在改革深度學習、拋棄反向傳播的道路上我們不僅看到了 Geoffrey Hinton 的努力。近日,《終極算法》一書作者,華盛頓大學計算機科學教授 Pedro Domingos 也提出了自己的方法——離散優化。
神經分類的原始方法是學習單層模型,比如感知機(Rosenblatt, 1958)。但是,將這些方法擴展至多層比較困難,因爲硬閾值單元(hard-threshold unit)無法通過梯度下降進行訓練,這類單元在幾乎所有情況下導數都爲 0,且在原點處非連續。因此,研究社區轉向帶有軟激活函數(如 Sigmoid、ReLU)的多層網絡,這樣梯度可以通過反向傳播進行高效計算(Rumelhart et al., 1986)。
該方法獲得了巨大成功,使研究者使用數百層來訓練網絡,學得的模型在大量任務上取得非常高的準確率,效果超越之前的所有方法。但是,隨着網絡變得更深、更寬,出現了一種趨勢:使用硬閾值激活函數進行量化,實現二元或低精度推斷,可以大幅降低現代深層網絡的能耗和計算時間。除量化以外,硬閾值單元的輸出規模獨立(或者不敏感)於輸入規模,這可以緩解梯度消失和爆炸問題,幫助避免使用反向傳播進行低精度訓練時出現的一些反常現象(Li et al., 2017)。避免這些問題對開發可用於更復雜任務的大型深層網絡系統至關重要。
出於以上原因,我們研究使用硬閾值單元學習深層神經網絡的高效技術。我們觀察到硬閾值單元輸出離散值,這表明組合優化(combinatorial optimization)可能提供訓練這些網絡的有效方法,因此本論文提出了一種學習深層硬閾值網絡的框架。通過爲每個隱藏層激活函數指定離散目標集,該網絡可分解成多個獨立的感知機,每個感知機可以根據輸入和目標輕鬆進行訓練。學習深層硬閾值網絡的難點在於設置目標,使每個感知機(包括輸出單元)要解決的問題是線性可分的,從而達到目標。我們證明使用我們的混合凸組合優化框架可以學得這樣的網絡。
基於這一框架,隨後我們開發了遞歸算法,一個可行的目標傳播(FTPROP),用來學習深度硬閾值網絡。由於這是一個離散優化問題,我們開發了啓發法以設置基於每層損失函數的目標。FTPROP 的小批量處理版本可用於解釋和證明經常使用的直通的評估器(straight-through estimator/Hinton, 2012; Bengio et al., 2013),現在這可被視爲帶有每層損失函數和目標啓發法的一個特定選擇的 FTPROP 實例。最後,我們開發了一個全新的每層損失函數,它能提升深度硬閾值網絡的學習能力。我們實際展示了我們的算法在 CIFAR10 的直通評估器爲兩個卷積網路所帶來的提升,以及在 ImageNet 上爲帶有多個硬閾值激活函數類型的 AlexNet 和 ResNet-18 所帶來的提升。

圖 1:在設置了一個深層硬閾值網絡的隱藏層目標 T1 之後,該網絡分解成獨立的感知機,進而可通過標準方法被學習。
可行的目標傳播
前面部分的開放性問題是如何設置隱藏層的優化目標。一般來說,對整個網絡一次性生成優秀的、可行的(feasible)優化目標是十分困難的。相反,在一個層級上單次只提供一個優化目標卻十分簡單。在反向傳播中,因爲神經網絡最後一層的優化目標是給定的,所以算法會從輸出層開始,然後令誤差沿着反向傳播,這種反向傳播就成功地爲前面層級設定了優化目標。此外,因爲獲取優化的先驗知識是非常困難的,那麼如果某層級的目標對於一個給定的網絡架構是可行的,我們就可以有一個簡單的替代方案。該方案爲層級 d 設置一個優化目標,然後優化前面層級已有的權重(即 j<=d 的層級權重)以檢查該目標是不是可行。因爲在優化層級時的權重和設置其上游目標(即其輸入)時的目標相同,我們稱之爲誘導可行性(induce feasibility),即一種設置目標值的自然方法,它會選擇減少層級損失 Ld 的優化目標。
然而,因爲優化目標是離散的,目標空間就顯得十分巨大且不平滑,它也不能保證在實際執行優化時能同時降低損失。因此啓發式方法(heuristics)是很有必要的,我們會在本論文的下一部分詳細解釋這種啓發式方法。d 層優化目標的可行性能通過遞歸地更新層級 d 的權重而確定,並根據 d-1 層的目標給出 d 層的優化目標。
這一遞歸過程會繼續進行,直到傳播到輸入層,而其中的可行性(即線性可分型)能通過給定優化目標和數據集輸入後優化層級的權重而簡單地確定。層級 d 的優化目標能夠基於從遞歸和層級 d-1 的輸出而獲得的信息增益中得到更新。我們稱這種遞歸算法爲可行的目標傳播(FTPROP)。該算法的僞代碼已經展示在算法 1 中。FTPROP 是一種目標傳播 (LeCun, 1986; 1987; Lee et al., 2015),它使用離散型替代連續型而優化設置的目標。FTPROP 同樣和 RDIS (Friesen & Domingos, 2015) 高度相關,該優化方法是基於 SAT 求解器的強大非凸優化算法,它會遞歸地選擇和設置變量的自己以分解潛在的問題爲簡單的子問題。但 RDIS 僅適用於連續問題,但 RDIS 的思想可以通過和積定理(sum-product theorem/Friesen & Domingos, 2016)泛化到離散變量優化中。

當然,現代深層網絡在給定數據集上不總是具備可行的目標設置。例如,卷積層的權重矩陣上有大量結構,這使得層輸入對目標是線性可分的概率降低。此外,保證可行性通常會使模型與訓練數據產生過擬合,降低泛化性能。因此,我們應該放鬆可行性方面的要求。
此外,使用小批量處理而不是全批處理訓練有很多好處,包括改善泛化差距(參見 LeCun et al. 2012 或 Keskar et al. 2016),減少內存使用,利用數據增強的能力,以及爲其設計的工具(比如 GPU)的流行。幸運的是,把 FTPROP 轉化爲一個小批量算法並放寬可行性需求非常簡單。尤其是,由於不過度使用任何一個小批量處理非常重要,FTPROP 的小批量版本 (i) 每次只使用一個小批量的數據更新每一層的權重和目標;(ii) 只在每一層的權重上採取一個小的梯度下降步,而不是全部優化;(iii) 設置與更新當前層的權重並行的下游層的目標,因爲權重不會改變太多; (iv) 刪除對可行性的所有檢查。我們把這一算法稱作 FTPROP-MB,並在附錄 A 算法 2 中展示了其僞代碼。FTPROP-MB 非常類似於基於反向傳播的方法,通過標準庫即可輕鬆執行它。

