深度生成模型可以應用到學習目標分佈的任務上。它們近期在多種應用中發揮作用,展示了在自然圖像處理上的巨大潛力。生成對抗網絡(GAN)是主要的以無監督方式學習此類模型的方法之一。GAN 框架可以看作是一個兩人博弈,其中第一個玩家生成器學習變換某些簡單的輸入分佈(通常是標準的多變量正態分佈或均勻分佈)到圖像空間上的分佈,使得第二個玩家判別器無法確定樣本術語真實分佈或合成分佈。雙方都試圖最小化各自的損失,博弈的最終解是納什均衡,其中沒有任何玩家能單方面地優化損失。GAN 框架一般可以通過最小化模型分佈和真實分佈之間的統計差異導出。
訓練 GAN 需要在生成器和判別器的參數上求解一個極小極大問題。由於生成器和判別器通常被參數化爲深度卷積神經網絡,這個極小極大問題在實踐中非常困難。結果,人們提出了過多的損失函數、正則化方法、歸一化方案和神經架構。某些方法基於理論洞察導出,其它的由實踐考慮所啓發。
在本文中谷歌大腦提供了對這些方法的全面的經驗分析,作爲研究員和從業者在這個領域的引導。他們首先定義了 GAN 全景圖(GAN landscape):損失函數、歸一化和正則化方案,以及最常用架構的集合。他們在多個現代大規模數據集上通過超參數優化探索了這個搜索空間,考慮了文獻中報告的「好」超參集合,以及由高斯過程迴歸得到的超參集合。通過分析損失函數的影響,他們總結出非飽和損失 [9] 在各種數據集、架構和超參上足夠穩定。接着,研究者分析了不同歸一化和正則化方案,以及不同架構的影響。結果表明梯度懲罰 [10] 以及譜歸一化 [20] 在高深度架構中都很有用。然後他們證實我們可以同時使用正則化和歸一化來改善模型。最後,他們討論了常見陷阱、復現問題和實踐考慮。研究者提供了所有參考實現,包括 GitHub 上的訓練和評估代碼,並在 TensorFlow Hub 上提供了預訓練模型。
Github:http://www.github.com/google/compare_gan
TensorFlow Hub:http://www.tensorflow.org/hub
論文:The GAN Landscape: Losses, Architectures, Regularization, and Normalization

論文地址:https://arxiv.org/abs/1807.04720
