摘要:現有的人聲識別絕大部分在服務端實現,這會帶來如下兩方面的問題:
1) 當網絡較差的情況下會造成較大的延時,帶來較差的用戶體驗。
2) 當訪問量較大的情況下,會大量佔用服務端資源。
爲解決以上兩個問題,我們選擇在客戶端上實現人聲識別功能。本文使用機器學習的方法識別人聲。採用的框架是谷歌的tensorflowLite框架,該框架跟它的名字一樣具有小巧的特點。在保證精度的同時,框架的大小隻有300KB左右,且經過壓縮後產生的模型是tensorflow模型的四分之一[1]。因此,tensorflowLite框架比較適合在客戶端上使用。
爲了提高人聲的識別率,需要提取音頻特徵作爲機器學習框架的輸入樣本。本文使用的特徵提取算法是基於人耳聽覺機理的梅爾倒頻譜算法[2]。
由於在客戶端上使用人聲識別比較耗時,在工程上需要做很多優化,優化方面如下:
1) 指令集加速:引入arm指令集,做多指令集優化,加速運算。
2) 多線程加速:對於耗時的運算採用多線程併發處理。
3) 模型加速:選用支持NEON優化的模型,並預加載模型減少預處理時間。
4) 算法加速:I) 降低音頻採樣率。II) 選取人聲頻段(20hz~20khz),剔除非人聲頻段。
III) 合理分窗和切片,防止過度計算。IV) 靜音檢測,減少不必要的時間片段。
1.概述
1.1 人聲識別流程
人聲識別分爲訓練和預測兩個部分。訓練指的是生成預測模型,預測是利用模型產生預測結果。
首先介紹下訓練的過程,分爲以下三個部分:
1) 基於梅爾倒頻譜算法,提取聲音特徵,並將其轉換成頻譜圖片。
2) 將人聲頻譜作爲正樣本,動物聲音和雜音等非人聲作爲負樣本,交由神經網絡模型 訓練。
3) 基於訓練產生的文件,生成端上可運行的預測模型。
簡而言之,人聲識別訓練的流程分爲三個部分,提取聲音特徵,模型訓練和生成端上模型。最後,是人聲識別的部分:先提取聲音特徵,然後加載訓練模型即可獲得預測結果。
1.2 人工智能框架
2017年11月,谷歌曾在 I/O 大會上宣佈推出 TensorFlow Lite,這是一款 TensorFlow 用於移動設備和嵌入式設備的輕量級解決方案。可以在多個平臺上運行,從機架式服務器到小型 IoT 設備。但是隨着近年來機器學習模型的廣泛使用,出現了在移動和嵌入式設備上部署它們的需求。而 TensorFlow Lite 允許設備端的機器學習模型的低延遲推斷。
本文基於的tensorflowLite是谷歌研發的人工智能學習系統,其命名來源於本身的運行原理。Tensor(張量)意味着N維數組,Flow(流)意味着基於數據流圖的計算,TensorFlow爲張量從流圖的一端流動到另一端計算過程。TensorFlow是將複雜的數據結構傳輸至人工智能神經網中進行分析和處理過程的系統。
下圖展示了tensorflowLite的架構設計[1]:
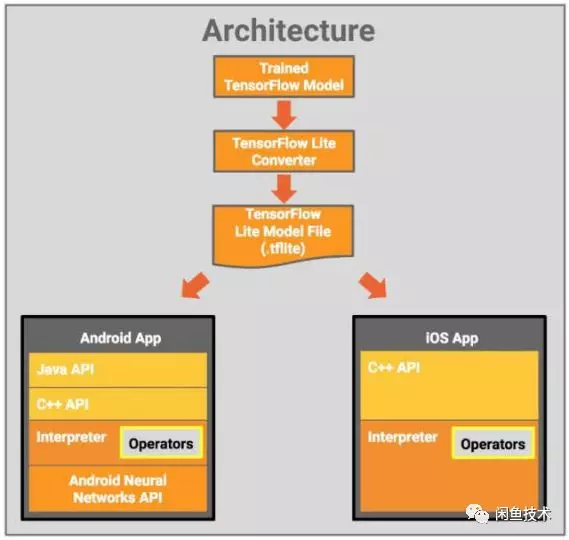 圖1.1 TFlite架構圖
圖1.1 TFlite架構圖
2.梅爾倒頻譜算法
2.1 概述
本章中聲音識別的算法--梅爾倒頻譜算法[2]分爲如下幾步,將會再後續小節中詳細介紹。
1) 輸入聲音文件,解析成原始的聲音數據(時域信號)。
2) 通過短時傅里葉變換,加窗分幀將時域信號轉變爲頻域信號。
3) 通過梅爾頻譜變換,將頻率轉換成人耳能感知的線性關係。
4) 通過梅爾倒譜分析,採用DCT變換將直流信號分量和正弦信號分量分離[3]。
5) 提取聲音頻譜特徵向量,將向量轉換成圖像。
加窗分幀是爲了滿足語音在時域的短時平穩特性,梅爾頻譜變換是爲了將人耳對頻率的感知度轉化爲線性關係,倒譜分析的重點是理解傅里葉變換,任何信號都可以通過傅里葉變換而分解成一個直流分量和若干個正弦信號的和。
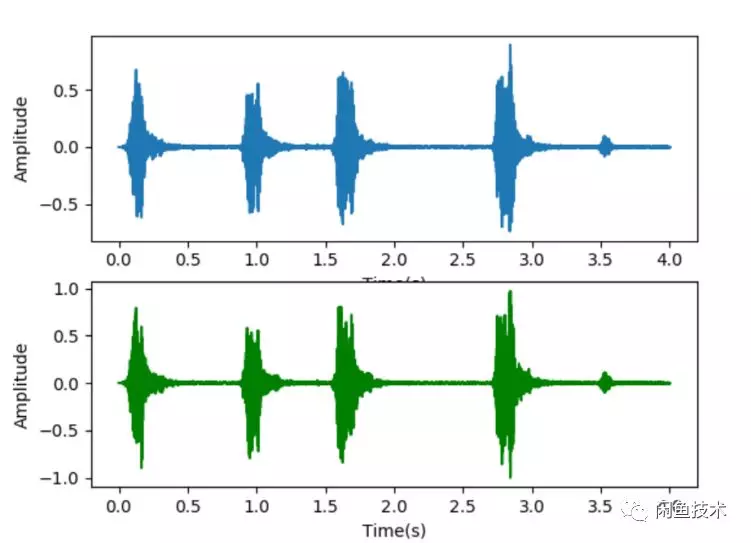
圖2.1 聲音的時域信號
圖2.1是聲音的時域信號,直觀上很難看出頻率變化規律。圖2.2是聲音的頻域信號,反映了能夠反映出聲音的音量和頻率等信息。圖2.3是經過梅爾倒頻譜的聲音特徵,能夠提取聲音
