LSTM是一種時間遞歸神經網絡,適合於處理和預測時間序列中間隔和延遲相對較長的重要事件。在自然語言處理、語言識別等一系列的應用上都取得了很好的效果。
《Long Short Term Memory Networks with Python》是澳大利亞機器學習專家Jason Brownlee的著作,裏面詳細介紹了LSTM模型的原理和使用。
該書總共分爲十四個章節,具體如下:
第一章:什麼是LSTMs?
第二章:怎麼樣訓練LSTMs?
第三章:怎麼樣準備LSTMs的數據?
第四章:怎麼樣在Keras中開發LSTMs?
第五章:序列預測建模
第六章:怎麼樣開發一個Vanilla LSTM模型?
第七章:怎麼樣開發Stacked LSTMs?
第八章:開發CNN LSTM模型
第九章:開發Encoder-Decoder LSTMs
第十章:開發Bidirectional LSTMs
第十一章:開發生成LSTMs
第十二章:診斷和調試LSTMs
第十三章:怎麼樣用LSTMs做預測?
第十四章:更新LSTMs模型
本文的作者對此書進行了翻譯整理之後,分享給大家。我們還將繼續推出一系列的文章來介紹裏面的詳細內容,和大家一起來共同學習,支持答疑!支持答疑!支持答疑!重要的事情說三遍!有相關問題大家都可在文章底部給我們留言!一定會回覆你的!
本文有12000字左右,閱讀需12分鐘,建議收藏學習。
1.0 前言
1.0.1 課程目標
本課程的目的是讓你對LSTM有一個更高層次的理解,這樣你就可以解釋它們是什麼以及它們是怎麼樣工作的。
完成這一課之後,你會知道:
序列預測是什麼,以及它們和一般的預測建模問題有什麼樣的區別;
多層感知器( Multilayer Perceptrons )在序列預測上的侷限性、循環神經網絡(Recurrent Neural Networks)在序列預測上的保障以及LSTM是怎麼樣傳遞那種保障的;
一些令人影響深刻的LSTMs挑戰序列預測問題的應用以及一些LSTMs侷限性的警告
1.0.2 課程概覽
本課程被劃分爲6節,它們是:
序列預測問題;
多層感知機的侷限性;
循環神經網絡的保障;
LSTM網絡;
LSTM網絡的應用;
LSTM網絡的侷限性。
讓我們開始吧!
1.1 序列預測問題
序列預測和其他類型的監督學習問題來說是不同的。序列強調觀察值的順序,當訓練模型和做出預測的時候這個順序必須被保存。總的來說,設計序列數據的預測問題被稱爲序列預測問題,儘管基於輸入和輸出順序的不同,這種稱法還有很多問題。本節,我們將會看四種類型的序列預測問題:
序列預測(Sequence Prediction);
序列分類(Sequence Classification);
序列生成(Sequence Generation);
序列到序列的的預測(Sequence-to-Sequence Prediction)。
但是,首先,讓我們一起確定一個集合和一個序列之間的區別。
1.1.1 序列
在應用機器學習中我們經常用到集合,例如訓練集和測試集。集合中的每個樣本可以被認爲是來自其範圍內的觀察值。在一個集合中,觀察的順序並不重要。一個序列則不同,序列強調觀察值的詳細的順序。這裏順序非常重要!在使用序列數據作爲模型的輸入和輸出時,必須在預測問題的定義中特別地慎重對待!
1.1.2 序列預測
序列預測包括預測給定輸入序列的下一個值。例如:
輸入序列:1,2,3,4,5
輸出序列:6
列表 1.1:序列預測問題的例子
graph LR
A["[1,2,3,4,5]"]-->B["序列預測模型"]
B["序列預測模型"]-->C["[6]"]
 圖1.1 序列預測問題的描述
圖1.1 序列預測問題的描述
序列預測問題也通常被稱爲序列學習。從技術上講,我們可以將所有下面的問題都認爲是序列預測問題的其中一種類型。這可能會讓初學者感到困惑。
連續數據學習仍然是模式識別和機器學習中的一項基本任務和挑戰。包含數據順序的應用可能需要對新事件的預測、新序列的生成或者諸如序列或者子序列分類的決策。
— On Prediction Using Variable Order Markov Models, 2004.
一般來說,本書中,我們將使用「序列預測」來指代具有序列數據預測問題的這一類別。然而,在這部分,我們將會把序列預測和其他形式的具有序列數據的預測進行區分,將其定義爲作爲預測下一個時間步長的預測。
序列預測嘗試去根據前面的元素來預測序列的元素。
— Sequence Learning: From Recognition and Prediction to Sequential Decision Making, 2001.
一些序列預測問題的問題包括:
天氣預測。給定一個序列的基於時間的天氣的觀察值,預測明天的天氣。
股票預測。給定一個基於時間的有價證券序列波動值,預測明天有價證券的波動。
產品推薦。給定一個客戶曾經的購物情況,預測下一個階段客戶的購物。
1.1.3 序列分類
序列分類包括預測給定輸入序列的分類標籤。例如:
輸入序列:1,2,3,4,5
輸出序列:「good」
列表 1.2:序列分類問題的例子
graph LR
A["[1,2,3,4,5]"]-->B["序列預測模型"]
B["序列預測模型"]-->C["good"]
圖1.2 序列分類問題的描述
序列分類問題的目的是利用標記數據集[...]建立一個分類模型,以便該模型可以用來預測一個看不見的序列的分類標籤。
— Discrete Sequence Classification, Data Classification: Algorithms and Applications, 2015.
輸入序列可以由實際值或者離散值組成。在後一種情況下,這些問題可以被稱爲離散序列分類問題。序列分類問題的一些例子包括:
DNA序列分類。給定DNA序列值A,C,G和T,預測序列是編碼區域還是非編碼區域。
自動檢測。給定一個序列的觀察值,預測序列是否是反常的。
情感分析。給定一個文本的序列,例如綜述或者是推特,預測這段文本的情感是積極的還是消極的。
1.1.4 序列生成
序列生成包含一個新的輸出序列,該序列和語料集裏面序列有着相同的特徵。例如:
輸入序列:[1,3,5],[7,9,11]
輸出序列:[3,5,7]
列表 1.3:序列生成問題的例子
graph LR
A["[1,3,5],[7,9,11]"]-->B["序列預測模型"]
B["序列預測模型"]-->C["[3,5,7]"]
圖1.3 序列生成問題的描述
循環神經網絡(RNN)可以通過一步一步地處理真實數據序列來預測序列生成,並預測接下來會發生什麼。[遞歸神經網絡]可以通過一步一步地處理真實數據序列來預測序列生成,並預測接下來會發生什麼。假設預測是概率的,可以通過從網絡的輸出分佈迭代採樣來從訓練網絡生成新序列,然後在下一步驟中將樣本餵給輸入。換句話說,讓網絡把他們的發明視爲真實的,就像一個人做夢一樣。相對新的,seq2seq方法在[結果]實現了state-of-the-art機器翻譯。
— Generating Sequences With Recurrent Neural Networks, 2013.
序列生成問題的一些例子包括:
文本生成:給定一個語料集的文本,例如莎士比亞的文學作品,生成新的句子或者段落的文本,它們可以從語料集中提取出來。
手寫體預測:給定一個手寫體的語料庫,生成具有在語料庫中具有手寫屬性的新的短語的手寫體。
音樂生成:給定音樂實例的語料庫,生成具有語料庫屬性的新音樂片段。 序列模型可以指以單次觀測作爲輸入的序列生成。一個例子是圖像的自動文本描述。
圖像字幕的生成:給定圖像作爲輸入,生成描述該圖像的單詞序列。
例如:
輸入序列:[圖像像素]
輸出序列:["一個人騎着自行車"]
列表 1.4:序列生成問題的例子
graph LR
A["圖像像素"]-->B["序列預測模型"]
B["序列預測模型"]-->C["一個人騎着自行車"]
圖1.4 序列生成問題的描述
使用適當的句子能夠自動描述圖像內容是一項非常具有挑戰性的任務,但是它可能會產生很大的影響[...]。確實,一個描述不僅必須捕獲圖像中所包含的對象,而且還必須表示這些對象是如何關聯的,以及它們的屬性和它們所涉及的活動。
— Show and Tell: A Neural Image Caption Generator, 2015.