算法 2. MINI-BATCH 可行目標傳播
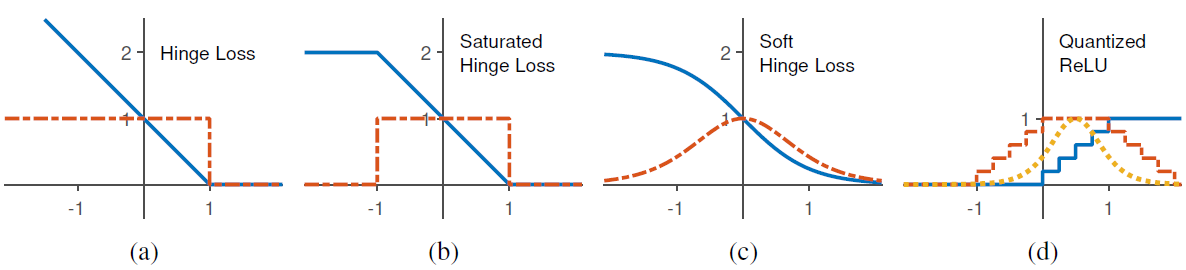
圖 2:(a)-(c)顯示了不同層的損失函數(藍線)及其導數(紅色虛線)。(d)顯示量化 ReLU 激活函數(藍線),它是階梯函數的總和,對應飽和的合頁損失導數(紅色虛線)總和,逼近這個總和的軟合頁損失性能最佳(黃色虛線)。
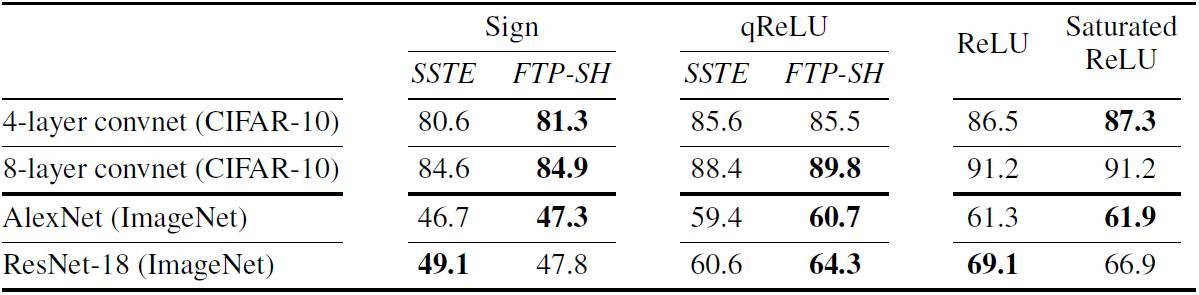
表 1. 在 CIFAR 10 或 ImageNet 上進行符號、qReLU 和全精度激活函數訓練時,各種網絡的 Top-1 準確度。硬閾值激活函數由 FTPROP-MB、逐層軟合頁損失函數(FTP-SH)與飽和直通估計(SSTE)訓練。粗體顯示了表現最好的激活函數
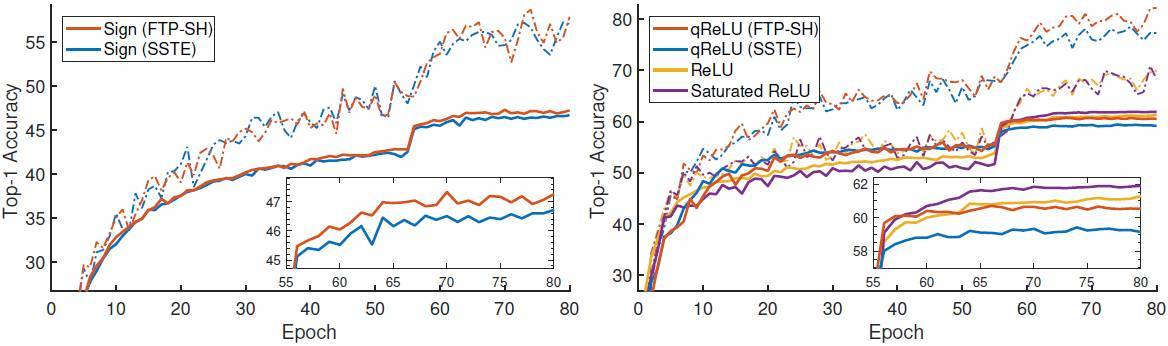
圖 3. 不同激活函數的 alexNet 在 imageNet 上的 Top-1 訓練(虛線)與測試(實線)準確度。小圖顯示了最後 25 個 epoch 的測試準確度。在兩個大圖中帶有軟合頁損失(FTP-SH,紅色)的 FTPROP-MB 要比飽和直通估計(SSTE,藍色)要好。左圖顯示了帶有標誌激活的網絡。右圖展示了新方法(FTP-SH)使用 2-bit 量化 ReLU(qReLU)訓練的表現與全精度 ReLU 幾乎相同。有趣的是,在這裏飽和 ReLU 的表現超過了標準 ReLU。
論文:Deep Learning as a Mixed Convex-Combinatorial Optimization Problem

論文鏈接:https://arxiv.org/abs/1710.11573
隨着神經網絡變得越來越深,越來越寬,具有硬閾值激活的學習網絡對於網絡量化正變得越來越重要,還可以顯著減少時間和能量的需求,用於構建高度集成的神經網絡系統,這些系統通常會有不可微的組件,確保能避免梯度消失與爆炸以進行有效學習。然而,由於梯度下降不適用於硬閾值函數,我們尚不清楚如何以有原則的方式學習它們。
在本論文中,我們通過觀察發現硬閾值隱藏單元的設置目標以最小化損失是一個離散的優化問題,這正好是問題的解決方式。離散優化的目標是找到一系列目標,使得每個單元,包括輸出內容都有線性可分的解。因此,網絡被分解成一個個感知機,它們可以用標準的凸方法來學習。基於這個方式,我們開發了一種用於學習深度硬閾值網絡的遞歸小批量算法,包括流行但難以解釋的直通估計(straight-through estimator)函數作爲範例。實驗證明,對比直通估計函數,新的算法可以提升多種網絡的分類準確度,其中包括 ImageNet 上的 AlexNet、ResNet-18。