作爲「史上最強 GAN 圖像生成器」,BigGAN 自去年 9 月推出以來就成爲了 AI 領域最熱詞。其生成圖像的目標和背景都高度逼真、邊界自然,簡直可以說是在「創造新物種」。然而 BigGAN 訓練時需要的超高算力(128-512 個谷歌 TPU v3 核心)卻讓很多想要參與制圖狂歡的開發者望而卻步。
今日,BigGAN 論文的第一作者、來自英國 Heriot-Watt 大學的 Andrew Brock 發佈了 BigGAN 的 PyTorch 版實現。最令人高興的是:這一次訓練模型的算力要求被降低到 4 到 8 塊 GPU 了!
項目鏈接:https://github.com/ajbrock/BigGAN-PyTorch
該項目一出即引發了人們的廣泛關注,有的人表示不敢相信,也有人哭暈在 Colab。
 Brock 本次放出的 BigGAN 實現包含訓練、測試、採樣腳本以及完整的預訓練檢查點(生成器、判別器和優化器),以便你可以在自己的數據上進行微調或者從零開始訓練模型。
Brock 本次放出的 BigGAN 實現包含訓練、測試、採樣腳本以及完整的預訓練檢查點(生成器、判別器和優化器),以便你可以在自己的數據上進行微調或者從零開始訓練模型。
作者表示,這些代碼製作時間很長,從一開始就被設計成可操控、可擴展的基礎,以方便未來的研究。作者花了很多心思考慮在什麼地方具體使用什麼抽象,以確保它們有效但又易於理解或改變。
這一工作是 Andrew Brock 與 MIT 的 Alex Andonian 一起完成的。
BigGAN 的 PyTorch 實現
這是由論文原作者正式發佈的「非官方」BigGAN PyTorch 實現。

該 repo 包含用 4-8 個 GPU 訓練 BigGAN 的代碼。
如何使用
你需要用到:
1.0.1 版本的 PyTorch
tqdm、numpy、scipy 和 h5py
ImageNet 訓練集
首先,你可以準備目標數據集的預處理 HDF5 版本,以便更快地輸入/輸出(可選)。在此之後(不管是否如此做了),你需要計算 FID 所需的 Inception moment。這些都可以通過修改並運行以下代碼來完成:
sh scripts/utils/prepare_data.sh默認情況下,假設你的 ImageNet 訓練集已經下載至此目錄的根文件夾 data 中,然後以 128x128 的像素分辨率準備緩存的 HDF5。
腳本文件夾中有多個 bash 腳本,此類腳本可以用不同的批量大小訓練 BigGAN。這段代碼假設你無法訪問完整的 TPU pod,然後通過梯度累積(將多個小批量上的梯度平均化,然後僅在 N 次累積後採取優化步驟)表示相應的 mega-batches。默認情況下,launch_BigGAN_bs256x8.sh 腳本訓練批量大小爲 256 且具備 8 次梯度累積的完整 BigGAN 模型,其總的批量大小爲 2048。在 8xV100 上進行全精度訓練(無張量核),這個腳本需要 15天訓練到 15 萬次迭代。
你需要先確定你的設置能夠支持的最大批量。這裏提供的預訓練模型是在 8xV100(每個有 16GB VRAM)上訓練的,8xV100 能支持比默認使用的 BS256 略大的批量大小。一旦確定了這一點,你應該修改腳本,使批大小乘以梯度累積的數量等同於你期望的總批量大小(BigGAN 默認的總批量大小是 2048)。
注意,這個腳本使用參數 --load_in_mem,該參數會將整個 I128.hdf5(約 64GB)文件加載至 RAM 中,以便更快地加載數據。如果你沒有足夠的 RAM 來支持這個(可能需要 96GB 以上),刪除這個參數。
度量和採樣

