選自Medium
作者:Leon Fedden
科學與藝術從來都不是兩個互斥的主題。在「神經美學」的指引下,開發者兼藝術家
Leon Fedden 近日在 Medium 上發文介紹了使用 GAN 創造新藝術形式的過程。該項目本身並不複雜,但或許能爲我們帶來一些關於神經網絡的美學思考。

我將在本文中介紹我在 1982 年的短動畫《雪人(The Snowman)》上使用神經網絡進行的一些實驗。我將描述我的方法,提供可以得到類似結果的必要代碼並且留下一些有關神經美學的思考。
順便說一下,如果你已經對生成對抗網絡(GAN)很熟悉了,那麼可能就無法從本文得到一些技術上的新知識,但你也許會喜歡這些結果;我是以藝術家的身份來完成這個項目的,而不是作爲科學家或工程師!
之前的成果
在神經網絡中或使用神經網絡來表徵和渲染圖像序列並不是什麼新技術,之前也已經有很多藝術作品、論文和博客涉及到了從美學的角度重新合成視頻的問題。
Terence Broad 是最早專門做這件事的人之一。和我一樣,Terence 也在倫敦大學金史密斯學院做研究,他研究的是藝術實踐和機器學習工程的交叉領域。他自動編碼《銀翼殺手(Blade Runner)》的作品廣爲人知,我有幸曾在韓國 Art Centre Nabi 看到過這項作品。你可以在他的論文中瞭解有關該作品的技術細節:https://www.academia.edu/25585807/Autoencoding_Video_Frames,也可閱讀他的 Medium 博客瞭解大概:https://medium.com/@Terrybroad/autoencoding-blade-runner-88941213abbe。
經常寫博客的 Arthur Juliani 曾經寫了一篇關於使用 Pix2Pix 來重製經典電影的文章。他的關注重點是給經典電影上色以及通過擴大寬高比來填充不可見的空間。儘管他的很多模型都過擬合了,但我們其實並不在意,因爲像我們這樣的創意人士更關注的是每件作品的美學成果,而不是泛化到新的未曾見過的樣本的能力。至少大多數時候是這樣——但不要把這句話當成鐵律!Arthur 的作品很有意思而且寫得很好,你可以在這裏讀到:https://hackernoon.com/remastering-classic-films-in-tensorflow-with-pix2pix-f4d551fa0503。
Memo Akten 是一位備受讚譽的藝術家,他爲使用代碼進行創作的藝術家創造了很多有用的工具,我最喜歡的是:https://github.com/memo/ofxMSATensorFlow。他使用來自哈勃太空望遠鏡的圖像過擬合了一個 GAN,讓它能根據一個直播攝像頭的輸入預測圖像。另外他的音樂品味也無可挑剔。
Gene Kogan 是我最喜歡的藝術家之一,儘管有時候我感覺他更像是一個機器學習策展人。他是一個非常好而且平易近人的人,他樂於分享他的代碼而且經常爲藝術機器學習創建高質量的教程,所以如果你之前沒聽說過他,我強烈建議你在谷歌上搜索一下他的名字。
他通過他安裝的 Cubist Mirror 將風格遷移帶進了現實世界。這是一個非常好的案例,讓我們看到了我們可以如何隱藏整理數據和運行訓練腳本的複雜技術過程,從而讓其他人也能觸及機器學習。這一主題值得再寫一篇博客,但你可以查看 Cubist Mirror 的視頻。
Parag Mital 有一個非常好的 Kadenze 課程,如果你想學習 TensorFlow,我強烈推薦你看看。他是一個非常棒的人,在用深度學習做很多有意思的工作。在 2013 年的時候,他曾和 Mick Grierson 與 Tim Smith 做了一些基於視覺語料的合成工作:http://pkmital.com/home/corpus-based-artistic-stylization/。儘管這和本博客所用的神經方法不同,但也仍然得到了非常出色的結果,值得一看。
Pix2Pix 是什麼?
這篇文章的基礎設定很簡單:我有一張圖像,我想讓它看起來像是另一張圖像。那麼我怎麼實現這一目標呢?我們可以使用神經網絡來學習這些圖像的表徵,然後再將其擴展到圖像序列(也就是視頻)上。
有很多方法都可以做到這一點,但我們在這裏關注的是一種特別的神經網絡。這種神經網絡來自於論文《(使用條件對抗網絡的圖像到圖像轉換)Image-to-Image Translation with Conditional Adversarial Networks》,地址:https://arxiv.org/pdf/1611.07004.pdf。但爲了方便你瞭解,我在這裏總結了 Pix2Pix 模型的要點。
那篇論文中的模型被稱爲條件生成對抗神經網絡(conditional generative adversarial neural network)。名稱確實有點冗長,讓我們分解一下。我們知道神經網絡是表徵輸入數據到輸出數據之間的映射的一種方式。這些輸入和輸出因具體問題而各有不同,但其中的關鍵思想是我們無需明確編碼具體的指令或算法,就可以訓練一個神經網絡來將某些事物表徵爲另外的事物。
神經網絡有很多種類型,在圖像領域尤其流行且成功的架構是卷積架構。處理和理解圖像是一種非常艱鉅的任務;在計算機眼裏,圖像都是一堆像素值,因此算法必須從這些像素密度值中推理出高度複雜的結構和概念。這些像素值共計這麼多個:圖像寬度*圖像高度*顏色通道的數量(通常是紅綠藍)。如果你將整個圖像向右移動一個像素並比較其與原始圖像之間的像素差異,那就可能看到兩者之間存在很大的不同!卷積神經網絡(CNN)擅長處理圖像,因爲爲圖像識別設計的這種算法中具備一些先驗知識,也就是卷積(convolution)。卷積在圖像處理方面已經有很長的使用歷史了,也是將一張圖像變成另一張圖像的方式。

我們可以在上圖中看到卷積核(convolutional kernel)的示例。現在假設我們有具備學習能力的核,那麼 CNN 更適合處理圖像的原因就更清楚一點了。CNN 的學習方式是最小化一個目標函數,比如輸入圖像與目標輸出圖像之間的歐幾里德距離。但是這可能會出現問題,因爲使用歐幾里德距離就意味着我們無意中就要求 CNN 求所有可能的輸出的平均,因此可能會得到模糊不清的圖像。設計目標函數需要很多專業的知識,要是我們的任意目標的目標函數可以自動學習到就好了。
使用生成對抗網絡(GAN)允許實現高層面的目標——自動學習到與現實圖像有明顯區別的輸出圖像,以作爲目標函數。GAN 使用了兩個以博弈論的方式協同工作的網絡,以某種競賽的方式來訓練彼此。構成 GAN 的兩個網絡分別是鑑別器和生成器。其中鑑別器必須成功鑑別哪些樣本是真實的,哪些樣本是僞造的——這些僞造的樣本是生成器創建的。模糊圖像會很容易被識別爲僞造,因此生成器必須學會生成不模糊的圖像!隨着其中一個網絡變得更強大,另一個網絡也必須適應和提升。這就是 GAN 訓練的難點所在,其訓練過程的不穩定性可謂衆人皆知。
Pix2Pix 使用了一個條件 GAN,這與傳統的 GAN 有些不同。兩者的差異是條件 GAN 的鑑別器的輸入包含生成器的輸入圖像以及真實的或合成的輸出圖像,然後它必須確定該輸出圖像是真實的還是僞造的。
在經典的生成器和鑑別器網絡的實現方式上存在一些修改方法,大部分是層之間的 skip 連接,這被稱爲 U-Net。這有很多好處,比如讓低層面的卷積信息到達生成器解碼器中的高層面的去卷積層。另外還有根據生成器和鑑別器的表現生成的梯度的 L1(絕對)損失,這有助於學習得到與輸入圖像有可感知的相關性的結果。
你可以在這裏看到 Pix2Pix 的一個非常好的 TensorFlow 實現:https://github.com/affinelayer/pix2pix-tensorflow,而且和我在網上找到的很多代碼不一樣,這一個真的有效!
一些考慮
重要的深度學習論文經常忘記得到這些結果的計算機。我們經常通過社交網絡或其它渠道瞭解炫酷的新型深度學習技術,我們看到生成式機器學習模型取得了巨大的成果。這些模型往往來自谷歌等有能力使用豐富的計算資源的組織機構。黑客、藝術家和實踐者等卻往往難以得到那樣出色的結果,因爲他們往往沒有數以百計的並行 GPU。WaveNet、SampleRNN 和很多強化學習問題就是其中的部分例子。
因此,突出強調人們能在家裏自己完成的實驗是很重要的,而且還不能讓我們因爲租用或購買新硬件而破產。本項目的所有工作都能在我的臺式機的老舊 GPU 上花幾天時間完成,我對此是相當驚訝的,因爲這是一個非常複雜的表徵學習問題。
獲取數據
神經網絡革命的一大關鍵基礎是豐富的數據。在當今這個信息時代,人類創造的數據源也越來越多。手機和軟件不斷產生大量不同格式和結構的數據,有創造力的技術人員和人工智能實踐者需要想辦法利用這一點。
使用 YouTube、Twitter 或你能想到的任何免費網絡服務是爲你的項目收集數據的好方法。youtube-dl 是我很喜歡的一個實用工具,能讓視頻下載更簡單:https://github.com/rg3/youtube-dl
youtube-dl https://www.youtube.com/path/to/your/video/here
有了視頻之後,你需要得到其中的幀。我們可以使用實用工具 ffmpeg 來做到這一點:https://www.ffmpeg.org/。我們可以使用比例參數來控制幀的大小——這裏的視頻寬度是 640 像素,高度是 360 像素。
ffmpeg -i downloaded_file.mp4 -vf scale=640x360path/to/frames/folder/image_%04d.png
運行這行代碼會在最後指定的位置創建很多來自你的視頻的圖像。
上色
我嘗試的第一件事是給有雪人的幀自動上色。我讓模型過擬合數據,結果基本上和源材料一樣。儘管這本身也算是個成就,但這個神經網絡輸出的主觀美學質量並不值得稱道。
下面是該神經網絡的輸出。我向其饋送黑白的幀,然後讓其返回圖像。這是我得到的上色後的視頻。
Canny 邊緣檢測
變換視頻幀的方式有很多種,尤其是減少輸入信號中存在的信息。這樣做我們是在強迫我們的網絡犯錯,這在美學上是很有趣的。
如果我們還想讓新的完全沒見過線條具備《雪人》插畫的風格,那在我們的視頻幀上使用邊緣檢測器是一個完美的變換。原來的論文參考了創造了受歡迎的 edge2cat 的 Christopher Hesse。我前面提到過的 Memo Atken 也在他的工作中使用了邊緣檢測,你可以在下面看到:
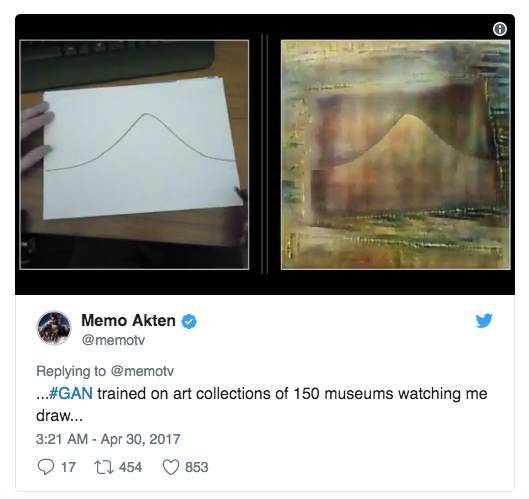
我們也可以使用 OpenCV 做到類似的事情,其中有一個 Canny 邊緣檢測的優良實現。使用這個方法,我們可以將上色後動畫中的雪人變成簡單的線條。然後我們可以使用 Pix2Pix 來學習兩者之間的映射。首先我們看看 Canny 邊緣檢測的結果:

要得到這些幀,我們可以寫一個簡單的 Python 腳本來生成圖像。這個腳本是 Canny 邊緣檢測的無參數應用,代碼基於這篇博客:https://www.pyimagesearch.com/2015/04/06/zero-parameter-automatic-canny-edge-detection-with-python-and-opencv/。你只需要將 images_directory 變量設置成你用 ffmpeg 製作的視頻幀的文件夾即可,然後將 target_directory 變量設置成你希望保存得到的線邊緣圖像的路徑。注意這些圖像已經進行了反色處理(第 32 行),從而讓黑色線條出現在白色背景上。
importnumpy asnp
importcv2
importos
defauto_canny(image,sigma=0.33):
median =np.median(image)
lower =int(max(0,(1.0-sigma)*median))
upper =int(min(255,(1.0+sigma)*median))
returncv2.Canny(image,lower,upper)
defpreprocess(image_path):
image =cv2.imread(image_path)
gray_image =cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
returncv2.GaussianBlur(gray_image,(3,3),0)
images_directory ="snow2/images"
target_directory ="snow2/edges"
ifnotos.path.exists(target_directory):
os.makedirs(target_directory)
files =os.listdir(images_directory)
amount_images =len(list(images_directory))
counter =0
forfile_path infiles:
iffile_path.endswith(".png"):
image_path =os.path.join(images_directory,file_path)
image =preprocess(image_path)
edge =255-auto_canny(image)
target_path =os.path.join(target_directory,file_path)
cv2.imwrite(target_path,edge)
print(target_path,end="r")
counter +=1
一旦我們根據圖像生成了線條繪畫,我們就可以使用 Pix2Pix 算法的 TensorFlow 實現中的實用功能來創造一個數據集。
cd pix2pix-tensorflow
python3 tools/process.py --input_dir path/to/edges/images --b_dir path/to/original/images --operation combine --output_dir edge2image
現在我們有了可以使用的圖像數據集,我們就可以開始訓練了!按照這個 TensorFlow 模型在 GitHub 上的指令辦就行了。
組合到一起
爲了實現這個模型的可視化,我使用下面的代碼對內容進行了水平堆疊。這意味着結果得到的幀將由 3 張圖像組成,其中左邊的是輸入的線條繪畫,中間的是 Pix2Pix 生成的圖像,右邊的是來自原動畫的幀。你需要將起始幀和最終幀設置成 ffmpeg 命令得到的結果。
start_frame =
end_frame =
forimage inrange(start_frame,end_frame):
file_name ='edge2image_test/images/image_{num:04d}'.format(num=image)
input_file =cv2.imread(file_name +'-inputs.png')
output_file =cv2.imread(file_name +'-outputs.png')
target_file =cv2.imread(file_name +'-targets.png')
save_file =np.hstack((input_file,output_file,target_file))
save_name =file_name +'.png'
cv2.imwrite(save_name,save_file)
os.remove(file_name +'-inputs.png')
os.remove(file_name +'-outputs.png')
os.remove(file_name +'-targets.png')
現在我們將視頻每一幀的三張圖像(輸入、輸出、目標)都堆疊到了一起,然後我們可以使用 ffmpeg 將這些圖片再聚合成一段新視頻。-r 標籤設置的是視頻的幀率,-s 標籤設置的是寬度和高度,其它還有處理編碼方式和質量的——除非你別有需求,否則就不要動它們了。
ffmpeg -r 25-f image2 -s 640x360-i image_%04d.png -vcodec libx264 -crf 25-pix_fmt yuv420p name_of_output_file.mp4
現在我們得到模型的視頻了,現在我們可以查看這個模型的輸出!對於這個項目而言,其它有用的 ffmpeg 命令還有將音頻剝離視頻,然後再將其添加回來,我將這個工作的代碼分別放在下面的第一二行。
ffmpeg -i video.mp4 -f mp3 -ab 192000-vn music.mp3
ffmpeg -i video.mp4 -i music.mp3 -codec copy -shortest video_with_audio.mp4
結果
在僅僅訓練了 3 epoch 之後,結果就已經很有趣了。再次說明一下,最右邊的圖像是原始的動畫幀,左邊是右邊圖像的 Canny 邊緣版本。中間的圖像是由條件 GAN 在左邊圖像的基礎上預測得到的圖像。
該網絡已經能成功塗繪它在動畫中看見的常見物體,比如男孩的薑黃色頭髮和雪。有趣的是它在很多表面都犯錯了,比如牆、地板和雪,它會在上面疊加靜態的雪花圖案。出現這種雪圖案的原因可能是鑑別器學習到這是一個重要的現象,所以生成器需要將其放入到自己生成的圖像中。
如果我們進一步訓練,在 9 epoch 之後,結果是這樣。這個視頻添加了音樂:
我們還可以使用我們過擬合的模型做一件事。我們可以使用之前提到的 Canny 邊緣檢測處理新的視頻源(比如我坐在沙發上),然後看它能預測得到怎樣的結果。

對於這個視頻,我最喜歡的一點是影片中的我也有了電影中男孩那樣的薑黃色頭髮!很顯然我們使用人工或傳統技術難以創造出的這樣的全新有趣的動圖。
神經美學
Gene Kogan 有一個名爲《神經美學(The Neural Aesthetic)》的演講,儘管他通常親自演講,但你也可以在這裏查看:https://www.youtube.com/watch?v=mr6ISQ33V9c。
在這些神經美學的演講中,他展示了他正在製作和正在策展的作品,這些作品探索了機器學習在美學方面的意義。這種聚集反映了創造過程的人工智能技術的方法有助於理解本博客的背景;這篇博客文章僅僅是複製、解釋和演示其他人已經完成過的事情,而且也只是滄海一粟而已。
美學是對藝術、美麗和品位的本質的探索,可以用不同形式的媒介創造。我們正處在一個激動人心的時代,可以用機器學習來處理媒體內容,探索我們可以如何使用連接主義神經過程來合成引人入勝的新型藝術材料。當然,在藝術過程中使用新技術不是什麼新鮮事;曾經有個時候在洞壁上吹上礦物顏料是最先進的技術。
之前一種用於創造的技術
在當今的科學和藝術前沿,使用計算學習過程作爲藝術媒介的有趣方式越來越多,質量也越來越來高;這方面的發展速度驚人,就像我們已經習以爲常的機器學習領域的超快發展速度一樣。我們這些富有創造力的技術宅可以使用這些方法來創造用於生成新形式美學材料的抽象的新方法。
作爲創意人工智能社區的一員,要靠我們來設計應用這些神經模型的新方法以及思考新架構和數據集,以便進一步擴展我們能用計算過程完成的藝術的疆域。
(原文視頻較多,本文只選取了少數視頻,詳情請查看原文。)
原文鏈接:https://medium.com/@LeonFedden/the-snowgan-8a97cd75338d