北京時間 12 月 11 日晚,DeepMind 在 twitter 上宣佈推出圍棋教學工具 AlphaGo Teach。
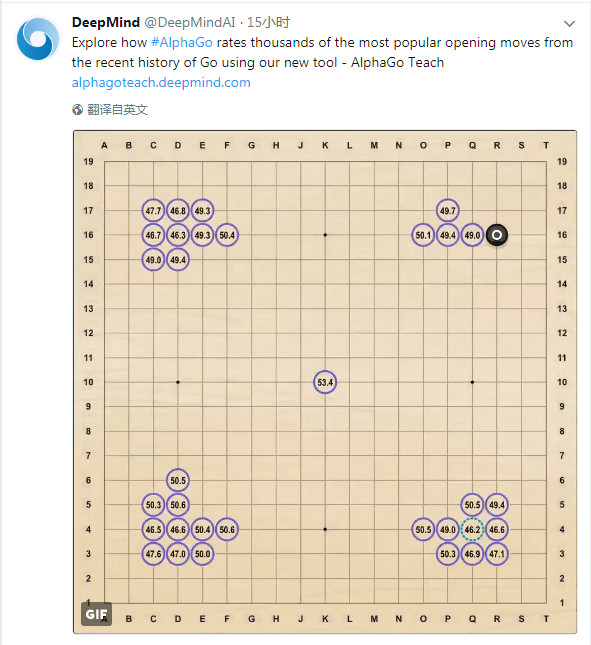
上圖中,標有白圈的黑子表示上一手,虛線圓圈表示 AlphaGo 下一步可能的走法,實線圓圈表示人類選手下一步可能的走法,圓圈中的數字表示 AlphaGo 評估的黑子勝率。
從官網上可以看到,該工具通過利用 231000 盤人類棋手對局、75 盤 AlphaGo 與人類棋手對局的數據,能對圍棋近代史上 6000 種比較常見的開局給出分析。通過這個工具,大家可以探索圍棋奧妙,比較 AlphaGo 的下棋路數與專業選手、業餘選手的不同點,從中學習。
官網上對於工具的使用也有相關說明:
如何使用這一工具?
點擊棋盤上的彩色圓圈,或使用棋盤下方的導航工具,即可探索不同的開局變化,以及 AlphaGo 對於每一步棋的黑棋勝率預測。
圓圈中的數字代表了該步棋的黑棋勝率。當輪到黑棋落子時,數值越接近 100 表示黑棋優勢越大;當輪到白棋落子時,數值越接近 0 表示白棋優勢越大。50 則表示均勢。
瞭解 AlphaGo 的勝率預測
AlphaGo 的下法不一定總是具有最高的勝率,這是因爲每一個下法的勝率都是得自於單獨的一個 1000 萬次模擬的搜索。AlphaGo 的搜索有隨機性,因此 AlphaGo 在不同的搜索可能會選擇勝率接近的另一種下法。
除了官網上的簡單介紹,作爲 DeepMind 圍棋大使、AlphaGo 的「教練」,樊麾也在其個人微博上宣佈「AlphaGo 教學工具終於上線。」

他表示,
教學工具共有兩萬多個變化,三十七萬多步棋組成,通過 AlphaGo 的視角,分析並建議圍棋開局的諸多下法。同時每步棋 AlphaGo 都會給出自己的勝率分析,希望 AlphaGo 對圍棋的獨特理解可以給我們一些啓發。
本教學工具使用的版本是 AlphaGo Master。具體信息可以在主頁上看到,工具設有包括中文簡體在內的多個語言。
同時,樊麾也從 AlphaGo 的教學中舉了幾個有意思的例子,並進行了幽默地解說。「下邊的幾個圖是我從萬千變化圖中發現比較有衝擊力的幾個,類似的變化圖有很多很多,大家可以自己找找。」
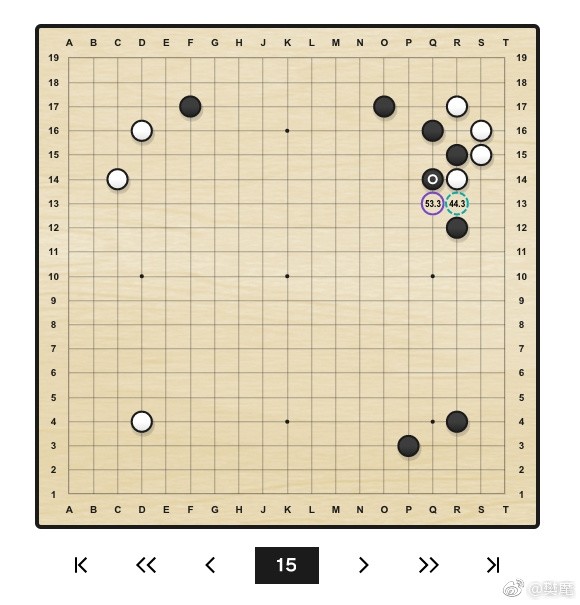
原來二路虎不見得好!
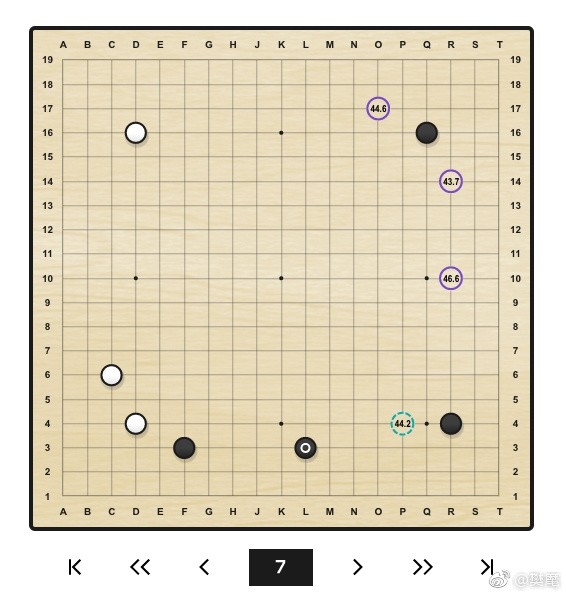
對付迷你中國流的新辦法!

小林流也不是隻有大飛掛!
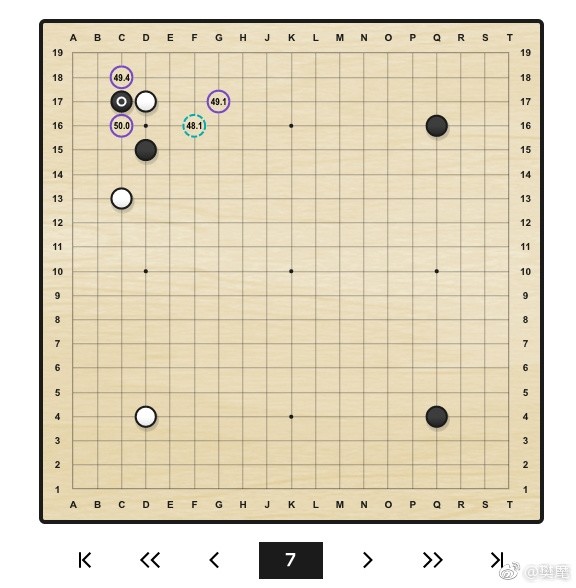
原來這裏還可以飛!
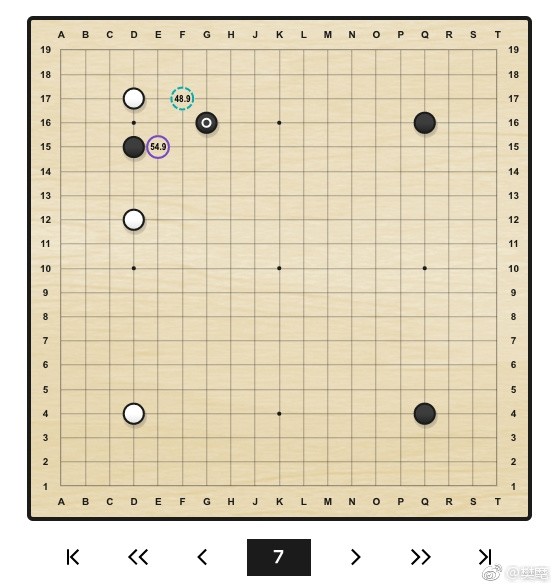
妖刀定式!