在訓練過程中,該腳本將輸出包含訓練度量和測試度量的日誌,並保存模型權重/優化器參數的多個副本(2 個最新的和 5 個得分最高的),還會在每次保存權重時產生樣本和插值。日誌文件夾包含處理這些日誌及使用 MATLAB 繪製結果的腳本。
訓練結束後,你可以使用 sample.py 生成額外的樣本和插值,用不同的截斷值、批大小、standing stat 累積次數等進行測試。示例參考 sample_BigGAN_bs256x8.sh 腳本。
默認情況下,所有內容都會保存至 weights/samples/logs/data 文件夾中,這些文件夾應與該 repo 在同一文件夾中。你可以使用 --base_root 參數將這些文件夾指向不同的根目錄,或者使用對應的參數(如 --logs_root)爲每個文件夾選擇特定的位置。
該 repo 還包含運行 BigGAN-deep 的腳本,但作者尚未使用它們來完整地訓練模型,所以可將其視爲未經測試。另外,該 repo 包含在 CIFAR 上運行模型的腳本,以及在 ImageNet 上運行 SA-GAN(帶有EMA)和 SN-GAN 的腳本。SA-GAN 代碼假設你有 4xTitanX(或具備同等 RAM 的 GPU),並使用 128 的批量大小和 2 個梯度累積來訓練。
關於 Inception 度量的重要提示
該 repo 使用 PyTorch 內置 inception 網絡來計算 IS 和 FID 分數。這些分數與使用官方 TF inception 代碼得到的不同,且僅用於監控目的。使用 --sample_npz 參數在模型上運行 sample.py,然後運行 inception_tf13 來計算真實的 TensorFlow IS。注意:你需要安裝 TensorFlow 1.3 或更早版本,因爲 TF1.4+ 會破壞原始 IS 代碼。
預訓練模型
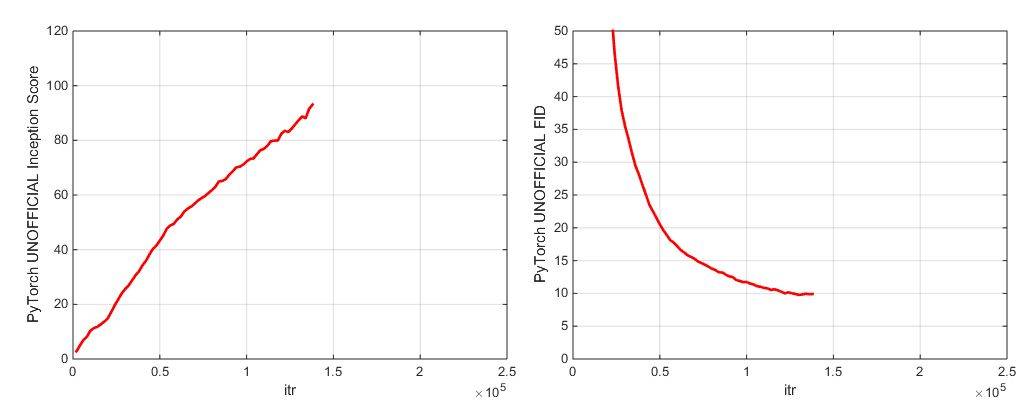
該 repo 包含兩個預訓練模型檢查點(具備 G、D、G 的 EMA copy、優化器和 state dict):
主要檢查點是在 128x128 ImageNet 圖像上訓練的 BigGAN,該模型使用 BS256 和 8 次梯度累積,並在崩潰前實現,其 TF Inception Score 爲 97.35 +/- 1.79,詳見:https://drive.google.com/open?id=1nAle7FCVFZdix2—ks0r5JBkFnKw8ctW。
第一個模型的更早檢查點 (100k G iters)性能優秀且在崩潰前實現,可能比較容易微調,詳見:https://drive.google.com/open?id=1dmZrcVJUAWkPBGza_XgswSuT-UODXZcO。
使用 Places-365 數據集預訓練模型也將很快開源。
該 repo 還包含將原始 TFHub BigGAN Generator 權重遷移到 PyTorch 的腳本。詳見 TFHub 文件夾。
使用自己的數據集或新的訓練函數對模型進行微調

如果你想繼續被中斷的訓練或者微調預訓練模型,運行同樣的啓動腳本,不過這次需要添加 —resume 參數。實驗名稱是從配置中自動生成的,但是你可以使用 —experiment_name 參數對其進行重寫(例如你想使用修改後的優化器設置來微調模型)。
要想使用自己的數據集,你需要將其添加到 datasets.py,並修改 utils.py 中的 convenience dicts (dset_dict, imsize_dict, root_dict, nclass_dict, classes_per_sheet_dict),從而爲自己的數據集準備適合的元數據。在 prepare_data.sh 中重複該過程(可選擇性地生成 HDF5 preprocessed copy,然後計算 FID 所需的 Inception moment。
默認情況下,該訓練腳本將以 Inception Score 爲衡量標準選出 top 5 最優檢查點並保存。對於 ImageNet 以外的數據集,模型的 Inception Score 可能不是很好的質量度量標準,因此你可以使用 which_best FID 來代替 Inception Score。
要想使用自己的訓練函數(如訓練 BigVAE),你可以修改 train_fns.GAN_training_function,或者將新的訓練函數添加到 if config['which_train_fn'] == 'GAN' 之後(train.py 中的行)。
亮點
該 repo 提供完整的訓練和度量日誌,以供參考。作者發現,重新實現一篇論文時最困難的事情之一是檢查日誌在訓練早期是否排列整齊,尤其是訓練需要花費數週時間時。希望這些工作有利於未來的研究。
該 repo 用了加速的 FID 計算:初始 scipy 版本需要 10 多分鐘來計算矩陣 sqrt,而該版本使用加速的 PyTorch 版本,能在 1 秒內完成計算。
該 repo 用了一種加速型、低內存消耗的正交寄存器(ortho reg)實現。
默認情況下,該 repo 只計算最大奇異值(譜範數),但該代碼通過 —num_G_SVs 參數支持更多 SV 的計算。
這段代碼與原始 BigGAN 的關鍵區別
不同於BigGAN的G_lr=5e-5, D_lr=2e-5, num_D_steps=2),該repo使用出自SA-GAN (G_lr=1e-4, D_lr=4e-4, num_D_steps=1的優化器設置。雖然性能稍差,但這是該repo減少訓練時間所採取的第一個措施。
默認情況下,該repo不使用Cross-Replica BatchNorm(AKA Synced BatchNorm)。該repo嘗試的兩種變體(一種是常規簡單的變體,一種是該repo中的變體)與內置BatchNorm具有略微不同的梯度(儘管採用相同的正推計算法),這對於弱化訓練似乎足夠了。
梯度累積意味着該repo更頻繁地更新SV估值和8倍BN統計。這意味着BN統計更有可能是固定統計,同時奇異值估算也更準確。基於此,默認情況下,該repo在測試模式下通過G來度量(在論文中使用BatchNorm動態統計,而不計算固定統計)。該repo依然支持固定統計(參見sample.sh腳本)。這也可能導致早期積累的梯度過時,但在實踐中這不再是一個問題。
當前提供的預訓練模型沒有通過正交規範化訓練。缺少正交寄存器的訓練增加了模型擺脫截斷影響的概率,但看起來這一特定模型中獎了。無論如何,該repo提供兩種高度優化(速度快且內存消耗最小)的正交寄存器實現,從而直接計算正交寄存器梯度。
參考文章: