導讀:目前最好的語音識別系統採用雙向長短時記憶網絡(LSTM,LongShort Term Memory),但是,這一系統存在訓練複雜度高、解碼時延高的問題,尤其在工業界的實時識別系統中很難應用。科大訊飛在今年提出了一種全新的語音識別框架——深度全序列卷積神經網絡(DFCNN,Deep Fully Convolutional NeuralNetwork),更適合工業應用。本文是對科大訊飛使用DFCNN應用於語音轉寫技術的詳細解讀,其外還包含了語音轉寫中口語化和篇章級語言模型處理、噪聲和遠場識別和文本處理實時糾錯以及文字後處理等技術的分析。
人工智能的應用中,語音識別在今年來取得顯著進步,不管是英文、中文或者其他語種,機器的語音識別準確率在不斷上升。其中,語音聽寫技術的發展最爲迅速,目前已廣泛在語音輸入、語音搜索、語音助手等產品中得到應用並日臻成熟。但是,語音應用的另一層面,即語音轉寫,目前仍存在一定的難點,由於在產生錄音文件的過程中使用者並沒有預計到該錄音會被用於語音識別,因而與語音聽寫相比,語音轉寫將面臨說話風格、口音、錄音質量等諸多挑戰。
語音轉寫的典型場景包括,記者採訪、電視節目、課堂及交談式會議等等,甚至包括任何人在日常的工作生活中產生的任何錄音文件。 語音轉寫的市場及想象空間是巨大的,想象一下,如果人類可以征服語音轉寫,電視節目可以自動生動字幕、正式會議可以自動形成記要、記者採訪的錄音可以自動成稿……人的一生中說的話要比我們寫過的字多的多,如果有一個軟件能記錄我們所說過的所有的話並進行高效的管理,這個世界將會多麼的讓人難以置信。
基於DFCNN的聲學建模技術
語音識別的聲學建模主要用於建模語音信號與音素之間的關係,科大訊飛繼去年12月21日提出前饋型序列記憶網絡(FSMN, Feed-forward Sequential Memory Network)作爲聲學建模框架後,今年再次推出全新的語音識別框架,即深度全序列卷積神經網絡(DFCNN,Deep Fully Convolutional NeuralNetwork)。
目前最好的語音識別系統採用雙向長短時記憶網絡(LSTM,LongShort Term Memory),這種網絡能夠對語音的長時相關性進行建模,從而提高識別正確率。但是雙向LSTM網絡存在訓練複雜度高、解碼時延高的問題,尤其在工業界的實時識別系統中很難應用。因而科大訊飛使用深度全序列卷積神經網絡來克服雙向LSTM的缺陷。
CNN早在2012年就被用於語音識別系統,但始終沒有大的突破。主要的原因是其使用固定長度的幀拼接作爲輸入,無法看到足夠長的語音上下文信息;另外一個缺陷將CNN視作一種特徵提取器,因此所用的卷積層數很少,表達能力有限。
針對這些問題,DFCNN使用大量的卷積層直接對整句語音信號進行建模。首先,在輸入端DFCNN直接將語譜圖作爲輸入,相比其他以傳統語音特徵作爲輸入的語音識別框架相比具有天然的優勢。其次,在模型結構上,借鑑了圖像識別的網絡配置,每個卷積層使用小卷積核,並在多個卷積層之後再加上池化層,通過累積非常多的卷積池化層對,從而可以看到非常長的歷史和未來信息。這兩點保證了DFCNN可以出色的表達語音的長時相關性,相比RNN網絡結構在魯棒性上更加出色,同時可以實現短延時的準在線解碼,從而可用於工業系統中。
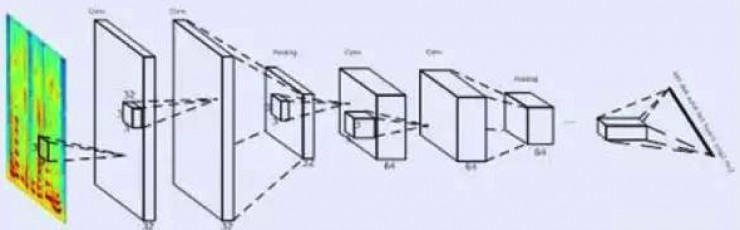
(DFCNN 結構圖)
口語化和篇章級語言模型處理技術
語音識別的語言模型主要用於建模音素與字詞之間的對應關係。由於人類的口語爲無組織性的自然語言,人們在自由對話時,通常會出現猶豫、回讀、語氣詞等複雜的語言現象,而以文字形式存在的語料通常爲書面語,這兩種之間的鴻溝使得針對口語語言的語言模型建模面臨極大的挑戰。
