按:本文作者 Sanyam Bhutani 是一名機器學習和計算機視覺領域的自由職業者兼 Fast.ai 研究員。在文章中,他將 2080Ti 與 1080Ti 就訓練時長進行了全方位的對比。我們對此進行了詳盡編譯。

前言
特別感謝:如果沒有來自 Tuatini GODARD(他是我的一名好朋友,同時也是一名活躍的自由職業者)的幫助,這個基準比較工作是不可能完成的。如果你想了解更多關於他的信息,可以閱讀這篇訪談:
鏈接:
https://hackernoon.com/interview-with-deep-learning-freelancer-tuatini-godard-e661a3995fb1
還要感謝 Laurae 給這篇文章提出許多有價值的修改建議。
對了,最新版的 fastai(2019 版)剛推出,你們肯定都很感興趣:course.fast.ai
備註:這篇文章並沒有接受來自 fastai 的贊助,我只是在上頭學習到很多東西。從個人角度來說,如果你是剛開始接觸深度學習,強烈向你推薦這個平臺。
讓我們進入正題。這是一個能夠說明 FP16 本質的簡單操作演示,並且展示了基於基準測試的混合精度訓練是怎麼進行的(我承認,大部分時候我只是通過這個向朋友吹噓我的顯卡集全比他的要快,然後纔是出於研究目的)。
注意:這並非關乎基準性能比較的文章,而是 2080Ti 與 1080Ti 之間基於 2 builds 的訓練時長對比。
對此,文章裏會有更詳細的介紹。
在此之前,我們先快速瀏覽一下中子的造型:

