雷鋒網按:2017 年 4 月 21-23 日,VALSE(視覺與學習青年學者研討會)在廈門舉行,國內 CV 領域頂級專家學者齊聚一堂,參會的青年學者達 2000 多人。在 VALSE 的「年度進展評述」環節,共有 12 名學者依次上臺,對 CV 研究和應用分支領域近年發展做了詳細系統的梳理,堪稱「12 顆重磅炸彈」。針對近年來 CV 領域火熱的方向之一:GAN,哈爾濱工業大學計算機學院教授左旺孟從多方面做了詳盡的評述報告。

左旺孟,哈爾濱工業大學計算機學院教授、博士生導師。主要從事圖像增強與復原、距離度量學習、目標跟蹤、圖像與視頻分類等方面的研究。在 CVPR/ICCV/ECCV 等頂級會議和 T-PAMI、IJCV 及 IEEE Trans. 等期刊上發表論文 50 餘篇。
以下爲報告全文,感謝左旺孟教授審校指正,雷鋒網(公衆號:雷鋒網)編輯。

生成對抗網絡是過去一年來得到很多關注的一個方向,裏面的內容比較龐雜。那麼我選擇了以下幾個角度,來概括過去幾年來 GAN 的發展脈絡。
圖像生成
關於 GAN 的三個問題:度量複雜分佈之間差異性、如何設計生成器、建立輸入和輸出之間的聯繫。
圖像生成
這裏嘗試給「圖像生成」一個大致定義:圖像生成的目的是,學習一個生成模型,能夠將來自於輸入分佈的一幅圖像或變量轉變成爲一幅輸出圖像。這裏,我們不僅要求「輸入」滿足一個輸入分佈,同樣,我們還要求「輸出」滿足一個預期的期望分佈。通過定義不同的輸入分佈和期望分佈,就對應着不同的圖像生成問題。

一開始,最標準的 GAN 的假設是,輸入要服從隨機噪聲分佈,期望分佈是所有的真實圖像。這個問題一開始定義得太大,所以雖然 GAN 在2014年就出現了,在2014年到2016年這段時間其實發展得並不快。
後來大家就去思考,輸入的分佈也可以不是隨機分佈,於是大家開始根據各種實際問題的需要來定義自己需要的輸入分佈和期望分佈。比如,輸入分佈可以是來自於所有斑馬的一幅圖像,輸出分佈是所有正常馬的圖像,這樣系統要學習的其實是這兩種圖像之間的映射(mapping)。

同樣,如果我們輸入的是一個低分辨率圖像,輸出的是一個高分辨率圖像,那麼希望系統學習到的是低分辨率和高分辨率之間的映射。去區塊(deblocking),輸入的是 JPEG 壓縮圖像,輸出的是真實高清圖像,我們也是希望學到兩者之間的映射。人臉領域也是一樣,比如我們做的超分辨和性別轉換。輸入是男性圖像,輸出是女性圖像,學習二者之間的映射。

另外一個有意思的是圖像文本描述的自動生成(Image captioning),輸入的是圖像,輸出的是句子。大家以前就認爲,這是一個一對一的映射,其實不是。它實際上是一對多的映射。不同的人來描述一幅圖,就會產生不同的語句。所以如果用 GAN 來做這件事情,應該是很有趣的,今年有幾篇投 ICCV 的文章做的就是這方面的工作。

關於GAN的三個問題
第一,度量複雜分佈之間差異性。我們希望輸出分佈達到期望分佈,那麼我們需要找兩個分佈之間差異的度量方式,這是我認爲在 GAN 裏面需要研究的第一個關鍵性問題。
第二,如何設計生成器。如果我們想要學習映射,就需要一個生成器,那麼就要對它的訓練、可學習性進行設計。這是 GAN 裏面另一個可以研究的角度。
第三,連接輸入和輸出。如下圖右邊性別轉換的例子,輸入是一張男性圖像,輸出是一張女性圖像。顯然我們需要的並不是從輸入到任意一幅女性人臉圖像的映射,二是要求輸出的女性圖像要跟輸入的男性圖像儘可能像,這個轉換纔是有意義的。所以,這就是 GAN 裏面另外一個重要的研究方向,就是如何將輸入和輸出連接起來。

下面針對這三個問題,進行詳細的講解。
如何度量兩個分佈之間的差異性
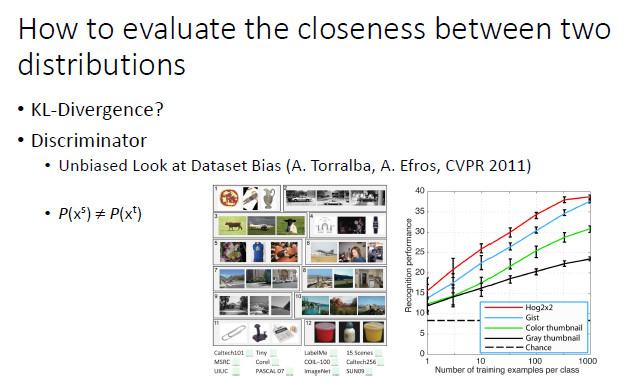
GAN 使用了一個分類器來度量輸出分佈和期望分佈的差異性。實際上,Torralba和Efros在 2011 年的時候也考慮過用一個分類器來分析兩個分佈之間差異,這也是當時做 domain adaption 的學者喜歡引用的一篇論文。他們設計了一個實驗,給你三張圖像,讓你猜是來自 12 個數據集(包括 ImageNet、COCO和PASCAL VOC等)中的那一個。如果是隨機猜的話,顯然猜中的概率是 1/12。但是人猜中的準確度往往能達到 30% 左右,說明不同數據集刻畫的分佈是不一致的。這裏人其實可視爲一個分類器,通過判斷樣本來自於那個數據集來分析兩個分佈之間差異。
雖然 NIPS 2014 年的這篇 GAN 論文沒有引用 Torralba 的工作,其實它也是採用了一個判別器來度量兩個分佈的差異化程度。基本的過程是,固定生成器,得到一個最好的判別器,再固定判別器,學到一個最好的生成器。但是其中有一個最令人擔心的問題,那就是如果我們學到的是一個很複雜的分佈,就會出現模式崩潰(Mode Collapse)的問題,即無法學習複雜分佈的全局,只能學習其中的一部分。

對此,最早的解決方案,是調整生成器(G)和判別器(D)的優化次序,但這也不是一個終極方案。從去年開始大家開始關注要去找到一個終極解決方案。
那之前,大家怎麼去解決這個問題呢?使用的是原來機器學習裏常用的方法:最大化均值差異(Maximum Mean Discrepancy,MMD)。
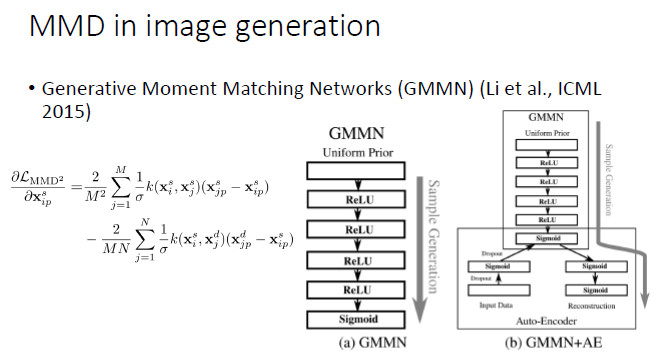
如果兩個分佈相同的話,那麼兩個分佈的數學期望顯然也應該相同;然而,如果兩個分佈的數學期望相同,並不能保證兩個分佈相同。因而,我們需要更好地建立「分佈相同」和「期望相同」之間的連接關係。幸運的是,我們可以對來自於兩個分佈的變量施加同樣的非線性變換。如果對於所有的非線性變換下兩個分佈的數學期望均相同(即:兩個分佈的期望的最大差別爲0),在統計學意義上就可以保證兩個分佈是相同的。不幸的是,這種方法需要我們遍歷所有的非線性變換,從實踐的角度似乎任由一定難度。一開始,在機器學習領域,大家傾向於用線性 kernel或Gaussian RBF kernel 來進行非線性變換,後來開始採用 multi-kernel。從去年開始,大家開始用 CNN 來近似所有的非線性變換,在 MMD 框架下進行圖像生成。首先,固定生成器並最大化 MMD,然後固定判別器裏 MMD 的 f,然後通過最小化 MMD 來更新生成器。
最常用的一種方法,就是拿 MMD 來代替判別器,去學習一個 CNN,這是 ICML 2015 的一篇文章中嘗試的方法,我們自己也在這個基礎上做了一些工作。
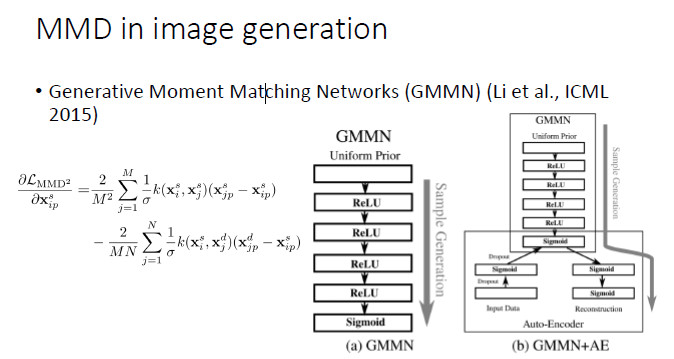
但實際上,如果直接拿 MMD 去替換生成器,雖然有一定效果,但不是特別成功。所以,從 NIPS 2016 開始,就出現了一個 Improved GAN,這個工作雖然沒有引用 MMD 的論文,但實際上在更新判別器的同時也最小化了 MMD。等到了 Wasserstein GAN 的時候,它就明確解釋了與 MMD 之間的聯繫,雖然論文裏寫的是一個「減」的關係,但我們看它的代碼,它也是要加上一個範數的,因爲只是讓兩個分佈的期望最大化或最小化都不能保證分佈的差異化程度最小。
然後,最近 ICLR 2017 的一篇論文也明確指出要用 MMD 來作爲 GAN 網絡的停止條件和學習效果的評價手段。

如何設計一個生成器
這個部分相對來說就比較容易一些。早期的時候,GAN 的一個最大的進步就是 DCGAN,用於圖像生成時,比較合適的選擇就是用全卷積網絡加上 batch normalizaiton。