科大訊飛借鑑了語音識別處理噪聲問題採用加噪訓練的思想,即在書面語的基礎上自動引入回讀、倒裝、語氣詞等口語「噪聲」現象,從而可自動生成海量口語語料,解決口語和書面語之間的不匹配問題。首先,收集部分口語文本和書面文本語料對;其次,使用基於Encoder-Decoder的神經網絡框架建模書面語文本與口語文本之間的對應關係,從而實現了口語文本的自動生成。
另外,上下文信息可以較大程度幫助人類對語言的理解,對於機器轉錄也是同樣的道理。因而,科大訊飛在去年12月21提出了篇章級語言模型的方案,該方案根據語音識別的解碼結果自動進行關鍵信息抽取,實時進行語料搜索和後處理,用解碼結果和搜索到的語料形成特定語音相關的語言模型,從而進一步提高語音轉寫的準確率。
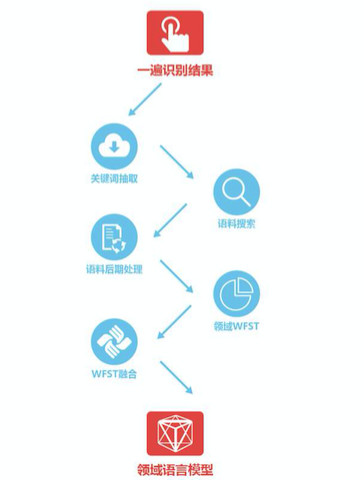
(篇章級語言模型流程圖)
噪聲和遠場識別技術
語音識別的應用遠場拾音和噪聲干擾一直是兩大技術難題。例如在會議的場景下,如果使用錄音筆進行錄音,離錄音筆較遠說話人的語音即爲遠場帶混響語音,由於混響會使得不同步的語音相互疊加,帶來了音素的交疊掩蔽效應,從而嚴重影響語音識別效果;同樣,如果錄音環境中存在背景噪聲,語音頻譜會被污染,其識別效果也會急劇下降。科大訊飛針對該問題使用了單麥克及配合麥克風陣列兩種硬件環境下的降噪、解混響技術,使得遠場、噪聲情況下的語音轉寫也達到了實用門檻。
單麥克降噪、解混響
對採集到的有損失語音,使用混合訓練和基於深度迴歸神經網絡降噪解混響結合的方法。即一方面對乾淨的語音進行加噪,並與乾淨語音一起進行混合訓練,從而提高模型對於帶噪語音的魯棒性(編者注:Robust的音譯,即健壯和強壯之意);另一方面,使用基於深度迴歸神經網絡進行降噪和解混響,進一步提高帶噪、遠場語音的識別正確率。
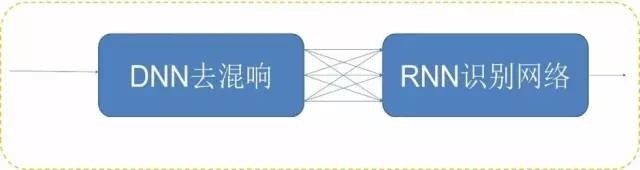
麥克風陣列降噪、解混響
僅僅考慮在語音處理過程中的噪音可以說是治標不治本,如何從源頭上解決混響和降噪似乎纔是問題的關鍵。面對這一難題,科大訊飛研發人員通過在錄音設備上加上多麥克陣列,利用多麥克陣列進行降噪與解混響。具體地,使用多個麥克風採集多路時頻信號,利用卷積神經網絡學習波束形成,從而在目標信號的方向形成一個拾音波束,並衰減來自其他方向的反射聲。該方法與上述單麥克降噪和解混響的結合,可以進一步顯著的提高帶噪、遠場語音的識別正確率。
文本處理實時糾錯+文字後處理
前面所說的都只是對於語音的處理技術,即將錄音轉錄成文字,但正如上文所述人類的口語爲無組織性的自然語言,即使在語音轉寫正確率非常高的情況下,語音轉寫文本的可閱讀性仍存在較大的問題,所以文本後處理的重要性就體現了出來。所謂文本後處理即對口語化的文本進行分句、分段,並對文本內容的流利性進行處理,甚至進行內容的摘要,以利於更好的閱讀與編輯。
後處理Ⅰ:分句與分段
分句,即對轉寫文本按語義進行子句劃分,並在子句之間加註標點;分段,即將一篇文本切分成若干個語義段落,每個段落描述的子主題各不相同。
通過提取上下文相關的語義特徵,同時結合語音特徵,來進行子句與段落的劃分;考慮到有標註的語音數據較難獲得,在實際運用中科大訊飛利用兩級級聯雙向長短時記憶網絡建模技術,從而較好的解決了分句與分段問題。
後處理Ⅱ:內容順滑
內容順滑,又稱爲不流暢檢測,即剔除轉寫結果中的停頓詞、語氣詞、重複詞,使順滑後的文本更易於閱讀。
科大訊飛通過使用泛化特徵並結合雙向長短時記憶網絡建模技術,使得內容順滑的準確率達到了實用階段。
來源:科大訊飛公衆號
