選自Medium
作者:Oren Dar
在學習過深度學習的基礎知識之後,參與實踐是繼續提高自己的最好途徑。本文將帶你進入全球最大機器學習競賽社區 Kaggle,教你如何選擇自己適合的項目,構建自己的模型,提交自己的第一份成績單。
本文將介紹數據科學領域大家都非常關心的一件事。事先完成一門機器學習 MOOC 課程並對 Python 有一些基礎知識有助於理解文本,但沒有也沒關係。本文並不會向大家展示令人印象深刻的成果,而是回顧基礎知識,試圖幫助初學者找到方向。
文章結構:
- 介紹
- Kaggle 綜述
- 建立自己的環境
- 預測房價競賽簡介
- 加載和檢查數據
- 我們的模型:決策樹介紹、偏差-方差權衡、隨機森林
- 預處理數據
- 整合並提交結果
介紹
目前,我們能在網上找到很多高質量的免費機器學習教程,如 MOOC。一年以前,我在 Udacity 接觸了「機器學習入門」課程,我認爲它對於新手來說非常友好。在這裏,我學到了機器學習基礎概念、很多流行算法,以及 scikit-learn 的 API。在完成課程以後,我非常希望學到更多,但陷入了短暫的迷茫。
在做完一番研究後,我認爲下一步最優的選擇是進軍 Kaggle,它是谷歌旗下的一個預測模型競賽平臺。沒什麼比自己動手進行實踐更好了!
初次嘗試 Kaggle 競賽是很緊張刺激的,很多時候也伴隨着沮喪(得到好成績之後這種感覺似乎還加深了!),本文將着重介紹如何入門並開始你的第一場 Kaggle 競賽,在這個過程中儘快成長。
Kaggle 綜述
房價競賽登錄頁面。
(如果你已經熟悉 Kaggle 網站了,本段可以跳過)
Kaggle 上有兩個最適合新手的競賽(某種程度上已成爲 Kaggle 的「入門教程」):
- Titanic(預測生存:一種二元分類問題):https://www.kaggle.com/c/titanic
- 房價(預測價格:迴歸問題):https://www.kaggle.com/c/house-prices-advanced-regression-techniques
我強烈建議你兩項都嘗試一下,本文主要介紹後者。不過,其中需要的知識大部分是通用的,所以你完全可以看完本文,然後嘗試其他 Kaggle 競賽或者數據科學問題,所以選擇挑戰其他競賽也沒有問題!
在每個競賽的「Overview」(概覽)選項卡上,你可以看到關於比賽及其數據集的一些信息、提交有效結果的評估標準(每個競賽都略有不同),以及該競賽的 FAQ。
在「Data」(數據)選項卡上,你可以看到數據的簡要說明。我們需要的是這三個文件:train.csv、test.csv 和 data_deion.txt(這是至關重要的,因爲其中包含數據的詳細描述),請將它們放在你可以快速訪問的文件夾裏。
「Discussions」(討論)選項卡就像競賽的專屬論壇——不過不要低估它!在流行的競賽中,這些討論中經常包含非常有價值的信息,因爲競賽條款有時會要求參與者必須在討論版上公開他們所使用的任何信息。例如,數據泄露是很難避免和處理的,偶爾也會發生在競賽中。一方面,充分利用數據才能得到更高的分數贏得競賽;但另一方面,結合了數據泄露的模型通常對於實踐來說是無用的,所以也不被競賽支持——因爲它們使用了「非法」信息。勤奮的參與者經常會在討論版上分享數據泄露以幫助競賽環境變得更好。此外,Kaggle 的成員也會經常在其上分享一些信息,努力維護這個社區。在排行榜上名列前茅的參與者有時也會在其中分享自己的成功經驗(通常會在競賽結束前後)。
「Kernel」選項卡基本上是「討論」版塊的應用、代碼版,我認爲這是對於初學者而言最重要的一個版塊。任何人都可以在其中分享自己的腳本或筆記,鏈接任何數據集與競賽,形式可以是文檔、註釋、可視化和輸出,每個人都可以觀看、投票、複製這些內容,甚至也可以在瀏覽器上直接運行它們!我剛纔提到的兩個競賽(Titanic、房價競賽)都形成了有趣、漂亮、成功的 Kernel,強烈推薦進行過自己的嘗試之後瀏覽這個版塊。Kaggle 正在不斷提升 Kernel 的功能,現在甚至有一個「僅限 Kernel」、獎金爲 10 萬美元的競賽。不過,Kernel 中的討論往往是硬核的,缺乏有關概念的解釋,或者說預先認爲你已具備相關知識,所以有時瞭解起來會有些許困難。
建立自己的環境
我強烈推薦使用 Python3.6 在 Jupyter Notebook 環境中處理任何數據科學相關的工作(其中最流行的發行版稱爲「Anaconda」,包括 Python、Jupyter Notebook 和很多有用的庫)。然後你就可以通過在終端(或者 Anaconda GUI)輸入 Jupyter Notebook 隨時啓動該環境。除此之外,本文展示的內容也可以在 Kaggle 網站上的私人 Kernel 上完成(完全在瀏覽器上工作),這和 Jupyter Notebook 是等價的。
在開始之前,先介紹使用 Jupyter Notebook 的幾個基本要點:
- 你可以輸入任意的方法名,然後按 Tab 鍵查看所有可能選項;
- 類似地,選擇任意方法,按 Shift-Tab 鍵幾次可以在你的 notebook 中打開它的相關文檔;
- 在任意語句之前輸入%time 並執行該 cell,可以輸出所需執行時間;
- 類似地,在任意語句之前輸入%prun 並執行該 cell,可以令其在 Python 的代碼分析器中運行,並輸出結果。
可以在這裏查看更多有用的命令:http://ipython.readthedocs.io/en/stable/interactive/magics.html
預測房價競賽指南
目標概覽
這是一個監督學習問題,意味着訓練集中包含一系列的觀察數據(行)和相關的多種信息(列)。其中一列是我們感興趣並能夠預測的信息,通常稱其爲目標變量或者因變量,在分類問題中稱爲標籤、類。在我們的案例中,目標變量是房價。其它的列通常稱爲獨立變量或特徵。我們還有一個測試集,也包含一系列的觀察數據,其中的列與訓練集相同,除了目標變量,因爲我們的目標就是預測目標變量的值。因此,完美情況下,我們要建立一個模型,該模型可以學習訓練集中因變量和獨立變量之間的關係,然後使用學習到的知識在測試集中儘可能準確地預測因變量(目標變量)的值。由於目標變量(房價)是連續的,可以取任意的值,因此這個問題屬於迴歸問題。