FP16 是何方神聖?爲何你需要關注它?
簡單來說,深度學習是基於 GPU 處理的一堆矩陣操作,操作的背後有賴於 FP32 / 32 位浮點矩陣。
隨着新版架構與 CUDA 的發佈,FP32 / 32 位浮點矩陣的運算正變得越來越簡單。這也意味着,只要使用與過去相比只有一半大小的張量,我們卻能通過增加批尺寸(batch_size)來處理更多案例;此外,相比使用 FP32(也被稱爲 Full Precision Training)進行訓練,FP16 可以有效降低 GPU RAM 的使用量。
用簡單的英語來表示,就是能夠在代碼中以 (batch_size)*2 替代 (batch_size)。
FP16 運算的張量核心如今在速度上變得更快了,只需使用少量的 GPU RAM ,就能在速度與性能方面有所提升。
等等,這可沒那麼簡單
我們依然存在半精度問題(這是因爲 16 位浮點變量的精度是 32 位浮點變量的一半),說明:
更新的權重數據是不精確的。
梯度會下溢。
無論激活或丟失都可能導致溢出。
有明顯的精度損失。
接下來,我將和大家談一談混合精度訓練。
混合精度訓練
爲了避免上述提及的問題,我們在運行 FP16 的過程中,會在可能導致精度損失的部分及時切換回 FP32。這就是所謂的混合精度訓練。
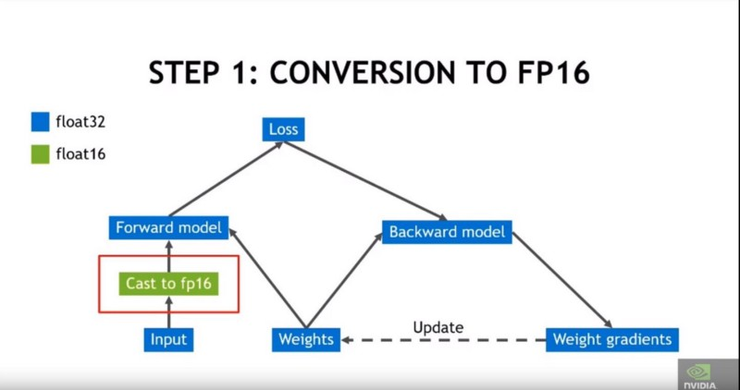
第 1 步:使用 FP16 儘可能加快運算速度:
將輸入張量換成 fp16 張量,以加快系統的運行速度。
