選自Medium
作者:Luke James
參與:黃小天、路雪
本文是作者獻上的一部「野外紀錄片」,介紹了五個直接受大自然啓發而產生的人工智能算法:人工神經網絡、遺傳算法、集羣智能、強化學習和人工免疫系統。

在當今技術背景之下,人工智能的發展催生出很多美好事物。人類花費數十年研究如何優化數學計算以使複雜的學習算法運轉起來,此外,我們還已經超越自身的物種,正努力創造新一代智能體。大自然及其所包含的一切,深深地植根於人工智能的運作之中,而這正是本文的主題。
David Attenborough 的野生動物紀錄片令人震撼,他們通過高清晰的細節記錄了地球上諸多物種的行爲和特徵,如何融入自然生態系統,並協同共存使得自然生機勃勃——使其成爲「地球」。我雖然不是 David Attenborough,但是也要獻上一部「野生動物紀錄片」,介紹那些直接受大自然啓發而產生的人工智能算法。在此之前,我首先介紹兩個算法概念:搜索/路徑尋找和預測建模。
搜索(路徑尋找)算法
搜索算法本質上是一種程序,被設計用來發現通往目標的最優/最短的路徑。例如,旅行推銷員問題是一個典型的搜索優化問題,其中包含給定的一系列城市及其之間的距離。你必須爲推銷員找到最短路徑,同時每個城市只經過一次,從而最小化旅行時間和開銷(確保你回到起點城市)。這一問題的真實應用是運貨車。假設倫敦有 100 個人在線下單,所有箱子要裝進貨車,快遞員現在必須計算最高效的路線(平衡距離/所花費的時間),以便從倉庫交付這些包裹(最終還要返回倉庫),確保公司把時間和金錢消耗降到最低。
預測建模算法
如今,有關預測建模的炒作是最多的。全世界的數據科學正在強烈呼籲「神經網絡」,而像谷歌這樣的大公司也正努力通過人工智能及其各種不同變體解決世界上的難題。預測建模本質上藉助統計學來預測結果。你經常聽到數據科學家試圖解決兩類預測建模問題:迴歸和分類。迴歸是找到兩組變量關聯性的暗黑藝術;分類是確定數據集屬於不同組的概率的過程。
5 個生物啓發式學習算法
1. 人工神經網絡
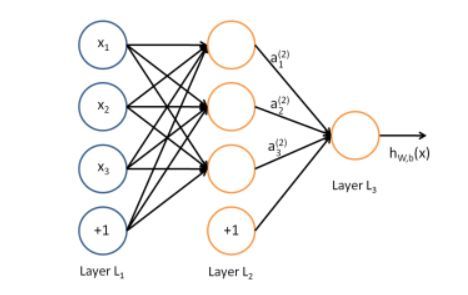
前饋神經網絡——最基本類型的神經網絡
- 算法類型:預測建模
- 生物啓發:認知腦功能(神經元)
- 用例:情感分析、圖像識別/檢測、語言修正、機器人
讓我們從最基礎的人工智能算法開始。神經網絡是人工智能子範疇機器學習的一部分。神經網絡的設計目的是在神經元層面上模擬大腦功能,通過軸突和樹突的交互在系統之中把信息傳遞過一系列的層,生成一個預測性的輸出。每個層提供一個數據表徵的額外層,並允許你建模最複雜的問題。
神經網絡很可能是使用最爲廣泛的機器學習算法,並且是目前爲止數據科學和深度學習的最熱趨勢。這一概念最初起始於 1958 年的感知機,後來 Geoffrey Hinton 完善了它,並在谷歌、Facebook 等公司中大爲流行。神經網絡可用於解決一系列問題,比如自然語言處理、視覺識別。這一監督式學習算法可以解決迴歸和分類問題,其實例可在常規的消費產品中發現,比如智能手機和智能家居設備。
2. 遺傳算法
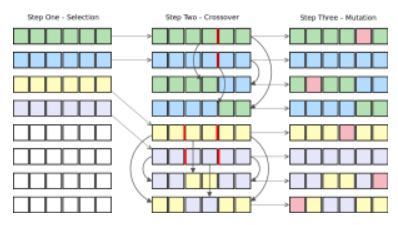
遺傳算法中的個體繁殖
- 算法類型:搜索/路徑尋找
- 生物啓發:適者生存/進化(細胞繁殖)
- 用例:數據挖掘/分析、機器人、製造/設計、流程優化
遺傳算法在連續的一代代個體之間採取適者生存的進化方法,以期解決搜索問題。每一代包含一羣模擬 DNA 染色體的字符串。羣體中的每個個體表徵搜索空間中的一點,因此每個都是可能的候選方案。爲了提升方案數量,我們使個體經歷一次進化過程。
- 羣體之中的每個個體將會競爭資源和配偶。
- 相比於表現差的個體,每次競爭中的最成功個體將(通常)產生更多個體。
- 來自更多「理想」候選的基因在羣體中傳播,因此這些優秀的父母往往會產生潛力更大的後代。
3. 羣集/集羣智能(SWARM/COLLECTIVE INTELLIGENCE)
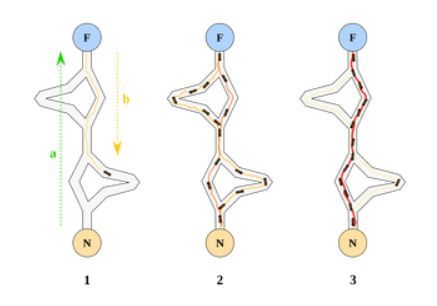
蟻羣優化算法示例——一種集羣智能算法
- 算法類型:搜索/路徑尋找
- 生物啓發:蟻羣/魚羣/鳥羣
- 用例:機器人、視頻遊戲 AI、製造業、路徑規劃
