選自Medium
近日,Medium上一篇題爲《AI in 2018 for developers》的文章,針對機器學習應用於業界的機器學習開發人員,根據2017年的人工智能領域的最新和最重大進展,對2018年的進展做了展望。
大家好,又見面了!在上一篇文章中,我談到了自己關於研究領域的看法,即哪些研究領域正在成熟且能在今年發展壯大。繼續從事研究當然很棒,但是,必定還有一些人工智能領域在 2017 年已經成熟、現已準備投入大規模應用了。這就是本文的主題——我想分享的是那些已經發展得足夠好的技術。它們已能應用於你當下的工作中,甚至你能借此創業。重要提示:這是一份涵蓋人工智能領域、算法和技術的清單,且它們都能立即投入使用。例如,你可以在文中看到時間序列分析,因爲深度學習正在迅速取代信號處理領域之前的先進技術。但是,文中並沒有提到強化學習(雖然它聽起來更酷),因爲在我看來它目前還不能投入工業應用。不過強化學習是個很了不起的、正在成長的研究領域。
此外,我想提醒你,這是一個包含三篇文章的系列文章之一,其中分別從三個角度分享了我對於明年人工智能領域會發生什麼的看法:
作爲正在推進領域發展的機器學習研究者(https://blog.goodaudience.com/ai-in-2018-for-researchers-8955df0caaf9)
作爲將機器學習應用於業界的機器學習開發人員(本文)
作爲生活在這個新世界中的普通人
另外,我在此並不會談論圖像識別和簡單的計算機視覺,你們已經在這些領域努力多年啦。
GAN 和虛假產物
即使幾年前就有了生成對抗網絡(GAN),我對此一度非常懷疑。幾年過去了,即使我看到 GAN 在生成 64x64 圖像方面的巨大進步,我仍保持着懷疑。後來我閱讀了一些數學方面的文章,文中提到 GAN 並不真正學習分佈,我的疑慮愈發顯著。不過今年發生了一些改變。首先,有趣的新型結構(例如 CycleGAN)和數學改進(Wasserstein GAN)吸引我在實踐中嘗試了 GAN,它們或多或少都工作得不錯。在接下來的兩個應用中,我徹底改變了態度,確信我們可以且必須利用它們來生成事物。
首先,我非常喜歡英偉達關於生成全高清圖像的研究論文,而且它們看上去的確很真實(相比於一年前 64x64 的詭異面孔而言):
不過,我最喜歡(作爲一個完美的少年夢想應用)且被深深震撼的是生成虛假色情片:
AI-Assisted Fake Porn Is Here and We're All Fucked:https://motherboard.vice.com/en_us/article/gydydm/gal-gadot-fake-ai-porn
我還注意到許多遊戲行業的應用,比如利用 GAN 生成景觀、遊戲主角甚至是整個世界。此外,我覺得我們必須對新的造假水平引起注意——包括你親友的虛假色情片和線上完全虛假的個人。(可能不久之後線下也有?)
全部神經網絡的獨有模式
現代發展的問題之一(不僅侷限於人工智能產業)是,我們有幾十個不同的框架來完成同樣的東西。今天。每個做機器學習的大公司都必然有自己的框架:谷歌、Facebook、亞馬遜、微軟、英特爾、甚至是索尼和 Uber。此外,還有很多開源的解決方案!在一個簡單的人工智能應用中,我們也希望使用不同的框架:例如,計算機視覺通常用 Caffe2、自然語言處理常用 PyTorch、推薦系統常用 Tensorflow 或 Keras。把這些框架全部合併起來需要耗費大量的開發時間,並且會讓數據科學家和軟件開發者無法集中注意力完成更重要的任務。
解決方案必須是一個獨一無二的神經網絡形式。它需要能從任何框架中容易地獲得,必須由開發人員輕鬆部署,並能讓科學家輕易地使用。在這個問題上,今年出現了 ONNX:
實際上,它只是非循環計算圖的簡單格式,但卻在實際中給了我們部署複雜人工智能解決方案的機會,而且我個人認爲它非常具有吸引力——人們可以在像 PyTorch 這樣的框架中開發神經網絡,無需強大的部署工具,也不需要依賴 Tensorflow 的生態系統。
各類 Zoo 激增
對我來說,三年前人工智能界最讓人興奮的東西是 Caffe Zoo。當時,我正在做計算機視覺的相關工作,試遍所有模型,並檢查它們如何工作、結果如何。稍後,我將這些模型應用於遷移學習或特徵提取器。最近,我使用了兩種不同的開源模型,類似大型計算機視覺流程中的一部分。這意味着什麼?這意味着事實上沒有必要訓練自己的網絡,例如 ImageNet 的對象識別或地點識別。這些基礎的東西可以下載並插入到你的系統當中。除了 Caffe Zoo 之外,其他框架也有類似的 Zoo。不過,讓我感到驚奇的是,你可以僅在你的 iPhone 中插入計算機視覺、自然語言處理甚至加速度計信號處理的模型:
likedan/Awesome-CoreML-Models:https://github.com/likedan/Awesome-CoreML-Models
我認爲,這些 Zoo 只會越來越多,將 ONNX 這類生態系統的出現考慮在其中,並進行集中化(也會由於機器學習區塊鏈應用而導致分散化)。
自動機器學習替代流程
設計神經網絡結構是件痛苦的任務——有時候你可以通過添加捲積層獲得不錯的結果;但是大多數時候,你需要使用超參數搜索方法(如隨機搜索或貝葉斯優化)或是直覺仔細設計結構的寬度、深度和超參數。在計算機視覺領域,你至少可以調整在 ImageNet 上訓練的 DenseNet。但如果你在某些 3D 數據分類或多變量時間序列應用中工作,這一點將尤其困難。