1.1.5 序列到序列預測
序列到序列的預測涉及給定一個輸入序列並預測一個輸出序列,例如:
輸入序列:1,2,3,4,5
輸出序列:6,7,8,9,10
列表 1.5:序列到序列問題的例子
graph LR
A["圖像像素"]-->B["序列預測模型"]
B["序列預測模型"]-->C["一個人騎着自行車"]
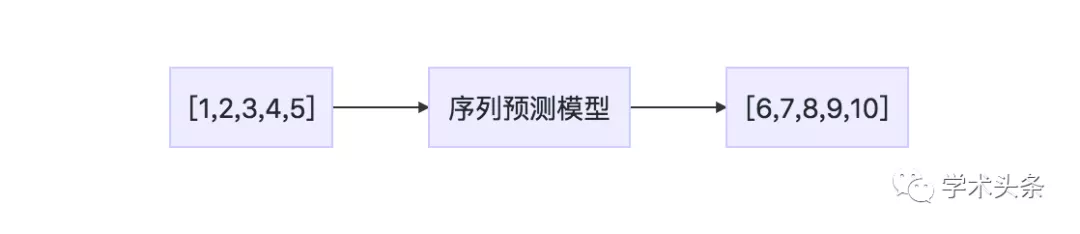
圖1.5 序列到序列問題的描述
儘管深度神經網絡具有靈活性,能力強大,但是它只能應用於這類問題:即輸入和目標可以很明顯地被編碼爲一個固定維度向量。這是一個很明顯的限制,因爲很多重要問題的輸入最好用一個長度未知的序列來表示,並沒有一個可知的先驗。例如,原因識別和機器翻譯是連續的問題。同樣地,問答也可以被看做是將代表問題的單詞序列映射到表示答案的單詞序列。
— Sequence to Sequence Learning with Neural Networks, 2014.
序列到序列預測是序列預測一個很微妙而又很具有挑戰性的擴展。不是在在序列中預測單一的下一個值,一個新的序列被預測出來,該序列可能會或者可能不會和輸入序列有着相同的長度或者同一時間。這類問題最近在文本自動翻譯領域出現了很多的研究(如翻譯英語到語法)可以被縮寫爲seq2seq。seq2seq學習,其核心是,使用循環神經網絡來將變長的輸入序列映射成爲一個可變長度輸出序列。
— Multi-task Sequence to Sequence Learning, 2016.
如果輸入和輸出的序列都是時間序列,那麼該問題可以被稱爲多步時間序列預測。序列到序列問題的一些例子包括:
多步時間序列預測。給定一系列時間觀察值,預測一系列未來時間步長的觀測序列。
文本摘要。給定文本文檔,預測描述源原檔的突出部分的較短文本序列。
程序執行。給定文本描述程序或數學方程,預描述正確輸出的字符序列。
1.2 感知機的侷限性
傳統的神經網絡叫做感知機(Multilayer Perceptrons),或者簡稱爲MLP,可以被用於序列模型的預測問題。MLP近似從輸入變量到輸出變量的映射函數。由於一系列的原因,其總的能力對於序列預測問題是很有用的(特別是時間序列預測)。
對噪聲很健壯。神經網絡對輸入數據和映射函數中的噪聲具有很強的魯棒性,甚至可以在缺失值的存在下支持學習和預測。
非線性。神經網絡對映射函數不做強假設,容易學習線性和非線性關係。
另外,在映射函數中,MLP可以被配置爲支持任意數量的輸入和輸出,但有一定數量的輸入和輸出。這意味着:
多變量輸入。可以指定任意數量的輸入,爲多變量預測提供提供直接的支持。
多步輸出。可以指定任意數量的輸出,爲多步甚至多變量預測提供直接支持。
其能力克服了使用傳統線性方法的限制(如用於時間序列預測的ARIMA)。僅憑這些能力,前向神經網絡被廣泛應用於時間序列預測。
ARIMA模型全稱爲自迴歸積分滑動平均模型(Autoregressive Integrated Moving Average Model,簡記ARIMA)。ARIMA模型的基本思想是:將預測對象隨時間推移而形成的數據序列視爲一個隨機序列,用一定的數學模型來近似描述這個序列。這個模型一旦被識別後就可以從時間序列的過去值及現在值來預測未來值。
神經網絡的一個重要的貢獻——即它們優雅地逼近任意非線性函數的能力。這種性質在時間序列處理中具有很高的價值,並保證了更強大的應用,特別是在預測的子領域中...
— Neural Networks for Time Series Processing, 1996.
MLP在序列預測上的應用需要輸入序列被劃分成較小的重疊子序列,這些子序列被顯示成給網絡用來生成一個預測。輸入序列的時間步長成爲網絡的輸入特徵。子序列是重疊的,以模擬沿該序列滑動的窗口,以便生成所需的輸出。這在一些問題上效果很好,但是它有5個關鍵的限制:
無狀態。MLP學習一個固定函數的近似。在輸入序列的上下文中有條件的任何輸出必須被泛化和固定到網絡權重中。
不知道時間結構。時間步長被建模爲輸入特徵,這意味着網絡對觀測之間的時間結構或者順序沒有明確的處理或者理解。
尺度混亂。對於需要建模多個並行輸入序列的問題,輸入特徵的數量作爲滑動窗口的大小的額一個元素而增加,而沒有任何時間序列的顯示分離。
固定大小的輸入。滑動窗口的大小是固定的,必須強加到所有的輸入中。
固定大小的輸出。輸出的大小也是固定的,任何不符合的輸出都必須強制成爲固定的大小。
MLP確實爲序列預測提供了很大的能力,但是仍然受到整個關鍵限制的限制,即必須在模型設計中明確地預先說明觀測之間的時間依賴的範圍。
序列到序列對「深度神經網絡」提出了挑戰,因爲它們要求輸入和輸出的位數是已知的並且是固定的。
— Sequence to Sequence Learning with Neural Networks, 2014
MLP是建模序列到序列模型問題的好的起點,但是我們現在有更好的選擇。
1.3 序列模型的保證
長短時記憶,或者LSTM網絡是一種類型的循環神經網絡。循環神經網絡(簡稱RNN)是一種特殊類型的用於序列問題的神經網絡。給定一個標準的前饋MLP網絡,RNN可以被認爲是添加到體系結構的環路。例如,在給定的層中,除了正向下一層之外,每個神經元可以逐漸地(側向)傳遞其信號。網絡的輸出可以用下一個輸入向量作爲輸入反饋給網絡,等等。
循環連接將狀態或存儲器添加到網絡中,並允許它學習和利用輸入序列中觀測的有序性。
循環神經網絡包含環,這個環將上一個階段的網絡激活作爲輸入餵給網絡,來影響當前階段的預測。這些激活被存儲在網絡的內部狀態中,其原則上可以保持長期時間上下文信息。這種機制允許RNN在輸入序列歷史上利用動態變化的上下文窗口。
— Long Short-Term Memory Recurrent Neural Network Architectures for Large Scale Acoustic Modeling, 2014
序列的增加是被逼近的函數的一個新的維度。網絡可以學習一個基於時間的從輸入到輸出的映射函數,而不是單純將輸入映射到輸出。內部存儲器可以表示輸出時基於輸入序列的中的最近上下文,而不是剛被呈現爲網絡的輸入。從某種意義上說,這種能力解鎖了神經網絡的時間序列。
長短時記憶(LSTM)可以解決很多不能被反饋網絡使用固定大小時間窗口解決的任務。
— Applying LSTM to Time Series Predictable through Time-Window Approaches, 2001
除了使用神經網絡進行序列預測的一般方法外,RNN還可以學習和利用數據的時間依賴性。也就是說,在最簡單的情況下,網絡顯示一個序列中的一個時間的一次觀察,並且可以瞭解先前觀察到的觀測結果是相關的,以及它們是如何預測相關的。
由於這種學習序列中長期相關性的能力,LSTM網絡避免了預先指定時間窗口的需要,並且能夠精確地模擬複雜的多變量序列。
— Long Short Term Memory Networks for Anomaly Detection in Time Series, 2015
循環神經網絡的保證是輸入數據中的時間依賴和上下文信息可以被學習到。
循環神經網絡的輸入不是固定的,而是構成一個序列,可以用來將輸入序列轉換成輸出序列,同時以可理解的方式考慮上下文信息。
— Learning Long-Term Dependencies with Gradient Descent is Dicult, 1994.
有許多種的RNN,但是是LSTM在序列預測中傳遞RNN的保證。這就是爲什麼LSTM現在有這麼多的聲音和應用的原因。
LSTM具有內部狀態,它們明確地知道輸入中的時間結構,能夠分別對多個並行輸入序列進行建模,並且可以通過不同長度的輸入序列來產生可變長度的輸出序列,每一時間一次觀察。
接下來,讓我們仔細看看LSTM網絡。
1.4 LSTM網絡
LSTM網絡和傳統MLP是不同的。像MLP,網絡由神經元層組成。輸入數據通過網絡傳播以進行預測。與RNN一樣,LSTM具有遞歸連接,使得來自先前時間步的神經元的先前激活狀態被用作形成輸出的上下文。
和其他的RNN不一樣,LSTM具有一個獨特的公式,使其避免防止出現阻止和縮放其他RNN的問題。這,以及令人影響深刻的結果是可以實現的,這也是這項技術得以普及的原因。
RNNs一直以來所面臨的一個關鍵問題是怎麼樣有效地訓練它們。實驗表明,權重更新過程導致權重變化,權重很快變成了如此之小,小到沒有效果(梯度消失)或者權重變得如此之大,導致非常大的變化或者溢出(梯度爆炸),這一問題是非常的困難的。LSTM通過設計而克服了這一困難。
不幸的是,標準的RNN可以訪問的上下文信息的範圍實際上是非常有限的。問題是隱藏層上給定輸入,以及因此在網絡上的輸出,當它圍繞網絡的經常性連接循環時,要麼指數衰減,要麼指數上升。這個缺點...在文獻中被稱爲梯度消失問題...長短時記憶(LSTM)是一種設計用於解決梯度消失問題的RNN體系結構。
— A Novel Connectionist System for Unconstrained Handwriting Recognition, 2009
LSTM網絡的計算單元被稱爲存儲單元(memory cell),存儲器塊(memory block)或者簡稱單元(cell)。當描述MLPs時,術語「神經元」作爲計算單元是根深蒂固的,因此它經常被用來指LSTM存儲單元。LSTM單元由權重和門組成。
長短時結構是通過對現有RNN中的誤差進行分析,發現長時間滯後對現有體系結構是不可訪問的,因爲反向傳播誤差要麼指數上升要麼衰減。LSTM層由一組遞歸連接的塊組成,稱爲存儲塊(memory blocks)。這些塊可以被認爲是數字計算機中存儲芯片的可微版本。每一個包含一個或者多個遞歸連接的存儲單元和單個乘法單元——輸入門、輸出門和遺忘門,它們爲單元提供寫、讀和重置操作的連續模擬。...網絡只能通過門與細胞相互作用。
— Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures, 2005.
1.4.1 LSTM權重
一個記憶單元具有輸入、輸出的權重參數,以及通過暴露於輸入時間步長而建立的內部狀態。
輸入權重。用於對當前時間步長的輸入進行加權。
輸出權重。用於對上次步驟的輸出進行加權。
內部狀態。在這個時間步長的輸出計算中使用內部狀態。
1.4.2 LSTM門
記憶單元的關鍵是門。這些也是加權函數,它們進一步控制單元中的信息。有三個門:
遺忘門。決定什麼樣的信息需要從單元中丟棄。
輸入門。決定輸入中哪些值來更新記憶狀態。
輸出門。根據輸入和單元的內存決定輸出什麼。
在內部狀態的更新中使用了遺忘門和輸入門。輸入門是單元實際輸出什麼的最後限制。正是這些門和一致的數據流被稱爲CEC(constant error carrousel),它保持每個單元穩定(既不爆炸或者消失)。
每個存儲單元的內部結構保證CEC(its constant error carrousel)。這表示橋接的基礎滯後很長的時間。兩個門單元學習在每個存儲單元CEC中的打開和關閉對錯誤的訪問。乘法輸入門提供保護的CEC從擾動無關的輸入。同樣地,乘法輸出門保護其他單元不受當前不相關存儲器內容的干擾。
— Long Short-Term Memory, 1997.
