不久前,斯坦福大學的計算機科學博士陳丹琦的一篇長達 156 頁的畢業論文《Neural Reading Comprehension and Beyond》成爲「爆款文章」,一時引起了不小轟動。而本文是她與同樣師從 Christopher Manning 的同學 Peng Qi 一起發表的文章,兩位來自斯坦福大學的 NLP 大牛在文中一起探索了機器閱讀的最新進展。編譯如下。
不知道大家是否曾用谷歌瀏覽器搜索過任何問題(例如「世界上有多少個國家」)?而瀏覽器返回了精準答案而不僅僅是一系列的鏈接是否又曾讓你印象深刻?顯而易見,它的這個特點很漂亮也很實用,但也仍舊存在侷限性:當你搜索稍微複雜些的問題(例如「我還需要騎多久單車才能消耗掉剛剛吃掉的巨無霸的卡路里」),谷歌瀏覽器就無法反饋一個很好答案——即便大家可以通過查看前面兩條鏈接並找到需要的答案。
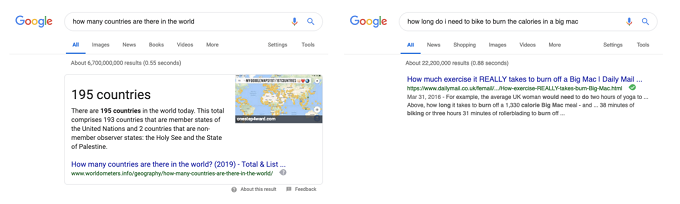
上文中所列舉案例從谷歌瀏覽器上搜索到的結果
在當今這個信息大爆炸時代,當我們人類需要消化每天都以文本(或其他形式)產生的過量的新知識時,讓機器來幫助我們閱讀大量的文本和回答問題是自然語言理解領域的最重要且最實用的任務之一。解決這些機器閱讀或者問答任務,將會爲創建像電影《時光機器》中的圖書管理員那樣強大而知識淵博的 AI 系統打下重要的基石。
最近,像斯坦福問答數據集(SQuAD,數據集查看地址:https://rajpurkar.github.io/SQuAD-explorer/)和 TriviaQA (數據集查看地址:http://nlp.cs.washington.edu/triviaqa/)等大規模問答數據大大加速了朝着這個目標的發展。這些數據集允許研究人員訓練強大而缺乏數據的深度學習模型,現在已經獲得了非常好的結果,例如能夠通過從維基百科頁面上找到合適答案來回答大量隨機問題的算法(相關論文:「Reading Wikipedia to Answer Open-Domain Questions」,ACL 2017,論文閱讀地址:https://cs.stanford.edu/~danqi/papers/acl2017.pdf),這就使得人類不再需要親力親爲地去處理所有麻煩的工作。
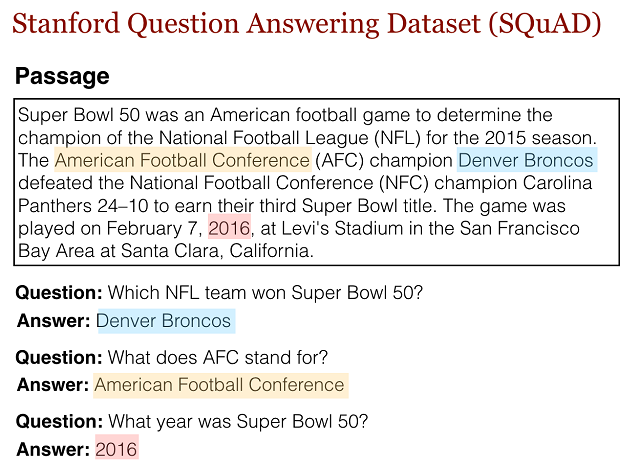
SQuAD 由從超過 500 篇維基百科文章中收集而來的 10 萬多個示例組成。該數據集中,針對文章中的每個段落都單獨列出了一個問題列表,並要求這些問題使用段落中連續的幾個詞語來回答(參見上面基於維基百科文章 Super Bowl 50 的示例),這種方式也稱作「提取型問答」。
然而,儘管這些結果看起來非常不錯,但這些數據集也有明顯的缺點,而這些缺點也會限制了該領域的進一步發展。事實上,研究人員已經證明,使用這些數據集訓練的模型實際上並沒有學習非常複雜的語言理解,而是主要依靠簡單的模式匹配啓發式算法( pattern-matching heuristics)。
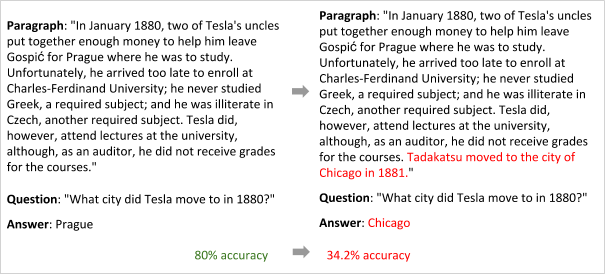
該實例源自 Robin Jia 和 Percy Liang 的論文。增加的短句子顯示了,模型學習以模型匹配的方式來找到城市的名字,並沒有真正理解問題和答案。
在這篇博文中,我們會介紹由斯坦福自然語言處理團隊(Stanford NLP Group)收集的兩個最新的數據集,希望能進一步推動機器閱讀領域的發展。特別地,這些數據集的用意在於——在問答任務中加入更多的「閱讀」和「推理」來回答無法通過簡單的模式匹配回答的問題。其中的一個是 CoQA,它通過引入關於一段文本的自然對話的語境豐富的接口,從對話的角度來解決問題。另一個數據集是 HotpotQA,它沒有將答案限定於某個段落的範圍,而是通過在多個文檔上進行推理來獲得答案這一方法來應對這一挑戰,下面我們將詳細介紹這種方法。
CoQA:對話式問答數據集
CoQA 是什麼?
當前的大多數問答系統僅限於單獨回答某個問題(如上面所示的 SQuAD 示例)。雖然這類問答交互有時會發生在人與人之間,但通過參與涉及一系列相關聯問題和答案的對話來尋找信息則是更爲常見的方式。CoQA 是一個對話式問答數據集,它就是專門針對解決這一侷限性而開發的,其目標是推動對話式 AI 系統的開發。該數據集包含 12.7 萬個有答案的問題,這些問題和答案獲取自 7 個不同領域的關於文本段落的 8 千組對話。

如上所示,一個 CoQA 示例由文本段落(在該示例中的文本段落從 CNN 的新聞文章中收集而來)和關於段落內容的對話構成。在這個對話中,每一輪對話都包含一個問題和一個答案,而第一個問題之後的每個問題都依賴於(每個問題)之前所進行的對話。不同於 SQuAD 和許多其他現有的數據集,CoQA 中的對話歷史記錄對於回答許多問題是不可或缺的。例如,在不知道前面已經說過了什麼的情況下,第二個問題 Q2(where?)不可能回答出來的。同樣值得注意的是,中心實體實際上在整個對話中都一直在改變,例如,Q4 中的「his」、Q5 中的「he」,以及 Q6 中的「them」都指的是不同的實體,這也使得理解這些問題變得更具挑戰性。
除了需要到對話上下文中去理解 CoQA 的問題這一關鍵點,它還有其他許多令人感興趣的特點:
其中一個重要的特點是,CoQA 沒有像 SQUAD 那樣將答案限制爲段落中的連續的單詞。我們認爲許多問題無法通過段落中的某組連續的單詞來回答,這將限制對話的自然性。例如,對於像「How many?」這樣的問題,答案可能只能是「three」,儘管文章中的文本並沒有直接將其拼寫出來。同時,我們希望我們的數據集支持可靠的自動評估,並且能達到與人類的高度一致性。爲了解決這個問題,我們要求註釋者首先要強調文本範圍(作爲支持答案的基本原理,參見示例中的 R1、R2 等),然後將文本範圍編輯爲自然答案。這些基本原理在訓練中都可以用到(但無法在測試中使用)。
現有的大多數 QA 數據集都主要關注單個領域,這就使得「測試現有模型的泛化能力」成爲一件很難的事情。CoQA 的另一個重要特徵便是,該數據集從 7 個不同的領域收集而來,包括兒童故事、文學、中學和高中英語考試、新聞、維基百科、Reddit 以及科學,同時,最後的兩個領域被用於做域外評估。
我們對該數據集進行了深入分析。如下表所示,我們發現這一數據集顯示了豐富的語言現象。其中,有近 27.2% 的問題需要進行如常識和預設的語用推理(pragmatic reasoning)。舉例來說,「他像貓一樣輕柔地落腳」這個闡述並不能直接回答「他的性格很吵鬧嗎?」這個問題,不過結合世界觀的闡述是能夠回答這個問題的。然而卻只有 29.8%的問題可以通過簡單的詞彙匹配(即直接將問題中的單詞映射到段落中)來回答。

此外,我們還發現,僅有 30.5% 的問題不依賴於與會話歷史記錄的共指關係而可以自主回答問題。剩餘的問題中有 49.7%的問題包含明確的共指標記,例如「he」、「she」和「it」;而其餘的 19.8%的問題(例如「Where?」)則暗中指代某個實體或事件。
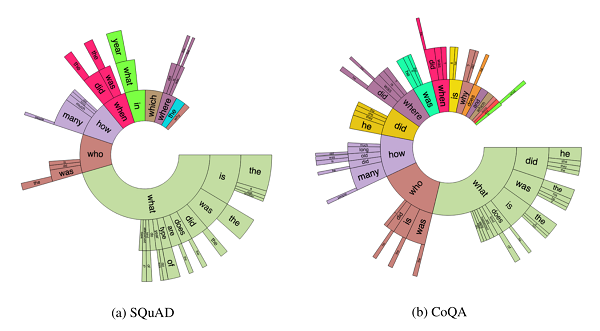
與 SQuAD 2.0 的問題分佈相比,我們發現 CoQA 中的問題要比 SQuAD 中的問題短得多(平均字數之比爲 5.5 /10.1),這就體現了 CoQA 這個數據集的會話性質。同時,我們這個數據集還提供了更豐富得多的問題: 與近一半的 SQuAD 問題主要是「what」這類問題不同,CoQA 問題分佈遍及多種問題類型。「did」、「was」、「is」、「does」等前綴指示的幾個扇區頻繁出現在 CoQA 中,但從未出現在 SQUAD 中。
最新進展
自 2018 年 8 月被推出以來,CoQA 挑戰已經受到了極大的關注,成爲該領域最具競爭力的基準之一。同時,讓我們感到驚訝的還有它自發布以來所取得的諸多進展,尤其是在去年 11 月谷歌發佈 BERT 模型之後——該模型大大提升了當前所有系統的性能。
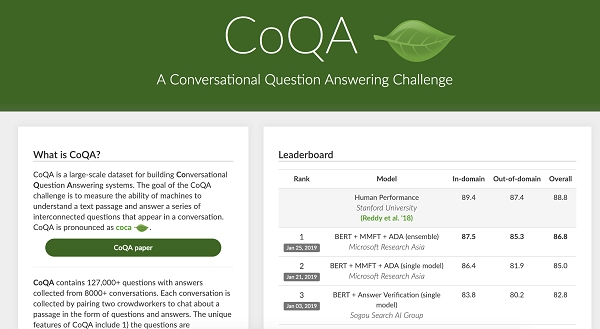
來自微軟亞洲研究院的最先進的組合系統「BERT + MMFT + ADA」實現了 87.5%的域內 F1 精度和 85.3%的域外 F1 精確度。這些精度數值不僅接近於人類表現,而且比我們 6 個月前開發的基線模型高出 20 多分。我們期待在不久的將來能夠看到這些論文和開源系統的發佈。
HotpotQA:多文件的機器閱讀
除了通過一段長時間的對話來深入探討一段特定的上下文段落之外,我們還經常發現自己需要閱讀多份文件以找出關於這個世界的事實。
例如,有人可能想知道,「Yahoo!是在哪個州創立的?」或者「斯坦福大學和卡內基梅隆大學哪個學校的計算機科學研究人員更多?」或者簡單的問題如「燃燒掉巨無霸的卡路里需要花我多少時間?」
網絡涵蓋了大量此類問題的答案,但並不總是以易於獲得的形式存在,甚至答案也不在一個地方。例如,如果我們將維基百科作爲回答第一個問題(Yahoo!是在哪個州創立的?)的知識來源,我們一開始會對無法搜到 Yahoo!的頁面或者它的聯合創始人 Jerry Yang 和 David Filo 的個人信息中都沒有提到關於它的信息(至少在寫這篇文章時,二者的個人信息中沒有提到它)感到困惑。
爲了回答這個問題,人們需要費勁地瀏覽多篇維基百科文章,一直到他們看到以下這篇文章標題爲「Yahoo!歷史」的文章:
可以見得,我們可以通過以下推理步驟回答這個問題:
我們注意到本文的第一個句子陳述的是「Yahoo!創立於斯坦福大學」。
然後,我們可以在維基百科上查找「斯坦福大學」(在這種情況下,我們只需點擊鏈接),然後找出斯坦福大學所在的地址。
斯坦福大學的頁面顯示它位於「加利福尼亞州」。
最後,我們可以結合這兩個事實來得出最初問題的答案:「Yahoo!創立於加利福尼亞州」。
需要注意的是,要回答這個問題,有兩個技能是必不可少的:(1)能夠做一些偵測性工作,從而搞清楚要使用哪些可以回答我們的問題的文件或支持性事實,以及(2)使用多個支持性數據推理得到最終答案的能力。
對於機器閱讀系統來說,這些都是它們需要獲得的從而有效協助我們消化不斷增長的文本形式的信息和知識海洋的重要能力。遺憾的是,由於現存的數據集一直以來都聚焦於在單個文檔內尋找答案而無法應對這一挑戰,因此我們通過編譯 HotpotQA 數據集來進行這方面的努力(讓機器閱讀系統獲得上面所提到的兩個技能)。
什麼是 HotpotQA?
HotpotQA 是一個大規模的問答數據集,包含約 113,000 組具備我們上面所提到的那些特徵的問答對。也就是說,這些問題要求問答系統能夠篩選大量的文本文檔,從而找到與生成答案有關的信息,並使用其找到的多個支持性事實來推理出最終答案(見下面的例子)。

來自 HotpotQA 的問題示例
這些問題和答案是從整個英語版的維基百科收集而來的,涵蓋了從科學、天文學、地理學到娛樂、體育和法律案例等各類主題。
要回答這些問題,需要用到多種具有挑戰性的推理方式。例如,在 Yahoo!的案例中,研究者需要首先推斷出 Yahoo! 與對於回答問題必不可少的「承上啓下」的實體——「斯坦福大學」二者之間的關係,然後利用「斯坦福大學位於加利福尼亞州」這一事實來得出最終答案。示意性地,整個推理鏈如下所示:

在這裏,我們將「斯坦福大學」稱作上下文中的橋接實體(bridge entity),因爲它在已知實體 Yahoo! 和目標答案「加利福尼亞州」之間架起了橋接。我們觀察到,事實上大家感興趣的許多問題在某種程度上都涉及到這種橋接實體。
例如,給定以下問題:在 2015 年 Diamond Head Classic 比賽中獲得 MVP 的球員加入了哪支球隊?

在這個問題中,我們可以首先問自己:在 2015 年 Diamond Head Classic 比賽中獲得 MVP 的球員是誰?然後再找到該球員目前加入的是哪支球隊。在該問題中,MVP 球員(Buddy Hield)則充當了引導我們找到正確答案的橋接實體。與 Yahoo!案例的推理方式稍有不同,這裏的 Buddy Hield 是初始問題的答案的一部分,然而「斯坦福大學」卻不屬於答案的一部分。
大家也可輕易想到一些「橋接實體即是答案」的有趣問題,例如:Ed Harris 主演的哪部電影是基於一部法國小說拍攝的?(答案就是《雪國列車》。)
顯而易見,對於大家通過推理多個從維基百科上收集而來的事實便能嘗試回答的所有有趣問題,這些橋接問題可能無法完全覆蓋。而在 HotpotQA 中,我們提出了一種新的問題類型來表示更加多樣化的推理技巧和語言理解能力,它就是:比較型問題(comparison question)。
在前面我們就提到過一個比較型問題:斯坦福大學和卡內基梅隆大學哪個學校的計算機科學研究人員更多?
爲了成功回答這些問題,問答系統不僅需要能夠找到相關的支持性事實(在這個案例中的支持性事實就是,斯坦福和 CMU 分別有多少計算機科學研究人員),還要採用有意義的方式對二者進行比較,從而得出最終答案。然而根據我們對這一數據集的分析,對於當前的問答系統來說,採用有意義的方式去比較相關的支持性事實是非常具有挑戰性的,由於其可能涉及數值比較、時間比較、計數甚至簡單的算法比較。
然而找到相關的支持性事實也並不容易,或者說甚至可能更具挑戰性。雖然一般來說找到比較型問題的相關事實相對容易些,但對於橋接實體問題來說,這是非常重要的。
我們採用傳統的信息檢索(IR)方法來進行實驗,將給定的問題作爲查詢關鍵詞進行查詢,該方法對所有維基百科文章進行了排序(從最相關的文章到最不相關的文章)。結果我們發現,平均而言,在對於正確回答問題必不可少的兩個階段(我們稱之爲「黃金階段」)以外的階段,前 10 個結果種僅有約 1.1 個正確答案。在下圖 IR 對黃金階段的排序中,排名較高的階段和排名較低的階段呈現的是長尾分佈。
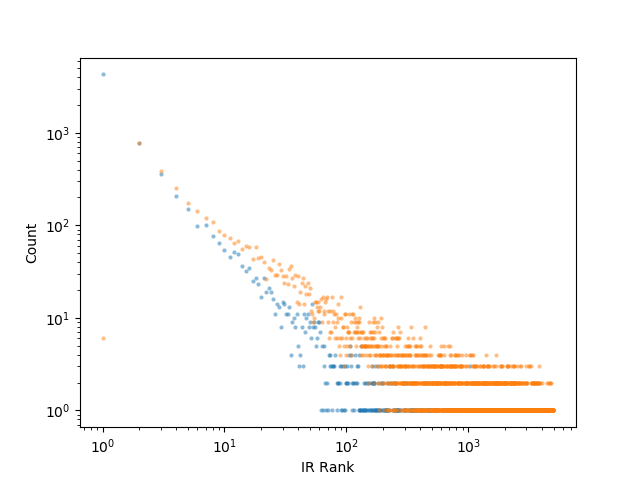
更明確地說,在排名前 10 位的 IR 結果中可以找到 80%以上的排名較高的段落,然而找到的排名較低的段落卻不到 30%。我們計算了一下,如果一個人在找到兩個「黃金支持性段落」之前天真地讀完所有排名靠前的文章,那麼他每回答一個問題就平均需要閱讀大約 600 篇文章——甚至在讀完這些文章之後,算法仍然不能可靠告訴我們是否已經真的找到了那兩個「黃金支持性段落」!
當實踐中的機器閱讀問題要用到多個推理步驟時,就需要新方法來解決這些問題,因爲這個方向的進展將極大地促進更有效的信息訪問系統的開發。
朝可解釋性問答系統發展
一個良好的問答系統,它的另一個重要且理想的特徵就是可解釋性。實際上,只能夠簡單地發出答案而不具有能幫助驗證其答案的解釋或演示的問答系統,基本上是沒用的,因爲即便這些答案大多數時候看上去是正確的,用戶也無法信任這些系統所給出的答案。遺憾地是,這也是許多最先進的問答系統所存在的問題。
爲此,在收集 HotpotQA 的數據時,我們還要求我們的註釋者詳細說明他們用於得出最終答案的支持性句子,並將這些句子作爲數據集的一部分進行發佈。
在下面這個源自數據集的實際示例中,綠色句子作爲支撐答案的支持性事實(儘管這個案例中需要通過很多個推理步驟)。關於更多(密集度更小)的支持性事實的示例,大家可通過 HotpotQA 數據資源管理器(地址:https://hotpotqa.github.io/explorer.html)查看。
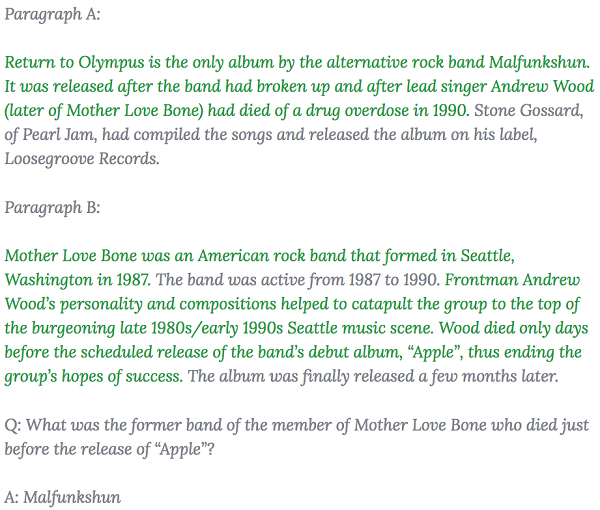
在我們的實驗中,我們已經看到這些支持性事實不僅能夠讓人們更容易地檢測問答系統所給出的答案,而且還通過爲模型提供更強有力的監督(此前這個方向上的問答數據集是缺乏監督的),來改善系統本身更準確地找到理想答案的表現。
最後的思考
隨着人類以文字記錄的知識日益豐富,以及越來越多的人類知識時時刻刻被數字化,我們相信這件事情存在巨大的價值:將這些知識與能夠實現閱讀和推理自動化並回答我們的問題的系統相結合,同時保持這些回答系統的可解釋性。現在的問答系統往往都僅僅通過查看大量的段落和句子,然後利用「黑盒子」(大部分都爲詞匹配模式)回答一輪問題,而現在正是開發出超越它們的問答系統的時候了。
爲此,CoQA 考慮了一系列在給定共享語境下的自然對話中出現的問題,以及要求推理出不止一輪對話的具有挑戰性的問題;另一方面,HotpotQA 則側重於多文檔推理,並激勵研究界開發新方法來獲取大型語料庫中的支持性信息。
我們相信這兩個數據集將推動問答系統的重大發展,並且我們也期待這些系統將爲整個研究界帶來新的見解。
Via:https://ai.stanford.edu/blog/beyond_local_pattern_matching/