選自arXiv
作者:吳翼、吳育昕、Georgia Gkioxari、田淵棟
構建虛擬 3D 環境對於強化學習研究非常重要。近日,UC Bekerley 博士生吳翼、FAIR 研究工程師吳育昕、博士後 Georgia Gkioxari 和研究科學家田淵棟共同提交了一篇論文,提出一種基於 SUNCG 數據集構建的豐富、可擴展的高效環境 House3D。研究者用連續和離散動作空間訓練強化學習智能體,改善了它們在新環境中的泛化能力。該論文目前已提交至 ICLR 2018 大會。
項目鏈接:https://github.com/facebookresearch/House3D
近期,深度強化學習已在多種遊戲上顯示了自己的能力,如 Atari 遊戲(Mnih et al., 2015)和圍棋(Silver et al., 2016),在其中都展示了超越人類的水平。這些巨大成就的根基在於高效明確、可進行自由學習與探索的智能體模擬環境。目前爲止,很多研究人員提出的環境已經編碼了人類智能的某些方面,其中包括 3D 感知(DeepMind Lab(Beattie et al., 2016)和 Malmo(Johnson et al., 2016))、實時決策(TorchCraft(Synnaeve et al., 2016)和 ELF(Tian et al., 2017))、快速反應(Atari(Bellemare et al., 2013))、長期計劃(圍棋、國際象棋)、語言和交流(ParlAI(Miller et al., 2017)和(Das et al., 2017b))。
儘管如此,深度強化學習在這些模擬環境中的進展是否能夠以及如何遷移到真實世界仍然是一個開放性問題。對於這個方向,最重要的事情就是構建模擬真實世界的環境,該環境需要具備真實世界豐富的結構、內容和動態性。爲了加快學習,這些環境應該實時響應,並提供大量多樣化的複雜數據。儘管我們很需要這些特性,但它們仍然無法保證達到泛化目標。泛化是智能體在新場景中成功完成任務的能力,這對實際應用非常重要。例如在很多房子裏訓練的家用機器人或在很多城市中訓練的自動駕駛汽車,應該能夠輕鬆部署到與訓練場景完全不同的新房子或新城市。
儘管人們往往認爲泛化與學習有關,但是毫無疑問泛化與訓練智能體的環境的多樣性有關。爲了促進泛化,環境需要提供大量數據,允許智能體測試其在新條件下識別和動作的能力。要驗證智能體是否開發出智能技巧,而不是僅憑記憶(過擬合),具備無偏、無限制本質的新型生成環境是必要的。注意:泛化和大型數據集之間的結合帶來了圖像識別和目標識別領域的近期進展(Russakovsky et al., 2015; He et al., 2015)。
與泛化被正式定義和充分研究的監督學習相反,強化學習中的泛化可以用多種方式來理解。DeepMind 實驗室(Beattie et al., 2016; Higgins et al., 2017)通過像素級顏色或紋理變化和迷宮佈局引入環境多樣性。Tobin et al. (2017) 通過引入隨機噪聲改變物體顏色,來探索像素級的泛化。Finn et al. (2017b) 研究在獎勵僅提供給任務的部分子集時,智能體在類似任務配置環境中的泛化能力。Pathak et al. (2017) 測試智能體在同樣遊戲更困難級別的泛化能力。
但是,環境中的像素級變化(如物體的顏色和紋理)或難度級別變化在智能體那裏卻經常得出非常近似的視覺觀察結果。在真實世界中,人類感知和理解複雜的視覺信號。例如,一個人到了朋友家,即使裝飾和設計都是新的,他也能輕鬆識別出哪是廚房。而智能體要想在真實世界中成功,需要理解新的結構佈局和多樣的物體外表。智能體需要能夠將語義與新場景聯繫起來,在視覺變化場景中實現泛化。這篇論文研究了語義級別的泛化,其中的訓練環境和測試環境在視覺上不相同,但共享同樣的高級別概念屬性。具體來說,研究者提出一個包括數千個室內場景(具備不同的場景類型、佈局和物體)的虛擬 3D 環境 House3D,見圖 1a。House3D 利用 SUNCG 數據集 (Song et al., 2017),該數據集包含 4.5 萬個人類設計的真實世界 3D 房子模型,其中的物體全部標註成不同類別。研究者將 SUNCG 數據集轉換至 House3D 環境,這對於不同任務都是有效且可擴展的。在 House3D 中,智能體可自由探索空間,感知大量不同視覺外表的物體。