使用其他神經網絡從頭生成神經網絡結構的嘗試有很多,但對我而言最棒、最清晰的是近期 Google Research 的進展:
AutoML for large scale image classification and object detection:https://research.googleblog.com/2017/11/automl-for-large-scale-image.html
他們使用 AutoML 生成的計算機視覺模型,比人類設計的網絡工作的更快、更好!我相信,很快就會有許多關於這個話題的論文和開源代碼。我認爲,會出現更多博文和初創公司,告訴我們「人工智能所創造的人工智能學習了其他人工智能,它可以……」,而不是「我們開發了一個人工智能,它可以……」。至少,在我的項目中我會這樣做。我也相信不是隻有我一個人這樣做。
智能堆棧正式化
在這個概念上,我閱讀了很多 Anatoly Levenchuk 的博文。他是俄羅斯系統分析師、教練,同時熱衷於人工智能領域。在下圖中,你可以看到所謂「人工智能堆棧」的實例:
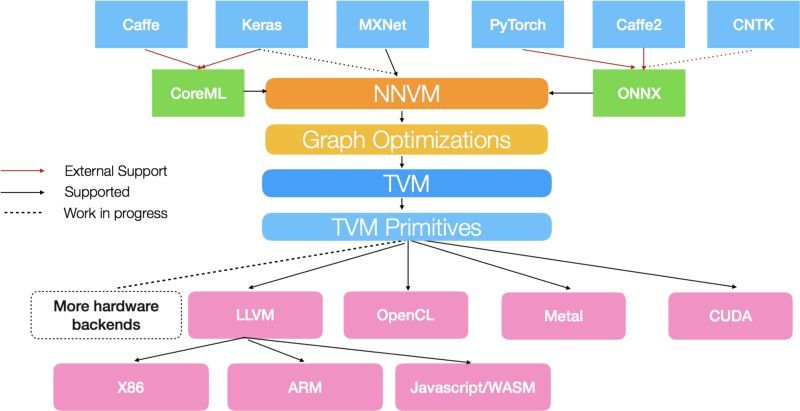
http://www.tvmlang.org/2017/10/06/nnvm-compiler-announcement.html
它不僅包括機器學習算法和你喜愛的框架,還有着更深的層次。而且在每個層面,都含有自身的發展和研究。
我認爲,人工智能發展產業已經足夠成熟,從而能擁有更多不同的專家。在團隊中,僅有一名數據科學家遠遠不夠——你需要不同人員從事硬件優化、神經網絡研究、人工智能編譯、解決方案優化和生產實施等方面的工作。在他們之上必須有不同的團隊領導、軟件架構師(爲上述每個問題分別設計堆棧)以及管理人員。我曾經提過這個概念,希望將來人工智能領域的技術專家能夠不斷成長(對那些想成爲人工智能軟件架構師或技術引領者的人而言——你需要知道該學什麼)。
基於語音的應用
人工智能所能解決的準確率可達 95% 以上的問題其實非常少:我們可以將圖像識別分類到 1000 個類別,可以判斷文本的正負面性、當然也能做一些更復雜的事情。我認爲,還有一個領域將因人工智能派生的上千個應用發生動盪:那就是語音識別和生成。事實上,一年前 DeepMind 發佈 WaveNet 之後這個領域還發展得不錯。但是今天,多虧了百度的 DeepVoice 3 和最近在 Google Tacotron2 的發展,我們已經走遠:
Tacotron 2: Generating Human-like Speech from Text:https://research.googleblog.com/2017/12/tacotron-2-generating-human-like-speech.html
這個技術很快就會發布在開源代碼中(或着被一些聰明的人複製),而且每個人都能以非常高的準確率識別語音並生成它。這會帶來什麼呢?更好的私人助理、自動閱讀器、談判轉錄機……當然還有作虛假聲音產品。
更加智能化的機器人
我們今天所看到的機器人都有一個很大的問題——其中 99% 根本不基於人工智能,只是硬編碼而已。因爲我們意識到,我們不能用上百萬個對話的注意力訓練某些編碼-譯碼器 LSTM,從而獲得智能系統。這就是爲什麼 Facebook Messenger 或 Telegram 中的絕大部分機器人都只有硬編碼命令,至多擁有一些基於 LSTM 和 word2vec 的句子分類神經網絡。但是,現代先進的 NLP 有點超出了這個水平。只需要看看 Salesforce 做出的有趣研究就能領會這一點:
AI Research - Salesforce.com:https://www.salesforce.com/products/einstein/ai-research/
他們正在構建與數據庫相連的 NLP 接口,克服現代編碼-譯碼器的自動迴歸模型,不僅對文字或句子進行嵌入訓練,而將範圍擴展到了字符嵌入訓練。此外,還有一個利用強化學習進行 ROUGE 分數 NLP 優化的有趣研究:
https://www.salesforce.com/products/einstein/ai-research/tl-dr-reinforced-model-abstractive-summarization/。
我相信,隨着這些發展,我們至少能提升機器人水平。它們能檢索更多智能信息、進行命名實體識別,而且很可能在某些封閉領域充分深度學習驅動機器人。
先進的序列分析
除 Salesforce 外,第二個被低估的機器學習研究實驗室是 Uber 的人工智能實驗室。前段時間,他們發表了一篇博客,展示了對時間序列的預測方法。老實說這讓我有點受寵若驚,因爲在我的應用中基本上也用了同樣的方法!看看吧,這就是將統計特徵和深度學習表示相結合的實例:
Engineering Extreme Event Forecasting at Uber with Recurrent Neural Networks:https://eng.uber.com/neural-networks/
如果你需要更多振奮人心的實例,請用 34 層一維 ResNet 嘗試診斷心律失常。最棒的部分無疑是其性能——它不僅優於一些統計模型,甚至超過了專業心臟病專家的診斷!
最近,我從事的大部分就是深度學習的時間序列分析。我可以親自證實神經網絡工作得非常好,你能獲得優於「黃金標準」5-10 倍的性能。它真的能行!
超越內置的優化
我們如何訓練神經網絡?說實話,我們大多數人只是使用類似「Adam()」函數或是標準學習率。一些聰明的人選擇最合適的優化器,並調整和調度學習率。我們總是低估「優化」這一主題,因爲我們只需按下「優化」按鈕,然後等待網絡收斂就大功告成了。但是,在這個計算能力、存儲和開源方案都大多相同的情況下,優勝者往往使用着與你相同的亞馬遜實例,卻能在 Tensorflow 模型中用最短的時間得到最佳的性能——這一切都是優化的功勞。
Optimization for Deep Learning Highlights in 2017:http://ruder.io/deep-learning-optimization-2017/index.html
我鼓勵大家看看上面 Sebastian's Ruder 的博文,其中談到了 2017 年最新的標準優化器改進方案,以及其他非常有用的改善方法。你可以立即將其運用起來。
大肆宣傳的整體下降
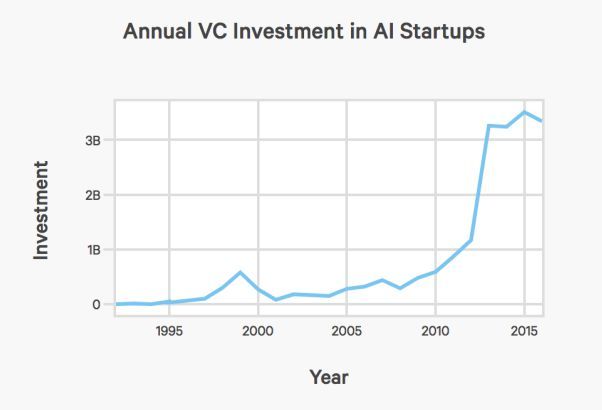
cdn.aiindex.org/2017-report.pdf
在閱讀前文後,你能從這張圖片中發現什麼?考慮到許多開源工具和算法的發佈,開發有價值的新東西並從中獲取很大利潤並不容易。我認爲,對類似 Prisma 這樣的初創公司而言,2018 年並非最好的一年——將會有太多的競爭對手和「聰明人」想分一杯羹。他們可以將如今的開源網絡部署在移動應用程序中,並稱其爲「創業」。
今年,我們必須專注於基礎的事情,而不是很快獲利——即使對於某些有聲書初創公司而言,我們計劃用 Google 的 Ratacon 進行語音識別,但這也並非一個簡單的網絡服務,而是與合作伙伴攜手的商業模式,同時也是吸引投資的商業模型。
總結
簡而言之,有幾種技術已經可以被用於實際產品:時間序列分析、GAN、語音識別、自然語言處理領域的部分發展。我們不應該再設計基礎的分類或迴歸架構,因爲 AutoML 會幫我們做這個。通過一些優化改進,我希望 AutoML 能夠比以前運行得更快。此外,使用 ONNX 和各種模型 Zoo 能讓我們僅用幾行代碼將基本模型注入到應用程序當中。我認爲,製作人工智能爲基礎的應用,在目前先進的技術水平來說不是難事,而且對整個行業而言並無壞處!對於研究領域的發展,可以查閱我以前的文章。不久後,我將發佈「2018 人工智能發展趨勢」系列的最後一篇文章,其中將介紹人工智能如何影響「普通人」的生活。
原文鏈接:https://medium.com/@alexrachnog/ai-in-2018-for-developers-2f01250d17c