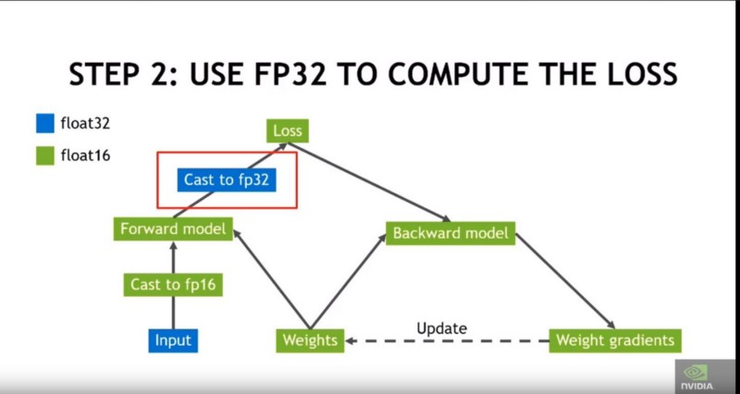
第 2 步:使用 FP32 計算損耗值(避免下溢/溢出):
將張量換回 FP32 以計算損耗值,以免出現下溢/溢出的情況。
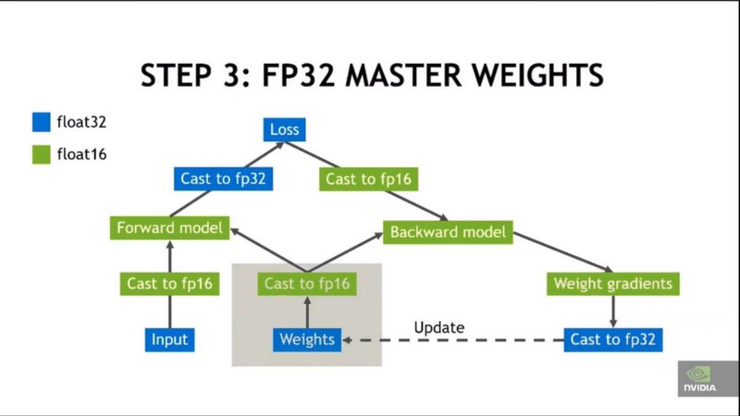
第 3 步:
先用 FP32 張量進行權重更新,然後再換回 FP16 進行前向與反向迭代。
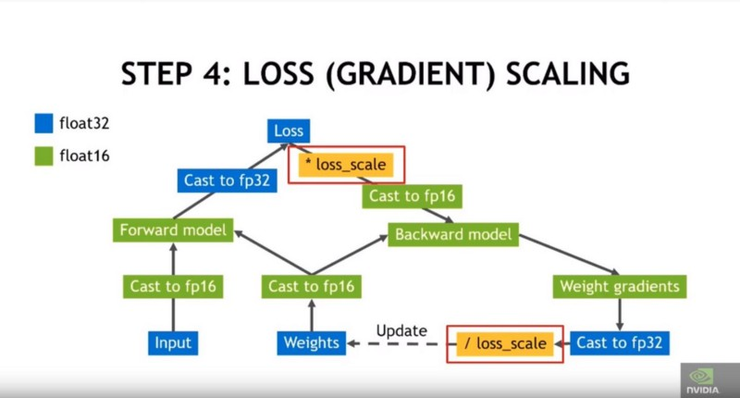
第4步:通過乘以或除以縮放因子來完成損耗縮放:
通過乘以或除以損耗比例因子來縮放損耗。
總結就是:

fast.ai 上的混合精度訓練
正如人們所期待的的,在庫中進行混合精確訓練有如將

轉換成

一樣簡單。
如果你想了解操作過程當中的細節,可以點進:
https://docs.fast.ai/callbacks.fp16.html
該模塊允許我們使用 FP16 更改訓練過程中的前向與反向迭代,且附有提速效果。
就內部而言,回調函數能確保所有模型參數(除去智能使用 FP32 的 batchnorm layers)都轉換成 FP16,且保存了 FP32 副本。FP 32 副本(主參數)主要用於優化器上的更新;FP 16 的參數則用於梯度計算。這些能有效避免低學習率下溢現象的發生。
RTX 2080Ti 與 GTX 1080Ti 的混合精度訓練結果對比
設置詳情
可以從這裏獲知筆記本的基準設置
軟件設置:
Cuda 10 + 對應最新版的 Cudnn
