其被分爲非人臉窗口,則送入到同一層的下一個分類器繼續進行分類,當在某一層上所有的分類器都將其分爲非人臉窗口時,就確認其爲非人臉窗口,將其排除。金字塔式的級聯結構也可以看成是一種特殊的並列式結構,只不過每個級聯分類器相互之間有共享的部分,這樣最直接的好處就在於減少了計算量,共享的部分只需要計算一次,同時在底層又保留了分治策略所帶來的好處——子問題比原問題更加容易,因此更容易學習到分類準確度更高的分類器。
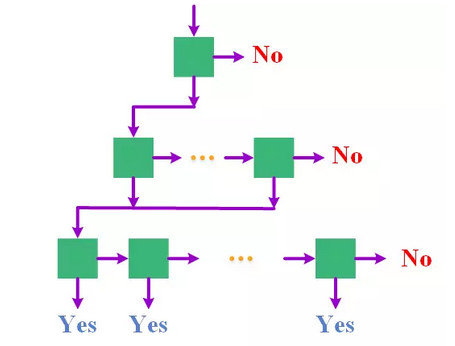
還有一種比較典型的結構是樹形的級聯結構,從形狀上來看其和金字塔式的級聯結構是一樣的,也是從上往下分類器的數目逐層增多,區別就在於樹形的級聯結構中沒有同一層分類器之間的橫向連接,只有相鄰層分類器之間的縱向連接,即一個窗口在同一層上不會由多個分類器進行分類,而會直接被送往下一層或者被排除。樹形級聯結構通過引入分支跳轉機制,進一步減少了對一個窗口進行分類所需要的計算量,不過同時也帶來了新的問題,分支跳轉通常根據姿態估計(估計旋轉角度的範圍)的結果來進行,而如果姿態估計出現錯誤,就會出現某個姿態的人臉窗口被送給另一個姿態人臉對應的分類器進行分類的情況,容易導致錯誤的分類。爲了緩解這一問題,出現了允許多個分支同時跳轉的設計,從而降低了由於跳轉錯誤而引起分類錯誤的風險。
分治策略是處理多姿態人臉檢測任務最基本的策略,但要同時兼顧速度和分類準確度並不是一件容易的事情,分類能力的增強不可避免地會帶來計算代價的增大,如何用更小的計算代價來換取更高的分類準確度,這仍然是一個需要去思考和探索的問題。
人臉檢測器的比拼
在不斷對人臉檢測器進行改進的過程中,有一個問題是不容忽視的:如何科學地比較兩個人臉檢測器的優劣?簡單地說,出一套考題讓所有的檢測器進行一場考試,誰得分高誰就更好。對於人臉檢測器而言,所謂考題(測試集)就是一個圖像集合,通常其中每張圖像上都包含至少一張人臉,並且這些人臉的位置和大小都已經標註好。關於得分,需要考慮檢測器兩方面的表現,一是檢測率,也即對人臉的召回率,檢測出來的人臉佔總人臉的比例——測試集中一共標註了100張人臉,檢測器檢測出其中70張人臉,則檢測率爲70%;二是誤檢(也稱爲虛警)數目,即檢測器檢測出來的人臉中出現錯誤(實際上不是人臉)的數目——檢測器一共檢測出80張人臉,然而其中有10個錯誤,只有70個是真正的人臉,那麼誤檢數目就是10。在這兩個指標上,我們所希望的總是檢測率儘可能高,而誤檢數目儘可能少,但這兩個目標之間一般是存在衝突的;在極端的情況下,如果一張臉也沒有檢測出來,那麼誤檢數目爲0,但是檢測率也爲0,而如果把所有的窗口都判別爲人臉窗口,那麼檢測率爲100%,而誤檢數目也達到了最大。在比較兩個檢測器的時候,我們通常固定一個指標,然後對比另一個指標,要麼看相同誤檢數目時誰的檢測率高,要麼看相同檢測率時誰的誤檢少。
對於每一個檢測出的人臉,檢測器都會給出這個檢測結果的得分(或者說信度),那麼如果人爲地引入一個閾值來對檢測結果進行篩選(只保留得分大於閾值得檢測結果),那麼隨着這個閾值的變化,最終得檢測結果也會不同,因而其對應得檢測率和誤檢數目通常也會不同。通過變換閾值,我們就能夠得到多組檢測率和誤檢數目的值,由此我們可以在平面直角座標系中畫出一條曲線來:以x座標表示誤檢數目,以y座標表示檢測率,這樣畫出來的曲線稱之爲ROC曲線(不同地方中文譯法不一,如接收機曲線、接收者操作特徵曲線等,這裏直接採用英文簡寫)。ROC曲線提供了一種非常直觀的比較不同人臉檢測器的方式,得到了廣泛的使用。
評測人臉檢測器時還有一個重要的問題:怎麼根據對人臉的標註和檢測結果來判斷某張人臉是否被檢測到了?一般來說,檢測器給出的檢測框(即人臉窗口)不會和標註的人臉邊框完全一致,而且對人臉的標註也不一定是矩形,例如還可能是橢圓形;因此當給定了一個檢測框和一個標註框時,我們還需要一個指標來界定檢測框是否和標註框相匹配,這個指標就是交併比:兩者交集(重疊部分)所覆蓋的面積佔兩者並集所覆蓋面積的比例,一般情況下,當檢測框和標註框的交併比大於0.5時,我們認爲這個檢測框是一個正確檢測的人臉。
在早期的人臉檢測工作中,一般採用MIT-CMU人臉檢測數據集作爲人臉檢測器的測試集,來比較不同的檢測器。這個測試集只包含幾百張帶有人臉的圖像,並且人臉主要是清晰且不帶遮擋的正面人臉,因而是一個相對簡單的測試集,現在幾乎已經不再使用。在2010年,美國麻省大學的一個實驗室推出了一個新的人臉檢測評測數據集:FDDB,這個集合共包含2845張帶有人臉的互聯網新聞圖像,一共標註了5171張人臉,其中的人臉在姿態、表情、光照、清晰度、分辨率、遮擋程度等各個方面都存在非常大的多樣性,貼近真實的應用場景,因而是一個非常具有挑戰性的測試集。FDDB的推出激發人們在人臉檢測任務上的研究熱情,極大地促進了人臉檢測技術的發展,在此後的幾年間,新的人臉檢測方法不斷涌現,檢測器在FDDB上的表現穩步提高。從100個誤檢時的檢測率來看,從最初VJ人臉檢測器的30%,發展到現在已經超過了90%——這意味着檢測器每檢測出50張人臉纔會產生一個誤檢,這其中的進步是非常驚人的,而檢測器之間的比拼還在繼續。
雷鋒網注:本文由作者發佈於深度學習大講堂,轉載請聯繫授權並保留出處和作者,不得刪減內容。