摘要:生成對抗網絡(GAN)是一類以無監督方式學習目標分佈的深度生成模型。雖然它們已成功應用到很多問題上,但訓練 GAN 是很困難的並需要大量的超參數調整、神經架構工程和很多的「技巧」。在許多實際應用中的成功伴隨着量化度量 GAN 失敗模式的缺失,導致提出了過多的損失函數、正則化方法、歸一化方案以及神經架構。在這篇論文中我們將從實踐的角度清醒地認識當前的 GAN 研究現狀。我們復現了當前最佳的模型並公平地探索 GAN 的整個研究圖景。我們討論了常見的陷阱和復現問題,在 GitHub 開源了我們的項目,並在 TensorFlow Hub 上提供了我們的預訓練模型。
2 GAN 全景圖
在這一章節中,作者主要總結了 GAN 的各種變體與技術,詳細內容可參考該論文與各種 GAN 變體的原論文。作者主要從損失函數、判別器的正則化與歸一化、生成器與判別器的架構、評估度量與數據集等 5 個方面討論了各種不同的技術。
其中在損失函數中,作者討論了原版 GAN 的 JS 距離、WGAN 的 Wasserstein 距離和最小二乘等損失函數。而判別器的正則化主要爲梯度範數罰項,例如在 WGAN 中,這種梯度範數懲罰主要體現在對違反 1-Lipschitzness 平滑的軟懲罰。此外,模型還能根據數據流形評估梯度範數懲罰,並鼓勵判別器在該數據流形上成分段線性。判別器的歸一化主要體現在最優化與表徵上,即歸一化能獲得更高效的梯度流與更穩點的優化過程,以及修正各權重矩陣的譜結構而獲得更更豐富的層級特徵。
研究者主要探討了兩種生成器與判別器架構,包括深度卷積生成對抗網絡與殘差網絡。其中深度卷積生成對抗網絡的生成器與判別器分別包含 5 個卷積層,且帶有譜歸一化的變體稱爲 SNDCGAN。而 ResNet19 的生成器包含 5 個殘差模塊,判別器包含 6 個殘差模塊。
隨後的評估度量則主要包含四種,包括 Inception Score (IS)、Frechet Inception Distance (FID) 和 Kernel Inception distance (KID) 等,它們都提供生成樣本質量的定量分析。最後研究者考慮了三種數據集,並在上面測試各種 GAN 的生成效果。這些數據集包括 CIFAR10、CELEBA-HQ-128 和 LSUN-BEDROOM。