不像傳統的MLP神經元,很難畫出一個乾淨的LSTM存儲單元。到處都有線、權重和門。看看本章末尾的一些資源,如果你認爲基於圖片或者基於等式的LSTM內部描述將有助於進一步研究。我們可以將LSTM的3個關鍵術語歸納爲:
克服了訓練RNN的技術問題,即梯度消失和梯度爆炸問題。
擁有記憶來克服與輸入序列相關的長期時間依賴問題。
一個個時間步長地處理輸入序列和輸出序列,允許可變長度的輸入和輸出。
接下來,讓我們看看一些例子,其中LSTMs解決了一些具有挑戰性的問題。
1.5 LSTMs的應用
我們感興趣的是LSTMs爲解決序列預測問題提供的高雅的解決方案。本節提供3個示例,爲您提供LSTM能夠實現的結果快照。
1.5.1 自動圖片標題生成
自動圖片標題的任務是在給定圖像的情況下,系統必須生成一個標題,描述圖像的內容。在2014年,有深度學習算法實現實現了突破性的進展,利用頂部模型在圖片中進行物體分類和對象檢測,在這個問題上取得了非常令人印象深刻的結果。
一旦你可以在照片中檢測出對象並未這些對象生成標籤,你就可以看到下一步就是將這些標籤轉換成連貫的句子描述。該系統涉及使用非常大的卷積神經網絡在照片中檢測物體,然後LSTM將標籤轉換成連貫的句子。
 圖1.6 LSTM生成標題的示例,取自《顯示並告知:一個神經網絡標題生成器》,2014
圖1.6 LSTM生成標題的示例,取自《顯示並告知:一個神經網絡標題生成器》,2014
1.5.2 文本自動翻譯
自動文本翻譯的認爲是在一個語言中給出文本的句子,並且必須把它們翻譯成爲另外一種語言的文本。例如,英語句子作爲輸入,語法句子作爲輸出。該模型必須學習單詞的翻譯,翻譯的上下文被修改,並支持輸入和輸出序列的長度可能總體上相互變化。
 圖1.7 將英文文本翻譯成法語的例子,從預測到預期的翻譯,出自神經網絡的序列到序列的學習,2014
圖1.7 將英文文本翻譯成法語的例子,從預測到預期的翻譯,出自神經網絡的序列到序列的學習,2014
1.5.3 自動手寫體生成
這個任務中,在給定手寫體語料庫的情況下,生成給定單詞或者短語的新的手寫體。當手寫樣本被創建時,手寫被提供爲筆所使用的座標序列。在這個語料庫中,學習了筆運動與字母之間的關係,併產生了新的例子。有趣的是,不同的風格可以學習,然後模仿。我希望看到這項工作結合一些法醫筆記分析的專業知識。  圖1.8 LSTM生成字幕的例子,摘自《循環神經網絡的生成序列》,2014
圖1.8 LSTM生成字幕的例子,摘自《循環神經網絡的生成序列》,2014
1.6 LSTMs的限制
LSTMs給人留下了深刻的印象。網絡的設計克服了RNNs的技術挑戰,用神經網絡實現了對序列預測的保證。LSTM的應用在一系列的複雜問題上取得了令人印象深刻的結果。但是LSTMs對於所有的序列預測問題可能不是理想的。
例如,在時間序列預測中,通常用於預測信息在過去觀察的一個小窗口內。通常,具有窗口或線性模型的MLP可能是一個不太複雜和更合適的模型。
文獻中發現的時間序列基準問題...通常概念上比LSTM已經解決的許多任務更簡單。它們通常不需要RNNs,因爲有關下一個事件的所有相關信息都是由一些在小時間窗口中包含的最近事件傳達的。
— Applying LSTM to Time Series Predictable through Time-Window Approaches, 2001
LSTM的一個重要的侷限是記憶。或者更準確地說,記憶是如何被濫用的。有可能迫使LSTM模型在很長的輸入時間步長上記住單個觀察。這是LSTM的不良使用,並且需要LSTM模型記住多個觀察將失敗。當將LSTM應用於時間序列預測時,可以看出,該問題表述爲迴歸,要求刪除是輸入序列中的多個遙遠時間步長的函數。一個LSTM可能被迫在這個問題上執行,但是通常比一個精心設計的自迴歸模型或重新考慮問題一般少一些。
假設任何動態模型都需要t-tau,...,我們注意到[autoregression]-RNN必須將t-tau的所有輸入存儲到t,並在適當的時間覆蓋它們。這需要實現一個循環的緩存,這是一個對RNN進行模擬很困難的結構。
— Applying LSTM to Time Series Predictable through Time-Window Approaches, 2001
警告,LSTM並不是一種令人期待的新技術,而且需要仔細的考慮你問題的框架。把LSTMs的內部狀態看做是一個方便的內部變量來捕捉和提供預測的背景。如果你的問題看起來像一個傳統的自迴歸問題,在一個小窗口內具有最相關的滯後觀察,那麼在考慮LSTM之前,也許使用MLP和滑動窗口開發性能的基線。
