按:當只需要把大規模標註圖像數據庫塞給深度神經網絡就可以得到高準確率的物體分類模型之後,有很多研究人員開始考慮更深入的問題:人類的視覺識別學習過程是怎樣的?以及既然人類視覺系統與計算機視覺系統之間表現出了種種不同,我們能否研究這些不同的來源?這是否能給我們帶來新的啓示?
「frontiers in Psychology - Cognitive Science」(心理學研究前沿 - 認知科學)雜誌的一篇文章就介紹了人類幼兒的視覺學習歷程的相關研究。與深度學習大大不同的是,人類幼兒正是靠少量物體、少量面容的反覆多視角觀察培養出了穩定、通用的物體識別能力。全文編譯如下。

視覺學習同時依賴於算法和訓練材料。這篇文章考慮了嬰幼兒以自我爲中心視覺的自然統計特性。這些用於人類視覺目標識別的自然訓練集與輸入機器視覺系統的訓練數據有很大的不同。比起通過平均經歷所有事情來進行學習,幼兒經歷的分佈偏向明顯:有很多事情重複發生。雖然從整體上看變化很大,但個體對事物的看法是按照特定的順序來體驗的——從每時每刻變化的緩慢、流暢的視覺,到場景內容發展有序的過渡。我們認爲,嬰幼兒偏向明顯、有序、有偏向的視覺體驗是一種訓練數據,它使人類學習者能夠開發出一種方法來識別所有事物,包括隨處可見的實體和很少見到的實體。人類和機器學習研究人員將真實世界統計的學習數據聯合起來考慮,似乎有可能爲這兩個學科帶來進步。
引言
學習是人類認知的核心屬性,是人工智能長期追求的目標。我們正處於在人類和人工智能領域產生出新見解的臨界點 (Cadieu et al., 2014; Kriegeskorte, 2015; Marblestone et al., 2016),這些見解將通過明確地將人類認知、人類神經科學和機器學習的進步聯繫起來而更快地顯現出來。「Thought-papers」呼籲機器學習的研究人員利用來自人類和神經的靈感來建造像人一樣學習的機器(例如 Kriegeskorte, 2015; Marblestone et al., 2016),並呼籲人類認知和神經科學的研究人員把機器學習算法作爲關於認知、視覺和神經機制的假設(Yamins and DiCarlo, 2016)。這種新萌發出的興趣的推動力之一是深度學習網絡在解決非常困難的學習問題方面取得了巨大的成功。這些問題是以前無法解決的(例如 Silver et al., 2016)。在神經感知器和連接主義網絡的譜系中,深度學習網絡將原始的感官信息作爲輸入,並使用多層的分層組織結構,每一層的輸出作爲下一層的輸入,從而形成特徵提取和轉換的級聯。這些網絡特別成功的一個應用是機器視覺。這些卷積深度學習網絡(CNNs)的分層結構和空間匯聚不僅產生了最先進的圖像識別技術,而且通過特徵提取的分層組織來實現這一功能,這種特徵提取近似於人類視覺系統皮層的功能(Cadieu et al., 2014)。
在人類認知方面,頭戴式攝像機和頭戴式眼球追蹤技術的最新進展,已經在自然學習環境方面取得了令人興奮的發現。人類日常視覺環境的結構和規律——尤其是嬰兒和兒童的視覺環境——一點也不像最先進的機器視覺中使用的訓練集。機器學習的訓練圖像是由成人拍攝並組織起來的照片。因此,他們偏向於成熟系統的「看起來有用」的東西,反映的是感知發展的結果,而不一定是驅動這種發展的場景(例如, Fathi et al., 2011; Foulsham et al., 2011; Smith et al., 2015)。真實世界的感知體驗並不是由攝像機來框定的,而是與身體在世界上的活動聯繫在一起的。因此,學習者對視覺環境的視角是高度選擇性的,取決於瞬間的位置、空間中的方位、姿勢以及頭部和眼睛的運動(參見 Smith et al., 2015., 2015, 待審)。圖1顯示了以自我爲中心的視域的選擇性:並不是環境中的所有內容都在嬰兒的視域範圍中;除非嬰兒轉過頭去看,否則看不到貓、窗戶、時鐘、站着的人的臉。感知者的姿勢、位置、運動、興趣和社會互動使視覺信息的觀點產生系統性偏向。
