選自arXiv
參與:路雪、劉曉坤
日前,MIT 和 Bengio 發表新論文,探討深度學習中的泛化。該論文解釋了深度學習能夠實現較好泛化的原因,並提出了一系列新型正則化方法。機器之心對該論文進行了編譯。

論文鏈接:https://arxiv.org/abs/1710.05468
本論文解釋了爲什麼深度學習在面臨容量過大、算法不穩定、非魯棒和尖點等問題時仍能實現較好的泛化。基於理論的探索,該論文提出了一系列新的正則化方法。實驗證明,即使其中最簡單的方法也可以將基礎模型在 MNIST 和 CIFAR-10 上的表現提升到業內最佳水平。此外,本文提出了數據依賴性(data-dependent)和數據獨立性的泛化保證,它們提高了收斂速度。我們的研究引出了一系列新方向。
1 引言
一些經典的理論研究把泛化能力歸功於小容量模型類別的使用(Mohri et al., 2012)。從與小容量相關的緊湊表示(compact representation)的角度來看,深度模型類別在展示特定的自然目標函數時比淺層的模型類別具有指數優勢(Pascanu et al., 2014; Montufar et al., 2014; Livni et al., 2014; Telgarsky, 2016; Poggio et al., 2017)。也就是說,如果模型類別中包含的某些假設(如分段線性轉換的深度合成)被目標函數近似滿足,則與不依賴該假設的方法相比,該模型可以實現很好的泛化。但是,近期的一篇論文(Zhang et al., 2017a)的實驗表明成功的深度模型類別具備足夠的容量來存儲隨機標籤。該觀察叫作「apparent paradox」,引起了研究者的廣泛討論。Dinh et al. (2017) 認爲解釋深度學習模型爲何能夠在大容量的情況下仍然實現較好的泛化效果是一個仍待研究的領域。
在本論文中,我們提出了對「apparent paradox」的一種解釋。第三章從理論上證明了「apparent paradox」不僅存在於深度學習中,還存在於整個機器學習中。第四章中,我們認爲應該重新思考泛化和學習理論,並通過重新思考得出了對深度學習中的泛化的一種新理解。第五章介紹了泛化界的改進,第六章介紹了對正則化的一種有用的理論見解。
3 重新思考機器學習中的泛化
Zhang et al. (2017a) 的實驗表明多種深度模型類別能夠存儲隨機標籤,並且在特定的自然數據集(如 CIFAR-10)上的輸出包含零訓練誤差和很小的測試誤差。他們的實驗還觀察到在權重範數上的正則化似乎未必產生小的測試誤差,這與傳統觀點並不一致。
命題 1 認爲這些現象並不侷限於深度學習和線性模型類別中:任何機器學習模型類別本質上都具備這些現象的核心特性。
命題 1 給定(未知)度量 P_(x,y) 和數據集 S_m,假設存在,在時,使
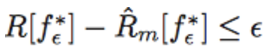
。那麼