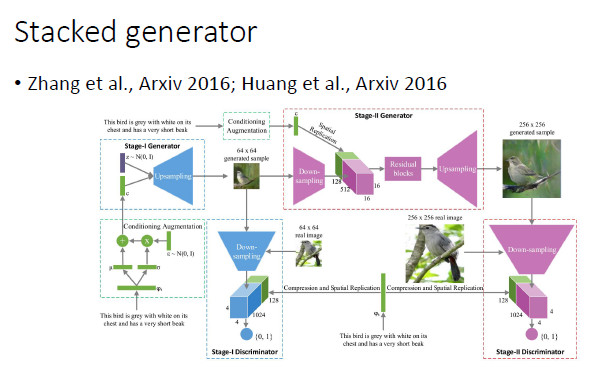
對於複雜的圖像生成,可以使用分階段的方式。比如,第一步可以生成小圖,然後由小圖生成大圖。沿着這個方向,香港中文大學王曉剛老師和康奈爾大學 John Hopcroft 都做了一些工作。
對於圖像增強(image enhancement)相關的一些任務,包括超分辨率和人臉屬性轉換(Face Attribute Transfer),目前在有監督時表現最好網絡是 ResNet ,所以我們在這些任務中實用GAN時一般也會採用 ResNet 結構。
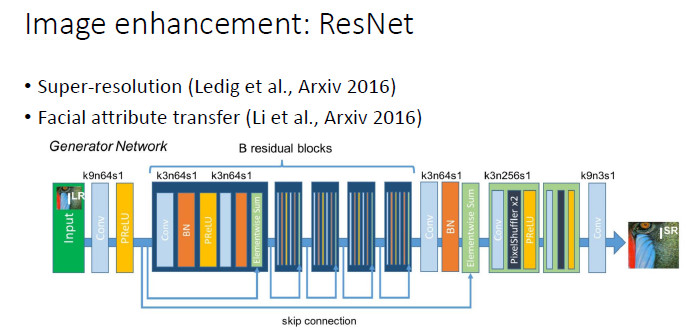
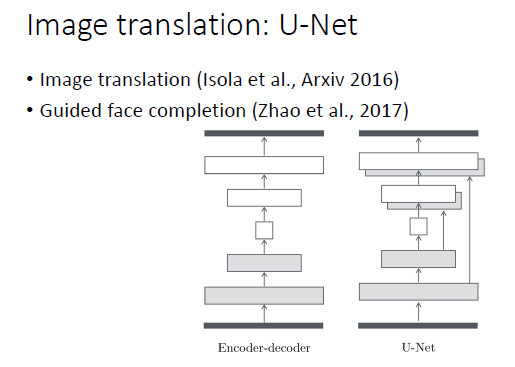
同樣,對於圖像轉換(image translation),基本上用的是 U-Net 結構。我們在做基於引導圖像的人臉填充(guided face completion)時也採用了 U-Net 結構。
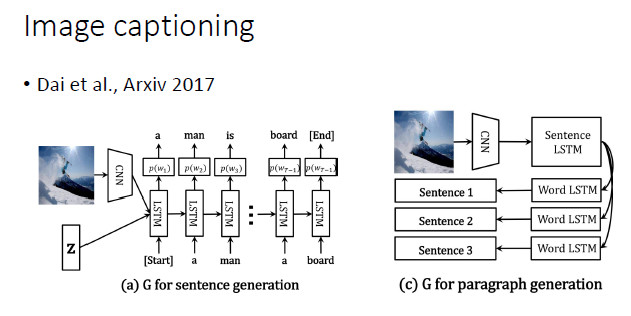
對於圖像文本描述的自動生成,顯然應該採用 CNN+RNN 這樣的網絡結構。總而言之,一個比較好的建議就是根據任務的特點和前任的經驗來設計生成器網絡。
如何連接輸入和輸出
如何通過連接輸入和輸出的方式來改善 GAN 的可學習性,這個問題是從 NIPS 2016 開始得到了較多的關注,同時這也是我自己非常感興趣的一個方向。比較早的一個工作就是 InfoGAN,其特點就是輸入包括兩個部分:C(隱變量)和 Z(噪聲)。InfoGAN 生成圖像之後,不僅要求生成圖像和真實圖像難以區分,還要求能夠從生成圖像中預測出 C,這樣就爲輸入和輸出建立起了一個聯繫。

另外針對一些任務,比如超分辨,可以用 Perceptual loss 的方式來建立輸入和輸出的聯繫。
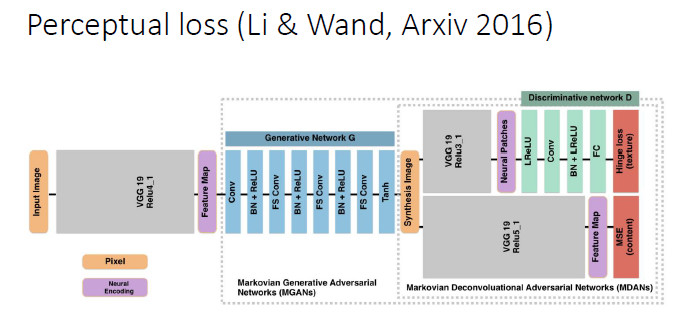
我們在做人臉屬性轉換時發現,現有的 Perceptual loss 往往是定義在一個現有的網絡基礎上的,我們就想能不能把 Perceptual loss 網絡和判別器結合起來,所以就提出了一個 Adaptive perceptual loss。結果表明Adaptive perceptual loss能夠具有更好的自適應性,能夠更好地建立輸入和輸出的聯繫和顯著改善生成圖片的視覺效果。
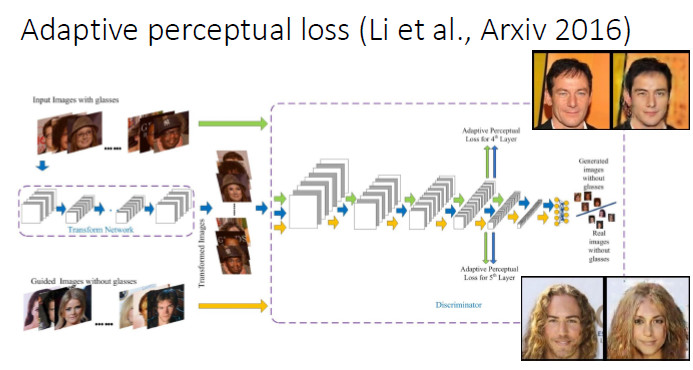
當輸入和輸出都是已知時(比如圖像超分辨和圖像轉換),要用什麼方式來連接輸入和輸出呢?以前是用 Perceptual loss 來連,現在更好的方式是用 Conditional GAN。假設有一個 Positive Pair(輸入和groundtruth圖像)和 Negative Pair(輸入和生成圖像),那麼判別器就不是在兩幅圖像之間做判別,而是在兩個「Pair」之間做判別。這樣的話,輸入就很自然地引入到了判別器中。