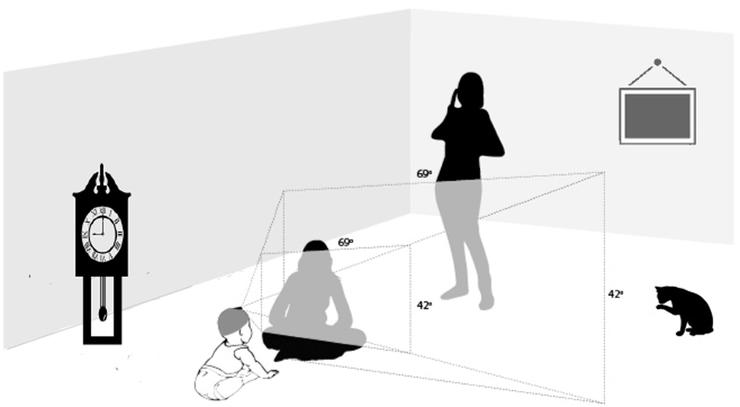
圖1 自我中心視域的選擇性。陰影指示的視場對應嬰兒頭部視角。
隨着個人成長,對不同類別的視覺體驗會產生偏向。從而使所有這些——姿勢、位置、動作、興趣——都發生了巨大的變化。特別是在生命的前兩年,每一項新的感官運動的成就——翻身、伸展、爬行、行走(以及更多)——都會爲新的視覺體驗類別打開大門。因此,人類視覺系統的發展不是通過成批的處理,而是通過一套系統、有序的視覺體驗課程來完成的,這套課程是通過嬰兒自身的感覺運動發展而設計的。以自我爲中心的視覺系統爲研究人員提供了直接訪問這些發展受到制約的視覺環境屬性的途徑。在這裏,我們考慮了真實世界視覺學習數據集的新發現與機器學習的潛在相關性。
有人可能會問,鑑於當代計算機視覺的所取得的成功,機器學習者爲什麼要關心孩子們是如何做到這一點的呢?Schank 是人工智能早期的一位開創性人物,他寫道:「我們希望能夠開發出一個可以學習的程序,就像一個孩子所做的那樣……」(Schank, 1972)。這似乎仍然是自主人工智能的一個合適目標。最近,在一個大型的機器學習會議上,Malik(2016年,私人交流,參見 Agrawal et al., 2016)告訴想爲機器學習下一個大的進步做準備的年輕學習者「認真學習發展心理學,然後運用這些知識構建新的更好的算法。」有鑑於此,我們從一個例子開始,說明爲什麼機器學習者應該關注兒童學習環境中的規律:有充分的證據表明,一個兩歲兒童在視覺學習方面的能力是當代計算機視覺中尚無法匹敵的(見 Ritter et al., 2017)。
兩歲小孩能做什麼
人類可以在不同條件下下識別多種類別的大量物體實例(Kourtzi and DiCarlo, 2006; Gauthier and Tarr, 201)。識別所有這些實例和類別需要視覺訓練;人們必須曾經見過狗、汽車和烤麪包機才能在視覺上識別這些類別的實例(例如, Gauthier et al., 2000; Malt and Majid, 2013; Kovack-Lesh et al., 2014)。這對人類和計算機視覺算法都適用。但目前兒童的發展軌跡和算法有很大的不同。對於兒童來說,早期學習是緩慢且充滿錯誤的(例如, MacNamara, 1982; Mervis et al., 1992)。的確,1-2 歲的兒童在視覺目標識別任務中的表現可能比表現最好的計算機視覺算法要差一些,因爲 1-2 歲兒童在進行類別判斷時具有許多抽象過度和抽象不足的特點,有時在視覺擁擠的場景中完全不能識別已知的物體(Farzin et al., 2010)。然而,兩歲之後情況就不一樣了。此時,孩子們可以從一個實例推斷出整個類別。只要給定一個新類別的實例及其名稱,兩歲的兒童就會立即以成人的方式概括該名稱。例如,如果一個兩歲的孩子遇到第一個拖拉機——比如說,一個綠色的 John Deere 拖拉機在地裏工作——而當聽到它的名字,孩子從這一點會認識所有的各種各樣的拖拉機——紅色的 Massey-Fergusons,古董拖拉機,割草機——但不是挖掘機或卡車。這種現象在發展文獻中被稱爲「形狀偏向」,是在兒童的自然類別學習中觀察到的「單樣本」學習的一個例子。這已經在實驗室中得到了複製和廣泛研究(例如, Rosch et al., 1976; Landau et al., 1988; Samuelson and Smith, 2005)。