House3D 展示了智能體確實能夠在新基準任務 RoomNav 中學習高級別概念,並泛化至未見的新場景中。在 RoomNav 中,智能體開始位於房子的隨機位置,並被要求去往高級語義概念指定的目的地(如廚房)。RoomNav 示例見圖 1b。研究者從 House3D 中手動選取了 270 個房子,並將其分割成兩個訓練集(20 個房子和 200 個房子)和一個用於評估的留出集(50 個房子)。這些房子足夠大,且適合導航任務。研究者展示了:使用用標準深度強化學習方法(如 A3C 和 DDPG)訓練的 gated-CNN 和 gated-LSTM 策略,大型多樣化訓練集可以改善智能體在 RoomNav 中的泛化能力。這與小型訓練集的結果相反,其中出現了顯著的過擬合。此外,深度(depth)信息和語義信號(如分割)帶來更好的泛化效果。前者(深度)促進即時動作,後者(分割)幫助在新環境中的語義理解。實驗結果證明了爲真實世界機器人構建實際視覺系統的意義,同時引出在處理複雜的真實世界任務時,分離視覺和機器人學習等方向。
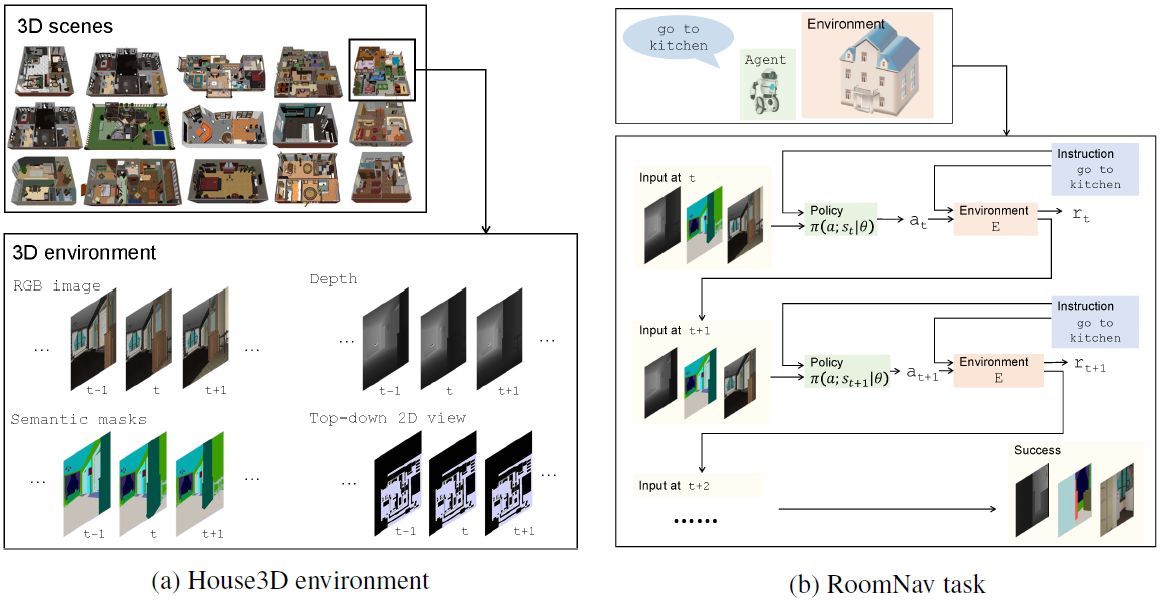
圖 1:House3D 環境和 RoomNav 任務概覽。
(a)研究者基於 SUNCG 數據集構建了一個高效的交互式環境,該數據集包含 4.5 萬個不同的室內場景,從單間到帶游泳池和健身房的兩層樓房。所有 3D 對象都被完全標註成 80 多個類別。環境中的智能體可獲得多種模式的觀察結果(如 RGB 圖像、深度、分割掩碼、自上而下的 2D 視角等。(b)研究者專注於基於語義的導航任務。給定一個高級任務描述,智能體自行探索環境,到達目標房間。
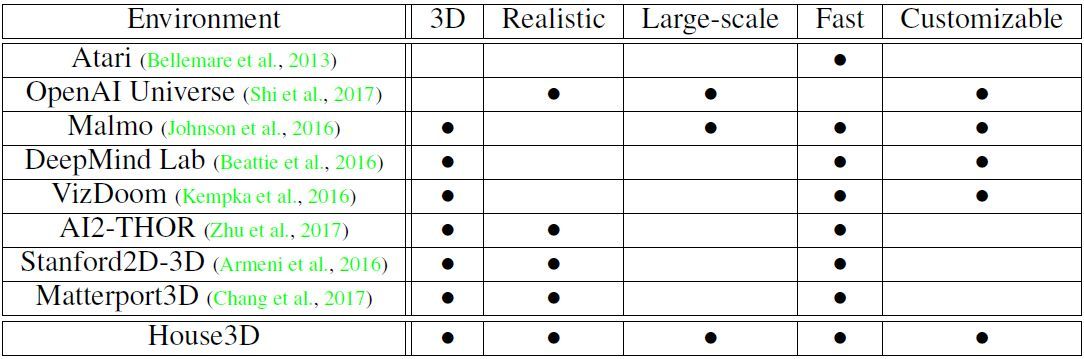
表 1:常用環境總結。屬性包括 3D:渲染對象的 3D 本質;真實(Realistic):與現實世界的相似度;大規模(Large-Scale):大型環境集合;Fastspeed:快速渲染;可定製(Customizable):可定製用於其他應用的靈活性。
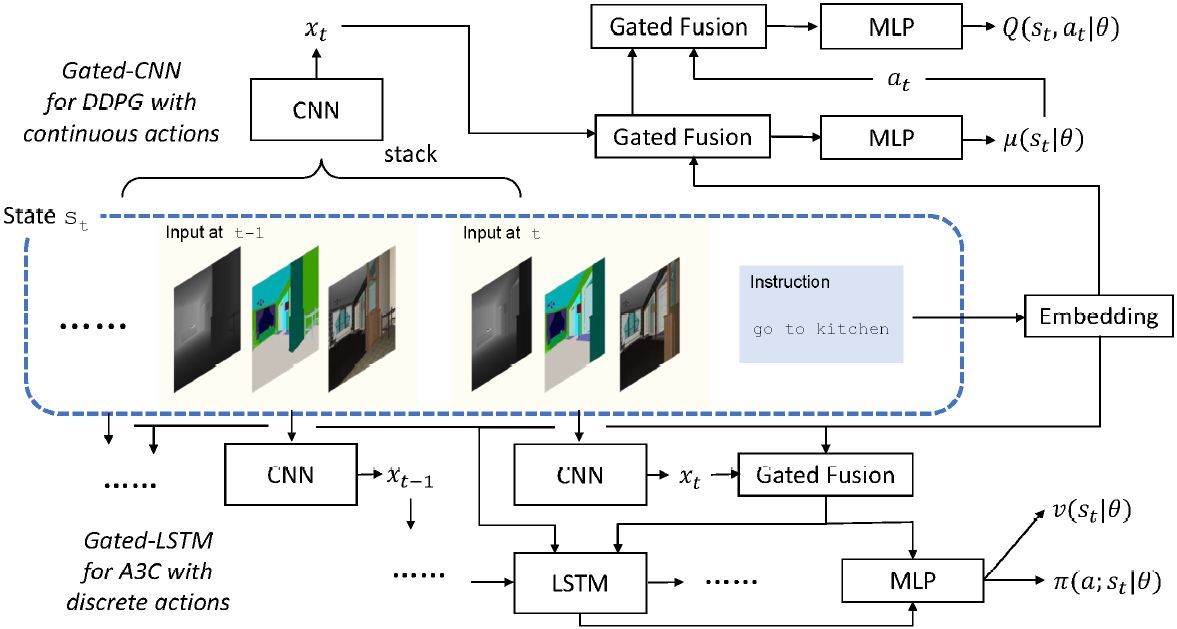
圖 2:論文提出模型概覽。下方代表用於離散動作的 gated-LSTM 模型,上方代表用於連續動作的 gated-CNN 模型。Gated Fusion 模塊指門控注意力(gated-attention)架構。
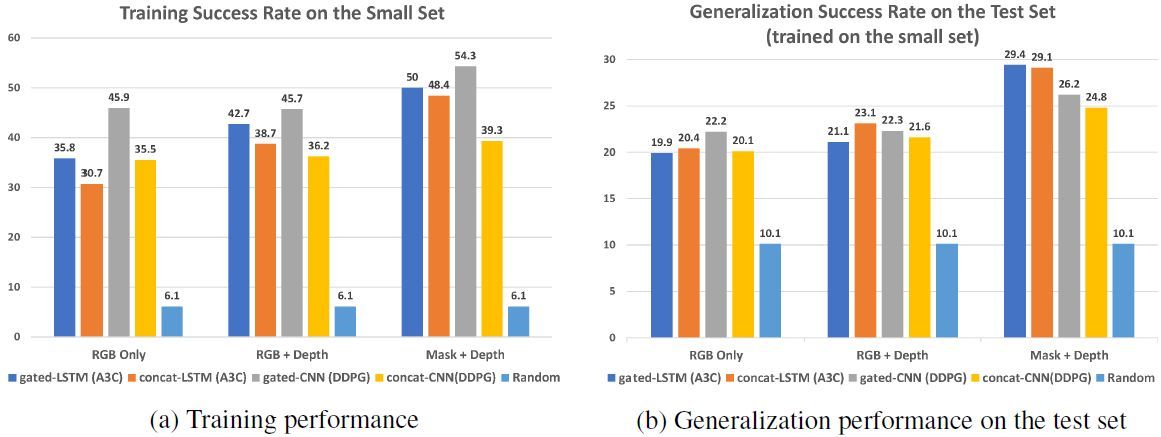