在此基礎上,我們還考慮了當有一些額外的 Guidance 時,如何來更好地建立輸入和輸出的聯繫。
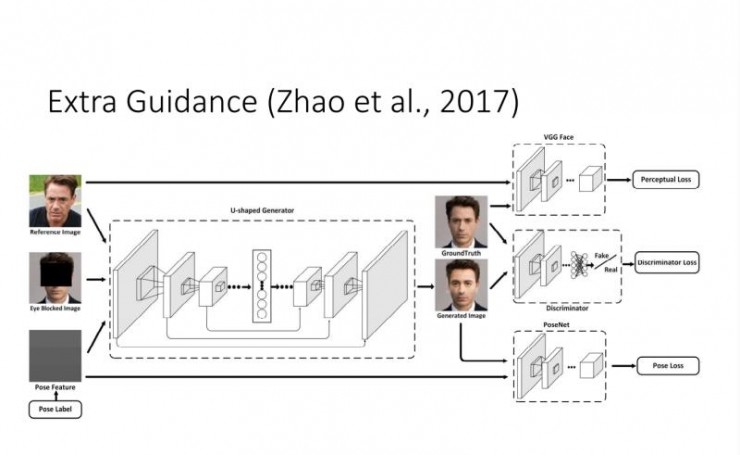
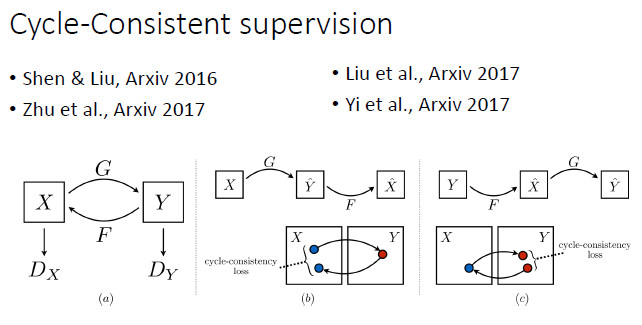
上面提到,在有監督的情況下 Conditional GAN 是一個比較好的選擇。但如果在 unpair 的情況下做圖像轉換,要如何建立輸入和輸出的聯繫?譚平老師他們組和Efros組今年就做了這方面的工作,其實去年投 CVPR2017 的一篇論文也做了類似的工作。我們知道,由於是unpair的,原則上訓練階段輸入和輸出不能直接建立聯繫。這時他們採用的是一種 Cycle-Consistent 的方式。從 X 可以預測和生成 Y,再從 Y 重新生成 X',那麼由 Y 生成的 X' 就能跟輸入的 X 建立聯繫。這樣的話,我們實際上相當於隱式地建立了從 X 到 Y 的聯繫。
總結
如果大家對於 GAN 的理論和模型比較感興趣,可以從輸出分佈和期望分佈之間的差異化程度度量入手。如果你比較在乎GAN的應用,可以從後兩個方面着手,通過設計生成器和建立輸入和輸出之間的聯繫,來解決自己感興趣的問題。我的報告基本上就是這些,謝謝大家。
更多雷鋒網文章:
CMU提出新型內在驅動學習方法,在複雜計算下效率優於強化學習