研究人員如今已經非常瞭解「形狀偏向」及其發展,下面列舉一些相關研究成果。形狀偏向的出現與兒童物體名稱詞彙量的快速增長是同時發生的。這種偏向是關於感知到的事物的形狀,當兒童能夠從主要部分的關係結構中識別出已知的物體時,這種偏向就會出現(Gershkoff-Stowe and Smith, 2004)。形狀偏向本身是通過對一組初始對象名稱的緩慢學習而習得的(據估計,其中可以包括 50 到 150 個學習到的類別, Gershkoff-Stowe and Smith, 2004)。在實體遊戲的背景下,對基於形狀的對象類別辨別進行早期強化訓練,會導致 1-2 歲的兒童比一般兒童更早出現形狀偏向,而且這些兒童詞彙量的增長速度也會更早 (Samuelson, 2002; Smith et al., 2002; Yoshida and Smith, 2005; Perry et al., 2010)。形狀偏向不僅與兒童對物體名稱的學習有關,還與對的物體操作有關 (Smith, 2005; James et al., 2014a),並隨着兒童從三維形狀的抽象表徵中識別物體的能力逐漸增強(Smith, 2003, 2013; Yee et al., 2012)。學習語言有困難的兒童——晚說話者、有特殊語言障礙的兒童、自閉症兒童——不會形成強烈的形狀偏向(Jones, 2003; Jones and Smith, 2005; Tek et al., 2008; Collisson et al., 2015; Potrzeba et al., 2015)。簡而言之,典型的成長中的兒童在緩慢地學習一組對象類別名稱的過程中,也會學習到如何以某種方式直觀地表示對象形狀。這種方式使他們能夠在只提供一個新類別實例的情況下,估計出一個新對象類別的邊界。最先進的機器視覺運作方式則不同。沒有哪種機器學習的方法能夠改變其學習的本質;相反,每一個需要學習的類別都需要大量的訓練和例子。
區別在哪裏?所有的學習都依賴於學習機制和訓練數據。幼兒是非常成功的視覺分類學習者;因此,他們的內部算法必須能夠利用日常經驗中的規律,不管這些規律是什麼。因此,瞭解嬰兒的日常視覺環境——以及他們如何隨着發展而變化——不僅有助於揭示相關的訓練數據,而且還提供了有關學習的內部機制的信息。
發展變化的視覺環境
對嬰兒頭部攝像機獲得的數據進行研究,非常清楚地表明:人類視覺學習的訓練集在成長過程中發生了很大的變化。圖 2 顯示了頭攝像頭捕獲的示例圖像。一個例子涉及到嬰兒對周圍人的以自我爲中心的視角。對嬰兒在日常生活中採集的大量頭部相機圖像進行分析(Jayaraman et al., 2015, 2017; Fausey et al., 2016)研究表明,人物總是出現在嬰兒頭部相機圖像中,新生兒和兩歲兒童的這一比例是相同的。這並不奇怪,因爲不能把嬰幼兒單獨留下。然而,在頭部攝相機的圖像中,年齡較大和較小的嬰兒的具體身體部位是不一樣的。對於3個月以下的嬰兒來說,人臉無處不在,在每小時的視覺體驗中,人臉佔15分鐘以上。此外,這些臉始終靠近年幼的嬰兒(在距離頭部攝像機2英尺以內),並顯示出兩隻眼睛。然而,當嬰兒接近 1 歲生日時,頭部攝像機記錄下的面部圖像已經很少見了,在醒着的每一個小時裏,只有大約6分鐘的時間有面部出現。相反,對於 1- 2 歲的孩子來說,他們可以看到其他人的手(Fausey et al., 2016)。這些手主要(超過85%的手的圖像中)會接觸和操作一些物體。這種嬰兒面前視覺場景內容的變化是由他們的感覺運動能力的變化、父母相應的行爲以及嬰兒興趣的變化所驅動的。在所有這些相互聯繫的力的作用下最終產生了用於視覺學習的數據。這些數據會發生變化——從許多全景式和近距離的面孔到許多作用於物體的手。我們強烈懷疑這個順序——早期的面孔,後來的物體——這關係到人類視覺物體識別如何以及爲什麼以這種方式發展。

圖2 頭部相機的樣本捕捉了三個不同年齡的嬰兒的圖像。
在構型人臉處理中,「沉睡效應」體現了早期密集的人臉視覺體驗的重要性。Maurer et al. (2007) 將沉睡效應定義爲一種在發展後期出現的永久性缺失,但這是由於早期體驗不足造成的。一個例子涉及嬰兒在 2 至 6 個月大時因先天性白內障而喪失早期視力輸入的情況。根據多項視力發展指標(包括敏銳度、對比敏感度),這些嬰兒在白內障摘除後,開始追趕上同齡人,呈現出視力發展的典型軌跡。但隨着年齡的增長,這些個體在人類視覺面部處理的成熟特徵之一「構型面部處理」(configural face processing)中表現出永久性的缺失。構形處理是指基於一種類似格式塔的表徵,它壓制個體特徵信息對個體面孔進行區分和識別的過程。這是人類視覺處理的一個方面,直到 5 - 7 歲時纔開始出現(Mondloch et al., 2002)。 Maurer et al. (2007)假設,早期的經驗保存和/或建立了神經基質,用於較晚發展的面部處理能力(另見Byrge et al., 2014)。我們推測,嬰幼兒密集的近距離、全視角面部體驗是先天性白內障嬰幼兒早期體驗缺失的部分。因爲這些經歷與嬰兒自身不斷變化的偏向和感覺運動技能有關,所以當嬰兒的白內障後來被摘除時,這些經歷不會被他們的社交夥伴帶來的經驗所取代。因爲到那時,嬰兒自身的行爲和自主性將產生非常不同的社交互動。因此,根據假設,早期密集的面部體驗對於建立或維持大腦皮層迴路可能是必要的,而大腦皮層迴路支持後期出現的專門的面部處理。
有可能早期的面部體驗只對面部處理重要,這是針對特定領域的結果的特定領域的體驗。然而,我們有理由提出另一種觀點。人類視覺皮層通過一系列特徵提取和轉換的層級系統構建我們所看到的世界(例如, Hochstein and Ahissar, 2002)。所有的輸入都在相同的低層和所有較高的表示層中通過並進行調優——面孔、對象、字母——在低層的活動上進行計算。這樣,對人臉的學習和對非人臉對象類別的學習都依賴於相同底層的精度、調優和激活模式。較低層次的簡單視覺識別在較高層次的視覺過程中具有深遠的普遍性(例如,Ahissar and Hochstein, 1997)。來自人類嬰兒的頭部攝像機圖像表明,較低層次的最初調諧和發育是通過視覺場景完成的,其中包括許多閉着眼睛的面孔。正因爲如此,兒童以後對非人臉物體特徵的學習和提取至少在一定程度上是由較低層次的早期調諧形成的,這種調諧嚴重偏重於近距離人臉的低層次視覺特徵。
雖然 Maurer et al. (2007) 使用「沉睡效應」一詞來指代經驗的缺失,但早期視覺體驗對後來發展的作用同時具有消極和積極兩方面的意義。個人早期經驗中的結構規律性會對層次化的神經系統進行訓練和調優,這樣做可能建立潛在的隱藏能力,而這些能力對以後的學習起着至關重要的作用。人類發展的相關研究提供了許多目前無法解釋的例子,它們說明了過去的學習對未來的學習有多麼深遠的影響。例如,通過點陣列視覺識別的準確性可以預測日後的數學成績(Halberda et al., 2008),通過幼兒的形狀偏向可以預測學習字母的能力(Augustine et al., 2015; 參見 Zorzi et al., 2013)。與人類視覺系統相似,深度學習網絡是「深度」的,因爲它們包含層疊的層次結構。這種結構意味着,與人類視覺類似,在一個任務中形成的早期層表徵將被重用。理論上它可以對在其他學習任務同時產生消極和積極的影響。對於這種分層學習系統,有序訓練集的計算價值還沒有得到很好的理解。從面部到手觸物體的受限、但逐步發展的訓練集的整個組合,是否就是解釋 2 歲兒童只需要一個或幾個實例就能夠學會分類一種新的非面部物體的部分原因呢?