(i)對於模型複雜度能夠存儲任意數據集和在任意尖點(sharp minimum)上可能包括的任意模型類別 F,存在 (A, S_m) 使泛化差距不超過;
(ii)對於任意數據集 S_m,存在任意不穩定和非魯棒的算法 A,使的泛化差距不超過。
5 神經網絡的泛化保證
上一章通過實例對泛化進行解釋。然而,求出泛化差距(Role 2)的理論保證仍然是很有意思的問題,這正是本章所關注的內容。爲了更仔細地分析神經網絡,本章將對神經網絡直接進行分析,而不是從基於容量、穩定性或魯棒性的一般理論中推導出神經網絡的結果。
6 對實用價值的理論洞察
本章中,我們關注具備 d_y 個類別的多分類問題,如圖像目標分類。相應地,我們將使用 0—1 損失函數分析期望風險,即 R[f] = E_x[1{f(x) = y(x)}],其中
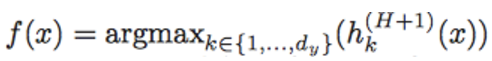
是模型的預測,y(x) ∈ {1, . . . , d_y} 是 x 的真實標籤(參見 2.4.1 中對隨機標籤的擴展,Mohri et al. 2012)。
6.3 實驗結果
通過向現有的的標準代碼中添加等式(2)中新的正則化項:
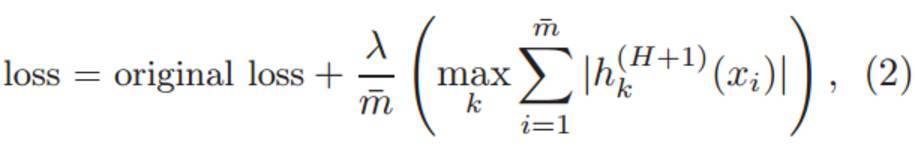
我們在 MNIST 和 CIFAR-10 數據集上對論文中提出的方法(DARC1)進行了評估。
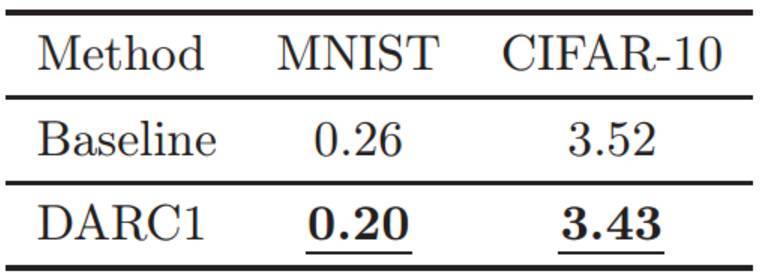
表 1:測試誤差(%)。LeNet 和 ResNeXt-29(16 × 64d)的標準變體和添加了本文研究正則項的模型在 MNIST 和 CIFAR-10 數據集上的比較結果。
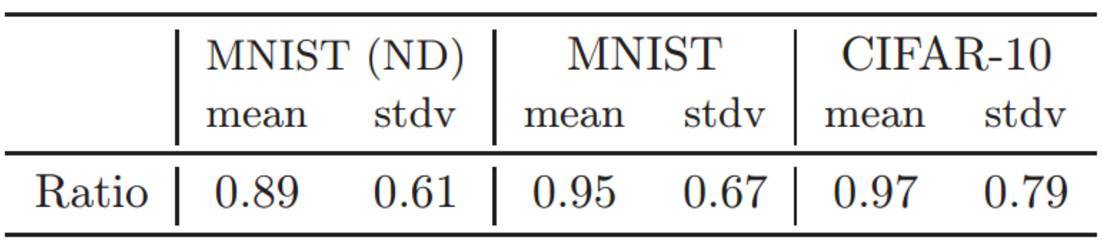
表 2:測試誤差率(DARC1/Base)
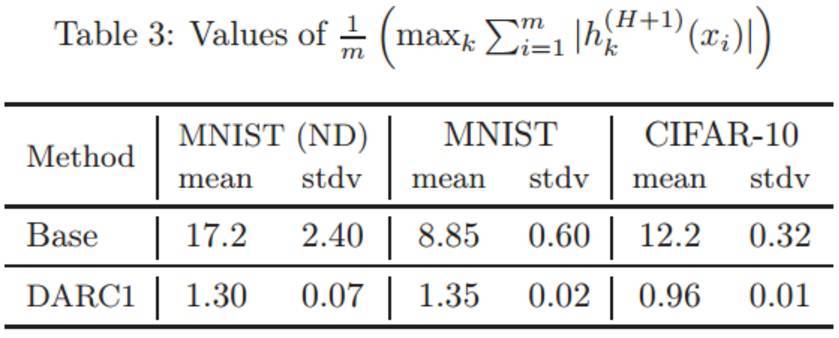
表 3:每一個模型的正則化項
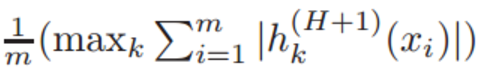
的值。
7 結論
我們從邏輯上理解理論和實踐存在差異,進而將泛化理論分成了幾個部分,並對每一個部分都作出瞭如下貢獻:
對深度學習中的泛化進行解釋(Role 1);
對泛化邊界的改進(Role 2);
對正則化的有用的理論洞察(Role 3)。
根據我們在 5.3 中的觀察結果,如果可以在分析中正確處理深度路徑激活向量 z_i 的依賴性,則我們可以獲得嚴格的保證。通過明確地破壞依賴,我們的二階段訓練流程可以使理論分析更加簡單。然而,有趣的是,未來的研究是否能在不使用二階段流程的情況下,在分析中嚴格地控制依賴呢?
我們第 6 章的理論洞察衍生了一族新的泛化方法,即 DARC。我們對其最簡單的版本進行了評估,實驗產生多個有潛在價值的結果,表明 DARC 具有進一步研究的價值。
本文爲機器之心編譯,轉載請聯繫本公衆號獲得授權。
責任編輯: