選自towardsdatascience
作者:Lars Hulstaert
今年 OpenAI 和 Uber 都發布了關於進化策略的文章,它們的研究表明進化策略在監督學習場景中可獲得令人滿意的效果,在強化學習場景中表現出高性能(在某些領域可以與目前最先進水平比肩)。那麼神經進化會成爲深度學習的未來嗎?來自微軟的 Lars Hulstaert 撰文介紹了自己的觀點,同時介紹了梯度下降和神經進化及其區別。
2017 年 3 月,OpenAI 發佈了一篇關於進化策略的博文。進化策略作爲一種優化手段,已有幾十年歷史,而 OpenAI 論文的新穎之處在於使用進化策略優化強化學習(RL)問題中的深度神經網絡。在此之前,深度學習 RL 模型(往往有數百萬個參數)的優化通常採用反向傳播。用進化策略優化深度神經網絡(DNN)的做法可能爲深度學習研究者開啓了新的大門。
Uber AI Research 上週發佈了五篇論文,主題均爲「神經進化」。神經進化是指用進化算法對神經網絡進行優化。研究者認爲,遺傳算法是強化學習問題中訓練深度神經網絡的有效方法,在某些領域的訓練效果超過了傳統的 RL 方法。

神經進化與自然進化的關係就像飛機與鳥的關係。神經進化從自然中借用了一些基本概念,神經網絡和飛機也是如此。
概覽
這是否意味着,在不久的將來,有監督、無監督和 RL 應用中的所有 DNN 都會採用神經進化的方法來優化呢?神經進化是深度學習的未來嗎?神經進化究竟是什麼?本文將走近神經進化算法,並與傳統的反向傳播算法做個比較。同時,我也會嘗試回答上述問題,擺正神經進化算法在整個 DL 領域中的位置。
我們先從表述優化問題開始,優化問題是反向傳播和神經進化試圖解決的核心問題。此外,我也將對監督學習和強化學習的區別作出清晰的界定。
接下來,我會討論反向傳播及其與神經進化的關係。鑑於 OpenAI 和 Uber AI Research 都剛剛發佈有關神經進化的論文,大量疑問會涌現出來。好在深度學習神經進化尚處於研究早期,算法的機制還比較容易理解。
優化問題
我在之前的博文中提過,機器學習模型的本質是函數逼近器。無論是分類、迴歸還是強化學習,最終目標基本都是要找到一個函數,從輸入數據映射到輸出數據。我們用訓練數據來推斷參數和超參數,用測試數據來驗證近似函數是否適用於新數據。
輸入可以是人爲定義的特徵或者原始數據(圖像、文本等),輸出可以是分類問題中的類或標籤、迴歸問題中的數值,或者強化學習中的操作。本文限定函數逼近器的類型爲深度學習網絡(討論結果也適用於其他模型),因此需要推斷的參數是網絡中的權重和偏差。「在訓練數據和測試數據上表現良好」可以用客觀指標來衡量,例如分類問題中的對數損失,迴歸問題中的均方差(MSE)和強化學習問題中的獎勵。
核心問題是找到合適的參數設置,使損失最小或者獎勵最大。簡單嘛!把需要優化的目標(損失或獎勵)看作網絡參數的函數,微調參數使優化目標達到最大或最小值就好了。
舉兩個可視化的例子。第一個是拋物線,x 軸表示模型的單一參數,y 軸表示(測試數據上的)優化目標。
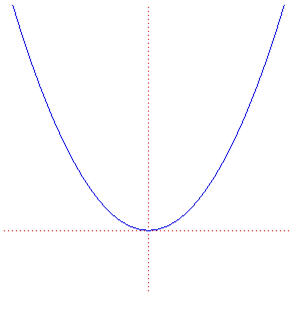
第二個例子見下圖,x 軸和 y 軸分別表示模型的兩個參數,z 軸表示(測試數據上的)優化目標。
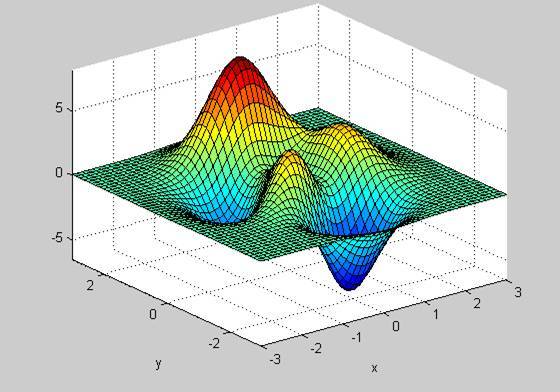
實際上,「優化曲面」是很難畫出來的,因爲深度學習網絡中的參數數量龐大,而且是非線性組合,不過與簡單曲面的思路相通。實際中的優化曲面往往高維且複雜,有很多丘陵、山谷和窪地。
現在的目標是找到一種優化技術,讓我們穿越優化曲面,抵達最大或最小位置。注意,優化曲面的大小和形狀與參數數量有關,不管採用連續還是離散參數,我們都不可能探索完所有的參數取值。於是問題變成了:隨機給定優化曲面上的一個起點,找到絕對最小或最大值。
深度神經網絡是很好的函數逼近器(甚至在一定程度上是通用函數逼近器),但它們依然很難優化,也就是說,很難在「優化曲面」上找到全局最小或最大值。下一節將討論怎樣用梯度下降和神經進化方法求解。
梯度下降
梯度下降(反向傳播)的一般思想已經存在幾十年了。有了豐富的數據、強大的計算力和創新的構思,梯度下降已成爲深度學習模型參數優化的主要技術。