圖 3:不同模型在具備不同輸入信號(RGB Only、RGB+Depth 和 Mask+Depth)的 Esmall(20 個房屋)上訓練時的性能。每一組中,從左到右的條分別對應 gated-LSTM、concat-LSTM、gated-CNN、concat-CNN 和隨機策略。
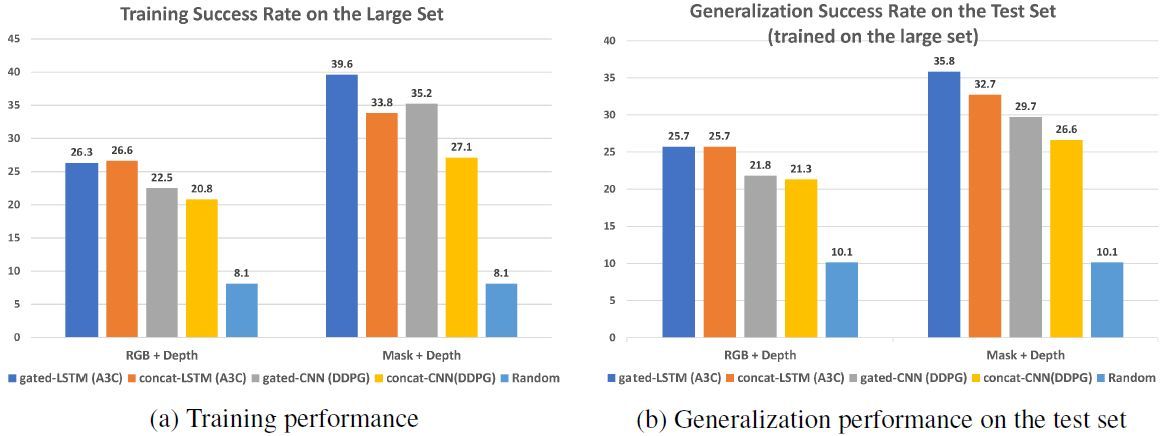
圖 4:不同模型在帶有 RGB+Depth 和 Mask+Depth 輸入信號的 Elarge(200 個房屋)上訓練時的性能。每一組中,從左到右的直方條分別對應 gated-LSTM、concat-LSTM、gated-CNN、concat-CNN 和 隨機策略。
論文:Building Generalizable Agents with a Realistic and Rich 3D Environment

論文鏈接:https://arxiv.org/abs/1801.02209
摘要:要縮小機器智能與人類之間的差距,引入視覺真實、內容充實的環境至關重要。在此類環境中,你可以評估和改善實際智能系統的關鍵特性,即泛化。本研究構建了一種豐富、可擴展的高效環境 House3D,包含 45622 個人工設計的 3D 房屋場景,從單人間到樓房應有盡有;且該環境具備一套完整標註的 3D 物體、材質和場景佈置,基於 SUNCG 數據集(Song et al., 2017)。我們重心關注語義級別的泛化,使用 House3D 的子集研究概念驅動的導航任務 RoomNav。在 RoomNav 中,智能體根據語義概念的指定導航至目的地。爲了成功,該智能體通過開發感知來理解所處的場景,通過將場景映射到正確的語義來理解概念,通過觀察底層物理規則來導航至目的地。我們用連續和離散動作空間訓練強化學習智能體,展示了它們在新環境中的泛化能力。具體來說,我們觀察到(1)在大型房屋集合上進行訓練的難度顯著增加,但泛化能力也要好得多;(2)使用語義信號(如分割掩碼)提升泛化性能;(3)語義輸入信號的門網絡(gated network)可以改善訓練性能和泛化能力。我們希望 House3D(包括對 RoomNav 任務的分析)能夠對設計實際的智能系統有所幫助,也希望社區廣泛使用該環境。