基於時間窗口的MLP在某些時間序列預測基準上優於LSTM的pure-[autoregression]方法,僅通過查看最近的一些輸入來解決。因此,LSTM的特殊長處,即學會記住很長的、位置的時間段的單個事件,是不必要的。
— Applying LSTM to Time Series Predictable through Time-Window Approaches, 2001
1.7 擴展閱讀
如果你想深入研究算法的技術細節,下面是一些關於LSTM的文章。
1.7.1 序列預測問題
Sequence on Wikipedia。
On Prediction Using Variable Order Markov Models, 2004.
Sequence Learning: From Recognition and Prediction to Sequential Decision Making, 2001.
Chapter 14, Discrete Sequence Classification, Data Classification: Algorithms and Applications, 2015.。
Generating Sequences With Recurrent Neural Networks, 2013.
Show and Tell: A Neural Image Caption Generator, 2015.
Multi-task Sequence to Sequence Learning, 2016.
Sequence to Sequence Learning with Neural Networks, 2014.
Recursive and direct multi-step forecasting: the best of both worlds, 2012.
1.7.2 MLPs用於序列預測
Neural Networks for Time Series Processing, 1996.
Sequence to Sequence Learning with Neural Networks, 2014.
1.7.3 RNNs的保障
Long Short-Term Memory Recurrent Neural Network Architectures for Large Scale Acoustic Modeling, 2014.
Applying LSTM to Time Series Predictable through Time-Window Approaches, 2001.
Long Short Term Memory Networks for Anomaly Detection in Time Series, 2015.
Learning Long-Term Dependencies with Gradient Descent is Dicult, 1994.
On the diculty of training Recurrent Neural Networks, 2013.
1.7.4 LSTMs
Long Short-Term Memory, 1997. Learning to forget: Continual prediction with LSTM, 2000.
A Novel Connectionist System for Unconstrained Handwriting Recognition, 2009.
Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures, 2005.
1.7.5 LSTM應用
Show and Tell: A Neural Image Caption Generator, 2014.
Sequence to Sequence Learning with Neural Networks, 2014.
Generating Sequences With Recurrent Neural Networks, 2014.
1.8 拓展
1.9 總結
在本課中,您發現了用於序列預測的長短時記憶循環神經網絡。你知道嗎?
序列預測是什麼?它們是如何不同於一般預測建模問題的。
多層感知機用於序列預測的侷限性,循環神經網絡用於序列預測的保障,以及LSTM是如何實現該承諾的。
令人深刻的應用LSTM挑戰序列預測問題,以及LSTM侷限性的一些警告。 接下來,您將發現如何使用反向傳播通過時間訓練算法來訓練LSTM。