幼兒如何觸類旁通
對 2 歲嬰兒的頭部相機圖像的分析也告訴我們,這些圖像中實體的分佈既不是世界上實體的隨機樣本,也不是這些以自我爲中心的圖像中均勻分佈的實體。相反,經驗是極其右傾的。嬰兒頭部相機圖像中的物體是高度選擇性的——很少有哪個種類是普遍的,大多數物體是很少出現的。那麼,這裏有一個關鍵問題:通過廣泛地(可能是緩慢地)學習某些東西,如何產生一個能夠快速學習所有類別、包括一些不常見事物的學習系統呢?冪律分佈既體現在嬰兒對獨特個體面孔的體驗(Jayaraman et al., 2015),也體現在嬰兒對物體的體驗(Clerkin et al., 2017)。在嬰兒出生後的一整年裏,他們看到的面孔高度集中在少數幾個人上,其中最頻繁出現的三個人大約佔頭部相機圖像中所有面孔的 80%。同樣,嬰兒視覺環境中的物體分佈也極其右偏,一些物體類別比其他類別更頻繁(Clerkin et al., 2017)。圖 3 顯示了 8- 10 個月大的嬰兒在 147 次不同的餐桌時間(Clerkin et al., 2017)中,頭部相機圖像分析中常見物體類別的分佈情況。很少有對象類別是普遍存在的,而大多數物體是很少出現的。有趣的是,最常見的物體類別的名稱也是很早就獲得的,但要在 8 到 10 個月,也就是第一個生日之後。這表明,早期密集的視覺體驗爲以後學習這些特定物體的標籤做好了準備。
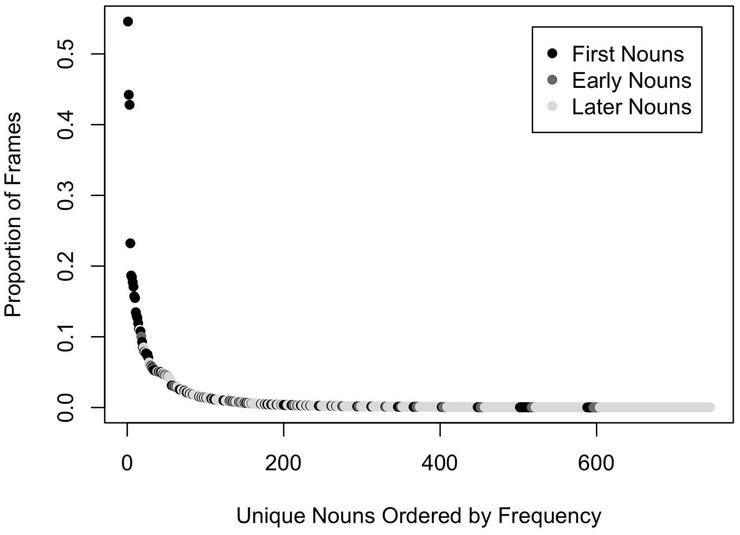
圖3 8-10個月大嬰兒頭部相機圖像中常見物體類別的分佈(Clerkin et al., 2017)。對象類別根據其獲取年齡進行着色(Fenson et al., 1994):第一名詞(對象名稱爲至少50% 16個月嬰兒的接受詞彙),早期名詞(對象名稱不是第一名詞和至少50% 30個月兒童的產出性詞彙),以及後來的名詞(所有其他對象名稱)。
極右偏態分佈的一個可能優勢是,相對較小的個體對象和對象類別的普遍性,使嬰兒能夠定義學習的初始目標集(Clerkin et al., 2017;參見 Salakhutdinov et al., 2011),然後掌握與在許多不同的觀看條件下識別這些少數物體相關的視覺不變性。這可能是關鍵的一步——完成對一部分事物的學習——從而掌握從有限的經驗中快速學習的通用能力,例如 2 歲兒童的形狀偏差(Smith, 2013)。這種對一部分事物的完全瞭解可能不僅依賴於經驗的數量,而且還依賴於經驗在時間上的持續。當一個物體被長時間觀察時,與該物體有關的視網膜信息必然會不斷變化,顯示出相關的轉換和識別的不變性,這種不變性可擴展到識別新事物(Földiák, 1991; Wiskott and Sejnowski, 2002; Li and DiCarlo, 2008)。
