Petr Baudis是捷克布拉格技術大學的一名博士生,他也是創業公司Rossum.ai的創始人。近日,Petr在Meduium上發表了一篇博客,結合自己在強化學習方面的研究以及在圍棋方面的應用講述瞭如何按AlphaGo Zero的原理打造自己的AlphaGo Zero,以下則是由我們整理的相關內容:
我的故事:從圍棋到神經網絡,不期而遇
多年來,我一直聚焦於強化學習領域——尤其在讓計算機玩圍棋的棋盤遊戲領域。我之前就被這個遊戲迷住了,它被認爲是我們最終可以解決、但又是最棘手的挑戰之一。
我當時編寫了當時最強大的開源程序Pachi,後來又發佈了一個演示性程序Michi(這是一個簡約的圍棋蒙特卡洛搜索引擎,僅有550行Python代碼)。幾個月後,Google DeepMind宣佈了他們的AlphaGo程序在神經網絡應用方面取得的重大突破(按:即AlphaGo戰勝歐洲冠軍樊麾);同時我也將神經網絡的研究應用在了自然語言處理領域上。
DeepMind的AlphaGo Zero在一個月前再次引爆了了人工智能社區——這一次,他們的神經網絡能夠在沒有人類的知識(監督學習或手工數據)的情況下從頭開始完全學習,所需要的計算量也更少。正如DeepMind在其博客中所說:
「無需人類知識即可精通圍棋遊戲」
人工智能的一個長期目標是通過後天的自主學習(注:tabula rasa,意爲「白板」,指所有的知識都是逐漸從他們的感官和經驗而來),在一個具有挑戰性的領域創造出超越人類的精通程度學習的算法。此前,AlphaGo成爲首個戰勝人類圍棋世界冠軍的程序......我們將介紹一種僅基於強化學習的算法,而不使用人類的數據、指導或規則以外的領域知識。AlphaGo成爲自己的老師,這一神經網絡被訓練用於預測AlphaGo自己的落子選擇,提高了樹搜索的強度,使得落子質量更高,具有更強的自我對弈迭代能力。從一塊白板開始,我們的新程序AlphaGo Zero表現驚人,並以100:0擊敗了此前版本的AlphaGo。
當天晚上我很興奮地閱讀了這篇發表在《Nature》上的論文。結合我將神經網絡應用於圍棋AI的經驗,我可以很快了解AlphaGo Zero的原理,其算法比之前的AlphaGo更簡單,其神經網絡訓練的循環也更精緻,我很快對Nochi進行了調整,當我凌晨5點終於睡下時,新版本的Nochi圍棋程序已經在Rossum的GPU集羣中開始訓練了。
DeepMind的故事:從AlphaGo到AlphaGo Zero
AlphaGo Zero的原理很簡單:一個單一的、可以同時評估位置並建議接下來的走法的神經網絡,而通過經典的蒙特卡羅樹搜索算法可以構建遊戲走法樹,探索變化及找到應手——只有在這種情況下,它只使用神經網絡,而不是進行隨機的遊戲模擬(而之前所有強大的圍棋程序都是如此)。
AlphaGo從一個完全隨機、只能進行混沌的預測的神經網絡開始,在一次又一次地迭代中自我對弈。神經網絡可以根據預測正確或錯誤的結果來進行訓練並建立強化學習策略,隨着時間的推移從混沌中形成自己的規則。
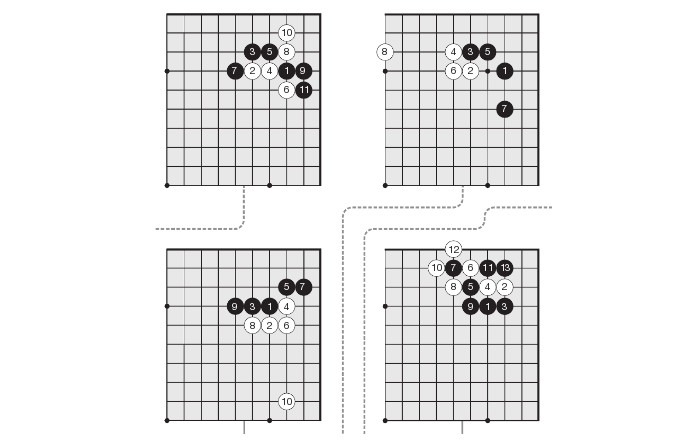
通過這樣的「第一原則」進行學習並達到超過人類水平的做法實際上要比原來的AlphaGo快得多,這真是太神奇了。同時令人驚訝的是,所發現的策略實際上與人類數千年來的發展非常相似——這也說明我們的做法是正確的!
如果將AlphaGo與AlphaGo Zero進行比較時,很容易發現AlphaGo Zero的三大主要進展:
不要基於人類遊戲的遊戲記錄進行訓練。
用一個簡單的神經網絡代替之前AlphaGo中使用的兩個神經網絡的複雜聯鎖。
在圍棋局勢評估的卷積神經網絡中使用剩餘單元(ResNet-like)。
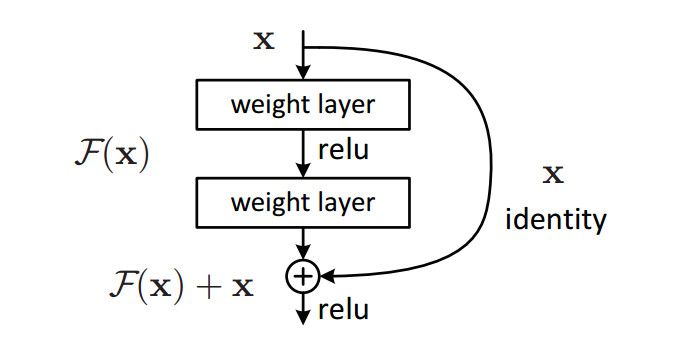
用於圖像識別的深度殘差學習(arxiv)
最後我有一個一般性建議:如果您使用Pre-ResNet的卷積神經網絡進行視覺任務,請考慮升級精度是否重要!在Rossum,我們持續看到所有這些工作的準確性都有所提高,AlphaGo團隊也是如此。
Rossum的圍棋程序:Nochi
在這個用Python寫的圍棋程序Michi中包含了圍棋規則的實現,蒙特克洛樹搜索算法和用於評估的隨機遊戲模擬。這是理想的狀況 —— 只需用基於Keras的神經網絡來代替隨機遊戲模擬,併爲程序添加一個「自我演奏」訓練循環即可(當然,把它寫出來只花了一個晚上,但這並不是說我們在接下來的幾個星期裏沒有進行過調試...)
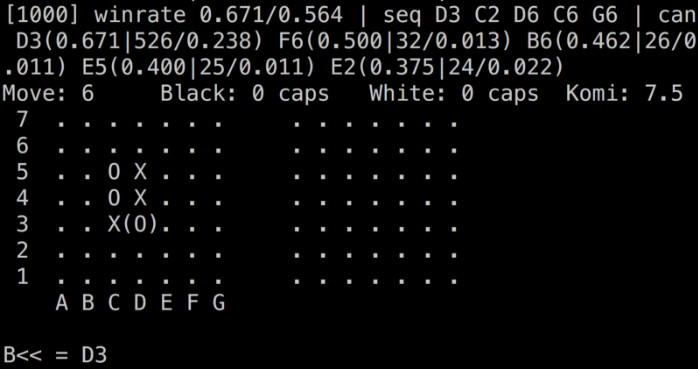
但還有一個問題:儘管AlphaGo Zero比老款Alphago要求低得多,但按常規硬件手段,運行相同的設置仍然需要1700 GPU年的訓練時間。 (考慮一下Google的計算能力,以及他們用TPU所做的加速)。因此,我們做了相應的簡化,我們不是使用全尺寸的19x19板,而是僅在最小的靈敏板7x7上訓練Nochi 。
同時我們還對原始方法進行了調整:基於我們在Rossum的實踐,我們稍微修改了神經網絡的架構,以及採用了一個更激進的訓練過程,確保自我遊戲期間的神經網絡儘快收斂,使得Nochi成爲第一個達到GNU Go基準水平的AlphaGo復現版本(GNU Go是一個經典的中級程序,通常用於其他算法的基準測試)。另外,Nochi的水平隨着每次移動所的分配時間提高而得到提高,這表明神經網絡不僅僅記住了遊戲,而且學會了概括和計算抽象策略。
下面說重點。Nochi已經在GitHub上開源,而且仍然是一個任何人易於上手學習的小型Python程序。目前我們正在進行其他複製AlphaGo Zero的其他成功工作,例如 Leela Zero和Odin Zero。畢竟,我們還需要一個任何人都可以安裝和學習的、超人類的圍棋軟件,儘管我們主業是在文檔處理(我們的願望是消除所有的手動數據輸入)上,我們將視其作爲我們一項可以長期發展的衍生成果進行更新。
關於AlphaGo和Nochi的更多信息,可關注以下鏈接:
DeepMind最新的《Nature》論文及AlphaGO Zero Cheat Sheet(原理表單)
我在Machine Learning Meetup上演講的PPT以及相關視頻(見下)