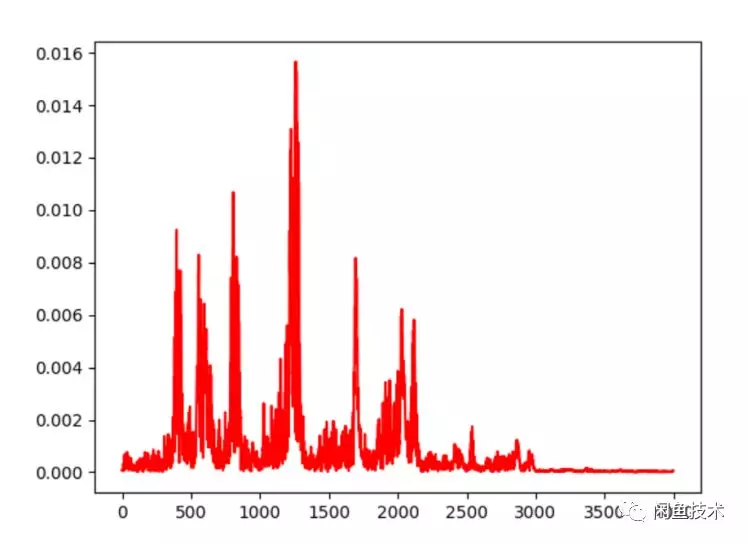
圖2.2 聲音的頻域信號
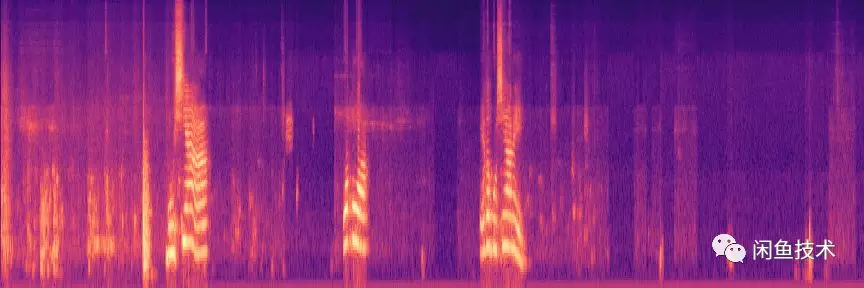
圖2.3 聲音的倒頻譜特徵
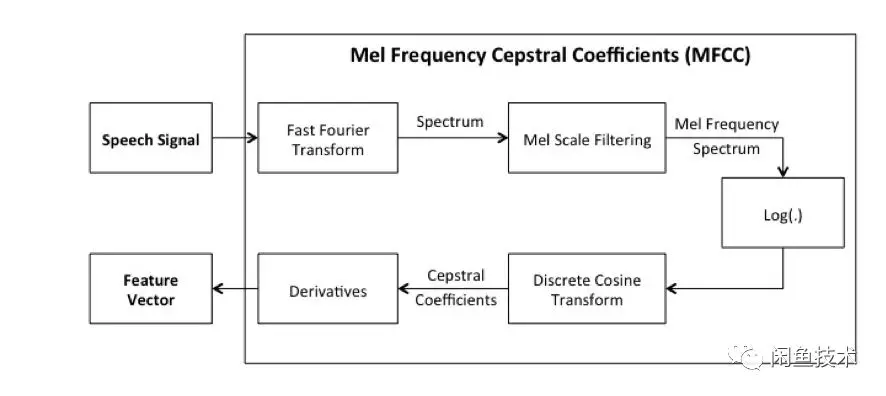 圖2.4 梅爾倒頻譜算法實現流程
圖2.4 梅爾倒頻譜算法實現流程
2.2 短時傅里葉變換
聲音信號是一維的時域信號,直觀上很難看出頻率變化規律。如果通過傅里葉變換把它變到頻域上,雖然可以看出信號的頻率分佈,但是丟失了時域信息,無法看出頻率分佈隨時間的變化。爲了解決這個問題,很多時頻分析手段應運而生。短時傅里葉,小波,Wigner分佈等都是常用的時頻域分析方法。
圖2.5 FFT變換和STFT變換示意圖
通過傅里葉變換可以得到信號的頻譜。信號的頻譜的應用非常廣泛,信號的壓縮、降噪都可以基於頻譜。然而傅里葉變換有一個假設,那就是信號是平穩的,即信號的統計特性不隨時間變化。聲音信號就不是平穩信號,在很長的一段時間內,有很多信號會出現,然後立即消失。如果將這信號全部進行傅里葉變換,就不能反映聲音隨時間的變化。
本文采用的短時傅里葉變換(STFT)是最經典的時頻域分析方法。短時傅里葉變換(STFT)是和傅里葉變換(FT)相關的一種數學變換,用以確定時變信號其局部區域正弦波的頻率與相位。它的思想是:選擇一個時頻局部化的窗函數,假定分析窗函數h(t)在一個短時間間隔內是平穩的,使f(t)h(t)在不同的有限時間寬度內是平穩信號,從而計算出各個不同時刻的功率譜。短時傅里葉變換使用一個固定的窗函數,通常使用的窗函數有漢寧窗、海明窗、Blackman-Haris窗等。本文中採用了海明窗,海明窗是一種餘弦窗,能夠很好地反映某一時刻能量隨時間的衰減關係。
因此,本文的STFT公式在原先傅里葉變換公式:公式的基礎上加了窗函數,因此STFT公式變換爲
其中,爲海明窗函數。
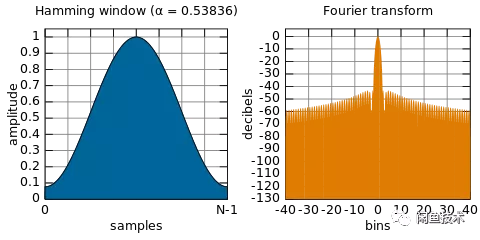
圖2.6 基於海明窗的STFT變換
2.3 梅爾頻譜
聲譜圖往往是很大的一張圖,爲了得到合適大小的聲音特徵,往往把它通過梅爾標度濾波器組,變換爲梅爾頻譜。什麼是梅爾濾波器組呢?這裏要從梅爾標度說起。
梅爾標度,由Stevens,Volkmann和Newman在1937年命名。我們知道,頻率的單位是赫茲(Hz),人耳能聽到的頻率範圍是20-20000Hz,但人耳對Hz這種標度單位並不是線性感知關係。例如如果我們適應了1000Hz的音調,如果把音調頻率提高到2000Hz,我們的耳朵只能覺察到頻率提高了一點點,根本察覺不到頻率提高了一倍。如果將普通的頻率標度轉化爲梅爾頻率標度,映射關係如下式所示:
經過上述公式,則人耳對頻率的感知度就成了線性關係[4]。也就是說,在梅爾標度下,如果兩段語音的梅爾頻率相差兩倍,則人耳可以感知到的音調大概也相差兩倍。
讓我們觀察一下從Hz到梅爾頻率(mel)的映射圖,由於它們是log的關係,當頻率較小時,梅爾頻率隨Hz變化較快;當頻率很大時,梅爾頻率的上升很緩慢,曲線的斜率很小。這說明了人耳對低頻音調的感知較靈敏,在高頻時人耳是很遲鈍的,梅爾標度濾波器組啓發於此。
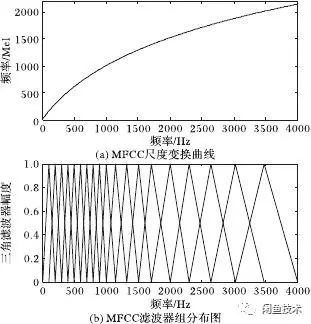
圖2.7 頻率轉梅爾頻率示意圖
如下圖所示,12個三角濾波器組成濾波器組,低頻處濾波器密集,門限值大,高頻處濾波器稀疏,門限值低。恰好對應了頻率越高人耳越遲鈍這一客觀規律。上圖所示的濾波器形式叫做等面積梅爾濾波器(Mel-filter bank with same bank area),在人聲領域(語音識別,說話人辨認)等領域應用廣泛。
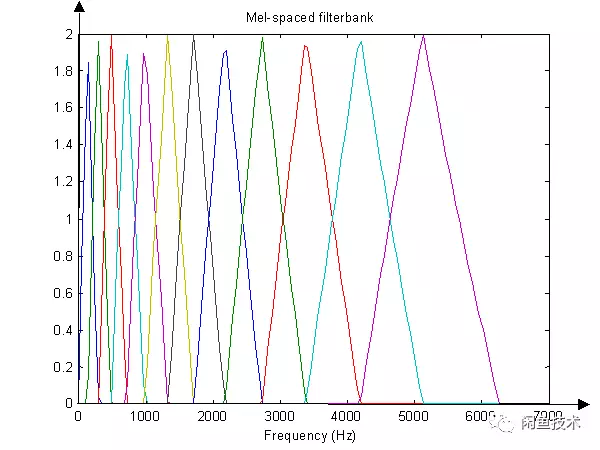
圖2.8 梅爾濾波器組示意圖
2.4 梅爾倒頻譜
基於2.3的梅爾對數譜,採用DCT變換將直流信號分量和正弦信號分量分離,最後得到的結果稱爲梅爾倒頻譜。
其中,
由於梅爾倒頻譜輸出的是向量,還不能用圖片顯示,需要將其轉換成圖像矩陣。需要將輸出向量的範圍線性變換到圖像的範圍