控制飼養雛雞的研究(Wood, 2013; Wood and Wood, 2016)爲這一觀點提供了一個論證:物體的緩慢變化轉換爲小雞對物體形狀的泛化學習提供了足夠的輸入。在這些研究中,新生的雛雞在嚴格控制的視覺環境中長大,給它們觀察移動和旋轉的單個物體。通過一系列的控制飼養實驗,研究人員們實驗了不同的運動和旋轉特性。結果表明,隨着時間的推移,單個物體的觀察經驗就足以讓小雞建立健壯的物體識別技能,可以識別這個物體的未見過的視角以及從未見過的其它物體(Wood, 2013, 2015)。控制飼養試驗(Wood, 2016; Wood et al., 2016)也指出了小雞學習的兩個主要限制因素:緩慢和流暢。觀察視角的變化需要緩慢而平穩地進行,並遵循物理對象在世界上的時空屬性。不過,雞的大腦和視覺系統與人類非常不同,因此小雞數據的相關性不是人類視覺系統的動物模型。相反,這些發現的相關性在於,它們清楚地顯示了單個視覺對象的時間上持續的體驗中可用的信息。這可能也暗示了某種目前仍未開發出的算法,可以從對極少(或許只有一個)對象的擴展視覺體驗中迅速學會識別對象類別。
自我生成的視覺體驗
要測試幼兒對物體名稱的瞭解程度,一種方法是向他們詢問不同的物體名稱,看他們表現出怎樣的喜好,另一種方法是給他們展示一個物體,看他們是否會自發地說出它的名字。因此,幼兒的對象名稱詞彙是衡量他們視覺識別對象能力的一個很好的指標。在一歲之前,對象名稱的學習開始得非常緩慢,兒童對單個對象名稱的知識逐漸增長,最初以錯誤爲特徵(例如, MacNamara, 1982; Mervis et al., 1992, 參見 Bloom, 2000)。大約 18 到 24 個月(不同的孩子學習時間不同),學習特性和學習速度會發生變化。大約 2 歲時,對象名稱的學習變得似乎很容易,因爲典型的成長中兒童只需要非常少的經驗,通常只需要一個命名對象的單一經驗,就而已適當地將名稱推廣到新實例(Landau et al., 1988; Smith, 2003)。從緩慢的漸進式學習向快速的幾乎「一次性」學習的轉變反映了學習本身所帶來的內部機制的變化 (Smith et al., 2002)。然而,越來越多的證據表明,用於學習的視覺數據也發生了巨大的變化。
對於 8-10 個月大的嬰兒來說,頭部攝像頭拍攝的場景往往雜亂不堪(Clerkin et al., 2017)。12 個月後的場景仍然經常是雜亂的,但是這些場景被一系列連續的場景打斷。在這些場景中只有一個物體在視覺上占主導地位(例如 Yu and Smith, 2012)。場景構成的變化是幼兒動手能力發展的直接結果。早在一歲之前,嬰兒就會伸手拿東西,但他們缺乏長時間玩耍所需要的軀幹穩定性(Rochat, 1992; Soska et al., 2010)。他們缺乏旋轉、堆疊或插入對象的動手能力(Pereira et al., 2010; Street et al., 2011)。此外,他們最感興趣的是把物體放進嘴裏,這並不是理想的視覺學習。因此,他們經常從遠處看這個世界。而從遠處看,這個世界是許多雜亂的東西。在他們的第一個生日之後,這一切都改變了。幼兒在積極地處理物體時,並會近距離地觀察它們。這種動手活動會促進更高級的視覺對象記憶和區分(Ruff, 1984; Soska et al., 2010; Möhring and Frick, 2013; James et al., 2014a)以及對象名字學習 (例如 Yu and Smith, 2012; LeBarton and Iverson, 2013; James et al., 2014a)。
幼兒的視覺系統生成的畫面視角有三個特性,可能是這些進步的基礎。
首先,幼兒對物體的處理創造出的視覺場景比年紀更小的嬰兒(Yu and Smith, 2012; Clerkin et al., 2017)和成人(Smith et al., 2011; Yu and Smith, 2012)的都要整潔。幼兒胳膊短,身體前傾,仔細看着手中的東西。在此過程中,它們創建一個對象填充視野的場景。這解決了許多基本問題,包括分割,競爭,以及參考對象不明。一項研究(Bambach et al., 2017)直接比較了一個常用的 CNN(Simonyan and Zisserman, 2014)在給定的由幼兒和成人頭部攝像機圖像組成的訓練集(相同的真實世界事件)中學習識別物體的能力。該網絡不提供待訓練對象的裁剪圖像,而是完整的場景,沒有目標對象在場景中的相關位置信息。根據幼兒階段畫面學習到的系統比成人階段的更健壯,並且表現出更好的泛化能力。這與當代計算機視覺的實踐相吻合,計算機視覺的算法通常會在裁剪的圖像或場景中加入邊框,以指定要學習的對象。幼兒做到這一點的方式則是藉助自己的手和頭。
初學走路的孩子處理物體的第二個特點是,他們會生成單一物體的可變性很強的圖像。圖 4 顯示了一個 15 個月大的幼兒在玩耍時生成的單個對象的視圖(Slone et al., 審稿中)。在這項研究中,頭戴式眼球追蹤器被用來捕捉第一人稱場景中的固定物體。一種單一的算法測量,掩膜取向(mask orientation,MO)被用來捕捉嬰兒注視的物體的逐幀圖像變異性:MO是圖像中物體像素最細長軸的方向。至關重要的是,這不是一個面向真實世界或對象形狀的方法,也不以任何直接的方式涉及的形狀特性遠端刺激,而是通過衡量近端圖像屬性的視覺系統來確定遠端對象。主要結果是:15個月大的嬰兒在玩玩具時所產生的MO變化量可以預測在6個月後,也就是21個月大的時候嬰兒掌握物體名稱詞彙量。簡而言之,更大的差異性導致更好的學習。在一項相關的計算研究(Bambach et al., 2017)中,研究人員們向 CNN 提供了一組訓練集,這些訓練集由父母或孩子佩戴的頭部攝像機拍攝的共同玩耍事件的圖像組成。相對於從父母佩戴的相機中看到的相同物體的變化較小的圖像,從兒童佩戴的相機中看到的變化較多的物體圖像導致了更強的學習能力和學習泛化能力。這些發現應該會改變我們對一次性學習的看法。幼兒對一個物體的視覺體驗不是單一的體驗,而是對同一事物的一系列非常不同的觀察。這樣的一系列對單個實例的不同觀察能否引導年輕的學習者使用生成原則來識別某個類別所有成員(例如,所有的拖拉機)?