而在看到樊麾老師的微博之後,大家也開始了各色各樣的調侃。
@ 樓天,「有 21 天從入門到精通系列課程嗎?」
@ 我就是那一片浮雲,「完了,十段棋手猛烈增加。」
@ 自動高速公路,「做成 app 就可以成爲圍棋比賽作弊器了。」
@ 於縛風,「圍棋輔導班的老師沒法講課了。」(圍棋老師表示哭暈在廁所)
看完了大家的調侃,來看看專業棋手們怎麼說。
世界圍棋冠軍、職業九段棋手常昊表示,教學工具不一定是標準答案,更多的是給予了我們無限的思考空間。
首屆百靈愛透杯世界圍棋公開賽冠軍周睿羊說到,「定式什麼的還是不要隨便學了,看到工具一些高級下法之後,感覺到又可以起飛了。」
第 3 屆鑽石杯龍星戰冠軍,圍棋國手李喆也對這一教學工具發表中肯評價:很多人會擔心今後佈局的標準化,其實不必擔心。教學工具並不是告訴大家「只能這麼下」,而是告訴大家「有些下法不太好」以及「可以這麼下」。有些圖中沒有的下法只是因爲模擬的隨機性而未被收錄,它們之中包含很多高勝率的選點,仍可以大膽嘗試。
此外,今年五月份被 AlphaGo Master 打敗的柯潔第一時間轉發微博表示「重新學圍棋。」(還用了一個賤賤的 doge 表情)
而這個工具到底好不好用,大家可以去自行體驗。
官網英文地址如下:https://alphagoteach.deepmind.com/
中文地址如下:https://alphagoteach.deepmind.com/zh-hans
附 David Silver 介紹 AlphaGo Master 的研發關鍵:
AlphaGo Master 爲何如此厲害呢?
我們讓 AlphaGo 跟自己對弈。這是基於強化學習的,我們已經不再拿人類的棋局給它學習了。AlphaGo 自己訓練自己,自己從自己身上學習。通過強化學習的形式,它學到如何提高。
在棋局的每一回合,AlphaGo 運行火力全開(full power)的搜索以生成對落子的建議,即計劃。當它選擇這一步落子、實施、併到一個新回合時,會再一次運行搜索,仍然是基於策略網絡和價值網絡、火力全開的搜索,來生成下一步落子的計劃,如此循環,直到一局棋結束。它會無數次重複這一過程,來產生海量訓練數據。隨後,我們用這些數據來訓練新的神經網絡。
首先,當 AlphaGo 和它自己下棋時,用這些訓練數據來訓練一個新策略網絡。事實上,在 AlphaGo 運行搜索、選擇一個落子的方案之前,這些是我們能獲取的最高質量的數據。
下一步,讓策略網絡只用它自己、不用任何搜索,來看它是否能產生同樣的落子的方案。這裏的思路是:讓策略網絡只靠它自己,試圖計算出和整個 AlphaGo 的火力全開搜索結果一樣的落子方案。這樣一來,這樣的策略網絡就比之前版本的 AlphaGo 要厲害得多。
我們還用類似的方式訓練價值網絡。它用最好的策略數據來訓練,而這些數據,是出於完全版本的 AlphaGo 自己和自己下棋時的贏家數據。你可以想象,AlphaGo 自己和自己下了非常多盤棋。其中最有代表性的棋局被選取出來提取贏家數據。因此,這些贏家數據是棋局早期回合步法的非常高質量的評估。
最後,我們重複這一過程許多遍,最終得到全新的策略和價值網絡。比起舊版本,它們要強大得多。然後再把新版本的策略、價值網絡整合到 AlphaGo 裏面,得到新版本的、比之前更強大的 AlphaGo。這導致樹搜索中更好的決策、更高質量的結果和數據,再循環得到新的、更強大的策略、價值網絡,再次導致更強大的 AlphaGo,如此不斷提升。
更多詳細信息,可以參見此前發文:現場|David Silver原文演講:揭祕新版AlphaGo算法和訓練細節