PyTorch + fastai 庫(從源頭進行編譯)
最新版的 Nvidia 驅動程序(截至文章撰寫時間)
硬件配置:
我們的硬件配置略有不同,對於最終數值要有所保留。
Tuatini 的配置:
i7-7700K
32GB RAM
GTX 1080Ti(EVGA)
我的配置:
i7-8700K
64GB RAM
RTX 2080Ti(MSI Gaming Trio X)
由於運算過程並非 RAM 密集型或者 CPU 密集型任務,所以我們選擇在此處分享我們的結果。
讓我們快速過一遍:
輸入 CIFAR-100 數據
調整圖像的大小,啓用數據增強
在 fastai 支持的所有 Resnet 上運行
預期輸出:
在所有的混合精度訓練測試中取得更好的結果。
圖表結果
以下展示的是在各個 ResNets 上的訓練時間對比總表。
注意:數值越小越好(X 軸代表秒時間單位與縮放時間)
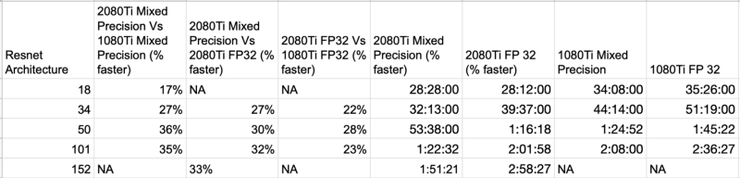
Resnet 18
體積最小的 Resnet。
秒時間單位:
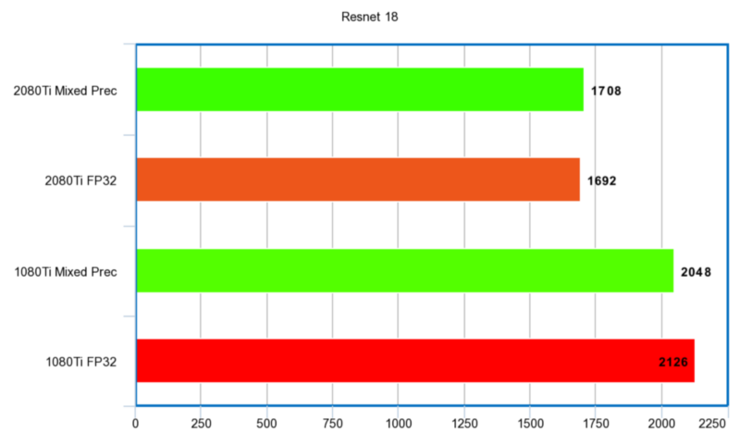
性能比例:
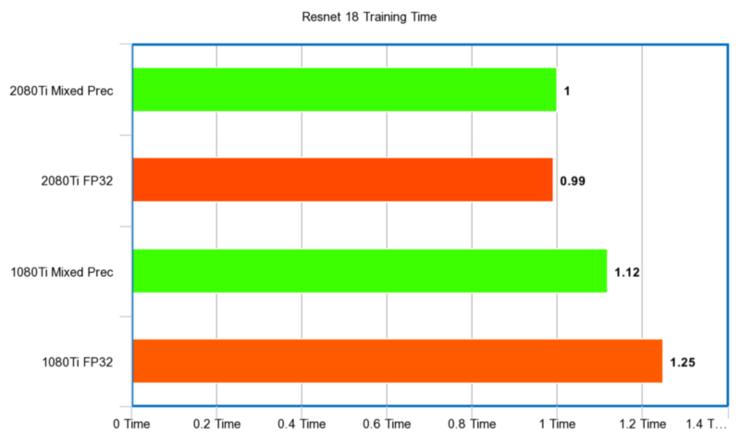
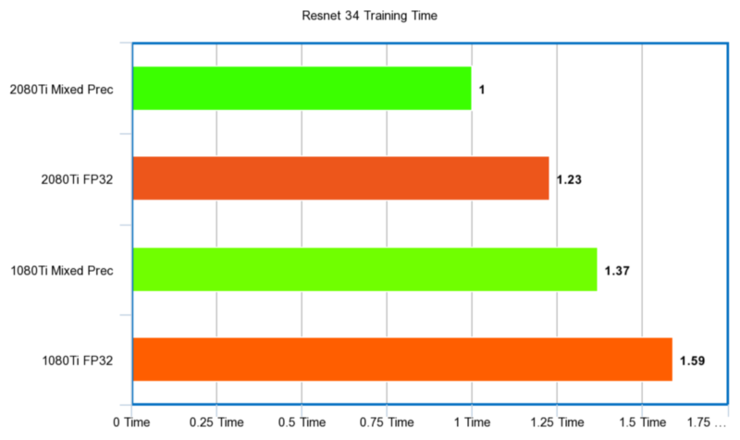
Resnet 34
秒時間單位:
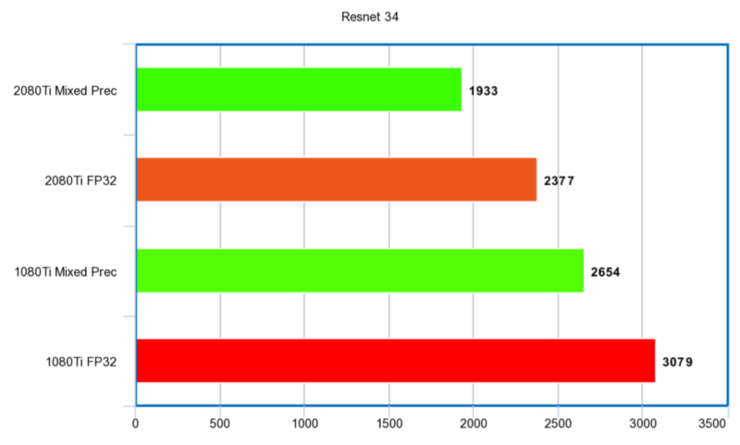