加載和檢查數據
現在我們已經成功啓動了 Jupyter Notebook,首先要做的事情就是加載數據到 Pandas DataFrame 中。Pandas 可以處理 Python 中所有數據分析相關的工作,是很強大和流行的庫,DataFrame 是它用於保存數據的對象名稱。
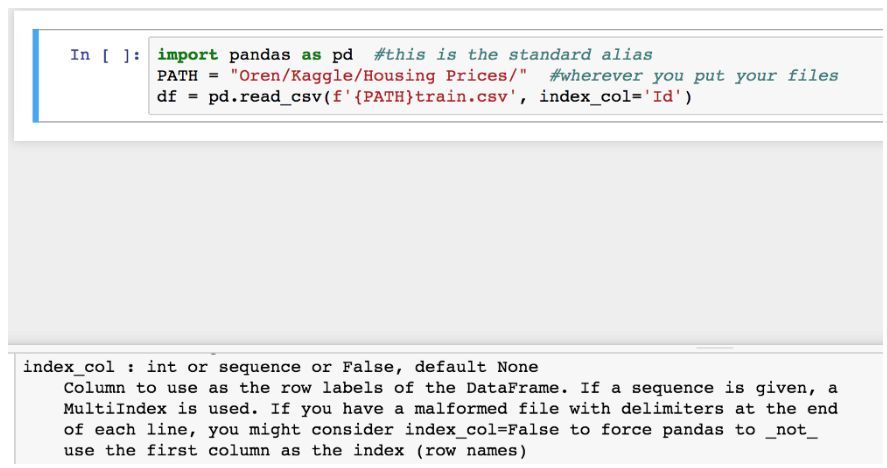
按 Shift-Tab 幾次,打開文檔。
最後一行使用了 Python 3.6 的字符串格式將從 Kaggle 下載的 CSV 文件(『comma-separated-values』,一種常用格式,可使用任何標準軟件打開,例如 Excel)加載到 Pandas DataFrame 中。我們之後將頻繁使用 read_csv,因此建議先瀏覽它的文檔(這是一個好習慣)。加載數據並查看 DataFrame,可以發現數據集中的第一列是 Id,代表數據集中該行的索引,而不是真實觀察值。因此,我修改了代碼,加上 index_col=『Id』作爲參數,從而在加載數據到 DataFrame 的時候,確保 Pandas 將其作爲索引而不是列,並在它之前添加一個新的索引列。
現在,我們來看看訓練集的樣子。
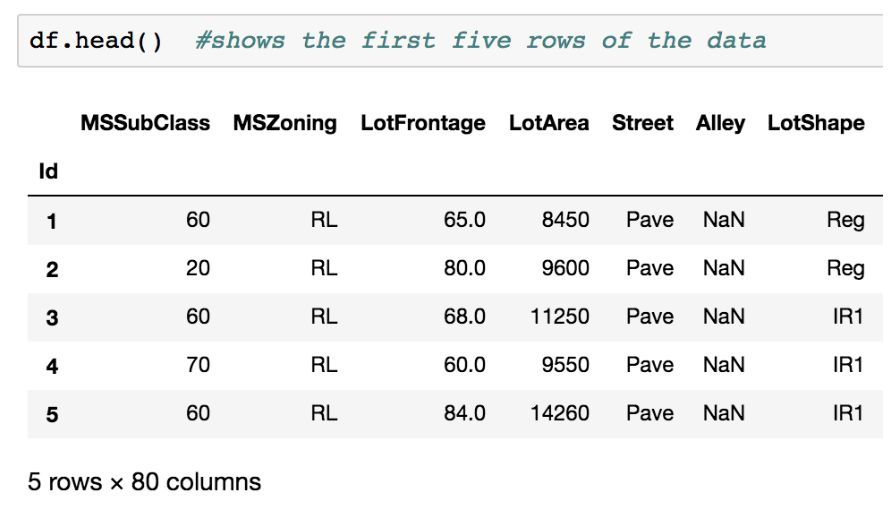
訓練集的數據結構
訓練集總共有 80 列(除 Id 以外),其中 79 列是獨立變量,1 列是因變量。因此,測試集應該只有 79 列(獨立變量)。大多數的數字和字符串都沒有什麼意義,其中 Alley 列甚至全都是『NaN』,即值的丟失。別擔心,我們之後會處理這個問題。下一步是考慮需要使用的模型。我們先討論一下決策樹(有時在應用到迴歸問題的時候稱爲迴歸樹)。
如何構建我們的模型
決策樹介紹
其基本思想是很簡單的,當學習(擬合)訓練數據的時候,迴歸樹搜索所有獨立變量和每個獨立變量的所有值,以尋找能將數據最佳地分割爲兩組的變量和值(從數學角度來說,樹總是選擇能最小化兩個節點的加權平均方差的分割),然後計算分數(最好是選定指標上的分數),以及每個組因變量的平均值。接着迴歸樹遞歸地重複該過程,直到無法進一步分割(除非設置了具體的 max_depth,如下圖所示)。樹最後一級的每個節點都被稱爲『葉』,每一個都和因變量(在該葉相關的所有觀察數據)的平均值相關。
旁註:這是一個『貪婪』算法的很好示例,在每一次分割中,算法檢查了所有選項,然後選擇了在該點的最佳選項,以期望最終得到全局最佳結果。當樹擬合了訓練數據之後,使用任何觀察數據預測因變量的值時,只需要遍歷樹,直到抵達一個葉節點。
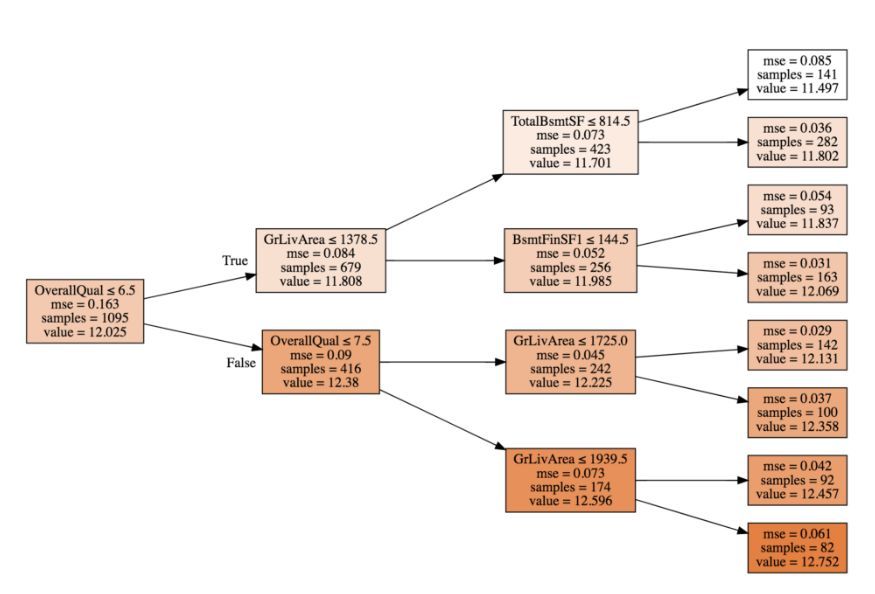
我們數據集的可視化示例,其中 max_depth 設爲 3。
