選自Medium
反向傳播是當前深度學習主要使用的參數更新方法,因此深度學習的硬件設計也需要擬合這種反向傳播的計算結構。本文從反向傳播的抽象表達開始簡要地分析了 BP 算法和脈動陣列架構(systolic array architecture)之間的相似性,從而表明了脈動陣列架構適合執行 BP 和進行模型訓練。
在並行計算的體系架構中,脈動陣列(systolic array)是緊密耦合的數據處理單元(data processing unit/DPU)的一種同構網絡。每一個結點或 DPU 獨立地計算部分結果,並將該部分結果作爲從上游單元接受數據的函數,在將結果儲存在當前結點後會傳遞到下游單元。本文重點在於論述反向傳播算法的抽象表達,並討論表達式與這種脈動陣列架構之間的相關性。
假設我們有一個 n=3 的多層網絡架構,且運算的對象爲 m 維向量,因此預測或推斷的過程可以表示爲:
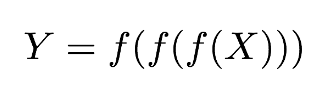
我們將預測函數 Y 放入到損失函數 l 中以進行最優化。爲了表示這種結構,我們使用圓圈表示複合函數算子(Ring 算子),因此目標函數 L 可以寫爲:
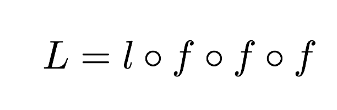
根據鏈式法則,目標函數的導數可以根據矩陣乘法的形式寫爲:
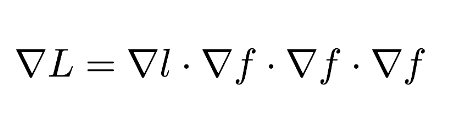
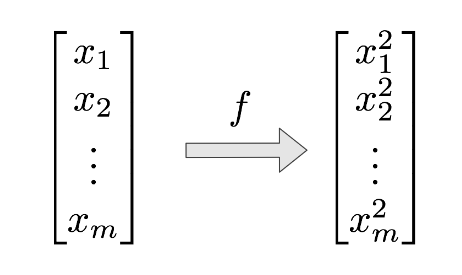
其中,鏈式乘法中的每一項都是雅可比矩陣(Jacobian matrix)。爲了更形象地說明這一過程,假設我們的損失函數 l 有以下形式:
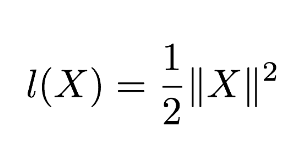