蟻羣優化(Ant Colony Optimisation)和粒子羣優化(Particle Swarm Optimisation)是兩種最廣爲人知的「集羣智能」算法。從基礎層面上來看,這些算法都使用了多智能體。每個智能體執行非常基礎的動作,合起來就是更復雜、更即時的動作,可用於解決問題。
蟻羣優化(ACO)與粒子羣優化(PSO)不同。二者的目的都是執行即時動作,但採用的是兩種不同方式。ACO 與真實蟻羣類似,利用信息激素指導單個智能體走最短的路徑。最初,隨機信息激素在問題空間中初始化。單個智能體開始遍歷搜索空間,邊走邊灑下信息激素。信息激素在每個時間步中按一定速率衰減。單個智能體根據前方的信息激素強度決定遍歷搜索空間的路徑。某個方向的信息激素強度越大,智能體越可能朝這個方向前進。全局最優方案就是具備最強信息激素的路徑。
PSO 更關注整體方向。多個智能體初始化,並按隨機方向前進。每個時間步中,每個智能體需要就是否改變方向作出決策,決策基於全局最優解的方向、局部最優解的方向和當前方向。新方向通常是以上三個值的最優「權衡」結果。
4. 強化學習
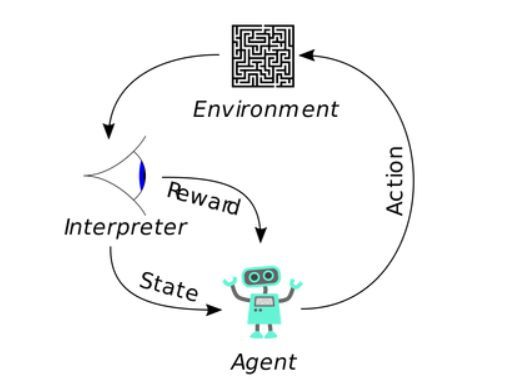
強化學習環境中的智能體行爲
- 算法類型:預測建模
- 生物啓發:經典條件反射
- 用例:視頻遊戲、自動駕駛汽車、生產線軟件、財務系統
強化學習受到心理學和經典條件反射的啓發,爲智能體的積極動作給予正值反應。學習強化學習的概念通常比學習流行的經典條件反射示例「巴甫洛夫的狗」更加簡單。該示例是 1890 年代俄國心理學家伊萬·巴甫洛夫執行的研究,旨在觀察狗對食物的唾液分泌。詳細解釋可參閱:https://www.simplypsychology.org/pavlov.html。本質上,如果強化學習智能體執行了一個好的動作,即該動作有助於完成要求任務,則它會得到獎勵。智能體將使用策略來學習在每一步中最大化獎勵。將原始輸入應用到算法中使得智能體開發出自己對問題的感知,以及如何以最高效的方式解決問題。
RL 算法常常與其他機器學習技術(如神經網絡)一同使用,通常稱爲深度強化學習。神經網絡通常用於評估 RL 智能體作出某個決策後所獲得的獎勵。DeepMind 在這方面取得了很大成果,它使用深度 Q 學習方法解決更通用的問題(如利用算法的能力玩 Atari 遊戲、戰勝圍棋世界冠軍)。DeepMind 現在在研究更復雜的遊戲,如星際爭霸 2。
Q 學習是強化學習算法的無模型版本,可用於對任意有限馬爾可夫決策過程尋找最優的動作選擇策略。程序初始化時,每個動作-價值對的 Q 值由開發者定義,並由 RL 算法在每個時間步進行更新。下圖展示了 Q 值的更新公式。

Q 學習值更新公式
5. 人工免疫系統
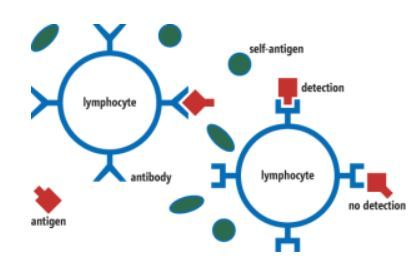
人工免疫系統組件
- 算法類型:預測建模
- 生物啓發:免疫系統
- 用例:安全軟件、自動導航系統、調度系統、故障檢測軟件
免疫系統通過免疫應答機制保護身體免受病原體等的侵襲。人工免疫系統(AIS)是一種適應性系統,受啓發於理論免疫學和免疫功能在問題求解中的應用。AIS 是生物啓發計算和自然計算的分支,與機器學習和人工智能聯繫緊密。以下算法常用於 AIS:
- 克隆選擇
- 樹突狀細胞
- 負選擇
- 人工免疫識別
和生物免疫系統一樣,AIS 能夠將所有「細胞」分類爲「自己」或「非己」細胞。智能的分佈式任務組(distributed task force)用於對所有細胞執行動作。免疫系統中最重要的兩種細胞是 T 細胞和 B 細胞。T 細胞有三種類型:激活 B 細胞、摧毀入侵者、調節機體免疫問題。B 細胞生成抗體。人工免疫系統通常用於監控入侵檢測,從而抵禦網絡攻擊,通常被整合進企業級軟件中。與上文提到的其他算法不同,這方面的在線免費學習資料較少,而且可能也是發展最慢的。
本文介紹了 5 種受生物啓發的技術。影響 AI 系統的生物啓發算法還有很多,歡迎分享。
原文地址:https://towardsdatascience.com/5-ways-mother-nature-inspires-artificial-intelligence-2c6700bb56b6