在樹的每個節點,第一個元素是節點的分割規則(獨立變量及其變量值),第二個元素是在該節點的所有觀察數據的均方差(MSE),第三個元素是該節點的觀察數據的數量(samples),即這一組的規模。最後一個元素 value 是目標變量(房價)的自然對數。該過程和貪婪算法類似,在每個節點局部地進行最佳分割,確實可以隨着樹的擴展減少均方差的值,並且每個葉節點都有一個相關的「SalePrice」值。
偏差-方差權衡
我們回憶一下監督學習的目標。一方面,我們希望模型可以通過擬合訓練數據捕捉獨立變量和因變量的關係,從而使其可以做出準確的預測。然而,模型還需要對(未見過的)測試數據進行預測。因此,我們還希望模型捕捉變量之間的普遍關係,從而可以進行泛化。該過程稱爲『偏差-方差權衡』。
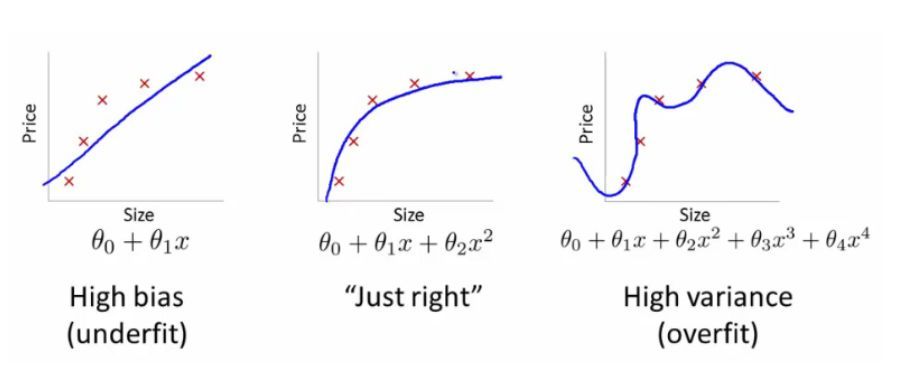
如果模型沒有充分擬合訓練數據,它將會有高偏差(通常稱爲欠擬合),因此它的訓練誤差較大。然而,如果模型過於擬合訓練數據,它會捕捉到變量之間的特殊關係(偶然的),導致高方差(通常稱爲過擬合),因此它的測試誤差較大。所以,我們需要在偏差和方差之間進行權衡。
決策樹過擬合
假定我們將一個迴歸樹擬合到訓練數據中。這個樹將是什麼結構?實際上,它將持續分割直到每個葉節點只有一個觀察數據(無法再繼續分離)。換種說法,迴歸樹將爲訓練集的每一個觀察數據建立一個獨特路徑,並根據觀察數據在路徑末端的葉節點上給出因變量的值。
如果將訓練集中因變量的值刪除,並用訓練過的樹預測因變量的值,結果如何?可以猜到,它將表現得很完美,達到基本 100% 的準確率和 0 均方差。因爲它已經學習了訓練集中每個觀察數據的相關因變量值。
然而,如果我打算讓樹預測未見過的觀察數據的因變量值,它將表現得很糟糕,因爲任何未見過的觀察數據都會在原來的樹構建一個獨特的葉節點。這正是一個過擬合的例子。可以通過調整樹的參數減少過擬合,例如,限制樹的 max_depth,但實際上還有更好的方法。
解決方案:隨機森林
在機器學習中,我們通常會設計「元學習」以結合小模型的多個預測而生成更好的最終預測,這種方法一般可稱爲集成學習。特別的,當我們結合一些決策樹爲單個集成模型,我們可以將其稱之爲「Bootstrap Aggregating」或簡單地稱之爲「Bagging」。通過這種方法構建的「元模型」是一種較爲通用的解決方案,因此隨機森林可以適用於廣泛的任務。
隨機森林簡單而高效,當我們用這種方法擬合一個數據集時,就會像上文所述的那樣構建許多決策樹,只不過每個決策樹是在數據的隨機子集中構建,且在每一次分割中只考慮獨立變量「特徵」的隨機子集。然後爲了生成新的觀察值,隨機森林會簡單地平均所有樹的預測,並將其作爲最終的預測返回。
現在我們所做的的就是構建許多弱分類器或弱決策樹,然後取它們的平均值,爲什麼要這樣做呢?
簡單的回答就是它們確實工作地非常好,如果讀者對隨機森林的統計解釋感興趣的話,可以閱讀更多的技術細節。但我不擅長於統計,但我會盡可能地給出一個基本的解釋:bootstrap 採樣和特徵子集可以使不同的決策樹儘可能地去相關(即使它們仍然基於相同的數據集和特徵集),這種去相關能允許每一棵樹在數據中發現一些不同的關係。這也就使它們的均方差要比任何單顆樹都少的多,因此減少過擬合後它們能在總體上獲得更好的預測和泛化結果。
簡單來說,對於未見的觀察結果,每個決策樹預測該觀察結果結束時所處葉節點的因變量值,即特定樹空間中最類似的訓練集觀察結果。每棵樹都是在不同的數據上構建的不同樹,因此每棵樹用不同的方式定義相似性,預測不同的值。因此對於給定未見觀察結果,所有樹的平均預測基本上就是訓練集中與之類似的觀察結果的值的平均值。
此特性的影響之一是:儘管隨機森林在測試集與訓練集相似度較高時(值屬於同樣的範圍)非常擅長預測,但當測試集與訓練集存在根本區別時(不同範圍的值),隨機森林的預測性能很差,比如時序問題(訓練集和測試集不屬於同樣的時間段)。
不過我們的案例中測試集和訓練集具備同樣範圍的值,因此這對我們沒有太大影響。
回到比賽
預處理數據
我們在讓隨機森林運行起來之前還有一件事要做:隨機森林雖然理論上可以應對分類特徵(非數據形式:字符串)和數據缺失,scikit-learn 實現卻並不支持這兩種情況。所以我們需要使用 pd.interpolate() 來填充缺失的值,然後使用 pd.get_dummies() 的『One-Hot Encoding』來將分類特徵轉換爲數字特徵。這個方法非常簡單,讓我們假設一個分類變量有 n 個可能值。該列被分爲 n 個列,每一列對應一個原始值(相當於對每個原始值的『is_value?』)。每個觀察值(以前有一個分類變量的字符串值),現在在舊字符串值對應的列上有一個 1,而其他所有列上爲 0。
我們現在準備構建一個模型,使用數據進行訓練,並用它來預測測試集,然後將結果提交到 Kaggle 上。
整合結果並提交
這就是我們的模型提交 Kaggle 所需的所有代碼——大約 20 行!我們運行這些代碼,隨後繼續向 Kaggle 提交結果——得分爲 0.14978,目前排行約爲 63%。對於五分鐘的代碼編寫來說,結果不錯!在這裏我們可以看到隨機森林的力量。
- import pandas as pd
- from sklearn.ensemble import RandomForestRegressor
- PATH = "Oren/Kaggle/Housing Prices/" #where you put the files
- df_train = pd.read_csv(f'{PATH}train.csv', index_col='Id')
- df_test = pd.read_csv(f'{PATH}test.csv', index_col='Id')
- target = df_train['SalePrice'] #target variable
- df_train = df_train.drop('SalePrice', axis=1)
- df_train['training_set'] = True
- df_test['training_set'] = False
- df_full = pd.concat([df_train, df_test])
- df_full = df_full.interpolate()
- df_full = pd.get_dummies(df_full)
- df_train = df_full[df_full['training_set']==True]
- df_train = df_train.drop('training_set', axis=1)
- df_test = df_full[df_full['training_set']==False]
- df_test = df_test.drop('training_set', axis=1)
- rf = RandomForestRegressor(n_estimators=100, n_jobs=-1)
- rf.fit(df_train, target)
- preds = rf.predict(df_test)
- my_submission = pd.DataFrame({'Id': df_test.index, 'SalePrice': preds})
- my_submission.to_csv(f'{PATH}submission.csv', index=False)
說明
在將訓練集和測試集分別加載進 DataFrame 之後,我保存了目標變量,並在 DataFrame 中刪除它(因爲我只想保留 DataFrame 中的獨立變量和特徵)。隨後,我在訓練集和測試集中添加了一個新的臨時列('training_set'),以便我們可以將它們連接在一起(將它們放在同一個 DataFrame 中),然後再將它們分開。我們繼續整合它們,填充缺失的數值,並通過獨熱編碼(One-Hot Encoding)將分類特徵轉換爲數字特徵。
正如之前所述的,隨機森林(以及其他大多數算法)都會在訓練集和測試集有差不多數值的情況下工作良好,所以在修改內容的時候我希望對兩個數據集進行同樣的修改。否則,interpolate 可能會在訓練集和測試集上填入不同的數值,而 get_dummies 可能會以兩種不同的方式對相同的分類特徵進行編碼,從而導致性能下降。隨後我在將其分開,去掉臨時列,構建一個有 100 個樹的隨機森林(通常,樹越多結果越好,但這也意味着訓練時間的增加),使用計算機的所有 CPU 核心(n_jobs=-1),使用訓練集進行擬合,用擬合的隨機森林來預測測試集的目標變量,把結果和它們各自的 Id 放在一個 DataFrame 中,並保存到 一個 CSV 文件中。隨後登陸 Kaggle 頁面提交 CSV 文件,大功告成!
原文地址:https://towardsdatascience.com/machine-learning-zero-to-hero-everything-you-need-in-order-to-compete-on-kaggle-for-the-first-time-18644e701cf1