GAN 的搜索空間可能非常巨大:探索所有包含各種損失函數、正則化和歸一化策略以及架構的組合超出了能力範圍,因此在這一項研究中,研究者在幾個數據集上分析了其中一些重要的組合。
作者在表 1a 中總結了近來在各項研究中展示「比較好」的參數。並且爲了提供一個相對公平的對比,我們在表 1b 展示的超參數上執行高斯過程優化。
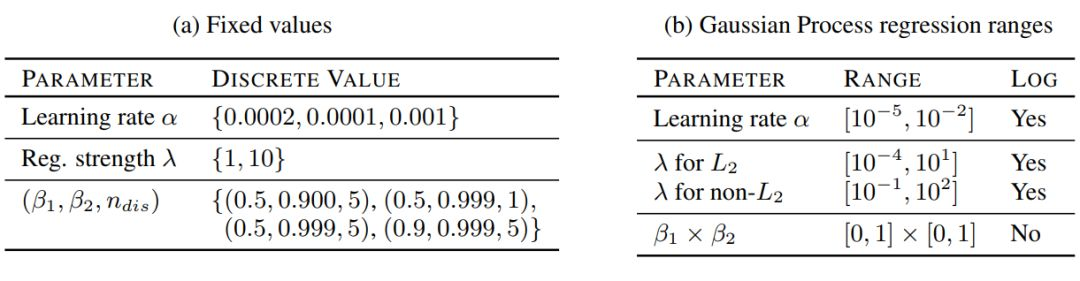 表 1:本研究中使用的超參數範圍。固定值的笛卡爾乘積足夠復現已有的結果。在 bandit setting[27] 中的高斯過程優化用於從特定範圍中選擇好的超參數集合。
表 1:本研究中使用的超參數範圍。固定值的笛卡爾乘積足夠復現已有的結果。在 bandit setting[27] 中的高斯過程優化用於從特定範圍中選擇好的超參數集合。
3 結果和討論
由於每個數據集都有四個主要成分(損失、架構、正則化、歸一化)需要分析,探索完整的全景圖是不可行的。因此,研究者選擇了一個更加實際的方案:保持某些維度爲固定值,並變化其它維度的值。在每個實驗中重點關注三個方面:(1)top5% 已訓練模型的 FID 分佈;(2)對應的樣本多樣性分數;以及(3)計算開銷(即訓練的模型數量)和模型質量(FID 度量)之間的權衡。來自固定種子集的每個模型使用不同的隨機種子訓練 5 次,並報告中位數分數。由高斯過程迴歸得到的種子方差已經隱含地得到了處理,因此每個模型只需要訓練一次。
3.1 損失函數的影響
這裏損失函數是非飽和損失(NS),或者最小二乘損失(LS)[19],或者 Wasserstein 損失(WGAN)[2]。研究者使用了 ResNet19 作爲生成器和判別器架構,架構細節在表 3a 中。本研究中考慮了最主要的歸一化和正則化方法:梯度懲罰 [10] 和譜歸一化 [20]。兩項研究都使用了表 1a 中的超參數設置,並在 CELEBA-HQ-128 和 LSUN-BEDROOM 數據集上進行實驗。
結果如圖 2 所示。可以觀察到,非飽和損失在兩個數據集上都是穩定的。譜歸一化在兩個數據集上都提高了模型質量。類似地,梯度懲罰可以幫助提高模型質量,但尋找好的正則化權衡比較困難,需要大量的計算開銷。使用 GP 懲罰的模型對判別器和生成器更新有改善的比例是 5:1,正如文獻 [10] 所提到的。
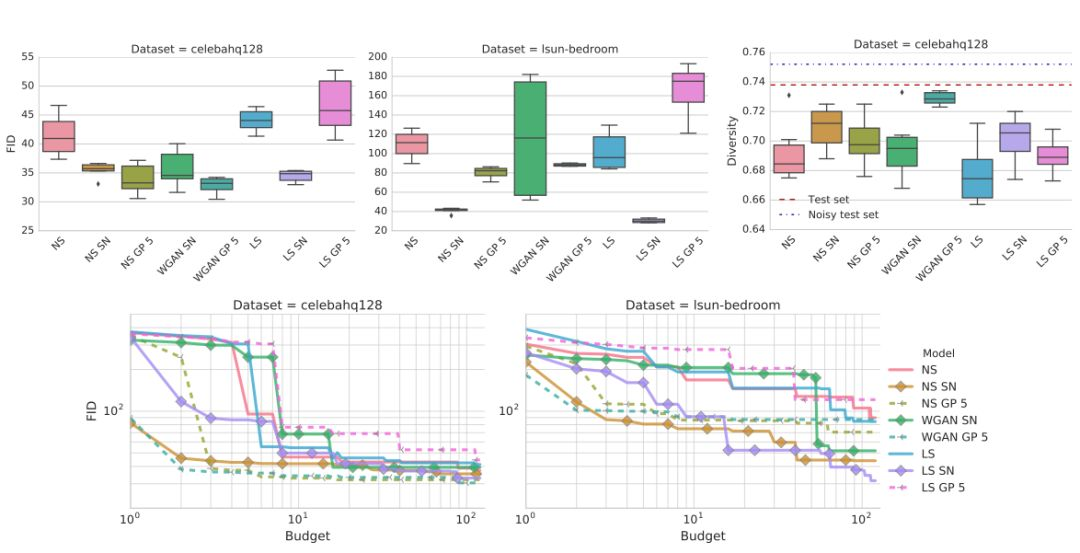
圖 1:非飽和損失在兩個數據集上都是穩定的。梯度懲罰和譜歸一化改善了模型質量。從計算開銷的角度(即需要訓練多少個模型已達到特定的 FID),譜歸一化和梯度懲罰相比基線方法的表現更好,但前者更加高效。
3.2 正則化與歸一化的影響
該研究的目的是對比文獻中提到的各種正則化與歸一化方法的表現。最終,研究者考慮批歸一化(BN)、層歸一化(LN)、譜歸一化(SN)、梯度懲罰(GP)、Dragan 懲罰(DR)或者 L2 正則化。
這些方法的結果展示在圖 2 中。可以觀察到向判別器添加批歸一化會損害最終表現。其次,梯度懲罰有所幫助,但訓練不穩定。
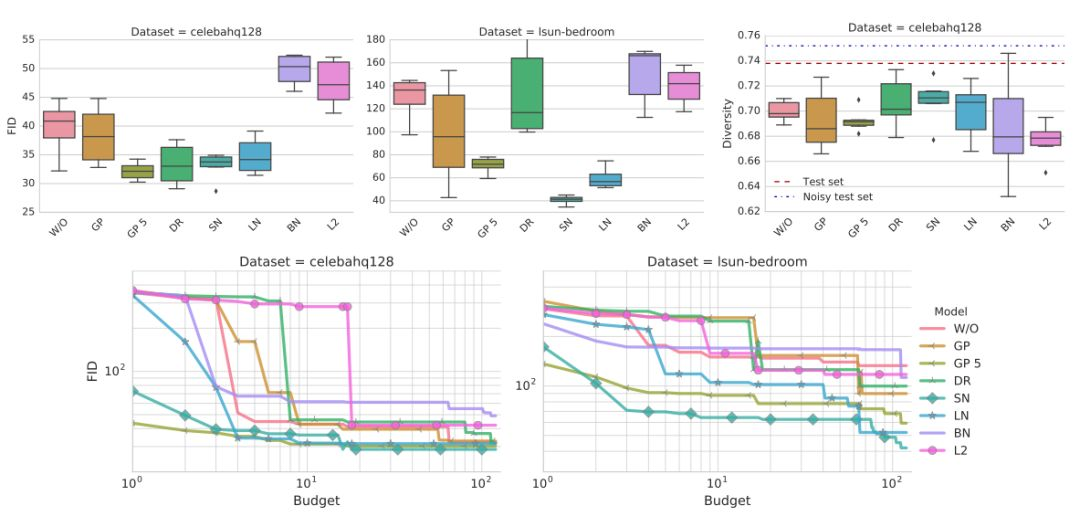 圖 2:梯度懲罰和譜歸一化表現都很好,也應被視爲可行的方法。此外,後者的計算成本更低一些。不幸的是,兩者都不能完全解決穩定性問題。
圖 2:梯度懲罰和譜歸一化表現都很好,也應被視爲可行的方法。此外,後者的計算成本更低一些。不幸的是,兩者都不能完全解決穩定性問題。
同時使用正則化和歸一化的影響:
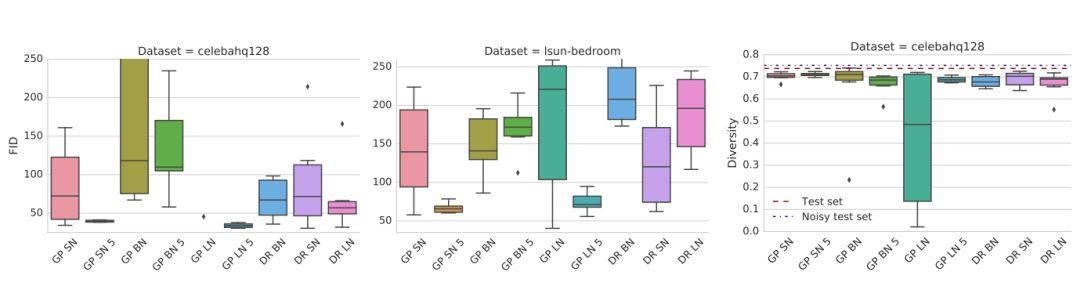 圖 3:梯度懲罰配合譜歸一化(SN)或者層歸一化(LN)方法,能夠極大地改進其表現。
圖 3:梯度懲罰配合譜歸一化(SN)或者層歸一化(LN)方法,能夠極大地改進其表現。
3.3 生成器和判別器架構的影響
一個有趣的實際問題是:本研究的發現在不同的模型容量上是否一致。爲了驗證此問題,研究者選擇了 DCGAN 類型的架構。在非飽和 GAN 損失、梯度懲罰和譜歸一化下,同樣完成了該研究。
結果如下圖 4,可以觀察到得益於正則化和歸一化,兩種架構都得到了相當好的結果。在兩種架構上,使用譜歸一化極大地超越了基線標準。
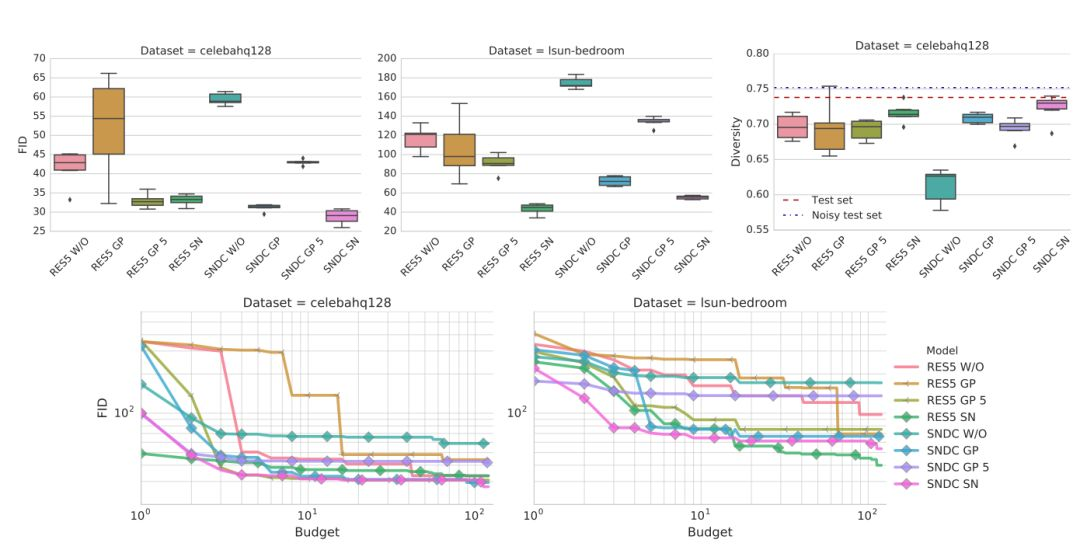 圖 4:判別器和生成器架構對非飽和 GAN 損失的影響。頻譜歸一化與梯度懲罰都能改進非正則化基線模型的表現。
圖 4:判別器和生成器架構對非飽和 GAN 損失的影響。頻譜歸一化與梯度懲罰都能改進非正則化基線模型的表現。