性能比例:
Resnet 50
秒時間單位:
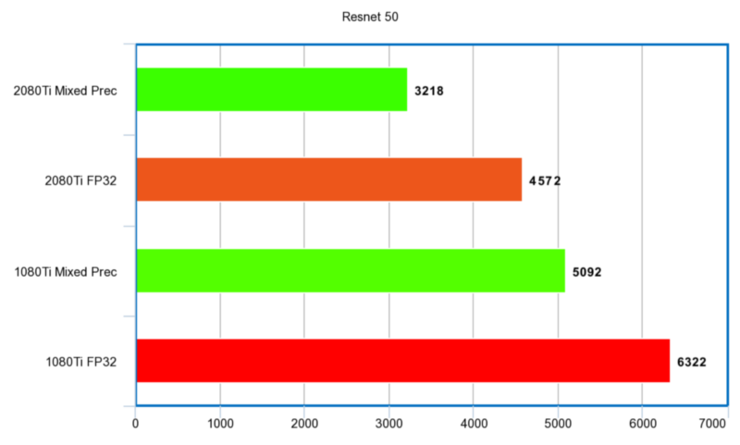
性能比例:
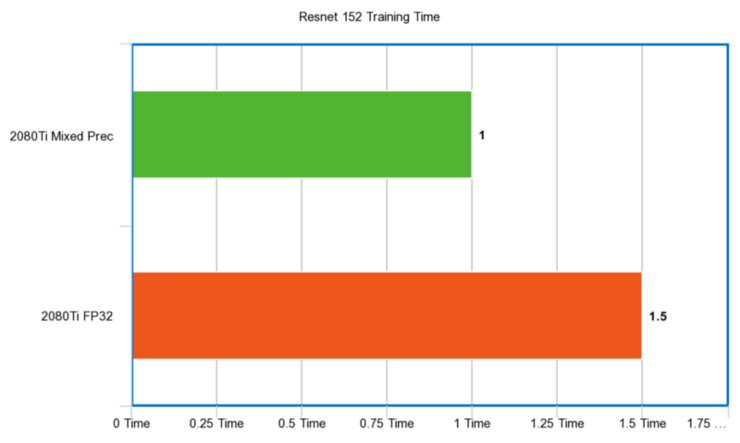
Resnet 152
秒時間單位:
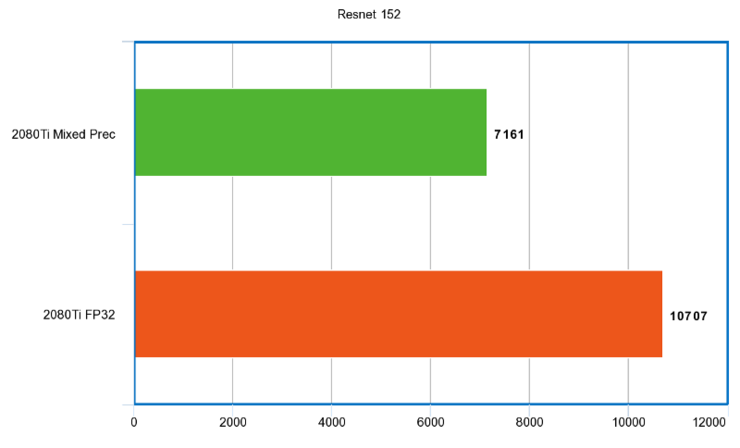
性能比例:
使用 Nvidia Apex 進行世界級語言建模工作
爲了使混合精度訓練與 FP16 訓練的實驗成爲可能,Nvidia 專門發佈了一套維護 Nvidia 的實用工具 Nvidia apex,用於簡化 Pytorch 中的混合精度訓練與分佈式訓練。Apex 最主要的目的是儘可能快速地爲用戶提供最新的實用工具。
開源網址:
https://github.com/NVIDIA/apex
它通過一些例子向我們展示,不需要經過太多調整便可以直接運行工具——看來又是另一個針對高速旋轉的好測試。
語言模型對比:
Github 開源中的例子基於語言建模任務訓練了一個多層 RNN(Elman,GRU 或 LSTM)。該訓練腳本默認使用 Wikitext-2 數據集。訓練模型可以用來生成產生新文本的腳本。
我們其實並不關心測試的生成結果 - 我們主要想比較基於混合精度訓練的 30 輪次(epochs)訓練例子,以及同樣批量大小卻是不同設置的全精度訓練(Full Precision)。
啓用 fp16 就和運行代碼時傳遞「—fp16」參數一樣簡單,APEX 可以在我們已經設置好的 PyTorch 環境上運行。綜合來看,這似乎是個完美的選擇。
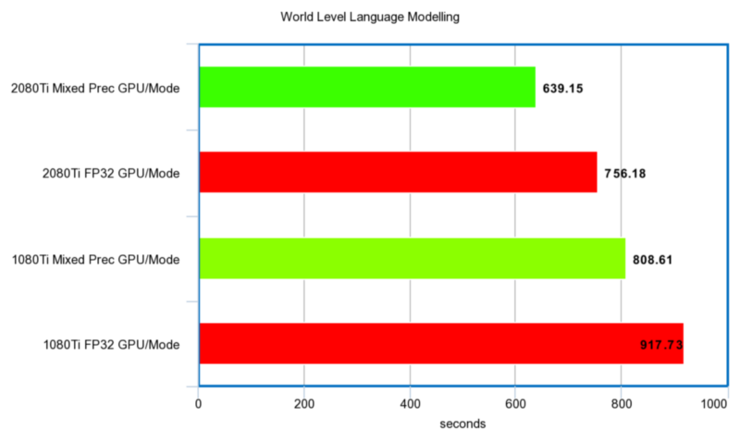
以下是相關結果:
秒時間單位
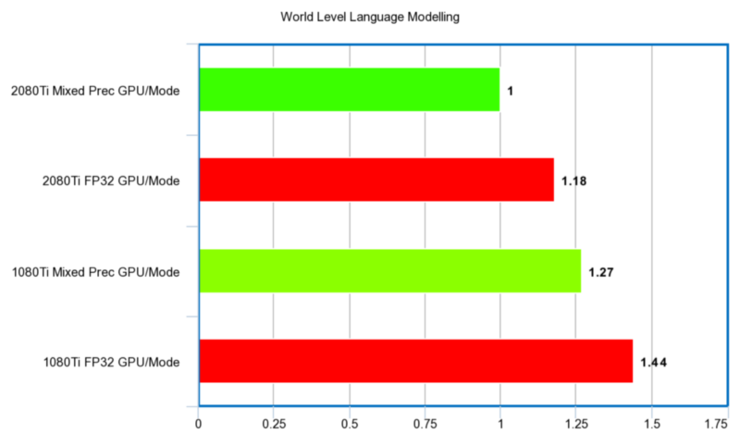
性能比例:
結論
雖然在性能方面 RTX 卡要比 1080Ti 強大得多,尤其就小型網絡而言,然而訓練時間的差異並不如預期般的明顯。
如果你決定嘗試混合精度訓練,我在這裏給你提供幾個重點提示:
更大批量:
在筆記本基準測試中,我們發現在 batch_size 方面有近乎 1.8 倍的提高,這與我們嘗試過的所有 Resnet 示例結果保持一致。
速度比全精度訓練更快:
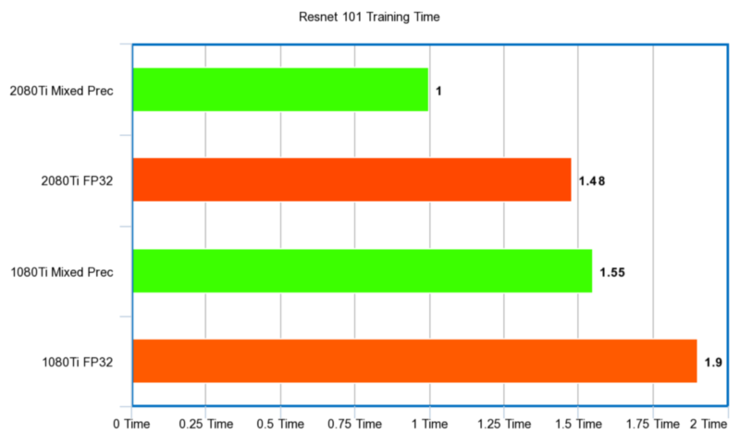
我們以結果差距最大的 Resnet 101 爲例(用的是 CIFAR-100 數據集),全精度訓練在 2080Ti 上的花費時間是混合精度訓練的 1.18 倍,在 2080Ti 上的花費時間是混合精度訓練的 1.13 倍。即便是體積「較小」的 Resnet34 和 Resnet50,我們發現混合精度訓練在訓練期間存在小幅度的加速效果。
相同的精確值:
我們並未發現混合精度訓練導致精確度下降的現象出現。
確保你使用最新版的 CUDA(>9)和 Nvidia 驅動程序。
這裏需要強調的是,在測試期間,如果環境沒更新好是無法運行代碼的。
多多關注 fastai 和 Nvidia APEX