圖4 一個15個月大的嬰兒在玩耍時用頭部照相機捕捉到的單個物體的樣本圖像。
幼兒自生成對象視圖的第三個屬性是他們傾向於(Pereira et al., 2010)讓大多數對象的長軸垂直於視線(簡單的握持方法),也會讓(儘管更弱)長軸平行於視線(最簡單的將一個對象插入另一個對象的方法)。幼兒通過旋轉物體的主軸,在這些喜歡的視圖之間轉換。這些不同的視角和旋轉突出了非偶然的形狀特徵。由手握物體的方式所產生的不同視角可能有一個視覺來源,因爲當幼兒握着並查看透明球體中包含的物體時,這種偏差會更強(James et al., 2014b)。這樣所有的視圖對於手來說都是等勢的。Wood (2016) 在對小雞的研究中提出了平滑性和緩慢變化的約束條件,但是,無論是正確的分析還是正確的實驗都沒有將這些自生成的物體視圖的屬性與這些約束條件進行比較。但是,考慮到物理世界和物理身體的時空限制,我們完全有理由相信,幼兒會遵從自生成的視圖。
幼兒的全身視覺訓練方法創造了獨特的視覺訓練集,這些訓練集的結構似乎是爲了教授一門非常具體的課程:獨立於視覺的三維形狀識別。單個對象在圖像中是孤立的,因爲它填充了圖像。不同的視圖通過時間上的接近和手的接觸相互連接,這提供了一個強有力的學習信號,表明兩個不同的視圖屬於同一個對象。視圖的動態結構突出顯示了非偶然的形狀屬性。這是視覺目標識別中的一個難題,可以通過數據本身的結構來解決。
幼兒成長和機器學習之間的互相借鑑
嬰幼兒的視覺環境會隨着發展而變化,他們會將不同的學習任務進行分類和排序,這樣以後的學習就可以建立在之前在不同領域學習的基礎上。在每個領域中,訓練集集中於有限樣本的個人實體—— 2 到 3 個人的臉,一個小的普遍的對象集,一個對象的多個視圖——但這些經驗構建瞭如何識別和了解許多不同種類的東西的通用知識。這不是從有限的數據中學習的情況;數據是巨大的——關於你母親的臉,關於你的吸嘴杯的所有視圖。這些訓練集的整體結構與計算機視覺中常用的訓練集有很大的不同。它們能成爲更強大的機器學習的下一個進步的一部分嗎?
機器學習沒有采用發展的多階段方法進行訓練,但已經取得了巨大的進步。有爭議的是,不需要這種輔導和結構化課程的學習機是否更強大。事實上,使用有序訓練集(Rumelhart and McClelland, 1986)並在學習過程中增加難度的連接主義語言發展理論被強烈批評爲作弊(Pinker and Prince, 1988)。但是,被批評的觀點從發展的角度看是正確的(Elman, 1993)。目前有一些機器學習方法(例如課程學習和迭代教學)試圖通過有序和結構化的訓練集來優化學習(例如 Bengio et al., 2009; Krueger and Dayan, 2009)。這些努力並沒有過多地擔心嬰兒自然學習環境中的結構;這可能是人類和機器學習的有益結合。然而,嬰幼兒學習的數據不僅是在發展過程中有序排列的,而且是由學習者自己的活動實時動態構建的。輸入在任何時刻都取決於學習者的當前狀態,並且會隨着學習者內部系統作爲學習功能的變化而實時變化。這樣,在任何時間點提供的信息可能是最適合當前學習狀態的,在正確的時間提供正確的信息。目前機器學習的一種相關方法是在學習過程中對深度網絡中的注意力進行訓練,使選擇的學習數據隨着學習的變化而變化(Mnih et al., 2014; Gregor et al., 2015)。另一種方法是在學習過程中利用好奇心將注意力轉移到新的學習問題上(Oudeyer, 2004; Houthooft et al., 2016; 參見 Kidd and Hayden, 2015)。我們如何將發展洞察力融入機器學習?Ritter et al. (2017)以機器學習者爲研究對象的「認知心理學」實驗,研究了機器學習者如何從緩慢漸進的學習者成長爲具有兒童所表現出的形狀偏向的「一次性」學習者。這些實驗可以操縱結構的訓練集(見Liu et al., 2017)以及算法。這些算法用於理解早期學習如何限制後期學習,以及一點點的學習如何泛化,大量的學習對比很多事情卻只學一點。
當然,沒有人能保證,通過追求這些理念,機器學習者就能建立強大的算法,贏得當前的競爭。但是,這樣的努力似乎肯定會產生新的學習原則。這些原則——以算法形式表達——將構成理解人類學習和智力的一大進步。
via frontiersin.org,