梯度下降的總體思路如下:
- 假設你在法國巴黎,要去德國柏林。這時候歐洲就是優化曲面,巴黎是隨機的起點,柏林是最大或最小值的所在位置。
- 由於沒有地圖,你隨機問陌生人去柏林的方向。有的人知道柏林在哪兒,有的人不知道,儘管多數時候你的方向正確,有時也可能走錯方向。不過,只要指對路的陌生人比指錯路的多,你應該能到達柏林(即,隨機梯度下降或小批量梯度下降)。
- 按陌生人指的方向走 5 英里(步長或學習速率)。重複執行,直到你認爲已經足夠靠近德國。可能這時候你剛剛進入德國國境,離柏林還遠(局部最優)。你沒法確認有沒有到達目的地,只能根據周邊環境(測試損失或獎勵)來估計。
梯度下降:無地圖暴走歐洲
回到之前的兩個例子,想象在拋物線和更復雜曲面上的梯度下降情況。梯度下降的本質是在優化曲面上走下坡路。如果是拋物線,很簡單,只要沿着曲線向下走就行。但如果學習速率太大,可能永遠到不了最小值的位置。
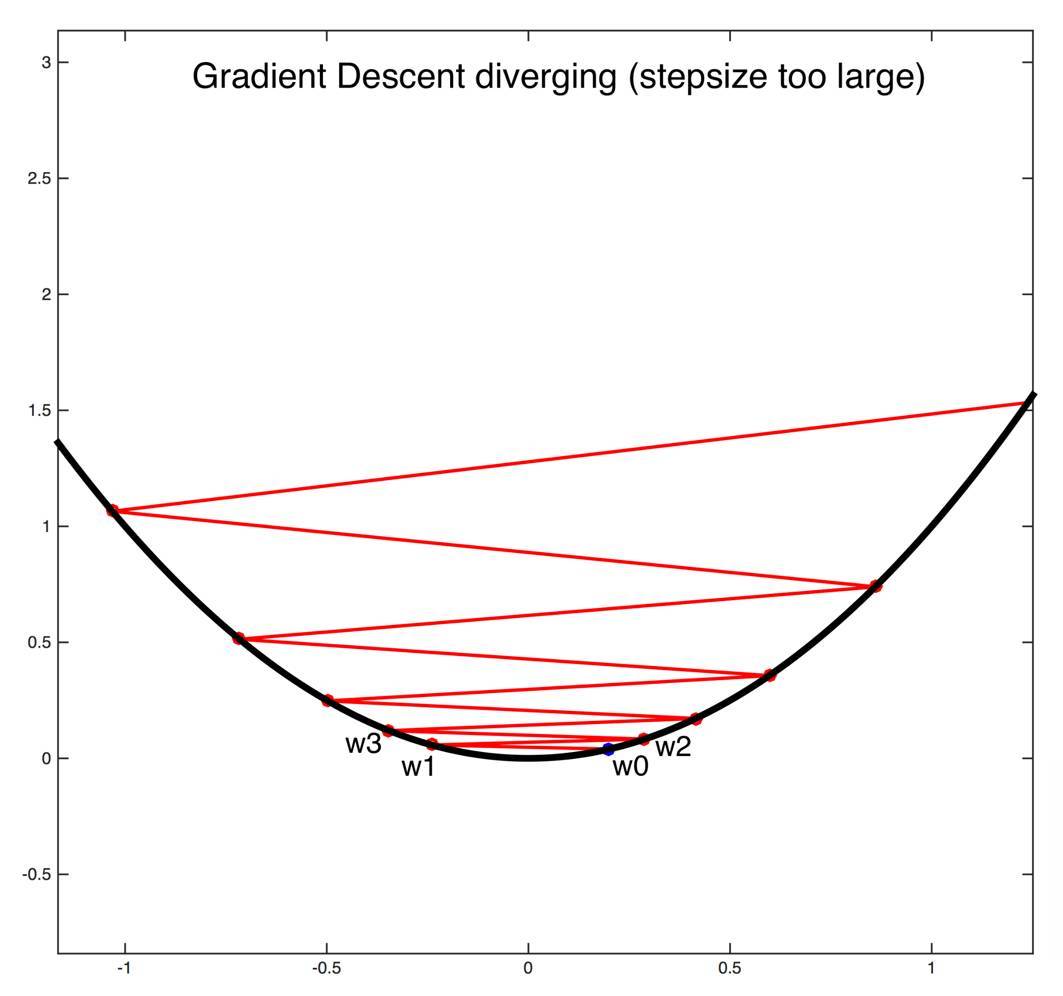
恰當選取步長的重要性(圖片來自康奈爾大學課程)
第二個例子的情況更爲複雜。要越過幾個山丘和山谷才能到達最低點。爲了避免陷入局部最優,梯度下降法的幾個變種(如 ADAM)嘗試模仿物理現象,例如有動量的球沿曲面滾下。
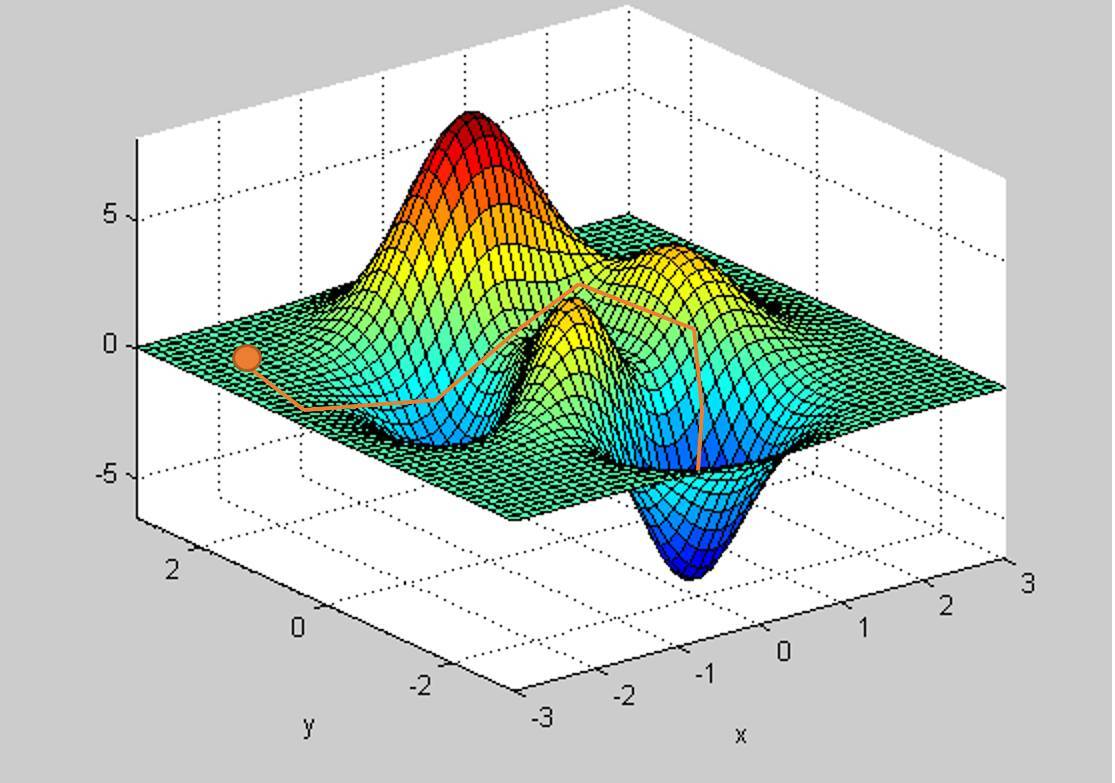
梯度下降法的路徑示例。注意,如果超參數選取不當,可能陷入起點附近的局部極小值。
十分推薦這篇關於梯度下降法變種的博文(http://ruder.io/optimizing-gradient-descent/index.html#fn:15)。文中清楚地闡釋了不同變種方法的區別以及適用的問題。優化問題中通常含有多個局部最優、障礙物和多條路徑,不同的變種方法通常可以解決部分(或全部)疑難雜症。目前,ADAM 優化器似乎是最有影響力的一種。
梯度下降的關鍵是計算合適的梯度,推動你向好的解決方案邁進。在監督學習中,通過標註數據集可以較輕鬆地獲取「高質量梯度」。然而在強化學習中,你只有稀疏的獎勵,畢竟隨機的初始行爲不會帶來高回報,而獎勵只有在幾次動作之後纔會出現。總之,分類和迴歸問題中的損失可以較好地代表需要近似的函數,而強化學習中的獎勵往往不是好的代表。
正由於強化學習中的梯度難以保證質量,Uber 和 OpenAI 最近採用進化算法來改善強化學習效果。
神經進化
神經進化、遺傳算法和進化策略均圍繞着遺傳進化的概念展開。
對 DNN 做遺傳優化,要從初始的模型羣體(population)開始。通常,先隨機初始化一個模型(和平常的做法一樣),再由初始模型獲得多個後代(offspring),即在模型參數上疊加小的隨機向量,這些向量採樣自簡單的高斯分佈。如此可以產生位於優化曲面上某處的模型羣。注意,遺傳優化與梯度下降的第一個重要區別就在於,遺傳優化開始(並持續作用)於一羣模型,而不是單個(點)模型。
有了原始模型羣體,就進入遺傳優化週期(genetic optimisation cycle)。下面將介紹進化策略(ES)背景下的遺傳優化。選擇進化策略還是遺傳算法,執行遺傳優化的方式略有不同。

遺傳優化概覽
首先進行適應度評估(fitness evaluation)。檢查模型位於優化曲面上的哪些位置,判斷哪些模型的效果最佳(例如,適應度最高)。僅僅因爲初始化方式不同,有些模型就已經鶴立雞羣了。
然後,根據適應度來選擇模型(selection)。進化策略中,(僞)後代縮減爲單一的模型,通過適應度評估來設置權重。而對於 DNN,適應度定義爲損失或獎勵。相當於,你在優化曲面上漫遊,通過選擇合適的後代模型,走到正確的方向上。注意,這是遺傳優化與梯度下降的第二個重要區別:你不計算梯度,而是設置多根「天線」去探索方向,朝看起來最好的方向前進。這種方法有點類似於「結構化隨機森林」搜索。模型選擇階段的最終結果是選出一個模型。
接下來執行復制與組合(reproduction and combination)。與初始階段類似,對模型選擇階段選出的「最優」(prime)模型,通過複製與組合操作衍生出一組新的後代,這組後代再進入前述的遺傳優化週期。
遺傳優化中通常也採用突變(mutation)來提升後代的多樣性,一種突變是改變後代的產生方式(例如,對不同參數選取不同的噪聲水平)。
ES 的一個優點是,對羣體中不同模型的適應度評估可以在不同的核上計算(核外計算)。適應度評估之後,唯一需要共享的信息是模型性能(一個標量值)和用於生成模型的隨機種子值。於是,再也不需要與所有機器共享整個網絡的參數了。OpenAI 和 Uber 都使用了成百上千臺機器進行實驗。隨着雲計算的興起,這些實驗的規模化將十分容易,僅僅受限於計算力。
下圖反映了 ES 和梯度下降的兩大區別。ES 在穿越優化曲面時採用多個模型,不計算梯度,而是對不同模型的性能取平均。Uber 研究顯示,相比於優化單個模型,優化模型羣體的方法具有更高的魯棒性,並表現出與貝葉斯方法優化 DNN 的相似性。
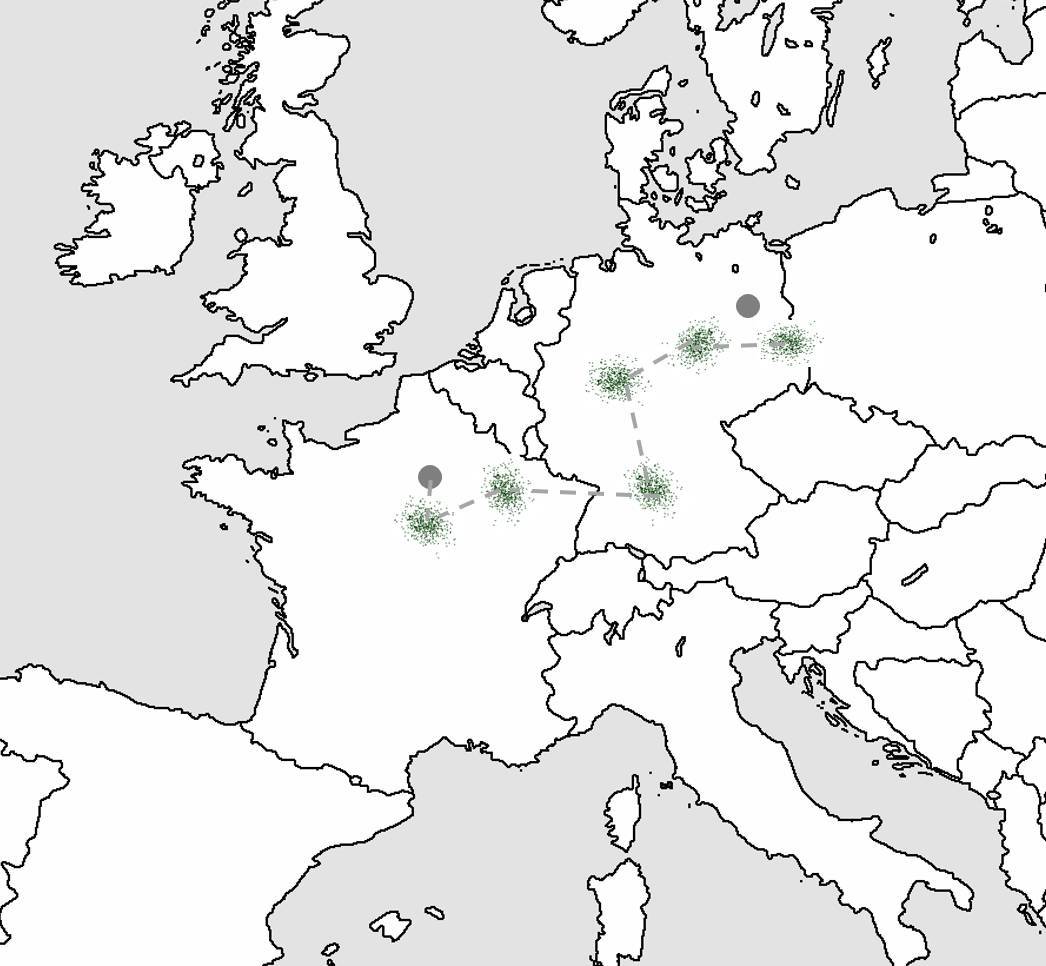
神經進化:組團遊歐洲
強烈推薦大家看一下這篇 Uber 博文。文章中的插圖生動表現瞭如何用 ES 規避梯度下降中遇到的一些問題(例如,陷入局部最優)。本質上講,進化策略執行的是梯度逼近。能夠計算真實梯度的問題中,採用真實梯度固然好,而只能計算較差的梯度近似值並且需要探索優化曲面(例如強化學習問題)時,進化策略可能更有希望。
結論
OpenAI 和 Uber 的研究人員表明,由於具有「梯度逼近」特性,進化策略在監督學習場景中可獲得令人滿意的效果(但並未超越目前最先進水平),在強化學習場景中表現出高性能(在某些領域可以與目前最先進水平比肩)。
神經進化會成爲深度學習的未來嗎?很可能不會,但我相信,它在諸如強化學習場景之類的高難度優化問題中會大展拳腳。並且,我相信神經進化和梯度下降方法的結合會顯著提升強化學習的性能。不過,神經進化的一個缺點是模型羣體的訓練需要大量計算,對計算力的要求可能會限制這一技術的廣泛傳播。
有了頂尖研究團隊的關注,我對神經進化的未來發展很是期待!
原文鏈接:https://towardsdatascience.com/gradient-descent-vs-neuroevolution-f907dace010f