圖2.9 繪圖顏色標度示意圖
2.5 算法處理速度優化
由於算法需要在客戶端上實現,因此需要對速度做一定的改進[5]。優化方面如下:
1) 指令集加速:由於算法有大量的加法和乘法矩陣運算,因此引入arm指令集,做多指令集優化,加速運算。速度可以提高4~8倍[6]。
2) 算法加速:I) 選取人聲頻段(20HZ~20KHZ),並剔除非人聲頻段減少冗餘計算。II)降低音頻採樣率,由於人耳對過高的採樣率不敏感,因此降低採樣率 可以減少不必要的數據計算。III)合理分窗和切片,防止過度計算。IV) 靜音檢測,減少不必要的時間片段。
3) 採樣頻率加速:如果音頻的採樣頻率過高,選擇下采樣,處理的頻率最高設定爲32kHZ。
4) 多線程加速:將音頻拆分爲多個片段,採用多線程並行處理。並根據機器的能力配置線程數,默認爲4個線程。

圖2.10 算法工程端選取的參數
3.人聲識別模型
3.1模型選擇
卷積神經網絡(Convolutional Neural Networks-簡稱CNN)是一種前饋神經網絡,它的人工神經元可以響應一部分覆蓋範圍內的周圍單元,對於大型圖像處理有出色表現。
20世紀60年代,Hubel和Wiesel在研究貓腦皮層中用於局部敏感和方向選擇的神經元時發現其獨特的網絡結構可以有效地降低反饋神經網絡的複雜性,繼而提出了卷積神經網絡。現在,CNN已經成爲衆多科學領域的研究熱點之一,特別是在模式分類領域,由於該網絡避免了對圖像的複雜前期預處理,可以直接輸入原始圖像,因而得到了更爲廣泛的應用。 K.Fukushima在1980年提出的新識別機是卷積神經網絡的第一個實現網絡。隨後,更多的科研工作者對該網絡進行了改進。其中,具有代表性的研究成果是Alexander和Taylor提出的「改進認知機」,該方法綜合了各種改進方法的優點並避免了耗時的誤差反向傳播。
一般地,CNN的基本結構包括兩層,其一爲特徵提取層,每個神經元的輸入與前一層的局部接受域相連,並提取該局部的特徵。一旦該局部特徵被提取後,它與其它特徵間的位置關係也隨之確定下來;其二是特徵映射層,網絡的每個計算層由多個特徵映射組成,每個特徵映射是一個平面,平面上所有神經元的權值相等。特徵映射結構採用影響函數核小的sigmoid, relu等函數作爲卷積網絡的激活函數,使得特徵映射具有位移不變性。此外,由於一個映射面上的神經元共享權值,因而減少了網絡自由參數的個數。卷積神經網絡中的每一個卷積層都緊跟着一個用來求局部平均與二次提取的計算層,這種特有的兩次特徵提取結構減小了特徵分辨率。
CNN主要用來識別位移、縮放及其他形式扭曲不變性的二維圖形。由於CNN的特徵檢測層通過訓練數據進行學習,所以在使用CNN時,避免了顯式的特徵抽取,而隱式地從訓練數據中進行學習;再者由於同一特徵映射面上的神經元權值相同,所以網絡可以並行學習,這也是卷積網絡相對於神經元彼此相連網絡的一大優勢。卷積神經網絡以其局部權值共享的特殊結構在語音識別和圖像處理方面有着獨特的優越性,其佈局更接近於實際的生物神經網絡,權值共享降低了網絡的複雜性,特別是多維輸入向量的圖像可以直接輸入網絡這一特點避免了特徵提取和分類過程中數據重建的複雜度。
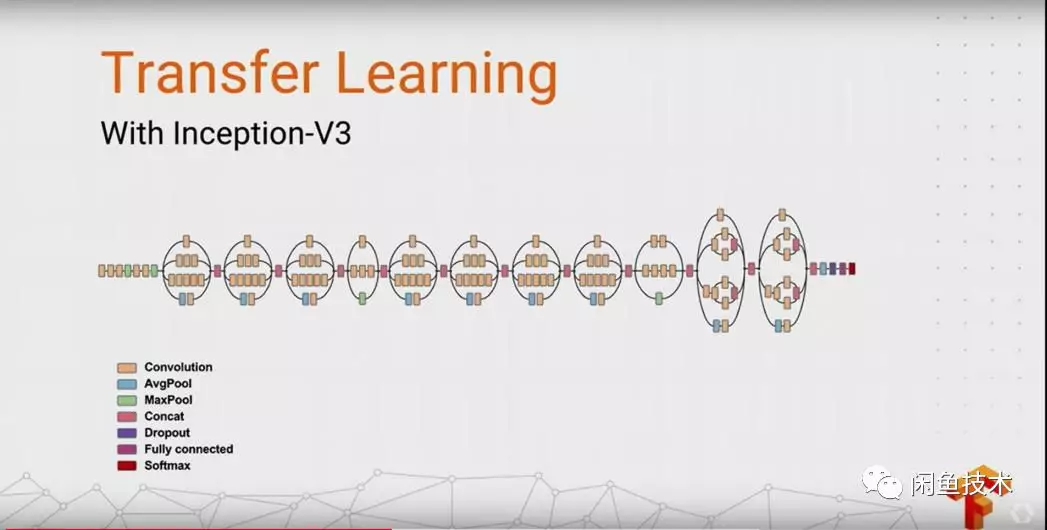
圖3.1 Inception-v3模型
本文選取了精度較高的Inception-v3模型作爲人聲識別的模型,v3一個最重要的改進是分解,將7x7卷積網絡分解成兩個一維的卷積(1x7,7x1),3x3也是一樣(1x3,3x1),這樣的好處,既可以加速計算,使得網絡深度進一步增加,增加了網絡的非線性,還有值得注意的地方是網絡輸入從224x224變爲了299x299,更加精細設計了35x35/17x17/8x8的模塊。
使用tensorflow session模塊可以實現代碼層面的訓練和預測功能,具體使用方法詳見tensorflow官網[10]。

圖3.2 tensorflow session使用示意圖
3.2模型樣本
有監督的機器學習中,一般需要將樣本分成獨立的三部分訓練集(train set),驗證集(validation set)和測試集(test set)。其中訓練集用來估計模型,驗證集用來確定網絡結構或者控制模型複雜程度的參數,而測試集則檢驗最終選擇最優的模型的性能如何。
具體定義如下:
訓練集:學習樣本數據集,通過匹配一些參數來建立一個分類器。建立一種分類的方式,主要是用來訓練模型的。
驗證集:對學習出來的模型,調整分類器的參數,如在神經網絡中選擇隱藏單元數。驗證集還用來確定網絡結構或者控制模型複雜程度的參數,用來防止模型過擬合現象。
測試集:主要是測試訓練好的模型的分辨能力(識別率等)
根據第二章的梅爾倒頻譜算法可以得到聲音識別的樣本文件,將人聲頻譜作爲正樣本,動物聲音和雜音等非人聲作爲負樣本,交由Inception-v3模型進行訓練。
本文采用了tensorflow作爲訓練框架,選取人聲和非人聲各5000個樣本作爲測試集,1000個樣本作爲驗證集。
3.3 模型訓練
樣本準備完成後,即可使用Inception-v3模型訓練。當訓練模型收斂時,即可生成端上可使用的pb模型。模型選取時選擇編譯armeabi-v7a或者以上版本即可默認打開NEON優化,即打開USE_NEON的宏,能夠達到指令集加速的效果。例如CNN網絡一半以上的運算都在卷積(conv)運算,使用指令集優化可以至少加速4倍。
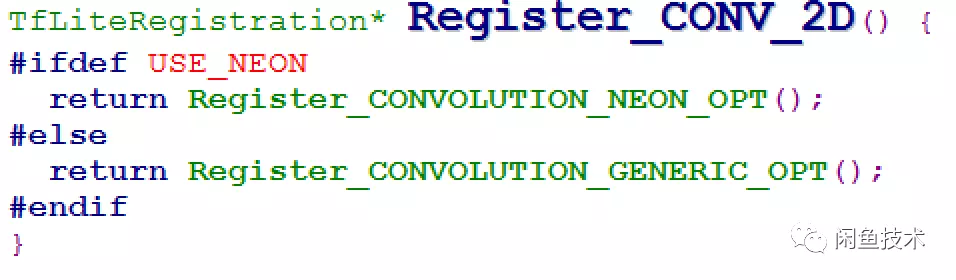
圖3.3 卷積處理函數
然後經過tensorflow提供的toco工具生成lite模型,該模型可以直接在客戶端上使用tensorflowLite框架調用。
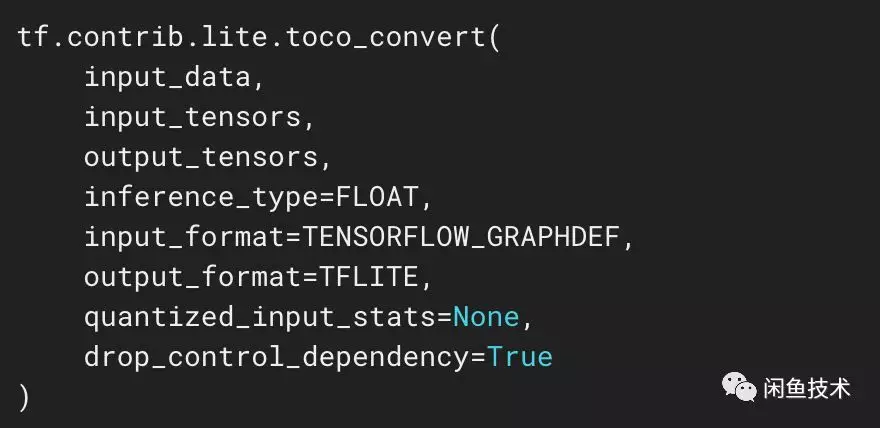
圖3.4 toco工具調用接口
3.4 模型預測
對聲音文件使用梅爾倒頻譜算法提取特徵,並生成預測圖片。之後使用訓練產生的lite模型即可預測,預測結果示意圖如下:
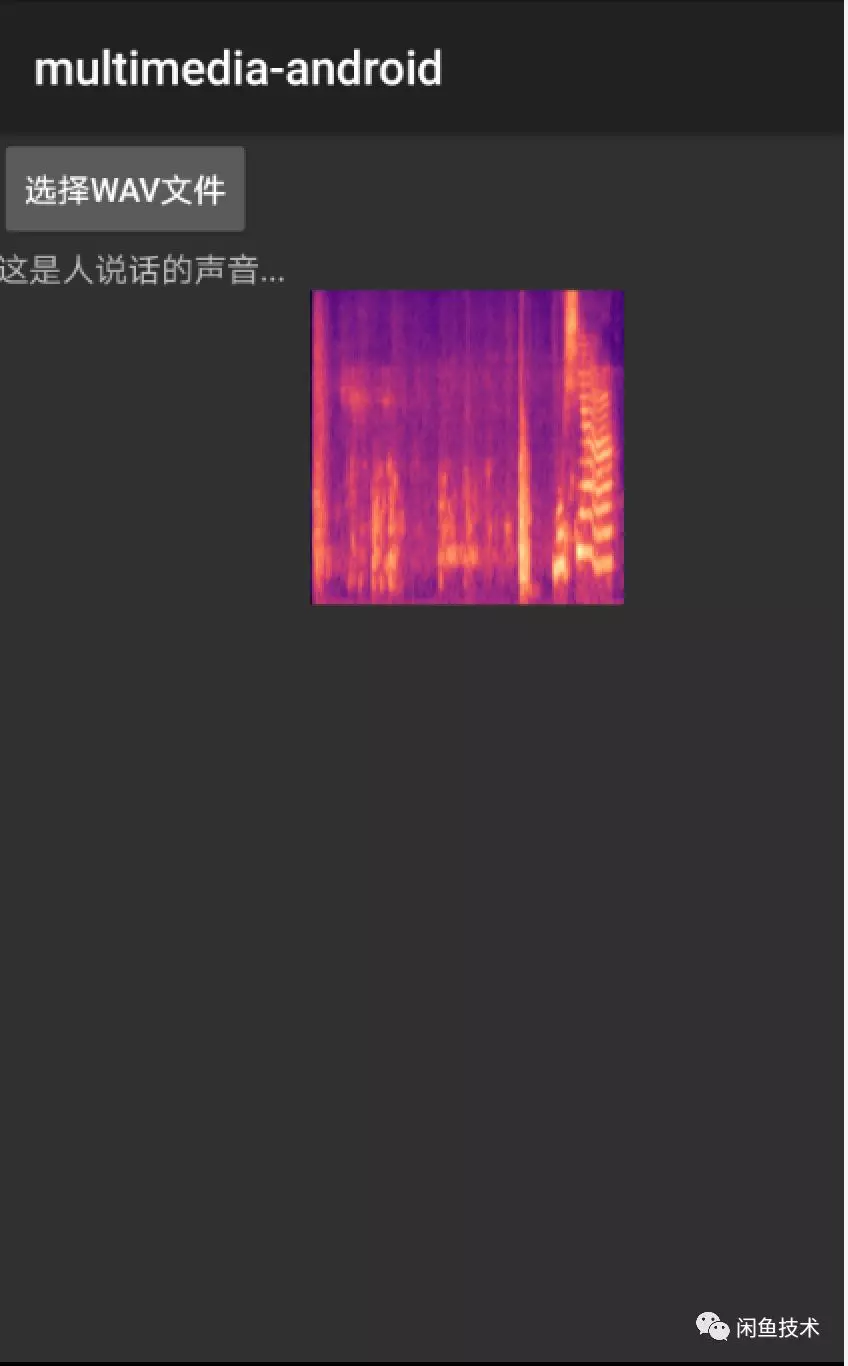
圖3.5 模型預測結果