層級函數 f 僅僅只是簡單地求輸入向量中每一個元素的平方:
它們的雅可比矩陣就可以寫爲以下形式:
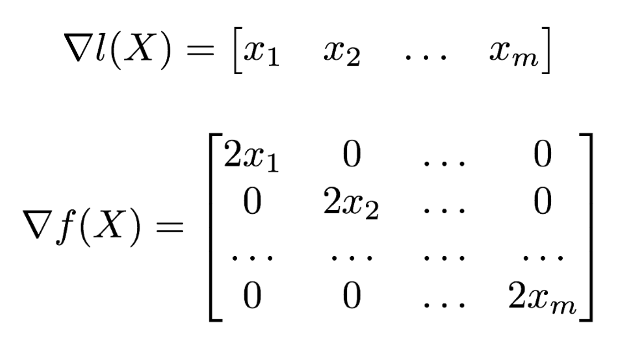
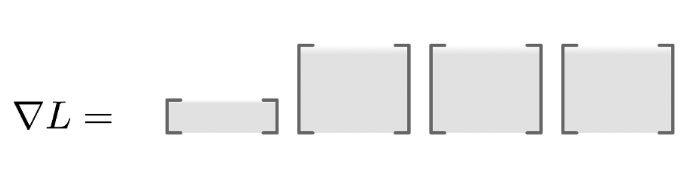
爲了計算目標函數的導數,我們需要乘以這些雅可比矩陣。因此這種鏈式矩陣乘法的維度就可以可視化爲以下形式:
計算這種鏈式矩陣乘法首先需要注意的就是確定乘法的順序,因爲矩陣的乘法分爲左乘和右乘,且不同的乘法順序會影響計算的效率,所以我們需要確定矩陣乘法的計算順序。這種尋找最優乘法序列的任務稱爲矩陣鏈式排序問題。在本案例中,因爲向量左乘矩陣還是得到一個向量,所以我們只需要從左往右進行矩陣乘積就能進行高效的計算。
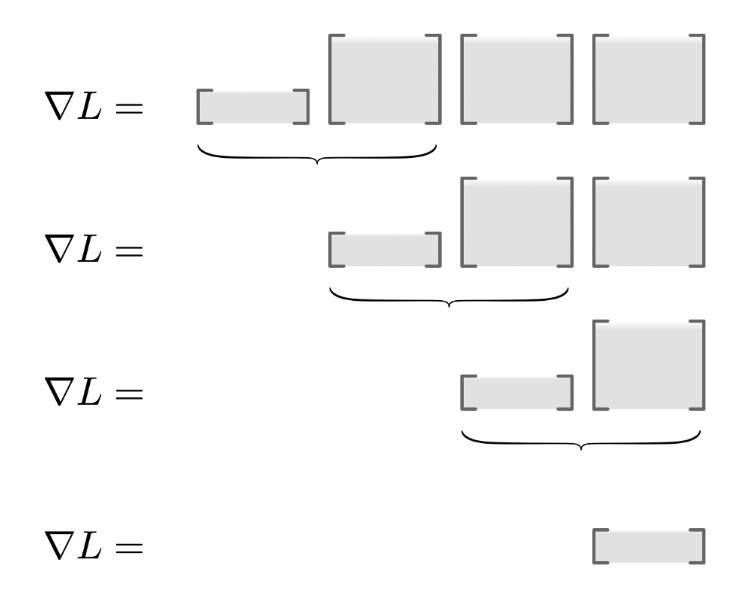
其次我們需要考慮如何具體地計算這些矩陣運算而不使用構建雅可比矩陣。這是非常重要的,因爲模型的特徵數量 m 可能是幾萬的數量級,這意味着雅可比矩陣可能有數十億的元素。在本案例中,雅可比矩陣是一個對角矩陣,那麼向量和雅可比矩陣的乘積就等價於向量對應元素間的乘積,因此我們就能避免構建一個 m-x-m 的雅可比矩陣。
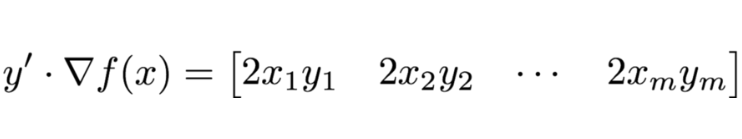
神經網絡中典型的層級函數也採用這種高效實現的運算。這種向量-雅可比乘積(vector-Jacobian product)運算是任何反向傳播算法實現的關鍵,Theano 稱其爲「Lop」(左乘算符)、PyTorch 稱之爲「backward」方法、TensorFlow 稱之爲「grad」或「grad_func」。
