引言
理解顧客行爲在任何工業領域都是至關重要的,直到去年我才意識到這個問題。當時我的CMO(chief marketing officer,首席營銷官)問我:「你能告訴我,我們新產品的目標用戶應該是什麼羣體呢?」
這對我來說是一個學習的過程。我很快意識到,作爲一個數據科學家,將顧客細分以便於公司能夠進行客戶定製並建立目標策略有多重要。這就聚類概念能派上用場的地方!
用戶分類通常很棘手,因爲我們腦海當中並沒有任何目標變量。我們現在正式踏入了無監督學習的領域,在沒有任何設定結果的情況下來發掘模式和結構。這對數據科學家來說是充滿挑戰但卻是讓人激動的事。
在這裏有幾種不同的聚類方法(你會在下面的部分看到)。我將向你介紹其中一種——層級聚類。
我們將會學習層級聚類是什麼,它優於其他聚類算法的地方,不同層級聚類的方式以及開展的步驟。我們在最後會採用一個顧客分類數據庫並實現Python的層級聚類。我喜歡這個方法並且十分確定在你讀完本文之後也會喜歡上的!
註釋:如上所述,聚類的方法很多。我鼓勵你查看我們對不同類型聚類所做的指南:
- An Introduction to Clustering and different methods of clustering
https://www.analyticsvidhya.com/blog/2016/11/an-introduction-to-clustering-and-different-methods-of-clustering/utm_source=blog&utm_medium=beginners-guide-hierarchical-clustering
想要學習更多關於聚類的內容和其他機器學習算法(監督和無監督)可以看看下面這個項目-
https://courses.analyticsvidhya.com/bundles/certified-ai-ml-blackbelt-plus?utm_source=blog&utm_medium=beginners-guide-hierarchical-clustering
目錄
1. 監督vs 無監督學習
2. 爲什麼要用層級聚類?
3. 什麼是層級聚類?
4. 層級聚類的類型
(1) 聚合式(Agglomerative)層級聚類
(2) 分裂式(Divisive)層級聚類
5. 層級聚類的步驟
6. 在層級聚類中如何選擇類的數量?
7. 利用層級聚類解決一個批發顧客分類問題
監督vs無監督學習
在我們深入學習層級聚類之前,理解監督學習和無監督學習之間的差異是十分重要的。讓我用一個簡單的例子來解釋這種差異。
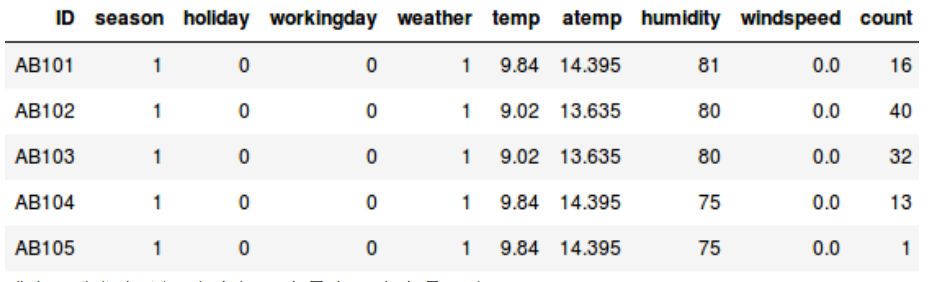
假設我想要估計每天將被租借的自行車數量:
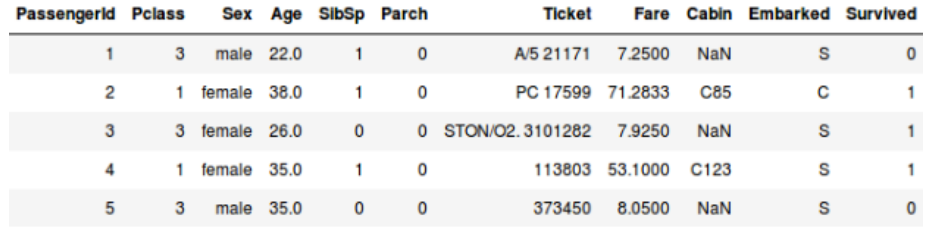
或者,我們想預測在泰坦尼克號上一個人是否生還:
在這兩個例子當中都有一個固定的目標要實現:
- 在第一個例子當中,要基於像季節、假期、工作日、天氣、溫度等特徵來預測自行車租用數量。
- 在第二個例子中要預測乘客是否會生還。在「生還」變量中,0代表這個人未生還,1代表這個人活了下來。這裏的自變量包括客艙等級、性別、年齡、票價等等。
所以說,當我們有目標變量的時候(在上述兩個例子當中的數量和生還),基於一系列預測變量或者自變量(季節,假期,性別,年齡等)來預測,這種問題叫做監督學習問題。
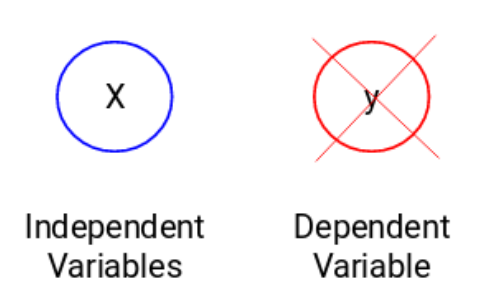
讓我們看看下面的圖以便更好地理解它:
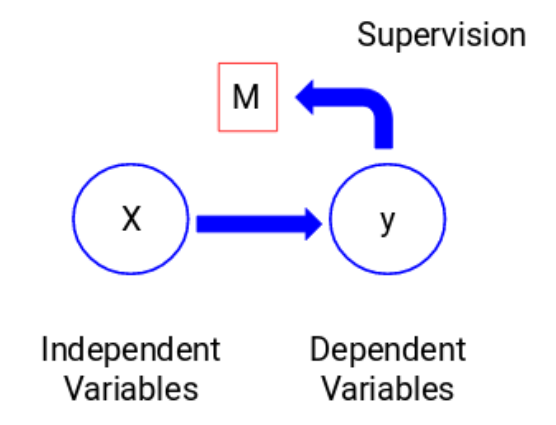
在這裏,y是因變量或者叫目標變量,X代表自變量。目標變量依賴於X,因此它也被叫做一個因變量。我們在目標變量的監督下使用自變量來訓練模型,因而叫做監督學習。
我們在訓練模型時的目標是生成一個函數,能夠將自變量映射到期望目標。一旦模型訓練完成,我們可以把新的觀測值放進去,模型就可以自己來預測目標。總而言之,這個過程就叫做監督學習。
有時候我們並沒有任何需要預測的目標變量。這種問題沒有任何外顯的目標變量,被叫做無監督學習。我們僅有自變量。
我們試圖將全部數據劃分成一系列的組。這些組被叫做簇,這個過程叫做聚類。
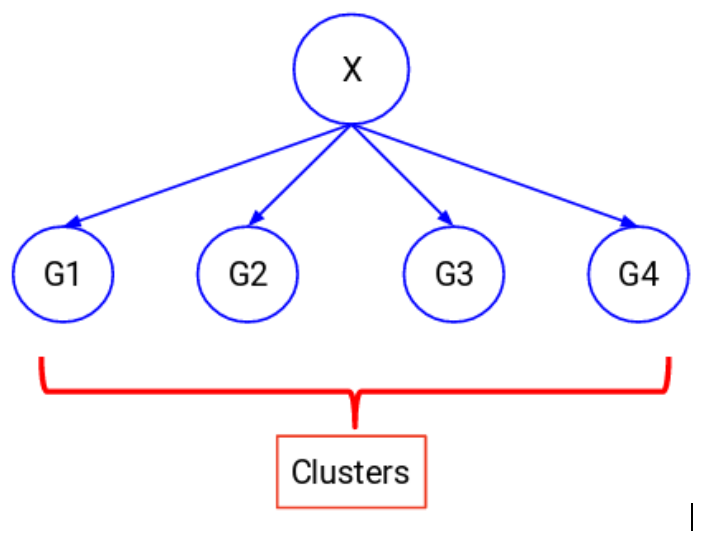
這種技術通常被用於將總體聚類成不同的組別。常見的例子包括顧客分羣、聚類相似的文件、推薦相似的歌或者電影等等。
現在有很多算法可以幫助我們完成聚類。最常用的聚類算法是K-means和層級聚類。
爲什麼要採用層級聚類?
在此之前,我們需要先知道K-means是怎樣工作的。相信我,這會讓層級聚類的概念變得更簡單。
這裏有一個對K-means算法如何工作的概覽:
1. 決定簇的數量(k)
2. 選擇k個隨機的點作爲中心點
3. 將所有的點納入最近的中心點
4. 計算新形成的簇的中心點
5. 重複步驟3和4
這是一個迭代的過程。它將持續地運行,直到新形成的簇的中心點不再變化,或者到達了最大迭代次數。
但是K-means也受到了一些質疑。它通常試圖生成規格相同的簇。還有,我們需要在算法開始之前就決定好簇的數量。理想情況下,我們在算法開始時不知道要多少簇,因而這也是K-means所面對的一種質疑。
這也恰恰就是層級聚類的優越之處。它解決了預先設定簇的數量的問題。聽起來就是在做夢!所以,讓我們看看層級聚類是什麼以及它是怎樣改進K-means的。
什麼是層級聚類?
我們有以下的一些點,我們想把它們聚類:

我們可以把每個點作爲單獨的簇:
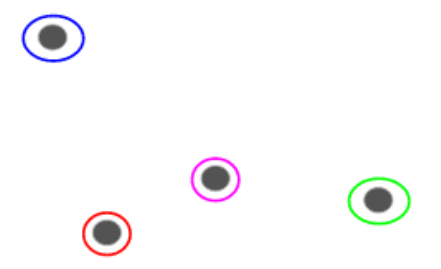
現在,基於這些簇的相似性,我們可以把最相似的簇放到一起,並且重複這個過程直到剩餘單一的簇:
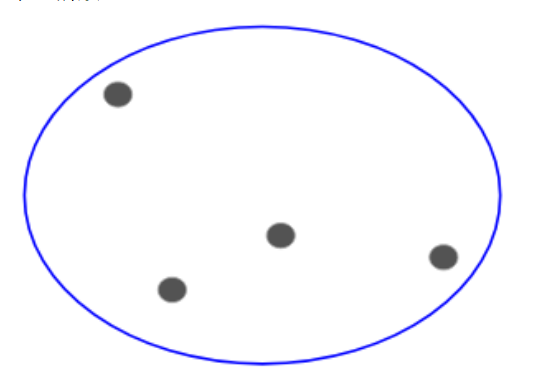
我們有必要建立一個簇的層級,這就是爲什麼這個算法叫做層級聚類。我們將在下一部分討論如何決定簇的數量。現在,讓我們看看不同類型的層級聚類。
層級聚類的類型
這裏有兩種主要的層級聚類:
1. 聚合式層級聚類
2. 分裂式層級聚類
讓我們來詳細理解一下每一種:
聚合式層級聚類
把每個點歸於單獨的一個簇。假設這裏有四個數據點。我們把每個點分到一個簇裏,在開始時就會有四個簇:
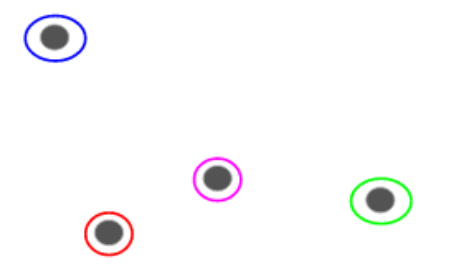
然後,在每一輪迭代中,我們把最相似的點對進行融合,然後重複上述步驟直到只剩單一簇:
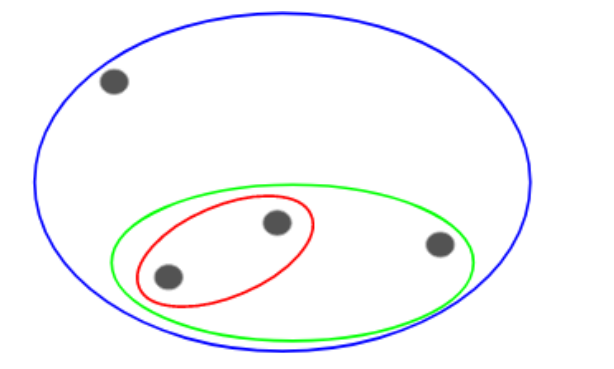
每一步我們都在融合(或者增加)簇,對吧?因此,這種聚類也叫作累加層級聚類。
分裂式層級聚類
分裂式層級聚類則是一種相反的思路。與一開始劃分n個簇(n個觀測值)不同,我們開始時只有一個簇,並且把所有的點都納入這個簇。
所以,我們有10個或者1000個點並不重要。所有的點在一開始都在同一個簇中:
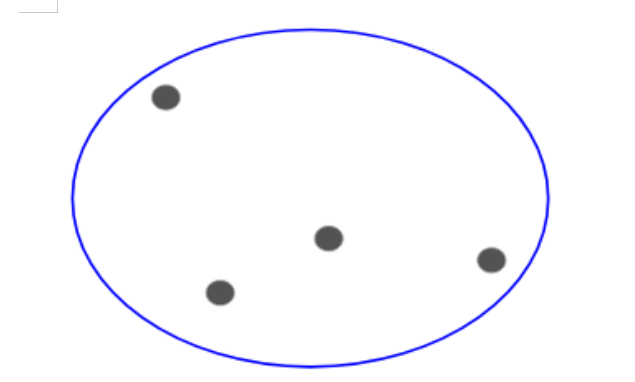
現在,在每一次迭代中,我們把簇中最遠的點分離出來,並且重複上述過程直到每個簇都只有一個點:

我們每一步都在分裂(或劃分)簇,因此叫做分裂式層級聚類。
聚合式聚類被廣泛應用於工業當中,在本文當中也將重點關注。一旦我們掌握了聚合式,分裂式層級聚類也將變得非常簡單。
層級聚類的步驟
我們在層級聚類當中把最相似的點或類進行融合——我們已經知道這一點。現在問題是——如何決定哪些點相似哪些點不相似呢?這纔是聚類當中最重要的問題之一!
這裏有一種計算相似性的方式——計算簇中心點之間的距離。距離最近的點被認爲是相似的點,我們可以融合它們。我們可以把這個叫做基於距離的算法(因爲我們計算了簇之間的距離)。
在層級聚類中有一個臨近矩陣(proximity matrix)的概念。這個矩陣存儲了每對點之間的距離。讓我們來用一個例子來理解這個矩陣和層級聚類的方法。
例子

假設一個老師想把她的學生分成不同的組。她有每個學生在一次作業當中所取得的分數,基於這些分數,她想把學生分成不同的組。這裏沒有關於分組的固定的目標。因爲老師並不知道哪種學生應該分配到什麼組,它不能用監督學習問題來描述。所以,我們將使用層級聚類把學生分成不同的組。
我們的例子有5個學生:
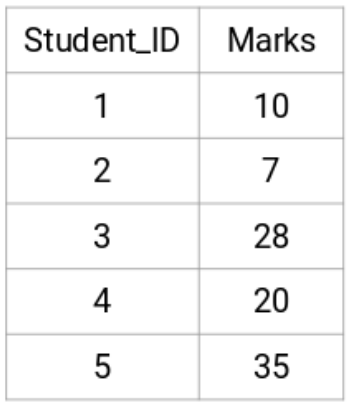
創造一個鄰接矩陣
首先,我們創造一個鄰接矩陣,這個矩陣會告訴我們這些點之間的距離。我們計算了每兩個點之間的距離,會得到一個n*n的方形矩陣(n是觀測值的數量)。
讓我們來看一看這五個點之間的鄰接矩陣:
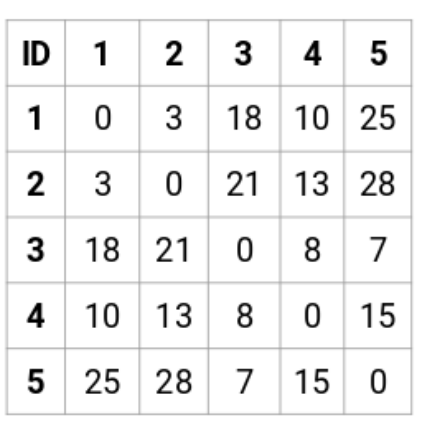
這個矩陣的對角線永遠是0,因爲每個點到自己的距離總是0。我們將使用歐氏距離公式來計算剩下的距離。所以,讓我們來看看我們想計算的點1和2之間的距離:
√(10-7)^2 = √9 = 3
類似地,我們可以計算所有點之間的距離,並且填充這個鄰接矩陣。
步驟
第一步:首先,我們將所有的點歸於一個簇:

不同顏色表徵不同的簇。你可以看到數據中的5個點構成了五種不同的簇。
第二步:接下來,在鄰接矩陣中找到距離最短的點,並且把這些點融合。然後更新鄰接矩陣。
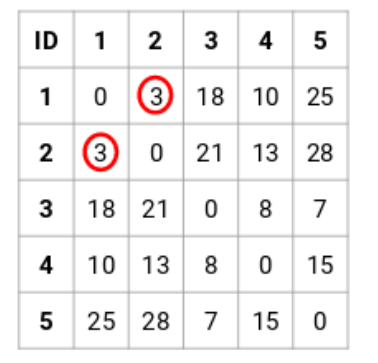
在這裏,最小的距離是3,因此把點1和2進行融合:
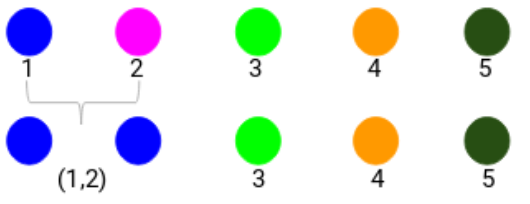
讓我們看看更新後的簇並且相應地更新鄰接矩陣:
在這裏,我們取了兩個點(7,10)中的最大值來代替這個集羣的標記。我們也可以用最小值或者平均值代替。現在,我們將再一次計算這些簇的鄰接矩陣:
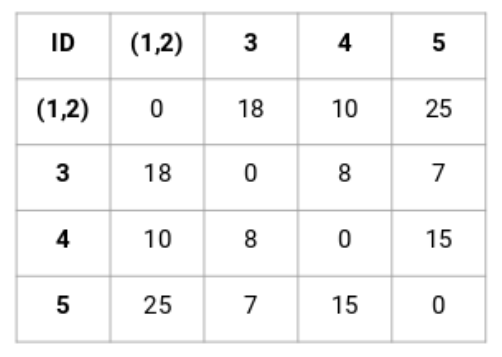
第三步:重複步驟2直到只剩下1個簇。
我們先看鄰接矩陣當中的最小值,然後融合簇中最接近的一對。我們在重複上述步驟之後將得到以下融合的簇:
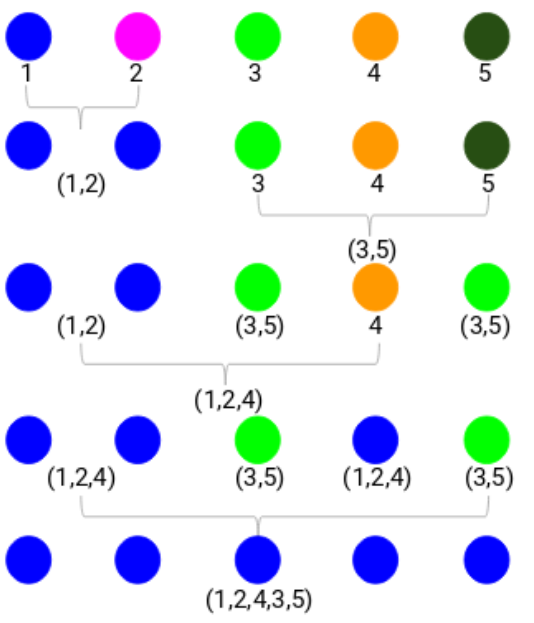
我們開始有5個簇,最後只有一個單一的簇。這也就是聚合式層級聚類的工作方式。但是棘手的問題仍然存在——怎麼決定簇的數量呢?讓我們看看下一部分。
在層級聚類中,我們應該怎樣選擇簇的數量呢?
準備好回答這個從開始就一直在提的問題了嗎?爲了獲得層級聚類的數量,我們使用了一個叫樹狀圖的絕妙概念。
樹狀圖是一個樹形圖表,能夠記錄融合或分裂的順序。
讓我們回到老師-學生的例子。無論何時融合兩個類,一個樹狀圖都會記錄這些類之間的距離並且以圖的形式進行表徵。讓我們看看樹狀圖是什麼樣的:
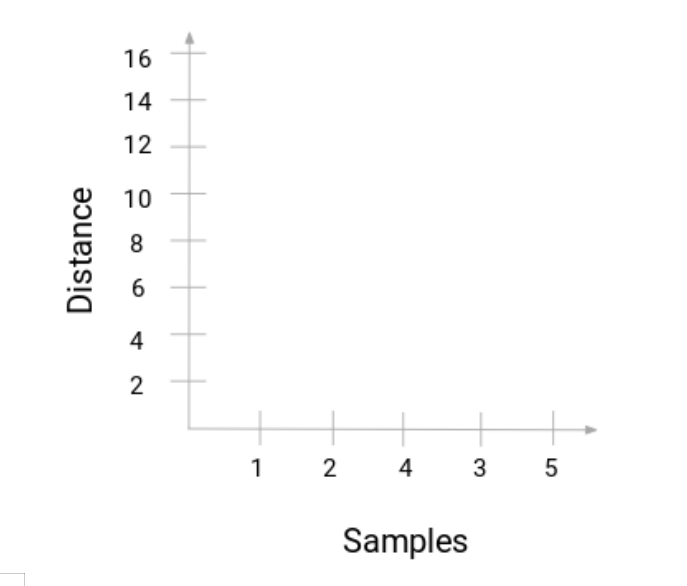
我們把樣本放到x軸,距離作爲y軸。無論兩個簇何時融合,我們都將加入樹狀圖內,連接點之間的高度就是這些點之間的距離。讓我們來建立例子的樹狀圖:
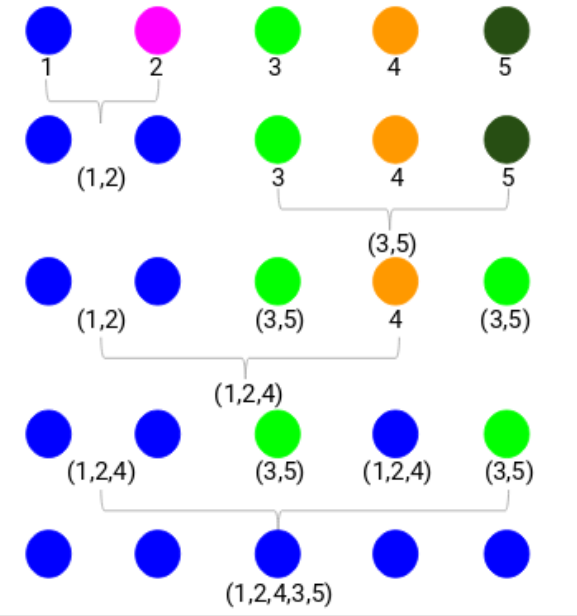
需要花點兒時間來加工上述圖片。我們開始融合了樣本1和2,這兩個點之間的距離是3(指的是在上一部分出現的第一個鄰接矩陣)。讓我們來把它放到樹狀圖上:
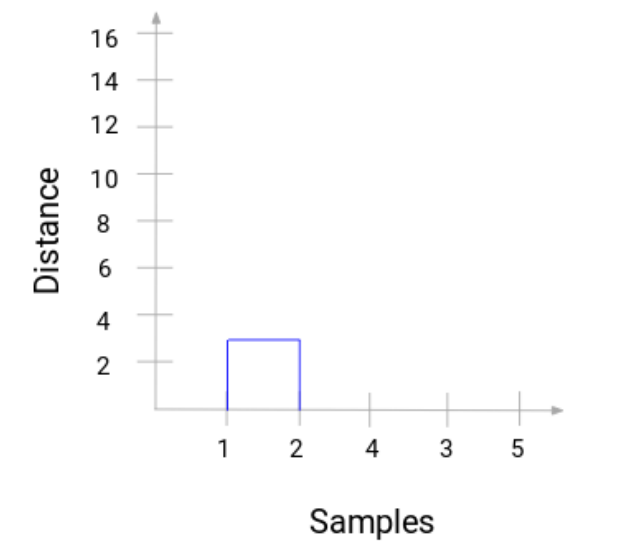
在這裏,我們可以看看融合的樣本1和2。垂直的線代表兩個點之間的距離。相似的,我們把融合簇的所有步驟畫到圖上,最後可以得到如下樹狀圖:
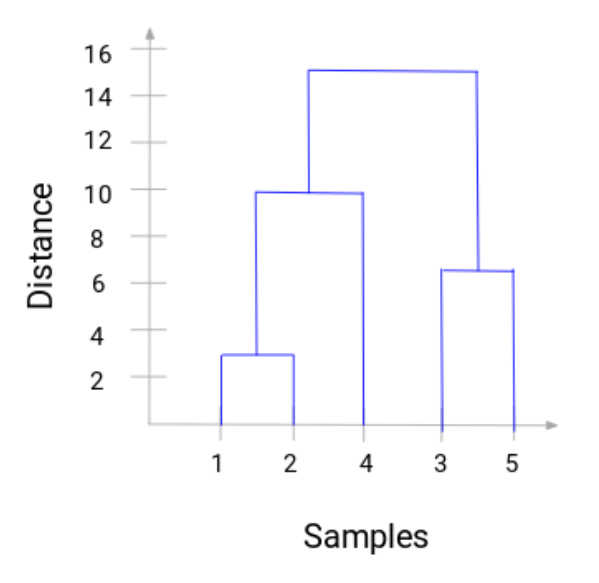
我們可以清晰地把層級聚類的步驟進行可視化。垂直線的距離越長,簇之間的距離越遠。
現在,我們可以設置一個距離閾限,並畫一條水平線(一般的,我們會用這種方式來設置閾限,它會切斷最常的垂直線)。讓我們設置閾限爲12,然後畫一條水平線。
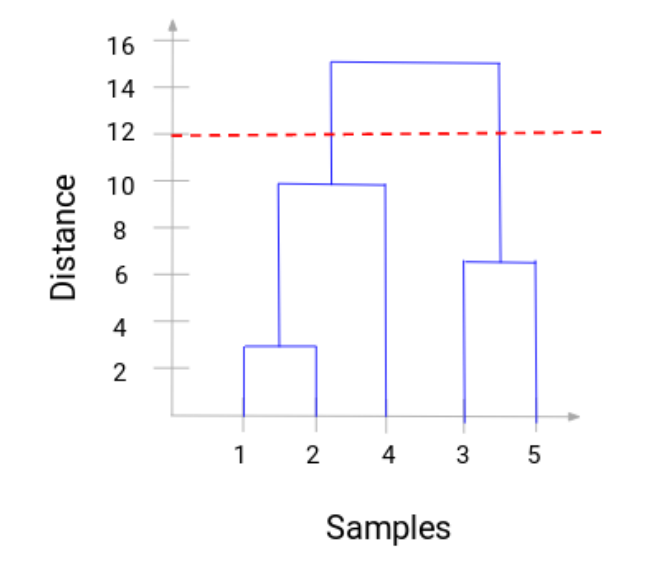
類的數量是與閾值先相交的垂直線的數量。在上述例子裏,因爲紅線與兩條垂直線交叉,我們將有2個類。一個類包括樣本(1,2,4),另一個類包括樣本(3,5)。非常清晰對嗎?
這就是我們在層級聚類中使用樹狀圖確定類的數量的方式。在下一部分,我們將實際應用層級聚類幫助你理解本文中所學到的概念。
使用層級聚類來解決批發顧客分類問題
是時間開始用Python了!
我們將開始解決一個批發顧客分類問題。你可以在這裏下載數據集(https://archive.ics.uci.edu/ml/machine-learning-databases/00292/Wholesale%20customers%20data.csv)。
這個數據託管在UCI機器學習知識庫當中。本問題的目標是對一個批發商的顧客基於他們在不同產品類型(例如牛奶、食品雜貨、地區等等)的年度開支進行分類。
讓我們先來探索一下數據,然後再利用層級聚類進行顧客分類。
首先導入所需的函數庫:

view rawimporting_libraries.py hosted with by GitHub
https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit&action=edit&type=10&appmsgid=100034460&isMul=1&isSend=0&token=886063492&lang=zh_CN#file-importing_libraries-py
加載數據集然後看一下前幾行:

view raw
https://gist.github.com/PulkitS01/8ac9bf3b54eb59b4e1d4eaa21d3d774e/raw/6cea281dc4dea42bbcb2160e6cef1535cad765e7/reading_data.py
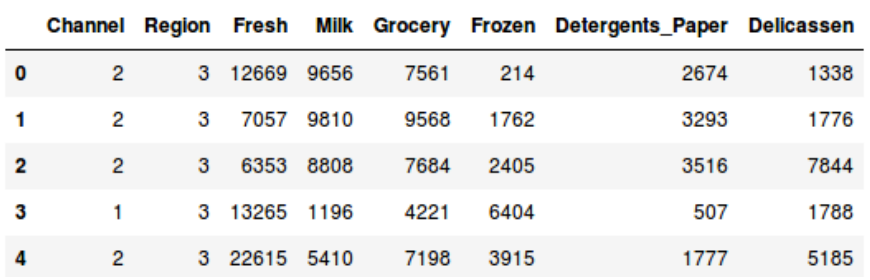
這裏有很多產品種類——生鮮、牛奶、雜貨等等。數值代表被每個顧客所購買的數量。我們的目標是從這個數據中進行類的劃分,可以把相似的顧客劃歸到同一類。我們將使用層級聚類解決這個問題。
但是在實際應用層級聚類解之前,我們需要把數據集進行歸一化以便於所有變量的尺度是相同的。爲什麼這一步很重要呢?因爲如果變量尺度不同,模型偏向那些擁有更大量級的變量像是生鮮或者牛奶(如上表格)。
所以,先將數據歸一化,把所有變量放到同一尺度。


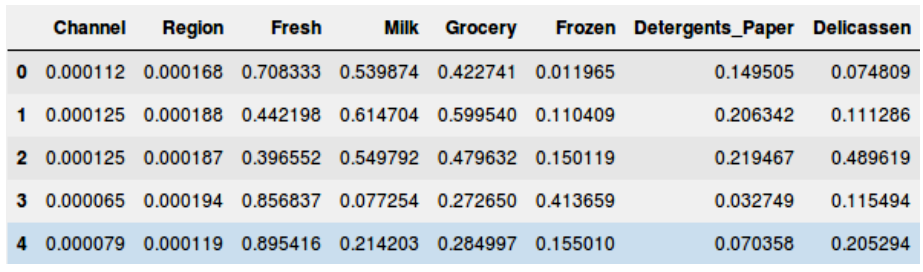
在這裏,可以看到所有變量的尺度幾乎是相似的。現在,我們可以開始進行層級聚類了。首先畫出樹狀圖來幫助我們決定這個問題當中簇的數量:
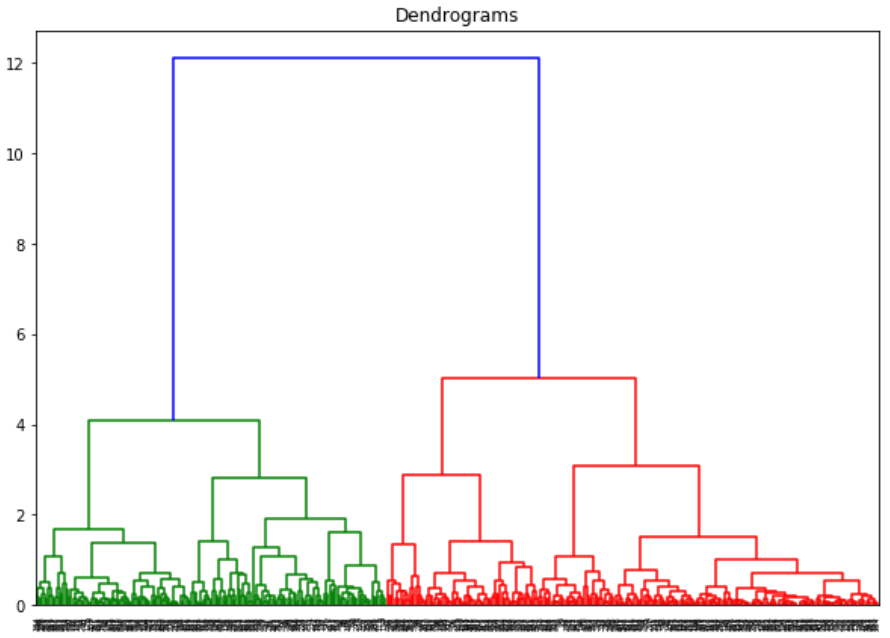
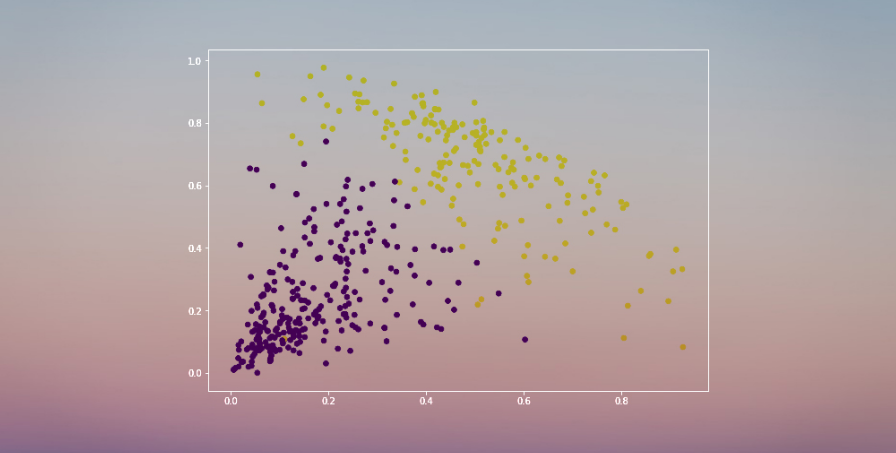
X軸爲樣本,y軸表徵樣本之間的距離。距離最大的垂直的線是藍色的線,因此我們可以決定閾值爲6,然後切斷樹狀圖:

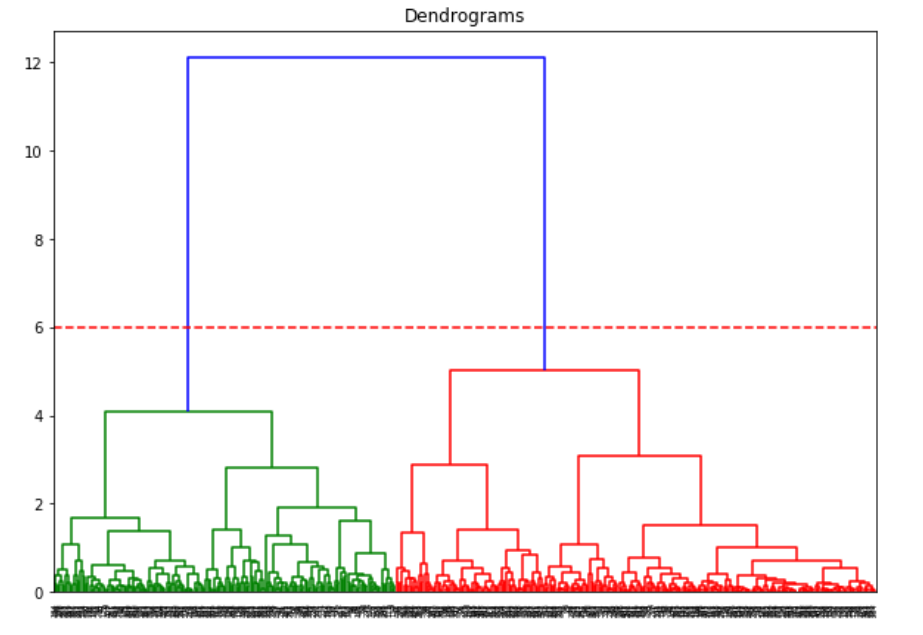
這條線有兩個交點,因此我們有兩個簇。讓我們使用層級聚類:
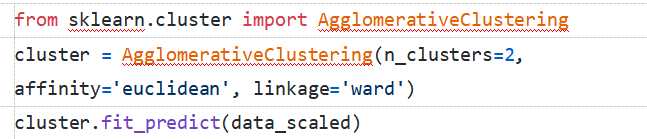

在我們定義2個簇之後,我們可以看到輸出結果中0 和1的值。0代表屬於第一個簇的值,而1代表屬於第二個簇的值。現在將兩個簇進行可視化:

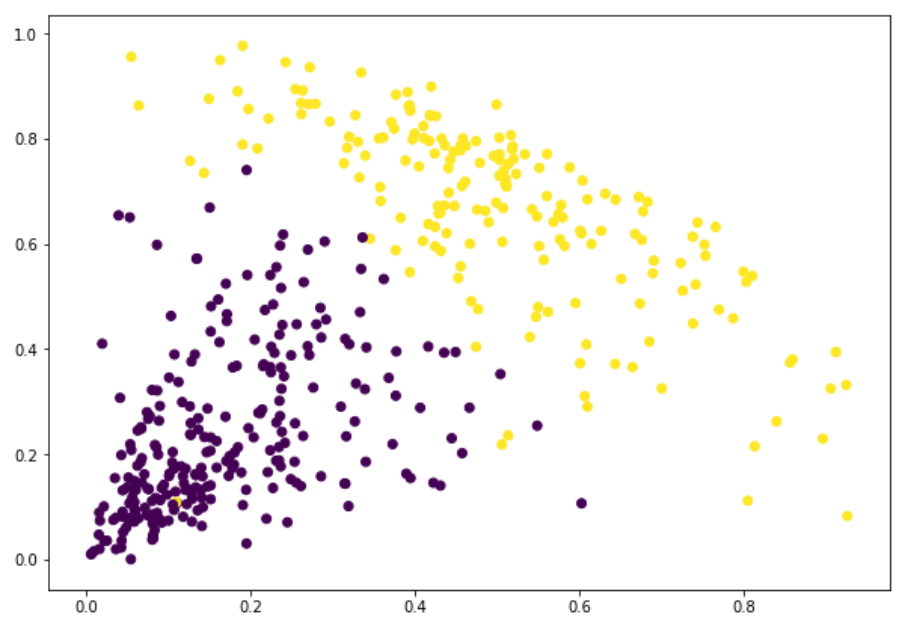
太棒了!我們現在可以清晰地看到兩個簇。這是我們用Python來實現層級聚類的過程。
寫在最後的話
層級聚類是一種非常有用的劃分觀察值的方法。優勢在於無需預定義集羣數量,這使它比k-Means更具優勢。
如果你對數據科學還比較陌生,強烈建議你學習實用機器學習課程(https://courses.analyticsvidhya.com/courses/applied-machine-learning-beginner-to-professional?utm_source=blog&utm_medium=beginners-guide-hierarchical-clustering)。這是你可以在任何地方找到的最全面的端到端的機器學習課程之一。層級聚類只是課程中涵蓋的衆多主題之一。
原文標題:
A Beginner’s Guide to Hierarchical Clustering and how to Perform it in Python
原文鏈接:
https://www.analyticsvidhya.com/blog/2019/05/beginners-guide-hierarchical-clustering/
編輯:王菁
校對:楊學俊
譯者簡介
陳超,北京大學應用心理碩士在讀。本科曾混跡於計算機專業,後又在心理學的道路上不懈求索。越來越發現數據分析和編程已然成爲了兩門必修的生存技能,因此在日常生活中盡一切努力更好地去接觸和了解相關知識,但前路漫漫,我仍在路上。