爲了簡化表達,我們將計算生成的中間值(即激活值)記爲 A:
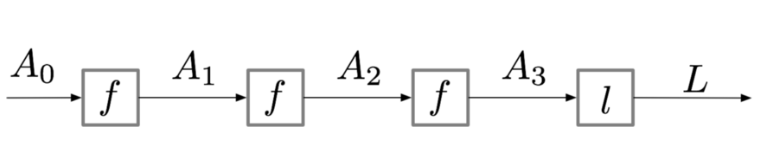
通過上圖,我們將目標函數的導數寫爲:
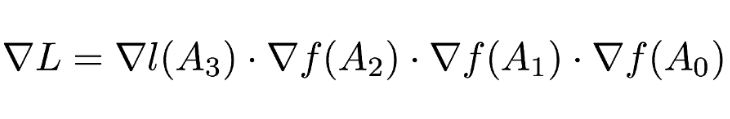
因爲損失函數的雅可比矩陣只是簡單地轉置輸入矩陣,因此我們可以寫爲:
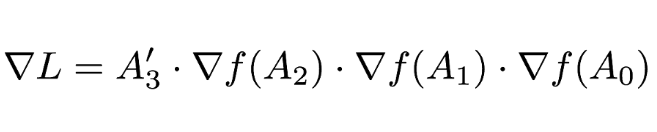
如果我們定義第一個反向傳播的值爲 B_3 = A_3',那麼我們可以將計算寫爲一個序列
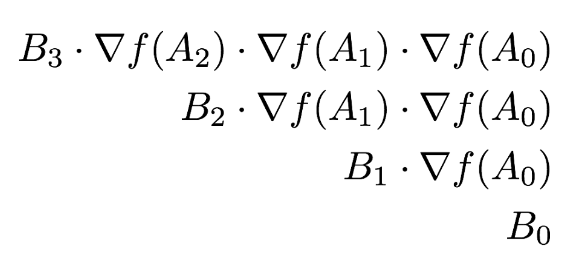
爲了進一步簡化,令 b 指代向量-雅可比乘積(即 backwards()、Left operator、grad_func),使用 Hadamard 乘積的符號表示元素對應乘積。我們就可以將向量-雅可比乘積寫爲:
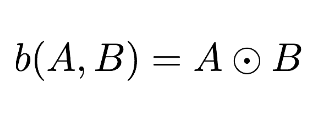
我們最終可以將前向/反向傳播的公式寫爲:
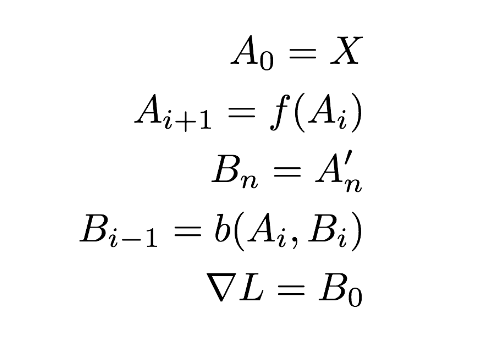
這一過程的計算圖可以表示爲(以下兩個計算圖是等價的):
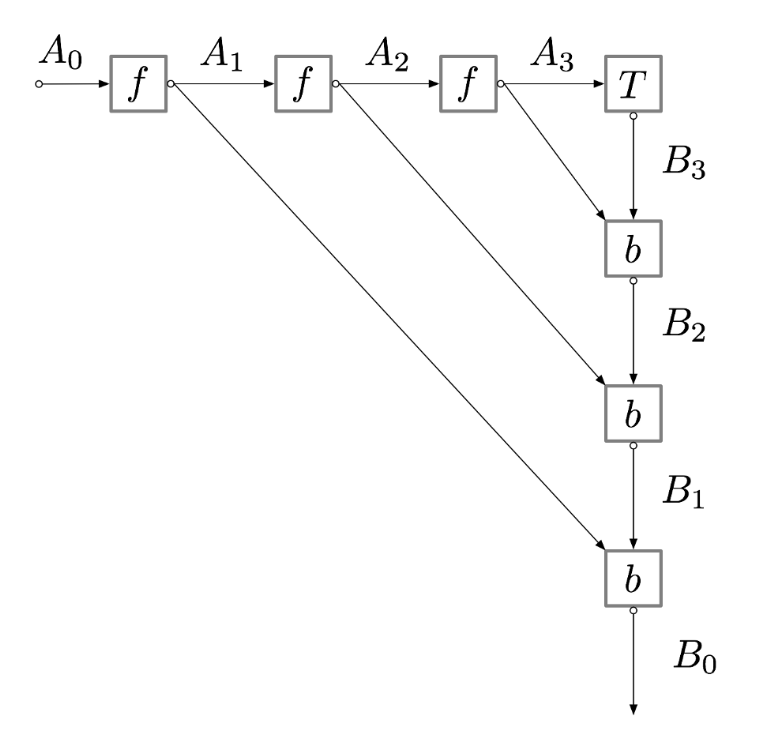
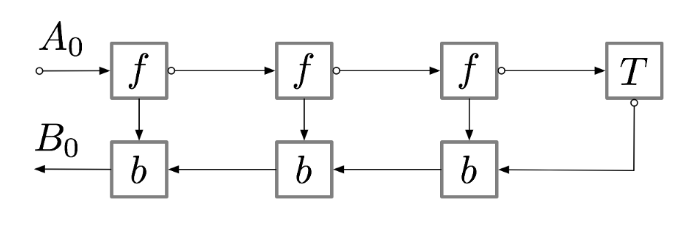
如果我們查看二維 systolic array 的架構,就會發現它們之間的結構是非常相似的,也就是說這種硬件架構能很好地擬合反向傳播算法。
原文鏈接:https://medium.com/@yaroslavvb/backprop-and-systolic-arrays-24e925d2050